Thực hiện nghiên cứu công nghệ thực sự là một việc đầy cạm bẫy (dù cho là người hay AI), bởi từ lúc bắt đầu nghiên cứu, bạn sẽ tiếp nhận lượng thông tin khổng lồ, quan điểm thông tin ngày càng nhiều, kết luận ngày càng mơ hồ. Vì vậy, luôn phải biết quay về với mục tiêu ban đầu.
Đây cũng là điểm mà AI từ trước đến nay chưa đủ xuất sắc, bởi từ góc độ tập trung và liên tưởng, AI sẽ dễ bị mắc kẹt trong lượng thông tin hiện tại hơn con người, và khả năng liên tưởng xuyên ngành thực sự có giá trị rất yếu.
Tất nhiên, điểm đủ xuất sắc của AI chính là khả năng thực thi, sẽ dưới hình thức agent từng tầng một đi tìm kiếm, tổng hợp, kết luận, hoàn toàn có thể tránh được hao tổn chi tiết.
Mặc dù nửa năm nay tôi không mấy đăng bài công khai trên WeChat, nhưng hầu như tất cả các mặt trận chính trong ngành tôi đều có quan tâm và nghiên cứu toàn diện, và thứ hỗ trợ đầu vào đầu ra này, chính là một hệ thống deep-research của riêng tôi.
Và trước việc tuần trước Claude Code ra mắt tính năng Dynamic Workflows này, tôi muốn đối đầu thử xem, xem năng lực mặc định của nó, liệu có thể hoàn toàn vượt qua tôi hay không.
II. Dynamic Workflows là gì
Dynamic Workflows (Luồng công việc động) ý tưởng cốt lõi của nó là: Trước khi thực hiện nhiệm vụ, để AI tự động thiết kế nhiệm vụ này nên dùng luồng công việc nào để hoàn thành, sau đó mới khởi động thực thi.
Điều này khác biệt cơ bản với "Chế độ kế hoạch" và "skill" mà chúng ta từng dùng trước đây. Chế độ kế hoạch là chia nhỏ nhiệm vụ hơn, nhưng chưa chắc đã phù hợp với một luồng công việc hợp lý nào đó, theo sự sắp xếp của prompt của bạn, mới có thể thêm tiêu chí nghiệm thu (điều này rất quan trọng với Research), tương tự bạn chỉ khi có prompt, nó mới có thể thiết lập trước một số quy tắc harness tốt hơn.
Nhưng luồng công việc động sẽ tự động đưa logic nghiệm thu, hội tụ kết quả, xác minh đối kháng... những thứ này vào.
Cách kích hoạt rất đơn giản, trực tiếp trong cc sử dụng /deep-research sau đó cung cấp một số mẫu nghiên cứu và tài liệu đầu vào là được, nếu muốn dùng riêng năng lực luồng công việc động thì dùng prompt hoặc nói trực tiếp ultracode, lưu ý trước khi dùng, lượng token tiêu hao gấp khoảng vài chục lần bình thường.
III. Sáu chế độ luồng công việc tích hợp sẵn
Dưới đáy của luồng công việc động, là sáu chế độ điều phối cốt lõi do chính thức tổng kết, đây là lý do tại sao nó mạnh hơn đối thoại/agent/skill thông thường.
Thực ra đằng sau sáu chế độ này chỉ có hai vấn đề cốt lõi: Nhiệm vụ chia thế nào? Kết quả hợp thế nào? Chia thành sáu loại bản chất là sự kết hợp của hai cái này.
3.1 Chế độ định tuyến (Classify-And-Act)
Đầu tiên một agent phân loại nhiệm vụ, sau đó phân phối nhiệm vụ cho agent chuyên môn phù hợp nhất để làm. Logic cốt lõi là logic lựa chọn định tuyến, chứ không phải song song hay lặp lại. Một nhiệm vụ chỉ đi một đường, các đường khác hoàn toàn không thực thi.
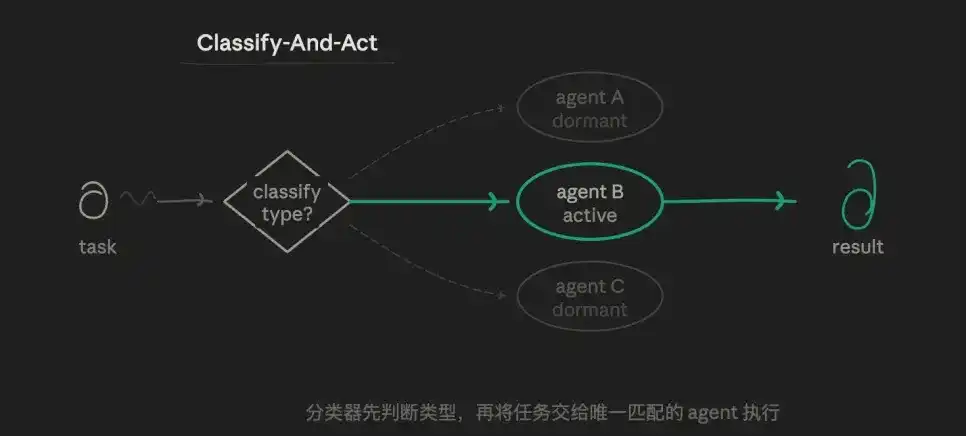
Ví dụ tôi có thể có ba vai trò subagent thiết lập trước: một agent phân tích nghiêm ngặt xác minh dữ liệu, một agent đầu ra giỏi viết, một agent thách thức chuyên tìm lỗ hổng. Để tầng định tuyến đánh giá nhiệm vụ con hiện tại phù hợp giao cho ai, chứ không để một agent ôm hết.
Giá trị của chế độ này nằm ở: Chính xác và tiết kiệm, prompt của mỗi agent có thể hoàn toàn độc lập, không bị nhiễu bởi mục tiêu khác, hình thành khám phá có chiều sâu chuyên môn. Lượng token tiêu hao thấp nhất, tốc độ phản hồi nhanh nhất. Ranh giới trách nhiệm rất rõ ràng.
Nhược điểm cũng rõ rệt, khả năng xử lý nhiệm vụ ranh giới mơ hồ (ví dụ "vừa là vấn đề kỹ thuật vừa là vấn đề tài khoản") yếu.
3.2 Chia nhỏ và hợp nhất (Fan-out & Merge)
Cũng là chế độ tôi hay dùng nhất, logic cốt lõi là song song + hợp nhất. Nhiệm vụ chia thành N nhiệm vụ con độc lập chạy đồng thời, đợi tất cả hoàn thành rồi hợp nhất thống nhất.
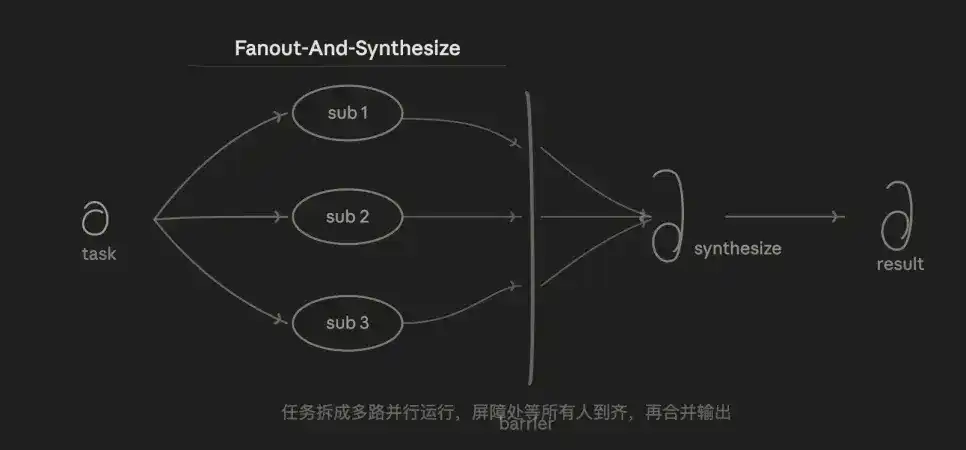
Ưu thế nằm ở tốc độ và cô lập. Tổng thời gian tiêu hao xấp xỉ bằng nhiệm vụ con chậm nhất, chứ không phải tổng của tất cả nhiệm vụ con. Mỗi nhiệm vụ con có context độc lập, không ảnh hưởng lẫn nhau, cũng không vì nhiễu của một nhiệm vụ con nào đó làm ô nhiễm nhiệm vụ con khác.
Điểm yếu là chi phí token gấp N lần so với tuần tự, bản thân tầng hợp nhất (Synthesize) cũng có độ khó - đầu ra cấu trúc không nhất quán của N đường hợp nhất thế nào là một thách thức thiết kế. Chia nhiệm vụ con không tốt sẽ dẫn đến bỏ sót hoặc phủ sóp trùng lặp.
3.3 Xác minh đối kháng (Adversarial Verification)
Logic cốt lõi là kiểm tra, đối với cùng một kết luận, để nhiều agent từ góc độ "bác bỏ" đi thách thức, số phiếu quá nửa mới tính là thông qua.
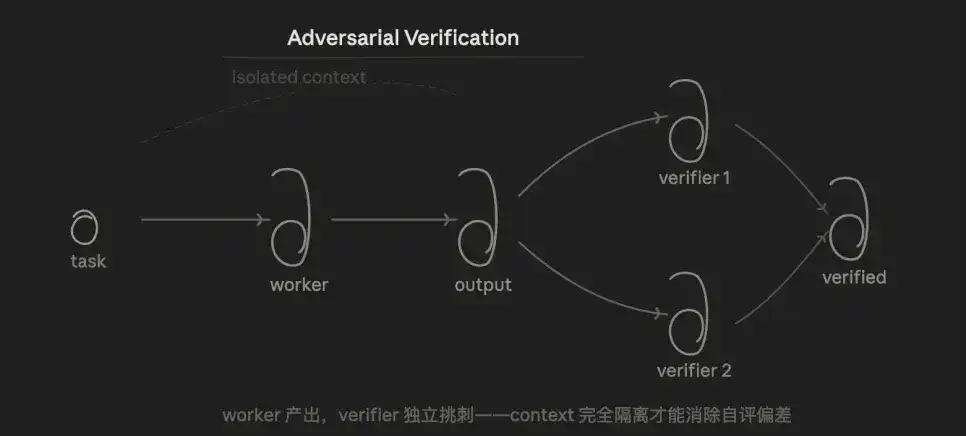
Ưu thế nằm ở, do Verifier không biết ý tưởng của Worker, chỉ xem kết quả, về cấu trúc đã loại bỏ độ lệch tự đánh giá khi "để mô hình kiểm tra code mình viết".
Chế độ này, giải quyết một vấn đề lâu nay làm tôi băn khoăn: Chúng ta thường dùng cách nói thông thường trò chuyện với AI, nhưng AI có xu hướng trả lời thuận theo kỳ vọng của bạn, dễ sản sinh "thiên kiến xác nhận". Thông qua xác minh đối kháng buộc AI đi tìm phản ví dụ, dựa trên dữ liệu và thực nghiệm để xác minh, chứ không phải chiều theo ý nghĩ của bạn.
Nhưng, việc xác minh này, nếu nó đưa ra phán đoán sai, sẽ dẫn Worker đi lệch, chiều theo Verifier. Vì vậy ưu tiên phải dựa trên sự thật có thể tái hiện, chứ không phải mượn quan điểm.
Nói đùa một chút, nếu bạn để AI tìm vấn đề, nó có thể tìm ra vô tận vấn đề, vì vậy bạn phải giới hạn biên giới tìm vấn đề của nó.
3.4 Tạo ra và lọc (Generate & Filter)
Logic cốt lõi là phát tán rồi hội tụ. Đầu tiên cố ý sản sinh ứng viên dư thừa, dùng rubric đào thải đến tinh hoa, chỉ giữ lại kết quả có độ tin cậy cao để xuất ra.
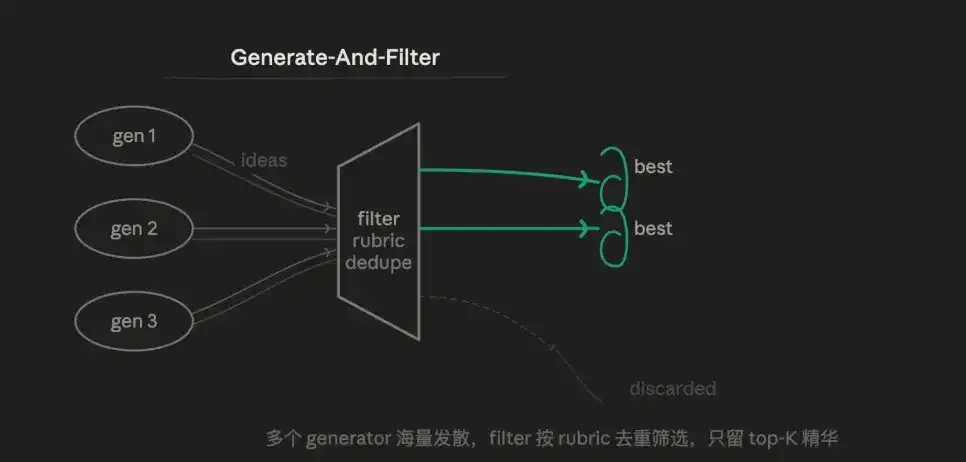
Thay vì để một agent xuất ra một đáp án "tạm được", không bằng để nó tạo ra mười cái, rồi dùng tầng xác minh sàng lọc. Vì vậy ưu thế nằm ở sự đa dạng. Nhiều Generator có thể dùng chiến lược khác nhau, prompt khác nhau, sản xuất cách giải mà con người khó lường trước, bước lọc khiến chất lượng đầu ra cuối cùng tập trung cao độ.
Điểm yếu là, chất lượng rubric của Filter quyết định trực tiếp hiệu quả cuối cùng, rubric thiết kế sai bằng với toàn bộ quy trình hỏng.
Kịch bản phù hợp là tình huống không biết trước đáp án chính xác, cần chọn ưu từ nhiều khả năng, có nhu cầu rõ ràng về đa dạng hóa.
Chỉ giống bề ngoài với Fanout-And-Synthesize: Cả hai đều là "đa tuyến song song → đầu ra đơn nhất", dễ nhầm lẫn nhất.
Khác biệt then chốt nằm ở ý đồ: Mỗi tuyến của Fanout xử lý phần khác nhau của nhiệm vụ, kết quả bổ sung cho nhau, khi hợp nhất tất cả tuyến đều có đóng góp; Mỗi tuyến của Generate-And-Filter xử lý cùng một nhiệm vụ, kết quả cạnh tranh với nhau, khi hợp nhất phần lớn bị loại bỏ. Cái trước là "ghép hình", cái sau là "chọn hoa hậu".
3.5 Chế độ giải đấu (Tournament)
Logic cốt lõi là đào thải cạnh tranh. N agent mỗi cái độc lập làm cùng một việc, thông qua so sánh pairwise loại dần từng vòng, cuối cùng chọn ra giải pháp tối ưu nhất.
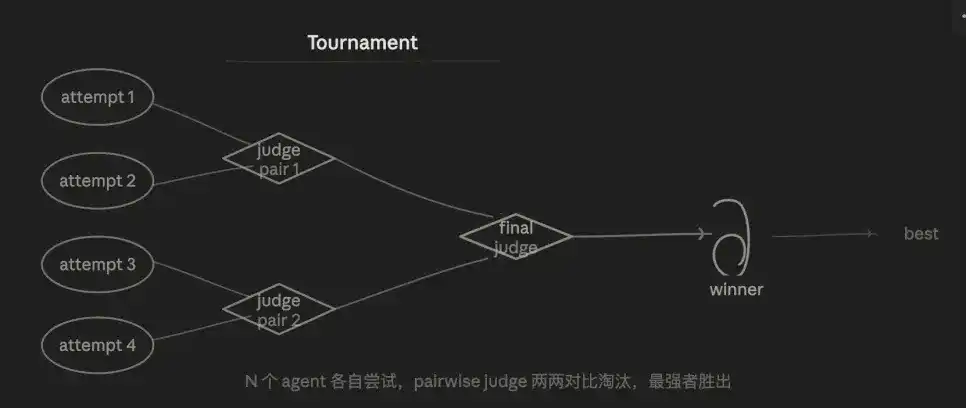
Cái này trước đây tôi từng làm thủ công - cùng một thay đổi code chạy hai ba phiên bản, rồi để AI so sánh cái nào tốt hơn. Bây giờ có thể trực tiếp sắp xếp vào trong luồng công việc.
Ưu thế nằm ở tính ổn định của phán đoán. So sánh cặp đôi ("A và B cái nào tốt hơn?") ổn định hơn nhiều so với chấm điểm tuyệt đối ("cho A chấm điểm"), bởi loại bỏ vấn đề trôi tiêu chuẩn chấm điểm. Kết quả trải qua cạnh tranh nhiều vòng, độ tin cậy của người chiến thắng cuối cùng cao.
Cũng chỉ giống bề ngoài với Generate-And-Filter: Cả hai đều là chọn ưu từ nhiều ứng viên. Khác biệt then chốt nằm ở cơ chế chọn ưu: Tournament dùng pairwise judge so sánh cặp đôi, là "để ứng viên cạnh tranh lẫn nhau". Khi rubric khó lượng hóa, phán đoán bản chất là tương đối, sẽ đáng tin cậy hơn.
3.6 Chế độ vòng lặp (Loop)
Logic cốt lõi là lặp lại thích ứng, liên tục thử, gặp trở lực thì thu thập thông tin lỗi, bổ sung ngữ cảnh, thử lại, cho đến khi thỏa điều kiện nghiệm thu thì thôi.
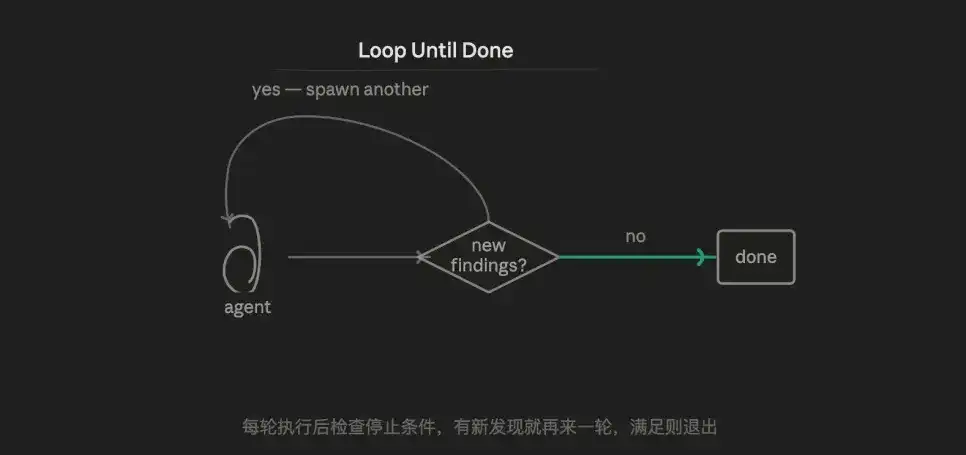
Bản chất là đang chống lại tính ngẫu nhiên của AI: thử nhiều lần, rồi sẽ gặp kết quả tốt hơn. Nhưng cách làm trưởng thành hơn là kết hợp xác minh đối kháng, để mỗi lần lặp đều mang thêm thông tin thực thi, chứ không phải chỉ dựa vào ngẫu nhiên.
Ưu thế nằm ở khả năng xử lý nhiệm vụ không biết trước khối lượng công việc. Năm chế độ còn lại đều giả định biên giới nhiệm vụ là xác định, Loop Until Done là chế độ duy nhất có thể xử lý "không biết phải làm bao nhiêu vòng".
Điểm yếu là nguy cơ mất kiểm soát tiềm ẩn - điều kiện dừng thiết kế không tốt sẽ lặp vô hạn. Agent mỗi vòng là context mới hoàn toàn, không thể tích lũy trạng thái xuyên vòng (trừ khi ghi rõ vào file).
IV. Skill của tôi và luồng công việc chính thức đối đầu
Trước khi luồng công việc động ra đời, tôi đã thiết kế riêng một bộ deep-research của mình. Logic của skill đó của tôi đại khái như thế này:
- Chỉ cung cấp một thông tin đơn giản (ví dụ một dự án mới lên chức năng nào đó)
- Để AI đi tìm kiếm tất cả tư liệu liên quan: tài liệu chính thức, mã nguồn, dư luận thị trường
- Nén thông tin thành bản tóm tắt có ý nghĩa
- Nhiều vai trò agent làm phân tích đối kháng, tạo báo cáo
- Tự động khử trùng lặp, bởi nội dung đa agent tỷ lệ trùng lặp cao
Dùng một thời gian, tôi thấy khá hay. Nhưng nó có một khuyết điểm căn bản: Thiếu sự hội tụ định hướng mục tiêu.
Và nhiều lúc dù có bước thứ năm khử trùng lặp, nhưng lúc này, nó thường xuyên xóa mất thông tin có giá trị, nếu không khử trùng lặp, lại đặc biệt dễ skill sẽ cho bạn một bài văn dài vạn chữ, thông tin rất đầy đủ, nhưng không trực tiếp nói cho bạn "việc này liên quan gì đến bạn, bạn nên làm thế nào".
Tuy nhiên, nghiên cứu là để phục vụ cho "quyết định", đây là lý do tại sao nhiều skill chỉ dừng lại ở bản thân nghiên cứu, có 80 điểm, nhưng thiếu 20 điểm then chốt nhất.
Đến nỗi AI sau khi hoàn thành sơ bộ nghiên cứu, còn cần tiếp tục suy nghĩ và đối thoại mười lần, mới đạt được kết luận chu toàn thỏa mãn.
Luồng công việc động chính thức làm thêm được gì
Thông qua thực nghiệm mấy lần nhiệm vụ nghiên cứu phức tạp tuần này, tôi phát hiện, luồng công việc deep research tích hợp sẵn trong Claude Code (lưu ý không chỉ là skill, mà là mô-đun biên dịch nhúng vào cc), so với trên cơ sở skill của tôi, có thêm mấy mắt xích then chốt:
- Tầng phân giải vấn đề: Nó sẽ không trực tiếp bắt đầu tìm kiếm, mà đầu tiên bắt đầu hỏi vấn đề, phân giải vấn đề của tôi thành nhiều vấn đề con: bạn thực sự muốn làm rõ cái gì? Việc này liên quan gì đến bạn? Những chiều nào đáng nghiên cứu sâu? Bước này trước đây tôi bỏ qua.
- Đánh giá độ tin cậy: Đánh giá khả năng bác bỏ đối với mỗi thông tin, tương tự điểm quyền uy trong SEO truyền thống - nguồn có đáng tin không? Số lần trích dẫn thế nào? Đây là mắt xích trước đây tôi chưa nghĩ đến phải thêm.
- Xóa chéo thay vì hợp nhất trung bình: Cách làm trước đây của tôi là chọn trung bình tất cả kết luận, vì vậy tài liệu rất lớn. Luồng công việc động sẽ đối với mỗi kết luận làm bỏ phiếu đa agent, số phiếu không đủ thì xóa, không phải hợp nhất đơn giản.
- Đầu ra định hướng mục tiêu: Báo cáo cuối cùng không phải chất đống thông tin, mà là xoay quanh mục tiêu ban đầu của bạn đưa ra phán đoán và phương án đề xuất. Mà then chốt thực hiện điểm này nằm ở năng lực thiết lập trước điều phối đa subagent của nó, lý do trước đây skill của tôi dễ thiếu định hướng mục tiêu cuối cùng, chính là vì sau lượng thông tin khổng lồ, suy giảm trọng số lệnh.
Những cơ chế này giải quyết vấn đề gì?
Nhắm vào chính mấy vấn đề điển hình của AI khi làm nhiệm vụ dài:
Trôi mục tiêu: Lúc bắt đầu nhiệm vụ trạng thái tốt, đến giữa thì không biết đang làm gì, lúc kết thúc lại tìm lại nhịp điệu - tương tự con người lơ đãng trong giờ học. Nhiệm vụ càng dài càng rõ.
Dừng sớm: Chạy chạy gặp khó khăn, AI tự cho là "hoàn thành" rồi dừng, thực ra tiêu chuẩn nghiệm thu căn bản chưa qua.
Ô nhiễm ngữ cảnh: Một agent đơn lẻ làm nhiệm vụ phức tạp, lượng prompt tiền trạp lớn sẽ nén không gian thực thi hậu kỳ. Cách tốt hơn là khống chế prompt tiền trạp trong vài k, dùng đa agent để phân bổ ngữ cảnh.
Thiên lệch đầu ra: AI có xu hướng trả lời thuận theo kỳ vọng của bạn, hỏi theo kiểu nói thông thường dễ kích hoạt vấn đề này hơn.
Mà luồng công việc động dùng cách thức cấu trúc hóa giải quyết bốn vấn đề này: Tự động thêm tiêu chí nghiệm thu ngăn ngừa dừng sớm; Song song cô lập ngữ cảnh; Xác minh đối kháng triệt tiêu thiên lệch đầu ra; Phân giải vấn đề tầng tầng ràng buộc AI hiểu mục tiêu trước rồi hành động.
V. Tổng kết
Cuối cùng, tác giả là người nghiên cứu lâu năm, thán phục cơ chế mới này của CC, sáu chế độ tích hợp sẵn của nó - lựa chọn định tuyến, chia nhỏ hợp nhất, xác minh đối kháng, tạo ra lọc, thi đấu giải đấu, vòng lặp Loop - bao phủ nhu cầu điều phối tuyệt đại đa số nhiệm vụ nghiên cứu phức tạp.
Khiến tôi không còn cần thiết kế thủ công điều phối agent, cũng không cần tự làm khử trùng lặp và xác minh chéo, những cái này đều được biên vào bản thân luồng công việc rồi.
Và nó đặc biệt phù hợp trong việc thiếu thông tin, tìm tòi vấn đề mở để suy nghĩ, bởi điều phối đa agent tự nhiên + phân chia mục tiêu nhiệm vụ, khiến nó nâng cao tính phổ dụng một lần nữa, thực ra từ 3 năm trước AI, đối với một ràng buộc tầng tầng, chỉ để nó giải quyết vấn đề nhỏ cực kỳ rõ ràng, đã làm rất tốt rồi, nhưng biến đổi chất lượng thực sự của AI vẫn là ở tính phổ dụng, điểm này đối thủ cạnh tranh của nó, từ code đơn giản trở thành Agent thực sự, từ giải quyết một vấn đề trạng thái rắn, đến thích ứng bất kỳ vấn đề nào.
Vì vậy Dynamic Workflows luồng công việc động không phải là "đối thoại một lần thông minh hơn", mà là bản thân quy trình nghiên cứu được cấu trúc hóa.
Vốn dĩ tôi cần phát động mười mấy lần đối thoại độc lập nghiên cứu, bây giờ nén xuống 3-4 lần. Mặc dù lượng Token tiêu hao tương ứng tăng trưởng vài chục lần rồi.
Vậy tại sao vẫn cần 3-4 lần? Tôi nghĩ căn nguyên nằm ở sự khác biệt của những nhu cầu này.
Thứ nhất là mức độ nghiêm khắc của cơ chế xác minh, tôi chủ yếu nghiên cứu công nghệ mới trên blockchain, nhiều việc, tài liệu chính thức đều chậm trễ, có dữ liệu mã nguồn mở đáng tham khảo hơn, giao dịch trên chain vân vân, mà hiện tại AI mặc định vẫn lấy tài liệu chính thức làm chuẩn, chứ không phải lấy xác minh tính sự thật làm chuẩn.
Thứ hai là suy nghĩ sâu hoàn toàn xuyên ngành, điểm này mặc dù thông qua thiết lập trước luồng công việc có thể giải quyết một phần (định nghĩa trước các subAgent chiều khác nhau) để suy nghĩ về cùng một vấn đề. Nhưng AI giỏi vẫn là mô hình suy nghĩ chủ lưu, đối với cái rất mới, rất sâu, thiếu căn cứ dữ liệu, thì hơi không đủ.
Thứ ba là thiết kế và xác minh giải pháp, ý nghĩa của giải pháp không nằm ở đề xuất mà nằm ở xác minh, hỗ trợ, nó dựa vào cân nhắc cơ chế hiện có, đầu tư và chi phí, nếu điều khiển AI tốt đương nhiên có thể làm tốt hơn, nhưng như vậy lại trái với tính phổ dụng rồi.
Cuối cùng là cô đặc thông tin cực hạn, đây lại cần quay về mức độ hiểu biết đối tượng tiếp nhận thông tin, có người hoàn toàn không có nền tảng, cần bạn biểu đạt theo kiểu hình tượng nhân hóa, mà có thính giả, cần bạn một câu đánh động anh ta~.





