Последнее десятилетие основным путём усиления ИИ был один путь: вкладывать больше данных и вычислительных мощностей в более крупные модели, позволяя опыту оседать в параметрах нейронных сетей. Этот путь привёл к скачку больших моделей после ChatGPT, но также оставил после себя проблему: модели становятся всё сильнее, но почему они успешны или терпят неудачу, во многих случаях всё ещё трудно объяснить и исправить.
Недавние эксперименты инженера OpenAI Вэн Цзяи предложили другую возможность: в условиях чёткой цели, работоспособной среды и замкнутого цикла обратной связи ИИ может становиться сильнее не только через обучение модели, но и через «самостоятельное изменение кода».
8 мая 2026 года Вэн Цзяи систематически описал эту серию экспериментов в своём личном блоге «Learning Beyond Gradients», одновременно опубликовав репозиторий кода, CSV-логи экспериментов и видео-записи. Он давно специализируется на инфраструктуре обучения с подкреплением и посттренинга, участвовал в первоначальном запуске ChatGPT и работал над проектами GPT-4, GPT-4 Turbo, GPT-4o, o-series, GPT-5 и другими. До прихода в OpenAI он получил степень бакалавра в области компьютерных наук в Университете Цинхуа, степень магистра в Университете Карнеги-Меллона, а также является основным автором библиотеки обучения с подкреплением с открытым исходным кодом Tianshou и высокопроизводительного параллельного движка среды EnvPool.

Изображение сгенерировано ИИ
Он заставил Codex многократно писать стратегический код, запускать среду, считывать логи, просматривать записи, выявлять ошибки, затем изменять код, дополнять тесты и продолжать оценку. После нескольких итераций Codex «вырастил» набор чисто программных стратегий на Python: достиг теоретического максимального результата в 864 балла в Atari Breakout, а в симуляторах робототехники, таких как MuJoCo Ant и HalfCheetah, также показал результаты, близкие к типичным алгоритмам глубокого обучения с подкреплением.
Истинная важность этих экспериментов заключается в одном ключевом вопросе: когда coding agent достаточно силён, должно ли обучение обязательно происходить в весах нейронной сети?
В этой серии экспериментов опыт записывался в код, тесты, логи и записи, превращаясь в программную систему, которую можно читать, изменять, проверять и аудировать. Если это направление продолжит развиваться, следующим шагом для Agentic AI может быть не просто обучение более крупных моделей, но и вовлечение моделей в поддержку постоянно эволюционирующей инженерной системы.
01
Замкнутый инженерный цикл от 387 баллов до максимального результата
Вэн Цзяи написал в блоге, что отправной точкой этого эксперимента была инженерная потребность. В своё свободное время он поддерживал EnvPool, и ему нужен был более дешёвый способ, чем «каждый раз запускать нейронную сеть», чтобы проверять правильность работы игровой среды, так как внедрение нейронной сети в CI было слишком затратным. Исходный вопрос: можно ли написать дешёвые, воспроизводимые, явно сильнее случайных, эвристические правила, чтобы привести среду к информационно-богатым состояниям?

Он попробовал с помощью Codex (базовая модель gpt-5.4) написать полностью основанную на правилах версию. Первоначальный промпт был очень прямолинейным: «Напиши стратегию, способную решить Breakout». Результат оказался неудовлетворительным. Низкий балл сам по себе не предоставил никакой информации: например, могла быть ошибочной семантика действий, обнаружение состояний, процесс оценки или структура стратегии могла быть слишком слабой.
Затем Вэн Цзяи изменил форму задачи. Он больше не требовал от Codex предоставить готовый policy.py, а потребовал поддерживать целый цикл: обнаружение действий и наблюдений, написание детектора состояний, написание стратегии, прогон полного эпизода, запись trials.jsonl и summary.csv, генерацию видео или графиков, проверку паттернов неудач, модификацию стратегии, упрощение кода, прогон регрессионных тестов.
Журнал экспериментов по Breakout очень чётко фиксирует этот процесс. В первом раунде Codex сначала подтвердил пространство действий и форму наблюдений, идентифицировал цвета мяча, ракетки и кирпичей из RGB-кадров, затем использовал метки изображений для сканирования 128-байтной памяти Atari RAM. Исходный baseline набрал только 99 баллов. После добавления логики смещения туннеля результат вырос до 387 баллов.
387 баллов — это локально высокий результат, который может ввести в заблуждение. Стратегия уже могла стабильно отбивать мяч, но траектория мяча застревала в периодическом цикле: жизни не терялись, но новые кирпичи не бились, и счёт застывал. Если бы писал код человек, можно было бы продолжать тонко настраивать «точность отбивания». Codex, просмотрев видео и последние десятки шагов траектории, определил проблему как недостаток возмущений в траектории мяча.
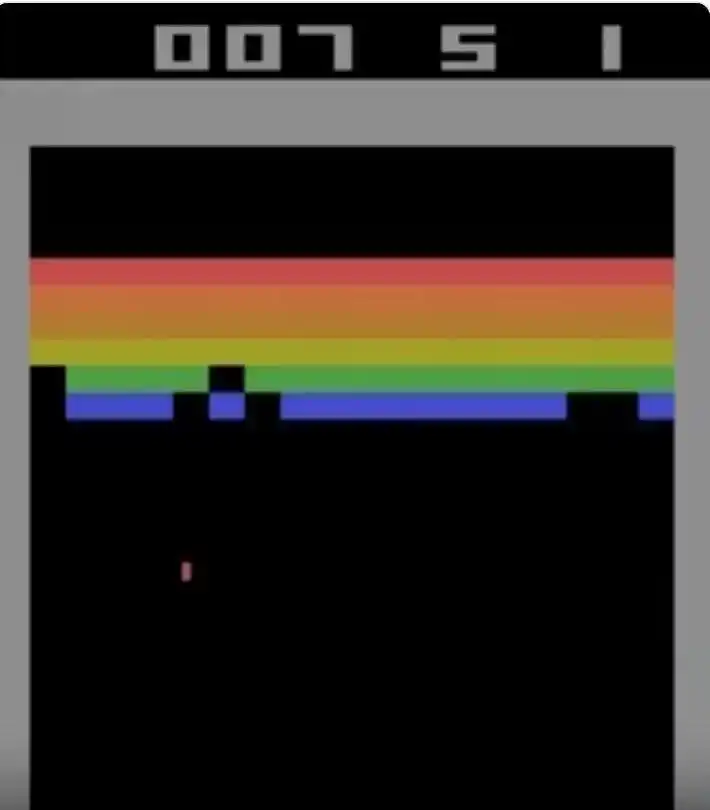
Рис.: Игровой экран Atari Breakout. Игрок контролирует нижнюю ракетку, чтобы отбивать мяч и последовательно разрушать разноцветные стены кирпичей сверху. Codex достиг в этой игре теоретического максимума в 864 балла.
Затем Codex добавил механизм «разрыва цикла»: если награда долго не поступает, периодически добавлять смещение к прогнозу точки падения, чтобы выбить мяч из локального цикла. Счёт подскочил с 387 до 507. При дальнейших итерациях возникла новая проблема: для быстрых низких мячей обычный перехват заставлял ракетку «чрезмерно опережать» и уходить в сторону. Codex добавил параметр fast_low_ball_lead_steps=3, и счёт вырос с 507 до 839. Последнее улучшение с 839 до 864 было больше похоже на поддержку уже усложнившейся системы: пробовались deadband, смещение при подаче, смещение застревания, смещение баланса кирпичей, шаги предвидения; многие направления не сработали, а полезным изменением оказалось условие на поздней стадии: «После разрушения первой стены кирпичей, смещение застревания включается только когда мяч далеко от ракетки, а при приближении мяча постепенно отпускается».
Финальная конфигурация на основе RAM стабильно выдавала 864 / 864 / 864 балла за три эпизода, достигнув теоретического предела в Breakout. Затем Codex мигрировал тот же геометрический контроллер на версию с чистым изображением — без чтения RAM, только с идентификацией ракетки, мяча и баланса кирпичей через RGB-сегментацию. Визуальная версия впервые набрала 310 баллов, затем 428, а после седьмого локального эпизода достигла 864 баллов, что соответствует 14504 шагам среды локальной стратегии.
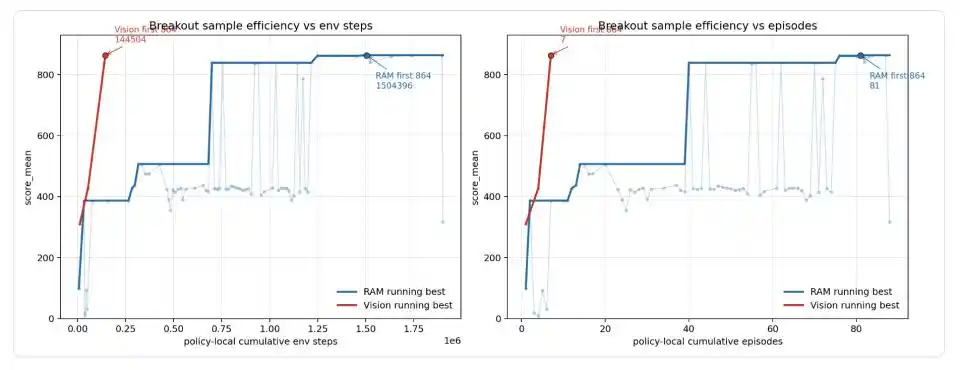
Рис.: Кривая эффективности выборок Codex в Breakout. Синяя линия — версия, читающая память игры (RAM), красная — версия, работающая только с экранным изображением (Vision). Версия RAM прошла через несколько скачков 99 → 387 → 507 → 839 → 864, впервые достигнув максимума на 81-м эпизоде, после накопления 1.5 миллионов шагов среды; версия Vision, благодаря переносу устоявшейся структуры из RAM версии, достигла 864 баллов всего за 7 эпизодов и около 14.5 тысяч шагов среды.
Вэн Цзяи особо подчеркнул, что это не следует понимать как «визуальный ввод с нуля за 14.5K шагов достиг максимума». Реальный процесс заключался в том, что Codex сначала обнаружил геометрический контроллер, разрыв цикла и освобождение смещения на поздней стадии в RAM-версии, и только после стабилизации структуры переключил слой считывания состояний с RAM на RGB. 14.5K — это бюджет миграции для визуальной версии.
02
Определение Heuristic Learning
Придумать название для этой постоянно эволюционирующей «программной стратегии» оказалось сложнее, чем написать её первую версию. Вэн Цзяи в итоге назвал этот процесс Heuristic Learning (HL, эвристическое обучение), а поддерживаемый им объект — Heuristic System (HS, эвристическая система).
Согласно его определению в блоге, HL состоит из программного кода и, как и современное глубокое обучение с подкреплением, имеет цикл состояний, действий, обратной связи и обновления. Отличие в том, что обновляемый объект — это программная структура, а не параметры нейронной сети; его обратная связь переваривается coding agent и может поступать из вознаграждений среды, тестовых случаев, логов, видео, записей или обратной связи от человека; его обновление не использует обратное распространение, а заключается в прямом редактировании агентом кода стратегии, детекторов состояний, тестов, конфигураций или памяти.
Стоит добавить, что концепция «использования программ вместо нейронных сетей в качестве стратегии» не является первоначальным изобретением Вэн Цзяи. В академических кругах уже много лет обсуждается Programmatic RL (программное обучение с подкреплением): в 2019 году Rice University и Caltech предложили фреймворк PROPEL, изучающий методы обучения с подкреплением, представляющие стратегию как короткие программы на символьном языке; работа LEAPS 2021 года продвинулась дальше в изучении пространства встраивания программ, сочетая дифференцируемые программные стратегии с обучением RL; HPRL на ICML 2023 предложила иерархическое программное обучение с подкреплением, где мета-стратегия комбинирует несколько программ; а фреймворк LLM-GS 2024 года от NTU и Microsoft использует программирующие способности и здравый смысл LLM для направления поиска программных стратегий RL.
Консенсус этих исследований заключается в том, что по сравнению с нейронными стратегиями, программные стратегии обладают лучшей интерпретируемостью, возможностью формальной верификации и способностью к обобщению на невиданные сценарии.
Существенный вклад Вэн Цзяи в этот раз заключается в рассмотрении coding agent как инженерного канала для поддержки эвристической системы. Раньше при работе с программным RL либо полагались на специально разработанные предметно-ориентированные языки, либо на алгоритмы поиска в ограниченном пространстве программ; Вэн Цзяи же, используя Codex, включил код, логи, тесты, видео-записи, настройку параметров в единый рабочий процесс агента, что позволило разово снизить стоимость итераций программной стратегии. Другими словами, он обосновывает новый инженерный путь: когда coding agent достаточно силён, те эвристические стратегии, которые раньше считались «слишком дорогими в поддержке», могут снова стать экономически выгодными.
Вэн Цзяи в блоге привёл сравнительную таблицу, чётко показывающую разницу между HL и Deep RL: в форме стратегии — это правила, конечные автоматы, контроллеры, MPC, макродействия, составляющие код, против параметров нейронной сети; в форме состояния — это явные переменные, детекторы и кэши против вектора наблюдений, читаемого сетью; в форме обратной связи — это тесты, логи, записи, рассматриваемые как эффективные сигналы, против в основном фиксированной функции вознаграждения; в форме памяти — это явное хранение испытаний, сводок, причин неудач и версионных diff, против (в on-policy алгоритмах) в основном отсутствия или (в off-policy) reliance on replay buffer.
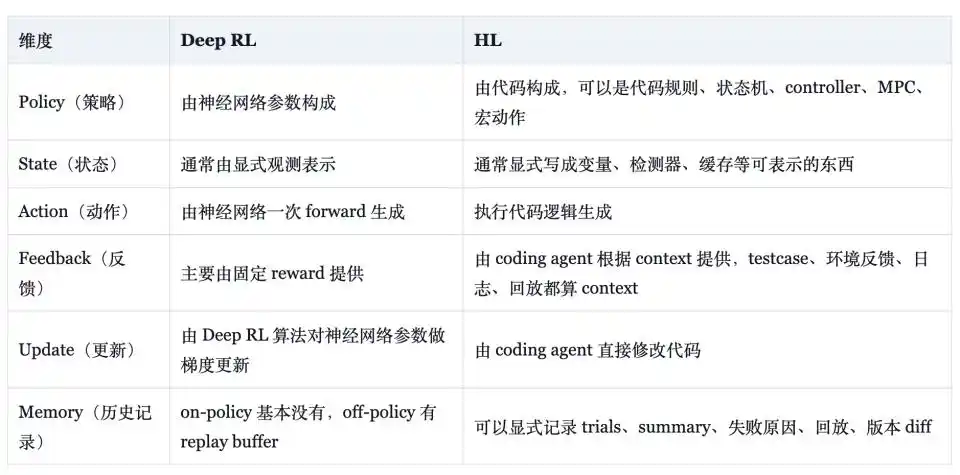
Это сравнение доказывает, что HL обладает некоторыми свойствами с инженерной точки зрения: стратегия интерпретируема, может быть переведена на естественный язык; эффективность использования выборок измеряется в «одном эффективном изменении кода», а не в медленных градиентных обновлениях; старые способности могут превращаться в регрессионные тесты, записи с фиксированным сидом или «золотые» кейсы; переобучение на тренировочные сиды или уязвимости тестов может быть ограничено упрощением, регрессионной проверкой и оценкой на множестве сидов; старые способности могут сохраняться не только в весах, но и в наборах правил и тестах, что частично решает давнюю проблему катастрофического забывания в нейронных сетях.
03
Пакетная проверка на Atari57: границы и слабые места
Если рассматривать только Breakout, историю легко упростить до «ИИ написал идеальную стратегию». Но Вэн Цзяи не остановился на Breakout; он расширил этот рабочий процесс Codex до Atari57, запустив 57 игр, два режима наблюдения, три повторения — всего 342 траектории поиска «без присмотра».
Дизайн эксперимента был довольно строгим. Каждая игра тестировалась двумя способами ввода: один — прямое чтение памяти игры, другой — только просмотр экрана. Каждый способ независимо повторялся три раза. Таким образом, было получено 342 траектории экспериментов «без присмотра»: каждый агент Codex получал один и тот же шаблон промпта, сам исследовал действия, сам писал код, сам запускал эксперименты, сам записывал результаты, без подсказок со стороны. Ограничения были прописаны жёстко: запрещено обучать нейронные сети, запрещено читать исходный код игр, запрещено использовать любую скрытую информацию, все шаги, использованные для отладки и проб, должны учитываться в общих затратах. Это было сделано, чтобы предотвратить любой способ «подсмотреть ответ» со стороны Codex.
При оценке результатов обычно используется показатель HNS (Human-Normalized Score, нормированный на человека балл) — проще говоря, это стандартизация балла каждой игры по принципу «средний уровень игрока-человека = 1» для удобства горизонтального сравнения между играми.
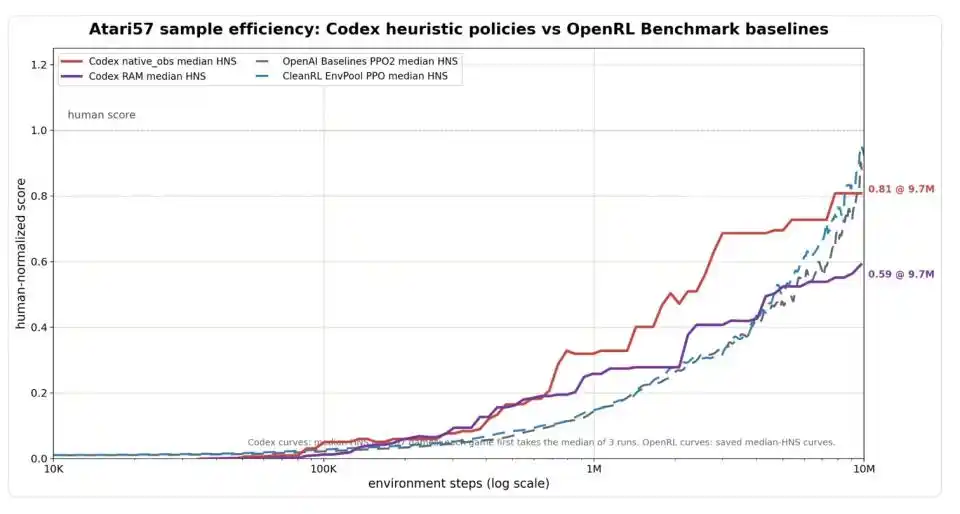
Рис.: Сравнение эффективности выборок на полном наборе Atari57. По горизонтали — шаги среды (логарифмическая шкала), по вертикали — HNS (нормированный на человека балл, 1.0 означает достижение среднего уровня игрока-человека). Версия Codex с визуальным вводом (красная линия) на начальном этапе явно опережает базовый уровень PPO (синяя/серая пунктирные линии), достигая 0.81 к 9.7 миллионам шагов, что близко к уровню PPO около 10 миллионов шагов; версия Codex с вводом из памяти (фиолетовая линия) сходится к 0.59.
По этому стандарту Codex показал впечатляющую эффективность на раннем этапе. Потратив всего 1 миллион шагов среды, медианный HNS для Codex с визуальным вводом достиг 0.32, а с вводом из памяти — 0.26, что значительно выше уровня классических алгоритмов обучения с подкреплением, таких как PPO, в тот же период. К 9.7 миллионам шагов версия Codex с визуальным вводом достигла 0.81, приблизившись к уровню PPO около 0.88–0.92 на 10 миллионах шагов. Если разрешить для каждой игры выбрать лучший из двух способов ввода Codex и агрегировать их, медианный HNS для Codex составил 0.83, для OpenAI Baselines PPO2 — 0.80, для CleanRL EnvPool PPO — 0.98 — по сути, ничья.
Но сам Вэн Цзяи довольно холодно очертил границу: это лишь сравнение эффективности взаимодействия со средой, без учёта затрат Codex на чтение логов, написание кода, просмотр видео. «Быстрый прогон» не равен «низкой общей стоимости», последняя пока остаётся чёрным ящиком.
Более пристального внимания заслуживает неравномерность результатов Codex в 57 играх. В играх с чёткой геометрической структурой, таких как Breakout, Boxing, Krull, и эвристические стратегии, и глубокое обучение с подкреплением явно превосходят человеческий уровень; в играх с чёткими правилами, таких как Asterix, Jamesbond, Tennis, эвристические стратегии даже сильнее; но в быстрых, сложных по паттернам играх, таких как Atlantis, VideoPinball, RoadRunner, StarGunner, PPO по-прежнему доминирует.

Наиболее показательным контрпримером является Montezuma’s Revenge. Это известная «крепкая задача» в области обучения с подкреплением, где герою нужно искать ключи, избегать врагов, открывать двери в запутанных подземельях, а сигналы вознаграждения чрезвычайно редки — классическая проблема «долгосрочного планирования + восстановления после неудачи». Codex действительно набрал в этой игре 400 баллов, но если открыть сгенерированный им файл стратегии, становится ясно, что это не настоящая «стратегия», а жёстко закодированная последовательность из 86 действий, соответствующая 1769 шагам среды: больше похоже на заучивание фиксированного маршрута, чем на обучение прохождению лабиринта. Вэн Цзяи особо отметил: «Это пограничный случай, и его не следует понимать как универсальную стратегию для Montezuma».
Montezuma раскрывает предел выразительной способности Heuristic Learning. Обычная программная стратегия по сути является реактивной логикой «вижу состояние — делаю действие», и ей трудно справляться с задачами, требующими строгой временной последовательности действий, продолжения плана из промежуточного состояния, долгосрочного планирования. Для таких задач нужны не просто дополнительные if-else, а программные структуры, более близкие к «комбинации макродействий + восстанавливаемое состояние поиска + долговременная память». Это показывает нам одну вещь: как бы ни был силён coding agent, некоторые проблемы просто не умещаются в обычный код.
04
Если парадигма устоит, каковы будут последствия для индустрии?
Вернёмся к промышленности. Если путь Heuristic Learning действительно окажется жизнеспособным, то есть «coding agent сможет стабильно поддерживать программные стратегии, превосходящие ручные правила и приближающиеся к базовым уровням RL», где будет его практическое значение?
Первая точка приложения — управление роботами, особенно в сценариях со относительно стабильной структурой. Вэн Цзяи в блоге предложил идею иерархического разделения: HL на уровне суставов, HL на уровне конечностей, HL баланса всего тела, HL на уровне задач. Низкий уровень занимается безопасностью и управлением с низкой задержкой, средний — походкой и контактом, высокий — задачами и долговременной памятью; coding agent не обязательно «понимает ходьбу», он больше похож на канал обновления, встроенный в систему, который возвращает в систему видео неудач, потоки датчиков, результаты симуляций, а затем переписывает обратную связь в код, параметры, защитные правила и память.
В сценариях со складскими AGV, инспекционными роботами, промышленными манипуляторами, стандартизированной сортировкой, где структура среды относительно фиксирована, а границы безопасности чётко определены, если ключевые управляющие стратегии могут быть зафиксированы в виде лёгкого кода, каждое действие робота не будет требовать запуска большой сети стратегий, снизится зависимость развёртывания от высокомощных GPU-карт для вывода, и больше нагрузки перейдёт на традиционные контроллеры и локальную программную логику.
Это не означает, что роботам не нужны GPU; восприятие, локализация, картографирование, семантическое понимание по-прежнему будут требовать нейронных сетей. Изменяется роль GPU: с «сжигания вычислительной мощности каждую секунду для сквозного принятия решений о действиях» на «периодическое использование при восприятии, офлайн-симуляции, генерации стратегий, анализе аномалий».
Вторая точка приложения — возможность аудита в критически важных для безопасности сценариях. Самой сложной инженерной проблемой нейронных стратегий является невозможность локализовать проблему после её возникновения. Если манипулятор внезапно даёт сбой под определённым углом, если автомобиль ошибочно оценивает какой-то граничный сценарий, если медицинский робот действует аномально в какой-то редкой позе, инженеры не могут ответить на вопрос «какой вес вызвал эту ошибку», и в итоге остаётся только дополнять данные, переобучать, проводить регрессионные тесты и надеяться, что новая модель не внесёт новых проблем.
Если стратегия существует в виде кода, переменные состояния, условные ветвления, логи неудач и регрессионные тесты становятся видимыми; определённое опасное действие можно жёстко запретить, corner case можно записать в тест, конкретный ошибочный переход состояний можно отдельно исправить. Это не делает систему изначально более безопасной, но впервые позволяет проблемам безопасности войти в нормальный процесс разработки программного обеспечения — они могут проходить code review, быть перехвачены CI, обрабатываться SRE. В таких областях, как автономное вождение, промышленные манипуляторы, медицинские роботы, где требуется регулирование и разделение ответственности, сама возможность аудита представляет коммерческую ценность.
Третья точка приложения — инженерное воплощение непрерывного и онлайн-обучения. Вэн Цзяи в блоге выдвинул это как основную линию аргументации всей статьи. Катастрофическое забывание в нейронных сетях — это структурная проблема: при изучении нового старое забывается. HL также подвержено забыванию, но в более инженерной форме: новое правило исправляет одну ошибку, но ломает старый сценарий; новая память постоянно направляет агента по неверному пути; слишком узкий диапазон теста приводит к тому, что стратегия учится его использовать; патч меняет общий интерфейс, и старые пути вызова незаметно перестают работать.
Эти проблемы не исчезают автоматически, но все они — проблемы, с которыми программная инженерия справляется уже десятилетиями, и для них существуют готовые инструменты — регрессионные тесты, версионные diff, записи с фиксированным сидом, golden trace, явно записанные причины неудач.
Здоровая HS должна одновременно выполнять две операции: усваивать новую обратную связь и сжимать исторические патчи; HS, которая только растёт, в конечном итоге превратится в «кодовую кашу», которую никто не осмелится трогать. Иными словами, HL преобразует математическую задачу «как обновлять параметры» в инженерную задачу «как поддерживать программную систему, постоянно поглощающую обратную связь».
Последняя задача не обязательно проще, но она ближе к существующим границам человеческих возможностей.
Четвёртая точка приложения — накопление способностей в продуктах-агентах. Сегодня продуктам-агентам больше всего не хватает стабильности вызова инструментов, надёжности цепочек выполнения, повторно используемого опыта неудач и поддающихся аудиту записей задач. Если логика HL окажется верной, память агента в процессе выполнения будет осаждаться в виде программных активов, которые можно использовать повторно между сессиями, пользователями и задачами. Это позволит напрямую интегрировать их в существующие процессы DevOps, а также означает, что агенты разных компаний и команд смогут обмениваться эвристиками, не делясь моделями, что невозможно при использовании нейросетевых решений.
Однако важно подчеркнуть: все четыре перечисленные точки зависят от дальнейшей проверки пути HL на более сложных задачах. Breakout и Ant — это относительно чистые среды; реальные роботы сталкиваются с изменениями трения поверхности, освещения, задержек исполнительных механизмов, шума датчиков — всё это ещё не было систематически оценено в открытых материалах. Контрпример с Montezuma уже показал, что задачи, требующие долгосрочного планирования, нуждаются в программных формах, выходящих за рамки обычных if-else. Насколько далеко может зайти эта концепция, покажут эксперименты следующего этапа.
05
Технический долг переносится с весов на код
Суд Вэн Цзяи в блоге довольно сдержан. Он пишет, что HL не может выполнять всё, что могут нейронные сети; она ограничена тем, что может выразить код, особенно в сложном восприятии и долгосрочном обобщении. По сегодняшним представлениям, он не может представить себе агента, который решает ImageNet с использованием чистого кода на Python, без помощи каких-либо нейронных сетей. Действительно стоящий для обсуждения вопрос — как объединить нейронные сети и HL для совместной обработки Online Learning и Continual Learning.
Предложенное им разделение обязанностей использует терминологию System 1 / System 2: специализированные неглубокие нейронные сети берут на себя часть System 1, отвечая за быстрое восприятие, классификацию и оценку состояния объектов; HL также берёт на себя часть System 1, отвечая за обработку свежих данных, правила, тесты, записи, память, границы безопасности и локальное восстановление; LLM agent выступает в роли System 2, предоставляя обратную связь HL, улучшая данные и периодически извлекая информацию из данных, генерируемых HL, для обновления самого себя.
Если глубокое обучение за последнее десятилетие доказало, что «опыт можно сжать в веса», то гипотеза, предложенная Вэн Цзяи в этот раз, представляет собой иное утверждение: в эпоху coding agent опыт, возможно, снова может стать читаемым, изменяемым, тестируемым программным обеспечением.
Эта статья взята с официального аккаунта WeChat «Tencent Technology», автор: Сяо Цзин, редактор: Сюй Цинъян








