Автор: Чжан Айла
Сегодня поговорим о перевалочных пунктах.
Проще говоря, перевалочный пункт для моделей — это когда модели OpenAI, Claude, Gemini, DeepSeek и другие подключаются к одному входу, позволяя разработчикам через один интерфейс, одну учетную запись и единый счет вызывать разные модели, а также выбирать, переключать и использовать резервные модели между разными моделями или поставщиками.
Конечно, для пользователей из Китая главная причина использования перевалочных пунктов — возможность задействовать зарубежные модели и дешевизна.
Это все и так понятно, о китайских перевалочных пунктах мы много говорить не будем, сегодня в основном поговорим об OpenRouter.

К 2026 году OpenRouter привлек $113 миллионов в раунде B, а оценка компании уже приблизилась к $13 миллиардам.
То есть это уже единорог.
Давайте разберем, почему «перевалочный пункт для моделей», который сам модели не создает, может стоить так много?
Чем же занимается OpenRouter?
OpenRouter официально позиционирует себя как: унифицированный интерфейс для больших моделей.
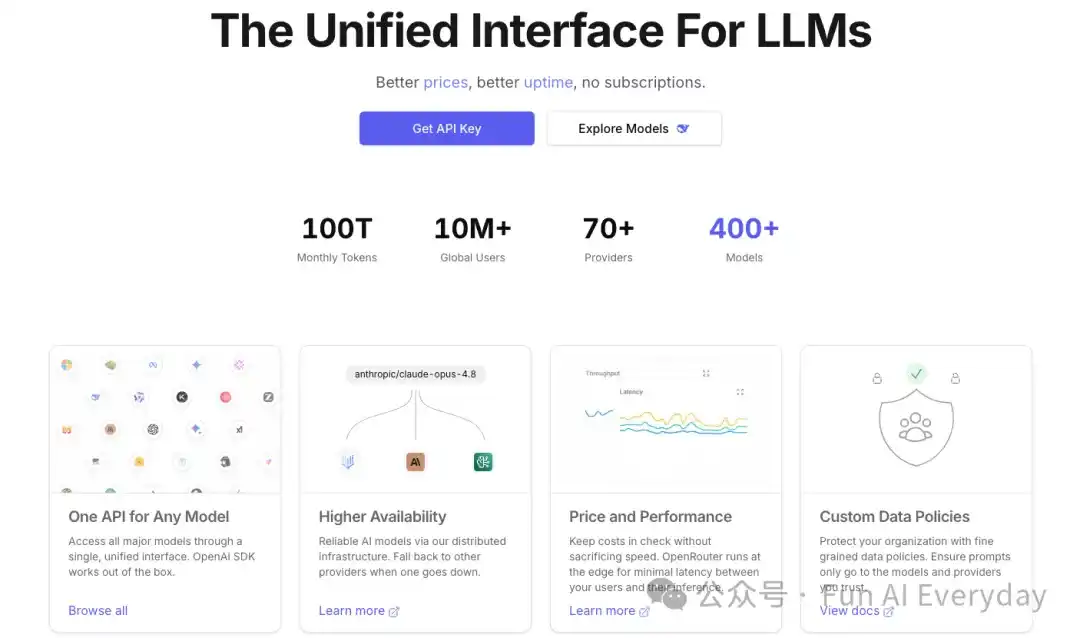
Сейчас OpenRouter поддерживает более 400 моделей от более чем 70 поставщиков.
На сайте также говорится, что платформа ежемесячно обрабатывает 100 триллионов токенов, а число пользователей по всему миру превышает 10 миллионов.
В сообщении о привлечении финансирования раунда B в мае 2026 года также упоминается, что за последние 6 месяцев еженедельный объем обработки OpenRouter вырос с 5 триллионов токенов до 25 триллионов токенов, а число обслуживаемых разработчиков достигло более 8 миллионов.
Эти цифры говорят об одном:
OpenRouter больше не маленький инструмент для разработчиков, а крупная точка входа для вызова ИИ.
Разработчики используют его тоже очень просто.
Раньше нужно было отдельно подключаться к OpenAI, Anthropic, Google, DeepSeek, Mistral, xAI и другим моделям.
Для каждой подключения нужно было изучать документацию, запрашивать API-ключ, привязывать счет, обрабатывать различия в интерфейсах, изучать правила ограничения скорости, реализовывать обработку ошибок.
С OpenRouter разработчики могут вызывать разные модели через один и тот же интерфейс.
Часто код, который раньше использовал интерфейс OpenAI, достаточно просто изменить базовый URL, заменить API-ключ и указать название модели, чтобы через OpenRouter вызывать другую модель.
Это также одна из причин его быстрого роста на раннем этапе: низкая стоимость миграции.
Почему разработчики не подключаются напрямую к компаниям-поставщикам моделей?
Кажется, что разработчики могут обойти OpenRouter и напрямую открыть API на сайте компании-поставщика модели.
Но в реальной разработке все не так просто.
Если продукт с ИИ — это просто демо, достаточно одной модели. Но как только дело доходит до реального бизнеса, сложно полагаться только на одну модель.
Например, в инструменте для написания текстов с ИИ может быть несколько разных задач:
- Для генерации заголовков достаточно дешевой модели;
- Для написания длинных статей нужны более сильные текстовые способности;
- Для анализа материалов нужна модель с длинным контекстом;
- Для модерации контента нужна низкая стоимость и высокая стабильность классификации;
- Корпоративные клиенты требуют, чтобы данные не сохранялись, поэтому нужно выбирать поставщиков с соответствующей политикой данных;
- В пиковые часы модель может ограничивать скорость, и тогда нужно автоматически переключаться на резервную модель.
В этом случае проблема уже не в «подключении одного API».
Команде нужно поддерживать целую систему вызова моделей:
какая модель за какую задачу отвечает, какая модель дешевле, какой поставщик работает быстрее, у какого поставщика ниже процент сбоев, как переключиться при проблемах, как распределять счета, как изолировать данные корпоративных клиентов.
Еще сложнее то, что рынок моделей меняется слишком быстро.
Сегодня Claude хорошо пишет код, завтра Gemini может иметь преимущество в длинном контексте, послезавтра DeepSeek или какая-нибудь открытая модель снизит цены.
Возможности моделей, цены, длина контекста, политики поставщиков постоянно меняются.
Вот в чем ценность OpenRouter.
Он не пишет за разработчиков приложения с ИИ, а помогает им управлять процессом выбора модели, вызова, резервирования и контроля затрат.
Не просто супермаркет моделей, а слой оркестрации моделей
Если понимать OpenRouter только как «супермаркет моделей», это будет недооценкой.
Супермаркет моделей решает задачу «здесь много моделей, выбирай».
Но настоящая важная способность OpenRouter — это оркестрация между моделями и поставщиками.
Одна и та же модель может предоставляться разными поставщиками для инференса.
Например, открытую модель могут размещать несколько облачных провайдеров или поставщиков услуг инференса. Цены, скорость, стабильность у разных поставщиков разные.
В документации OpenRouter есть функция под названием provider routing, или маршрутизация поставщиков.
Разработчики могут настраивать автоматическую отправку запросов разным поставщикам в зависимости от цены, задержки, пропускной способности, порядка поставщиков и других условий.
Он также поддерживает fallback, то есть автоматическое переключение системы на резервный вариант, если какая-то модель или поставщик выйдут из строя.
Для разработчиков OpenRouter выносит «выбор модели» и «обработку сбоев» из бизнес-кода в отдельную платформу.
Зачем предприятиям нужен этот слой?
Когда предприятия внедряют ИИ, начальная проблема часто заключается в «возможности использования», но очень быстро она превращается в «управление».
Внутри одной компании может быть много команд, использующих ИИ.
Маркетинговая команда использует для создания контента, команда поддержки — для ответов пользователям, команда разработчиков — для написания кода, операционная команда — для анализа данных, юридическая команда — для обработки контрактов.
Если каждая команда подключает модели самостоятельно, проблем становится все больше:
- Счета сложно разделить; выбор моделей не унифицирован;
- Политика данных не прозрачна; разные команды подключаются повторно;
- При возникновении проблем никто не знает, какой именно вызов вызвал ошибку;
- Если меняется поставщик моделей, систему сложно единообразно адаптировать.
Рабочие пространства, контроль бюджета, журналы вызовов, стратегии поставщиков, маршрутизация с нулевым хранением данных, которые предоставляет OpenRouter, как раз решают эти проблемы.
Например, нулевое хранение данных.
Для многих предприятий не все запросы можно отправлять любому поставщику моделей. Информация о клиентах, содержание контрактов, медицинские данные, финансовые данные могут иметь строгие требования.
В документации OpenRouter поддерживается Zero Data Retention, то есть нулевое хранение данных.
Разработчики могут настроить отправку запросов только поставщикам, которые не хранят данные. Эта стратегия может применяться глобально, для групп моделей, по правилам безопасности или для отдельных запросов.
Еще пример — prompt caching, то есть кэширование промптов.
Многие приложения с ИИ многократно используют длинные системные промпты, содержимое базы знаний или контекст. Если каждый раз пересчитывать, стоимость будет высокой.
OpenRouter поддерживает повышение попаданий в кэш с помощью маршрутизации с привязкой к поставщику, стараясь направлять последующие запросы на одну и ту же конечную точку поставщика, тем самым снижая стоимость повторного контекста.
Такие функции могут звучать не так захватывающе, но они очень практичны, и чем больше масштаб приложения с ИИ, тем очевиднее экономия.
Как OpenRouter зарабатывает деньги?
Бизнес-модель OpenRouter понятна: зарабатывает на объеме использования.
Разработчики сначала покупают кредиты на платформе, а затем платят за фактически вызванные модели и токены.
OpenRouter официально четко пишет:
Платформа взимает комиссию 5,5% при покупке кредитов, минимум $0,8; цены поставщиков базовых моделей передаются пользователям по первоначальной цене, без дополнительной наценки на цену инференса модели.
Это классический бизнес «платы за проезд трафика».
Преимущество этой модели в том, что доход привязан к объему использования.
Чем больше разработчики вызывают, тем выше доход платформы; чем больше приложений с ИИ и чем больше потребляется токенов, тем больше бизнес OpenRouter.
Но у нее есть и особенность: комиссия за одну транзакцию невысока, поэтому нужно полагаться на масштаб.
Вот почему объем обработки токенов так важен для OpenRouter.
Его ключевой показатель — не число зарегистрированных пользователей, а сколько токенов проходит через него еженедельно и ежемесячно.
В 2025 году годовой объем обработки OpenRouter вырос примерно с 10 триллионов токенов до более чем 100 триллионов токенов.
К 2026 году OpenRouter уже достиг годового объема обработки около 1,5 квадриллионов токенов.
В этом и заключается основная логика этого бизнеса.
Пока все больше приложений с ИИ работают на многомодельных системах, OpenRouter может продолжать взимать плату за обслуживание с этих вызовов.
Почему в последнее время рост такой быстрый?
Рост OpenRouter, в целом, обусловлен тремя изменениями.
Первое изменение — моделей становится все больше.
Раньше, создавая приложение с ИИ, многие команды по умолчанию сначала использовали OpenAI. Сейчас все иначе.
Claude, Gemini, DeepSeek, Qwen, Mistral, Llama, Grok, а также множество открытых моделей имеют преимущества в разных сценариях.
Это не рынок, где кто-то полностью заменяет другого.
Одна модель хорошо пишет код, другая дешевле, у третьей сильный длинный текст, четвертая быстрая, пятая подходит для ролевых игр, шестая для корпоративных документов, седьмая для многомодальности.
Чем больше моделей, тем выше стоимость выбора; чем выше стоимость выбора, тем ценнее промежуточный слой.
Второе изменение — приложения с ИИ начинают заботиться о затратах.
Многие продукты на раннем этапе используют самую сильную модель, потому что сначала нужно добиться результата.
Но как только у продукта появляются пользователи, стоимость моделей быстро становится проблемой.
Чат-бот поддержки, продукт для поиска с ИИ, помощник по коду, инструмент для генерации контента — если все запросы идут через самую дорогую модель, маржа легко может быть съедена.
Более зрелый подход — разделить задачи:
- Простые задачи выполнять дешевыми моделями;
- Сложные задачи — сильными моделями;
- Для частых задач отдавать предпочтение моделям с низкой задержкой;
- При сбое переключаться на резервную модель;
- При работе с конфиденциальными данными использовать только поставщиков, соответствующих политике данных.
Это именно тот сценарий, где нужен OpenRouter.
Он не обязательно найдет «самую сильную модель», но может помочь сбалансировать результат, цену, скорость и стабильность.
Третье изменение — приложения с ИИ эволюционируют от чат-окна к агентам.
Агенты вызывают инструменты, читают файлы, ищут в интернете, выполняют задачи, а также многократно и последовательно вызывают модели.
По сравнению с обычным чатом, агенты потребляют больше токенов и больше зависят от стабильности.
Для OpenRouter это хорошо.
Потому что чем больше вызовов и чем длиннее цепочка, тем больше разработчикам нужны маршрутизация, резервирование, журналы, контроль затрат и управление поставщиками.
Вот почему в сообщении о финансировании OpenRouter подчеркивается, что ИИ переходит от экспериментов к критически важным производственным приложениям и сценариям с агентами.
Его рост по сути обусловлен увеличением объема вызовов ИИ.
У этого бизнеса тоже есть риски
Позиция OpenRouter хороша, но не безопасна.
Он находится между компаниями-поставщиками моделей, облачными провайдерами и разработчиками приложений. Такая позиция ценна, но и уязвима для давления.
Первый риск — крупные компании могут создать собственное решение.
Для небольших команд OpenRouter очень удобен.
Но для крупных предприятий маршрутизацию моделей, управление доступом, журналы, контроль затрат тоже можно сделать самостоятельно или поручить облачным провайдерам.
Особенно клиенты из финансового, медицинского, государственного секторов могут больше заботиться о контроле данных и приватном развертывании.
Чтобы привлечь таких клиентов, OpenRouter не может полагаться только на «много моделей». Ему необходимо углубленно развивать управление доступом, аудит, политику данных, управление поставщиками и корпоративную поддержку.
Второй риск — облачные провайдеры также могут делать шлюзы для моделей.
AWS, Google Cloud, Azure и другие облачные платформы уже имеют корпоративных клиентов, системы биллинга, управления доступом и соответствия требованиям.
Они вполне могут сделать многомодельный вызов, маршрутизацию, мониторинг и управление затратами частью облачных услуг.
Преимущество OpenRouter — открытость и нейтральность, широкий охват моделей, быстрая интеграция.
Но преимущество облачных провайдеров — отношения с клиентами и корпоративные процессы закупок, это долгосрочная конкуренция.
Третий риск — отношения с поставщиками моделей.
OpenRouter приносит трафик компаниям-поставщикам моделей, но также отдаляет их от конечных разработчиков.
Когда платформа становится больше, она получает больше информации об отношениях с пользователями и данных об использовании моделей.
Поставщики моделей, с одной стороны, хотят получить дистрибуцию, но с другой — могут опасаться ослабления своей переговорной позиции.
Такие промежуточные платформы на раннем этапе обычно приветствуются поставщиками; по мере роста масштаба отношения становятся более тонкими.
Четвертый риск — плата за платформу может быть снижена.
Сейчас 5,5% комиссии OpenRouter кажется невысокой.
Но если подобных услуг станет больше, разработчики будут сравнивать цены, стабильность, охват моделей и корпоративные функции.
Если некоторые конкуренты предложат более низкие тарифы, или облачные провайдеры включат такие возможности в существующие услуги, OpenRouter придется доказывать, что он не просто «ретранслятор запросов».
Он должен постоянно предоставлять лучшую маршрутизацию, более широкий охват моделей, более прозрачные цены, более стабильный сервис и более полный корпоративный контроль.








