Setiap kali model terdepan dirilis, kalangan AI akan menatap beberapa 'raport' yang sudah familier.
MMLU-Pro, MMMU, MMMU-Pro... Nama-nama ini mungkin terdengar asing bagi pengguna biasa, tapi bagi perusahaan model dan peneliti, mereka hampir menjadi 'mata pelajaran standar'. GPT, Claude, Gemini, Llama, Qwen, DeepSeek terus-menerus mengumpulkan 'lembar jawaban' mereka di tolok ukur ini.
'Harus diuji untuk melihat kualitasnya', performa model seringkali harus dibuktikan dengan skor-skor ini.
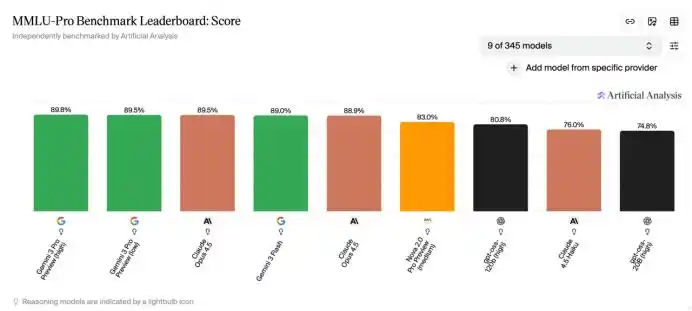
Banyak grafik perbandingan performa dalam peluncuran model, tak lepas dari mereka; beberapa peringkat di HuggingFace juga dibangun di atas sistem evaluasi ini. Bahkan bisa dikatakan, saat industri AI membahas kemampuan model hari ini, yang digunakan adalah bahasa bersama yang didefinisikan oleh tolok ukur ini.
Tapi yang menarik, hampir semua orang fokus pada skor, tapi sangat sedikit yang tahu siapa pembuat soalnya. Dan di balik MMLU-Pro, MMMU, dan MMMU-Pro, bisa dilihat nama yang sama—Chen Wenhu.
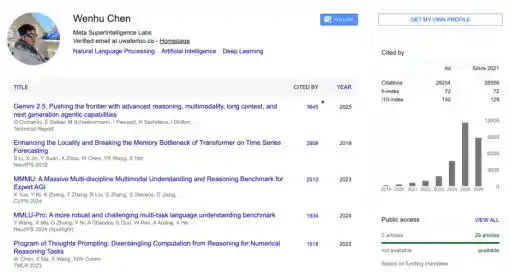
Dia adalah Asisten Profesor di Departemen Ilmu Komputer, Universitas Waterloo, Kanada. Di Google Scholar, makalahnya telah dikutip lebih dari 30.000 kali.
Dia juga pendiri "TIGERLab", singkatan dari Text and Image Generative Research Lab. Karena namanya mengandung karakter "Hu" (harimau), Chen Wenhu memberinya nama Mandarin yang sangat khas—Hutou Bang (Geng Harimau).
01
Setelah Soal Ujian Lama Kehilangan Fungsi
Chen Wenhu pertama kali lebih banyak diperhatikan karena MMLU-Pro.
MMLU dulunya adalah salah satu tolok ukur evaluasi kemampuan model bahasa besar yang paling umum digunakan. Ia seperti lembar ujian komprehensif, mencakup berbagai disiplin ilmu, digunakan untuk mengukur performa model dalam tugas pemahaman pengetahuan dan penalaran.
Di awal, lembar ujian ini sangat berguna. Jarak antar model bisa dibedakan oleh skor, dan industri juga bisa mengamati apakah model bahasa besar benar-benar berkembang.
Tapi masalah segera muncul.
Seiring kemampuan model terus meningkat, MMLU perlahan menjadi 'terlalu mudah untuk diuji'. Skor model terdepan semakin tinggi, perbedaan di antara mereka semakin kecil.
Saat OpenAI merilis o3, masalah ini menjadi lebih jelas. Akurasi o3 di MMLU sudah mendekati 100%, model terdepan lainnya juga satu per satu memberikan hasil yang mendekati nilai sempurna.
Ini terdengar seperti kabar baik, tapi untuk evaluasi, justru berarti masalah.
Sebuah soal ujian jika semua orang bisa mendapat nilai mendekati sempurna, akan sulit untuk terus menilai siapa yang lebih kuat, kuat di mana. Ia masih bisa membuktikan model sudah memiliki kemampuan tertentu, tapi tidak lagi cocok untuk mengukur kemajuan baru.
Industri AI membutuhkan soal ujian yang lebih sulit, dan lebih tidak mudah untuk 'dilewati dengan mudah'.
Pada tahun 2024, Chen Wenhu dan tim meluncurkan MMLU-Pro.
MMLU-Pro mendesain ulang soal ujian ini, bukan sekadar memperbesar bank soal.
Ia mencakup 12.032 soal, meliputi 14 bidang seperti matematika, fisika, kimia, hukum, teknik, psikologi, kesehatan. Dibandingkan MMLU versi asli, ia memperluas pilihan dari 4 menjadi 10, mengurangi kemungkinan model menebak dengan benar; sekaligus menambahkan lebih banyak soal penalaran, membersihkan soal-soal yang relatif sederhana, ambigu, atau kurang membedakan di bank soal asli.
Efeknya langsung.
Hasil penelitian menunjukkan, akurasi model di MMLU-Pro turun 16% hingga 33% dibandingkan MMLU asli. Model yang sama diuji dengan 24 gaya prompt berbeda, fluktuasi nilainya juga turun dari 4-5% di MMLU asli, menjadi sekitar 2%.
Artinya, lembar ujian baru ini tidak hanya lebih sulit, tapi juga lebih stabil.
Ia membuat model-model yang tampak sama-sama unggul di soal ujian lama, kembali terpisah jaraknya. Apakah model benar-benar bisa bernalar, atau hanya lebih pandai menghadapi soal lama, juga jadi lebih mudah terlihat.
02
Tolok Ukur yang Berguna
MMLU-Pro segera digunakan industri.
MMLU-Pro kemudian masuk ke jalur Dataset dan Tolok Ukur NeurIPS 2024, juga diintegrasikan ke dalam framework evaluasi model bahasa lm-evaluation-harness milik EleutherAI. Bagi komunitas model sumber terbuka, ini berarti ia bukan lagi sekadar dataset dalam sebuah makalah, tapi telah masuk ke rantai alat evaluasi yang umum digunakan.
Banyak model mulai melaporkan skor MMLU-Pro saat dirilis. Beberapa peringkat di HuggingFace juga memasukkannya ke dalam sistem evaluasi.
Jika MMLU-Pro menyelesaikan masalah 'soal ujian lama tidak berfungsi' dalam evaluasi model bahasa, maka MMMU mendorong Chen Wenhu dan TIGERLab ke pusat evaluasi multimodal.
Masalah model multimodal lebih kompleks.
Model bahasa menjawab soal, terutama menangani teks. Model multimodal harus menangani berbagai bentuk informasi secara bersamaan: gambar, bagan, diagram skematis, peta, tabel, partitur musik, struktur kimia. Ia tidak hanya harus memahami pertanyaan, tapi juga benar-benar mengerti isi gambar, dan melakukan penalaran dengan menggabungkan informasi visual, informasi teks, dan pengetahuan disiplin ilmu.
Tolok ukur MMMU berisi 11.500 soal multimodal, berasal dari ujian universitas, kuis, dan buku teks, mencakup enam bidang utama: Seni & Desain, Bisnis, Sains, Kesehatan & Kedokteran, Humaniora & Ilmu Sosial, Teknologi & Teknik, yang selanjutnya dibagi menjadi 30 disiplin ilmu dan 183 sub-bidang.
Soal-soal ini tidak sekadar menanyakan 'apa yang ada di gambar', ia menuntut model untuk menggabungkan informasi gambar dan pengetahuan disiplin ilmu seperti seorang siswa mengerjakan soal profesional.
Saat MMMU dirilis, tim peneliti menguji 14 model multimodal sumber terbuka, serta model tertutup perwakilan seperti GPT-4V, Gemini Ultra. Bahkan model tertutup terkuat saat itu, GPT-4V dan Gemini Ultra, hanya mencapai akurasi 56% dan 59%.
Angka-angka ini menunjukkan, model multimodal tampaknya berkembang cepat, tapi dalam soal yang benar-benar membutuhkan pemahaman profesional dan penalaran, masih ada banyak ruang untuk perbaikan.
Kemudian, tim Chen Wenhu meluncurkan MMMU-Pro, lebih jauh menutup ruang bagi model untuk menghindari informasi visual. Ia menyaring soal yang bisa dijawab hanya dengan model teks, memperluas pilihan jawaban, dan memperkenalkan pengaturan vision-only, menanamkan pertanyaan dalam gambar, menuntut model menyelesaikan pembacaan visual dan pemahaman teks secara bersamaan.
Sederhananya, tidak membiarkan model 'hanya membaca teks untuk menebak jawaban'.
Pekerjaan semacam ini terdengar agak rumit, tapi sangat krusial. Karena model multimodal di masa depan akan masuk ke skenario seperti kesehatan, pendidikan, penelitian, desain, teknik, hanya bisa mendeskripsikan gambar tidaklah cukup. Ia harus bisa menilai, bernalar, menjelaskan, dan juga harus bisa menemukan bagian yang benar-benar berguna dalam informasi visual yang kompleks.
03
Orang di Balik 'Soal Ujian'
Chen Wenhu kemudian mengerjakan MMLU-Pro dan MMMU, berasal dari minat penelitiannya yang sudah lama.

Minat penelitiannya memang berkaitan dengan pemahaman informasi kompleks, tanya jawab pengetahuan, dan penalaran.
Dia lulus sarjana dari Universitas Sains dan Teknologi Huazhong, kemudian melanjutkan magister di RWTH Aachen University, Jerman, lalu mendapatkan gelar Ph.D. Ilmu Komputer dari University of California, Santa Barbara. Selama masa doktoral, dia sudah mulai melakukan penelitian seputar tanya jawab kompleks, penalaran tabel, pelokalan bukti pengetahuan, dll.
Tugas-tugas semacam ini memiliki kesamaan: jawabannya seringkali tidak berada dalam satu teks tunggal.
Mungkin tersembunyi dalam sebuah tabel, mungkin perlu menggabungkan sebuah teks dan gambar, atau mungkin membutuhkan model untuk mencari informasi terlebih dahulu, lalu mengintegrasikan, menghitung, dan bernalar. Model tidak boleh hanya bisa mengulang pengetahuan yang sudah ada.
Proyek-proyek yang pernah diikuti Chen Wenhu seperti HybridQA, TabFact, Program of Thoughts, MAmmoTH, semuanya berhubungan dengan garis ini.
Ini juga menjelaskan mengapa dia sensitif terhadap celah dalam evaluasi model.
Tolok ukur yang baik bukan sekadar membuat soal semakin sulit, tapi harus memperkirakan di mana model paling mudah 'menebak soal dengan benar', 'tampak bisa'.
Model mungkin menghafal bank soal, bisa menebak jawaban berdasarkan pilihan, atau mungkin menggunakan teks untuk menghindari informasi visual... Evaluasi yang baik harus menambal celah-celah ini.
Setelah lulus doktoral, Chen Wenhu bergabung ke Google Research, kemudian dari 2021 hingga 2025 terlibat dalam pekerjaan model multimodal Gemini dan evaluasi di Google DeepMind. Pengalaman ini juga penting. Paparan jangka panjang terhadap pengembangan model terdepan membuatnya lebih memahami bagaimana kemampuan model tumbuh, dan juga lebih mudah melihat kemungkinan bias dan titik buta dalam evaluasi.
Musim gugur 2022, Chen Wenhu bergabung dengan Fakultas Ilmu Komputer Universitas Waterloo, menjabat sebagai Asisten Profesor. Tahun yang sama, dia terpilih sebagai Canada CIFAR AI Chair. Kemudian, dia mendirikan "TIGERLab (alias Hutou Bang)", melanjutkan penelitian seputar model dasar, kemampuan multimodal, dan tolok ukur evaluasi.
Hutou Bang tidak hanya membuat tolok ukur evaluasi, tapi juga melakukan penelitian model dan sistem.
Dalam arah video, UniVideo mencoba memasukkan pemahaman video, generasi, dan penyuntingan ke dalam satu framework yang sama, membuat model tidak hanya menghasilkan cuplikan gambar, tapi juga memahami konten, merespons instruksi, dan menyelesaikan modifikasi. Vamba menargetkan pemahaman video panjang, menyelesaikan masalah memori, komputasi, dan efisiensi pelatihan yang dibawa oleh video level satu jam. MoCha, kolaborasi dengan tim Generative AI Meta, fokus pada generasi karakter virtual yang berbicara, menghasilkan video karakter berkualitas tinggi melalui deskripsi suara dan teks.

Seorang pembuat soal yang tidak pernah mengerjakan soal, tidak mungkin bisa membuat soal yang baik. Turun tangan membuat model sendiri, sebaliknya juga membuat mereka lebih cocok melakukan evaluasi.
Karena evaluasi yang benar-benar baik, seringkali berasal dari pemahaman batas kemampuan model. Hanya dengan tahu bagaimana model dibuat, tahu masalah apa yang akan dihadapinya dalam tugas nyata, baru lebih mudah merancang soal yang bisa mengukur perbedaan, dan juga mengekspos masalah.
Saat ini, Chen Wenhu bergabung ke Meta Super Intelligent Lab, pekerjaan terus berkonsentrasi pada data pra-pelatihan multimodal dan evaluasi, dan melayani model dasar Meta.
Industri AI tidak kekurangan orang yang terlihat. Di industri AI, sorotan biasanya jatuh pada wirausahawan, peneliti bintang, dan pimpinan perusahaan model besar. Peluncuran produk baru, kabar pendanaan, model sumber terbuka, dan penyesuaian tim, seringkali paling mudah menarik perhatian luar, juga membuat nama-nama ini lebih mudah masuk ke pandangan publik.
Tapi di bidang AI hari ini, partisipasi talenta Tionghoa sudah jauh melampaui posisi yang paling terlihat ini.
Artikel ini berasal dari akun WeChat "Zimu AI", penulis: Xiao Jinya






