文 | Alter
4月24日上午,姗姗来迟的DeepSeek V4终于显露真身。
当天,DeepSeek-V4-Pro即登顶Hugging Face开源模型榜,两个“核弹级创新”被津津乐道:
一是百万级的超长上下文,但KV cache只有V3.2的10%,被亚马逊工程师盛赞将解决HBM短缺问题;
二是对国产芯片的适配,在研发过程中与华为紧密合作,并第一时间适配了昇腾、寒武纪等国产芯片。
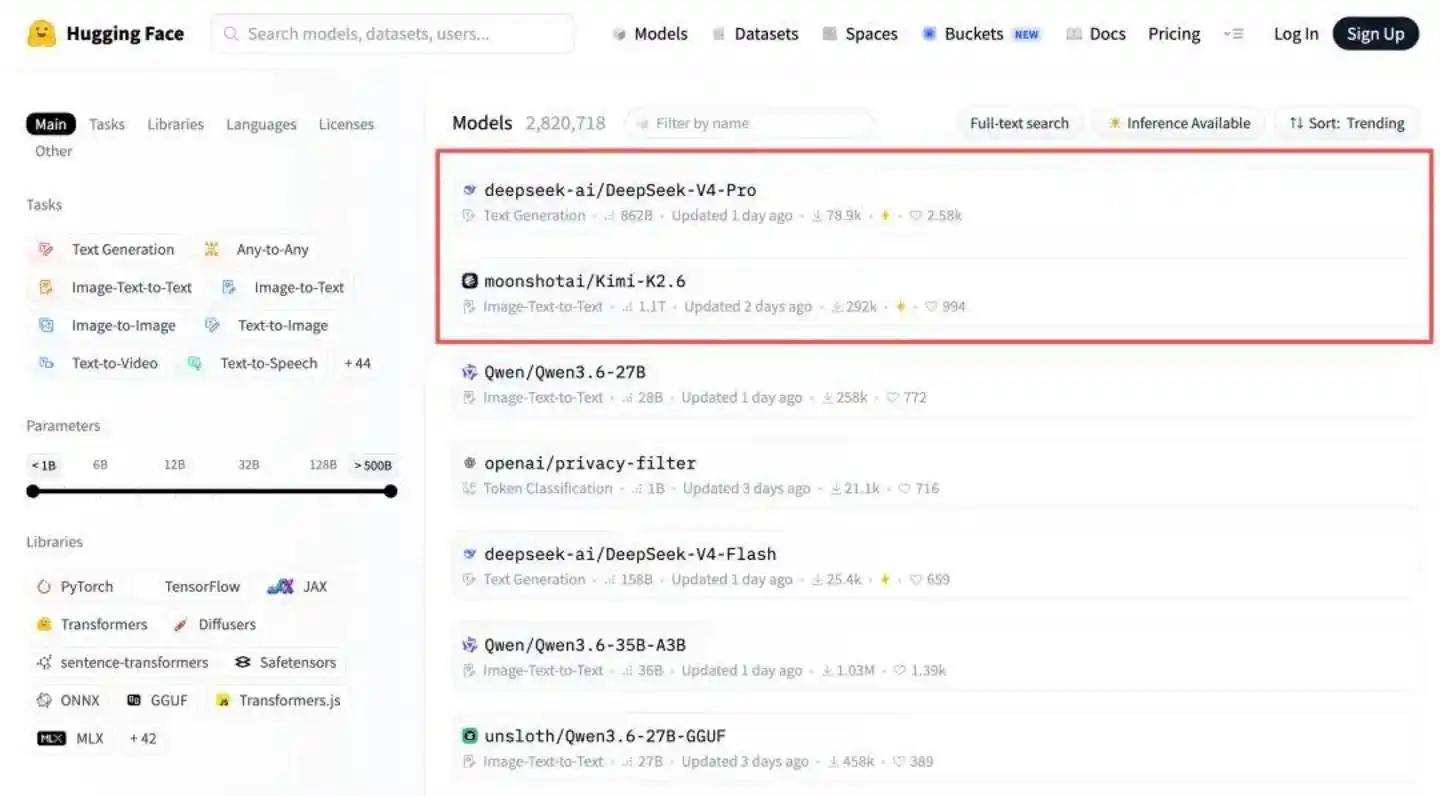
巧合的是,Hugging Face开源模型榜排名第二的,正是4月20日深夜发布并开源的Kimi K2.6。
如果是在太平洋对岸,两个万亿参数模型的“撞档”,免不了为了估值、商业版图互相攻讦,国内却上演了截然不同的一幕:没有互揭老底的戏码、没有暗流涌动的公关战,甚至在技术底层进行了“换防”。
“不寻常”的背后,暗藏了中美在AI技术路线上的分歧:硅谷疯正在狂“竖起高墙”,试图用闭源守住既得利益;国大模型厂商则选择“拆掉围墙”,在开源的土壤上走向了协同进化。
01 硅谷深陷“权力的游戏”
不同于国内大模型百花齐放的开源路线,OpenAI、Anthropic、谷歌Gemini为代表的硅谷AI头羊,无不是闭源的拥趸。
当前沿的技术创新被锁死在各自的数据中心里,面对算力成本的重压和资本市场的期待,以开放与协作著称的“硅谷精神”渐渐消亡,玩家们不可避免地陷入了零和博弈的“权力游戏”。
过去两年里,技术“暗战”已经演变成公开互撕,最典型的手段就是互相“抢风头”:在竞争对手发布新产品的关键节点,迅速抛出自家的重磅更新来遏制对方的声量,已经成为硅谷的常规操作。
早在2024年5月,OpenAI和谷歌就曾同时发布AI新品,一方说GPT-4o全球领先,一方说Gemini家族能覆盖全生态全路径。最后两家公司的CEO都坐不住了,公开在社交媒体上嘲讽对方。
不只是和谷歌的“缠斗”,OpenAI与Anthropic的较量也进入了白热化:就在4月16日,Anthropic刚发布了新模型Claude Opus 4.7,OpenAI在两个多小时后便宣布Codex大幅更新,喊出了“Codex for(almost) everything”的口号。明眼人都看得出来,时间上的撞档绝非巧合,而是OpenAI针对Anthropic精心策划的一场“狙击”。
除了舆论场上的“文斗”,互相“揭老底”的“武斗”也成了硅谷的常态。
Anthropic在4月7日高调宣布年化收入达到300亿美元,成功超越OpenAI的250亿美元。
一个礼拜后,OpenAI首席营收官在给全体员工的内部信中直言不讳地指出:Anthropic对外宣称的300亿美元年化营收存在严重水分,因为它采用的是“总额法”,把分给亚马逊、谷歌等云服务商的抽成,也全额算进了自己的总营收里,导致年化收入被高估了约80亿美元。
内部信中给对手拆台的做法,在科技行业并不常见,目的无非是想告诉投资人——Anthropic的增长神话是注水的。
而一旦敌意滋生,会无孔不入地影响每一个决策。
Anthropic因拒绝删除合同中的特定安全条款与五角大楼“闹掰”后,OpenAI几个小时后就高调宣布已与美国国防部达成合作。
在2026年的“超级碗”上,Anthropic重金投放了一条广告,内容是“广告正在进入AI领域,但不会进入Claude。”可以说是对着刚开始测试广告功能的OpenAI“贴脸开大”.......
为何昔日的“同门兄弟”,走到了水火不容的地步?
根源在于闭源商业模式的固有逻辑:闭源的生存根基在于构建护城河,而构建护城河的前提就是阻断技术扩散,垄断最先进的生产力。再加上技术路线不兼容、产品叙事对立,自然而然地形成了一个纳什均衡:谁先“停火”,谁的品牌叙事就会坍塌,最终在内耗的泥潭里越陷越深。
02 开源阵营的“协同进化”
将视线转回国内,剧本的走向完全不同。
时间回到一年多前,DeepSeek-R1的横空出世,为狂奔的大模型创业赛踩了一脚刹车,进入决赛圈的大模型“六小虎”首当其冲。和硅谷最大的区别,DeepSeek没有扮演吃掉池子里所有鱼的“鲨鱼”,而是像鲶鱼一样激活了整个中国大模型生态,大家纷纷拥抱开源。
直接的例子就是和DeepSeek的成长轨迹高度重合的月之暗面 都是2023年起步的初创团队,都保持着人数极少但人才密度极高的团队结构,并且都是Scaling Law的坚定信徒。
2025年7月,月之暗面发布了全球第一个万亿参数的开源模型Kimi K2,在技术报告里毫不掩饰的说采用了DeepSeek开源的MLA架构。对于大模型来说,处理超长文本最大的噩梦是显存墙,而MLA架构的颠覆性在于,巧妙将KV Cache的压缩率做到了惊人的93%以上。
有了DeepSeek贡献的“业界标准”,月之暗面在内的大模型团队不需要重复造轮子,快速降低了推理成本。
故事并未止步于此。
翻看DeepSeek V4的技术文档,详细描述了模型的架构,其中一个重要升级是把大部分模块的优化器从AdamW换成了Muon,实现了更快的收敛速度、更优的训练稳定性。
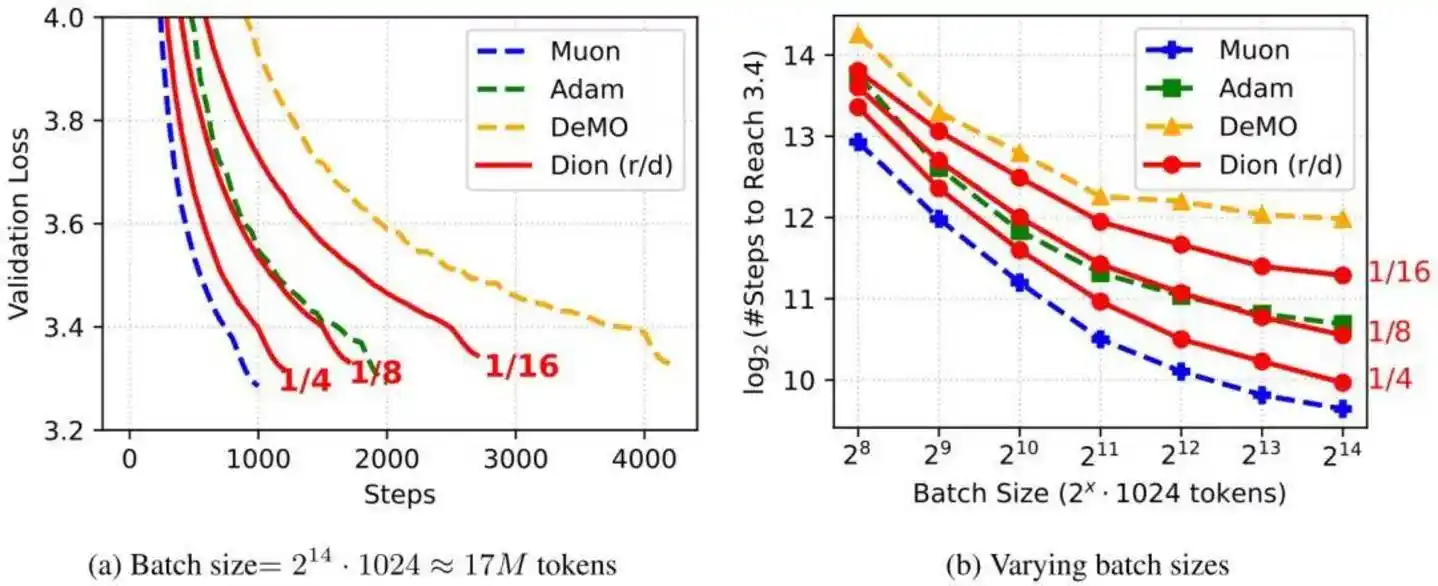
在Kimi K2.6的技术文档中,同样提到了Muon优化器,在相同的训练量下实现了2倍的效率提升。
两个模型都提到的Muon优化器,最早由独立研究者Keller Jordan在2024年底的博客里提出。同样被AdamW困扰的月之暗面团队,在2025年初对Muon进行了关键的工程化改进,增加了Weight Decay、RMS控制等能力,并命名为MuonClip。
月之暗面在Kimi K2上率先验证了Muon优化器的稳定性,实现了预训练全程“零Loss Spike”。DeepSeek在训练V4大模型时,同样采用了被验证过的Muon优化器。
需要说明的是,开源大模型的“协同进化”并未陷入同质化,正在走向一条“和而不同”的道路。
比如DeepSeek-V4聚焦基础模型的核心能力攻坚,进一步筑牢了全球开源大模型的性能天花板,为全行业提供了性能比肩闭源旗舰的基础底座;Kimi K2.6深耕Agent工程化落地,解决了大模型长程自主执行的痛点,为大模型进入真实生产场景打通了关键路径。
整个过程中,没有旷日持久的商业谈判,没有剑拔弩张的专利博弈。在开源阵营里,技术创新正在像水一样自由流动,谁做得好,大家就用谁的。
在开源生态中汲取养分,在技术路线上互补。中国的大模型厂商,用行动向世界示范了硅谷之外的另一种可能。
03 美国在“造墙”,中国在“修路”
赞叹开源协同进化的同时,必须直面一个商业现实。
目前OpenAI和Anthropic的年化收入均达到了百亿美元以上,而国内头部大模型厂商的营收,刚跨过年化一亿美元的大门。
OpenAI在二级市场的估值约8800亿美元,Anthropic的估值已经飙升到了1万亿美元左右,而Kimi和DeepSeek新一轮融资的估值,分别为180亿美元和200亿美元。
有人高呼中国大模型厂商的市值被低估了,也有人认为:“能否将技术口碑转化为真金白银,是摆在中国厂商面前的生死大考。”一时间,关于开源“性价比”的讨论甚嚣尘上。
想要看清终局,或可以从大模型的竞争阶段着手:

第一阶段是“拼参数、拼Benchmark”。到了2026年4月末,这个阶段基本结束,各家在榜单上的跑分已经拉不开实质性差距。
第二阶段是“拼训练效率、拼推理成本、拼架构创新”。正是当下所处的赛段,也是算力成本倒逼下的必然结果。
第三阶段将是“拼Agent体系、拼生态、拼开发者”。当Token从免费流量变成执行任务的“燃料”时,生态的繁荣度将决定生死。
国内的开源大模型处于什么生态位呢?我们找到了两组直观的对比数据。
一个是训练成本。
2025年8月发布的GPT-5,训练成本超过5亿美元;同期的Kimi K2 Thinking,训练成本约460万美元;DeepSeek没有公布V4系列模型的训练成本,但V3模型仅花费了557.6万美元......国内大模型厂商只用了不到OpenAI零头的资源,训练出了同等水平的模型。
另一个是调用量。
进入2026年后,多模型聚合平台OpenRouter的数据显示:在OpenClaw代表的Agent产品的带动下,全球的Token消耗量呈现出了指数级增长,中国的“开源梦之队”,凭借“好用又便宜”的口碑,调用量已经连续多周超越美国。
原因并不难解释。
中国开源阵营已经跑通了“正反馈飞轮”:A公司开源底层技术,B公司采用并进行工程优化,再将优化的结果和经验反哺给整个生态。如果说闭源模型的进化是建立在海量算力堆砌上的线性增长,等待开源路线的,将是技术创新相互碰撞带来的指数级扩散。
按照摩根大通的研报,2025-2030年间中国AI推理token消耗量将实现约330%的年复合增长率,将从2025年的10万亿token,激增至2030年的3900万亿token,增长规模达370倍。
也就是说,2026年仍处于AI爆发的初期,未来5年里还有数百倍的增长机会,远未到盖棺定论的时候。
恰恰是对长远机会的自信,在硅谷巨头们拼命造墙时,中国的大模型厂商选择用协同补位的方式,不断夯实通往AGI的路。
04 写在最后
这场轰轰烈烈的AI浪潮,谁会笑到最后?答案不仅关乎模型,还关系到算力的自主可控。如果把模型比作“原子弹”的话,摆脱外部技术封锁的国产算力,就是将原子弹送上天的“火箭”。
让人欣慰的是,国产模型和国产算力的融合越来越紧密:DeepSeek V4的技术文档中,将昇腾NPU与英伟达GPU并列写入了硬件验证清单;月之暗面在最新的论文中将大模型推理的预填充和解码运行在了不同芯片上,为国产芯片大规模参与模型推理打开了大门。
2025年初,DeepSeek R1为国产大模型争取到了上牌桌的机会;到了2026年,中国的开源大模型阵营,正在协同合作中不断创造更多定义牌桌规则的硬资本。








