文 | 朝阳资本论,作者 | 沙华
AI行业的竞争,已经从模型技术之争,演进为算力、人才、产品与生态的全面战争。
在这场战争面前,任何试图独善其身的“技术乌托邦”,都走进了围城之中。
2026年4月,国内AI明星公司DeepSeek被曝出启动首次外部融资,计划以不低于100亿美元的估值筹集至少3亿美元资金。
消息一出,市场震动。
“不差钱”的DeepSeek开口要钱了。
这一举动,打破了创始人梁文锋此前“拒绝融资、保持独立性”的理想主义叙事。
但耐人寻味的是,100亿美元的估值,放在智谱AI和MiniMax港股上市后动辄数千亿港元的市值面前,简直“便宜得离谱”。
3亿美元的募资规模,放在今天的大模型赛道里,甚至比不上同行一轮融资的零头。
况且,DeepSeek账上并不缺钱,幻方量化每年数亿美元利润持续输血,梁文锋也曾公开表示“VC的钱是负担”,为什么突然在这个时间点,以这样一个金额和估值,拥抱资本市场?
技术理想国的困境
2025年春节,DeepSeek凭借R1模型以560万美元的训练成本炸穿了中美AI圈对大模型研发的常识。美国风投家马克·安德森称之为AI领域的“斯普特尼克时刻”。
比技术突破更让市场记住的,是梁文锋对资本的拒绝。
腾讯、阿里的入股邀约被他一一回绝,市面上几乎每一家顶级风投都在他的闭门羹列表里。他的理由很直白:VC都是帮LP管钱的,都得赚钱,所以谈不到一块去。
在梁文锋的理想里,DeepSeek不应该被任何人的商业化时间表绑架,要追AGI、做开源,让技术本身说话。
这份底气来自母公司幻方量化。
据私募排排网数据,2025年幻方量化平均收益率高达56.6%,管理规模超700亿元。有业内人士估算,仅2025年一年幻方就为梁文锋带来了超过7亿美元的收入。这就是DeepSeek的“无限弹药”。
DeepSeek不需要向任何外部资本低头,不需要在任何一个季度交出一份漂亮的商业化报表。
可到了2026年春天,这个故事续写不下去了,变化最先出现在产品端。
DeepSeek已有15个月没有大版本更新,突然踩下了刹车。原计划于2026年2月春节前后发布的旗舰模型V4,发布时间从1月传到4月,一次次把开发者吊到嗓子眼。同期,OpenAI和Anthropic却进入了“月更模式”。
比产品节奏放缓更致命的是人才的流失。
据公开资料,2025年下半年至今,DeepSeek至少有5名核心研发成员确认离职。第一代大语言模型核心作者王炳宣去了腾讯;V3核心贡献者罗福莉被雷军千万年薪挖至小米;R1核心研究员郭达雅以传闻近亿元总包入职字节跳动Seed团队;OCR系列核心作者魏浩然和多模态成果核心贡献者阮翀也先后离开。
DeepSeek总共不到200人,核心研究团队100多人,基模架构团队仅小几十人。在这个极度依赖个人能力的小团队里,每一个核心研究员的流失都意味着整条技术线的停顿。
DeepSeek的内困,在外部压力下被放大。
被捧上神坛的公司,正在被时间一点点拉回地面。
智谱和MiniMax已在港股上市,市值分别站上4000亿港元和2700亿港元。在海外,Anthropic更是凭借智能体产品年化收入突破300亿美元、一举反超OpenAI。
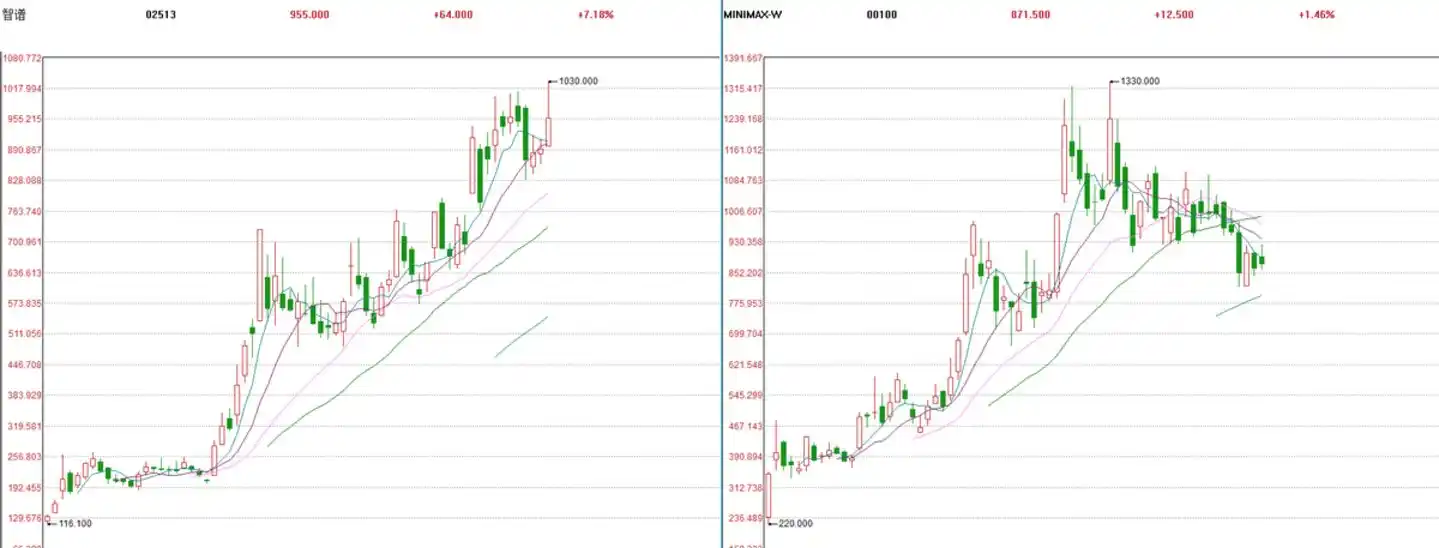
Anthropic、智谱和MiniMax的ARR狂飙,揭示行业竞争进入围绕算力、人才、产品和生态的商业化竞速阶段。
纯粹的技术理想,已不足以支撑一家AI公司在产业化进程里持续领跑,更无法让顶尖人才坚定留下来的信心。
DeepSeek需要一个锚点,为“理想”标价
人才为何流失?
薪酬数字的账最直白。
DeepSeek的绝对薪资在同业中并不低,但竞争对手开出的条件“翻2到3倍问题不大”,部分甚至给出八位数总包。比如,罗福莉的出走背后,雷军以千万年薪亲自下场加码招募。
这背后是AI行业正在经历的一场深刻的人才通胀。猎聘2025年报告指出,中国AI人才缺口已突破500万。麦肯锡曾预测,2030年中国对AI专业人员的需求将增至2022年的6倍。

图源:猎聘2025年度人才供需趋势报告
资本巨头们正在以近乎疯狂的速度为顶级大脑定价,用经过验证的人才对冲自身的研发不确定性。
但巨头高薪抢人还只是第一层原因,比薪酬数字更致命的是期权本身“无法定价”带来的不确定性。
DeepSeek面临的挑战并不仅仅是基数差距,更关键的是其期权缺少一个可对标的市场化价格基准。
DeepSeek从成立至今从未接受过任何外部融资,员工手中的期权完全依赖内部估值。在没有外部机构以真金白银确认价格之前,这种账面财富在顶级AI人才眼中缺乏足够的流通性和溢价锚点。没有上市预期、没有股权变现通道、没有可对标的估值锚点,这纸期权就是一张无法兑现的期票。
梁文锋或许不需要VC的钱来维持公司运转,但他缺一个经过市场验证的“价格锚点”。
有了这个锚点,DeepSeek的期权就从一个虚无缥缈的概念变成了一个有公允价值的金融资产,组织激励机制也从理想主义落地为市场逻辑。
3亿美元,放在今天的AI赛道里,不是什么大数字。对于DeepSeek更是仅仅付出3%的股权,换取市场价值认可,重构DeepSeek的人才激励机制。在AI行业“人才即一切”的铁律下,这可能是比任何技术突破都更务实的一步。
除此之外,梁文锋把这笔钱花在哪儿,比融资本身更能说明问题。
从研究机构到生态玩家,V4与国产算力的赌注
V4延期的真正原因,从来不是技术瓶颈。
此前,路透社报道披露了一个细节:DeepSeek R1发布后,有关部门鼓励公司采用华为昇腾处理器。
一位知情人士对媒体表示,过去几个月,DeepSeek的工程师们一直在做一件吃力不讨好的事,即把V4从英伟达的CUDA生态,整体迁移到华为昇腾的CANN架构。
为此,DeepSeek要重写底层代码,调整通信库和训练框架,对模型在不同硬件上的输出做精度对齐。但这是一次不得不做的战略转向。
为什么非做不可?
从产业链的逻辑看,在美国对高端芯片实施出口管制的情况下,这是长期安全稳定发展的保证。
英伟达CEO黄仁勋在近期采访中直言不讳:“基于国产硬件平台的新模型对美国而言可能是一个糟糕的结果。”他担心一旦顶尖AI模型被优化到在国产芯片上表现更好,英伟达多年构建的生态护城河将不再牢固。
美国不断加码出口管制,导致英伟达在中国高端AI芯片市场的份额,从曾经的95%直接跌至零。
如果V4成功跑通,它将成为全球首个不依赖英伟达的前沿大模型。
值得一提的是,光有前沿模型还不够,今天的AI竞争早已不是“谁参数最大谁赢”的单点游戏。
一位业内人士用一句话概括了当下的格局:谁能在应用层构建完整的生态闭环,谁才能真正活下来。
对此,字节跳动的打法是把AI能力拆解为可复用的“积木”,嵌入抖音、即梦、飞书等产品线,形成“产品矩阵+AI中台”的积木式布局。而腾讯直接把手伸进坐拥12亿用户的微信,推出ClawBot插件,用户无需跳转即可调用AI智能体。就连智谱AI也在Coding赛道上实现了规模化收入,GLM-5.1发布后,配套的Coding Plan订阅一度“瞬间断货”。
相比之下,DeepSeek的短板清晰可见。
DeepSeek缺乏一个像抖音或微信那样的超级应用入口,也缺乏一个被大规模验证的商业化闭环。强大的模型和开源社区的声望是它的护城河,但在终端产品、多模态能力和Agent生态上,它明显滞后。
换句话说,DeepSeek仍在用模型时代的思维去打生态时代的仗,这不只是慢半拍,而是跑错了赛道。
从长期竞争的角度考虑,融资的深层战略意图,是宣告DeepSeek正式加入AI生态的“下半场”竞争。
引入外部资本,意味着DeepSeek的公司治理结构将走向规范化,成为一个要面对市场检验、要向投资人交代的商业主体。
这一步,是DeepSeek从研究机构转型为产业级玩家的入场券。
V4能否在国产算力上证明自己,融资能否撬动它补齐应用层的短板,将决定它从一匹“技术黑马”蜕变为一个“生态玩家”的可能性。而这场蜕变,需要的远不止3亿美元。
新的风暴,刚刚出现。