
Представьте сценарий: вы просите трёх ИИ-ассистентов совместно решить математическую задачу.
Традиционный подход таков — первый ИИ «записывает» ход решения, второй ИИ «читает» его и записывает новые соображения, третий ИИ снова «читает» и «записывает».
Этот процесс напоминает трёх человек, по очереди передающих информацию по рации, каждый раз переводя мысли в слова, а собеседник снова переводящий слова обратно в мысли. Медленно? Да. Затратно? Да. Что ещё хуже, этот процесс «перевода» теряет информацию — то, что вы думаете, и то, что вы говорите, часто не одно и то же.
Это и есть основная проблема, с которой сталкиваются современные многоагентные ИИ-системы: «языковой налог».
А недавно UIUC, Стэнфорд, Nvidia, MIT совместно предложили новый подход — RecursiveMAS. Он позволяет ИИ пропустить шаг «говорения» и общаться напрямую «мыслями». В реальных тестах скорость рассуждений увеличилась в 2.4 раза, а потребление токенов сократилось на 75%.
(Ссылка на исследование: https://arxiv.org/abs/2604.25917)
Проблема совещаний ИИ: эффективность тратится на «разговоры»
За последние два года многоагентные системы стали одним из самых популярных направлений исследований в области ИИ. От Swarm от OpenAI до AutoGen от Microsoft, от LangGraph до CrewAI — все исследуют, как заставить несколько ИИ работать совместно для решения сложных задач, непосильных одной модели. Однако в этих системах эффективность совместной работы множества агентов всегда ограничивалась базовым предположением — агенты должны общаться посредством текста на естественном языке.
Когда вы заставляете «эксперта по математике» и «ревьювера кода» сотрудничать, весь процесс выглядит «разумным», но при детальном разборе обнаруживается много проблем:
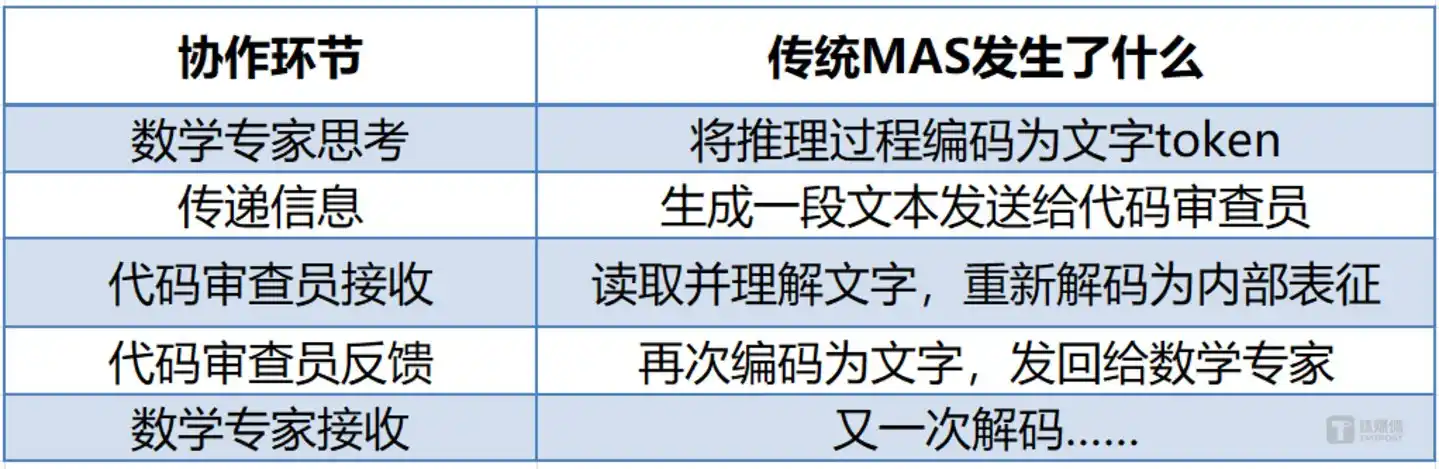
Каждая передача информации сопровождается двойным преобразованием: внутренняя мысль → текст → внутренняя мысль. Этот процесс потребляет токены, которые являются не только деньгами, но и драгоценными вычислительными ресурсами и временем. Что ещё важнее, процесс «записать, а потом прочитать» теряет информацию — богатая семантика, сжатая моделью в текст при декодировании, не может быть полностью восстановлена следующей моделью при повторном декодировании. В рабочем процессе, включающем пять агентов, временные затраты на текстовое кодирование/декодирование часто составляют более 60% от общей задержки.
Ещё больше раздражает, что в этой парадигме постоянно не хватает чёткого «регулятора» для системной оптимизации — добавить больше агентов? Предельная полезность снижается, а коммуникационные издержки растут экспоненциально. Увеличить контекстное окно? Стоимость токенов взрывается. Увеличить параметры модели? Отдельный агент становится сильнее, но эффективность совместной работы не повышается качественно — подобно тому, как выдать группе людей лучшие рации, но они всё равно будут по очереди зачитывать текст. Способ общения не изменился, и даже если каждый стал умнее, общая эффективность не может получить прорывного роста. Отраслевые решения, будь то инженерия промптов или тонкая настройка LoRA, могут лишь частично смягчить симптомы, но не излечить эту фундаментальную архитектурную проблему.
RecursiveMAS: Замена «рации» на «телепатию»
Основная идея RecursiveMAS очень изящна: раз язык — это узкое место, значит, не будем его использовать.
Она заимствует идею рекурсивной языковой модели (Recursive Language Model). В традиционных языковых моделях данные линейно движутся от первого слоя к последнему, больше слоёв — больше параметров; рекурсивная языковая модель действует наоборот — не увеличивает количество слоёв, а повторно использует один и тот же набор слоёв, заставляя данные «циркулировать» между слоями. Каждый раз, когда данные проходят через этот набор слоёв, это эквивалентно дополнительному раунду «размышлений», глубина рассуждений углубляется, но количество параметров не нужно увеличивать.
RecursiveMAS расширяет эту идею с «внутри одной модели» до «многоагентной системы»:
Каждый агент подобен слою в рекурсивной языковой модели, они больше не генерируют текст, а передают «мысли» — непрерывные векторные представления, существующие в латентном пространстве (latent space).
Исследователи используют поэтичную метафору: «агенты общаются телепатически как единое целое».
Конкретно, агент A1 обрабатывает данные и передаёт своё скрытое представление агенту A2, A2 обрабатывает и передаёт A3... пока последний агент не завершит обработку, и его скрытый вывод напрямую передаётся обратно A1, запуская новый раунд рекурсивной итерации. Весь процесс полностью происходит в латентном пространстве, и только последний агент в последнем раунде декодирует итоговое скрытое представление в текстовый вывод. Это как если бы группа экспертов сидела за столом, не разговаривая, не записывая заметки, каждый просто молча думал, а затем напрямую передавал «результат мысли» в голове следующему человеку — весь процесс тихий и эффективный.
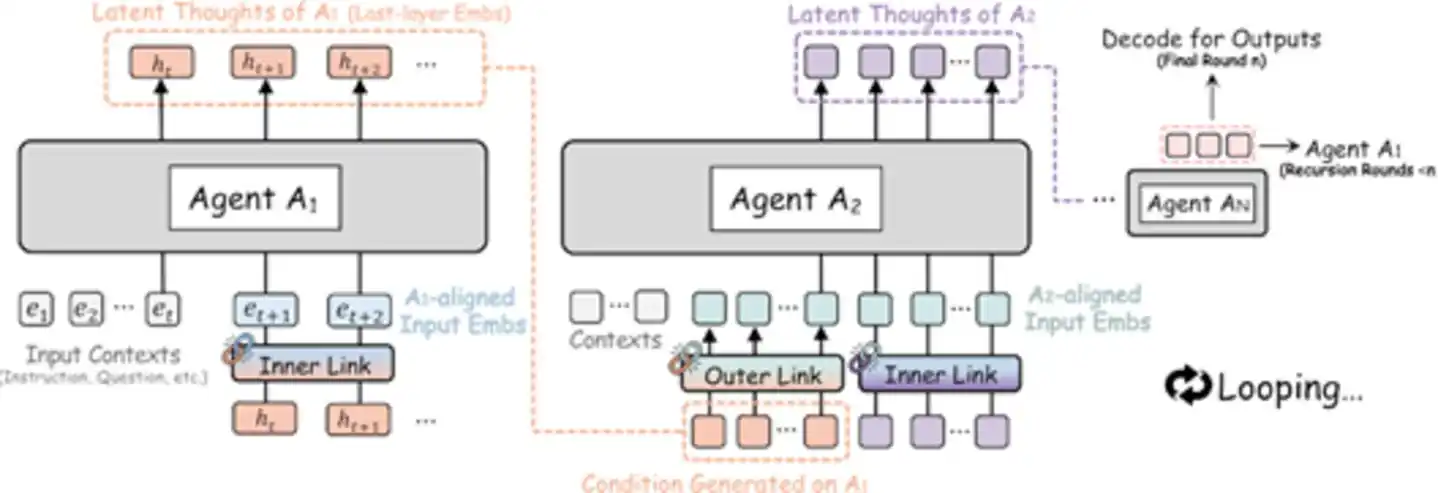
Рис.: Схема архитектуры RecursiveMAS — множество агентов реализуют замкнутую рекурсивную коллаборацию через пространство эмбеддингов (источник: arXiv)
Ключевой компонент этой системы называется RecursiveLink, лёгкий двухслойный остаточный модуль, отвечающий за сохранение и преобразование скрытого представления одного слоя модели и его передачу в пространство эмбеддингов следующей модели. Скрытое состояние последнего слоя языковой модели уже кодирует богатую семантическую информацию для рассуждений. Задача RecursiveLink — полностью «перенести» эту высокоразмерную информацию, а не сначала перевести в текст и затем интерпретировать. Он имеет внутреннюю и внешнюю версии:

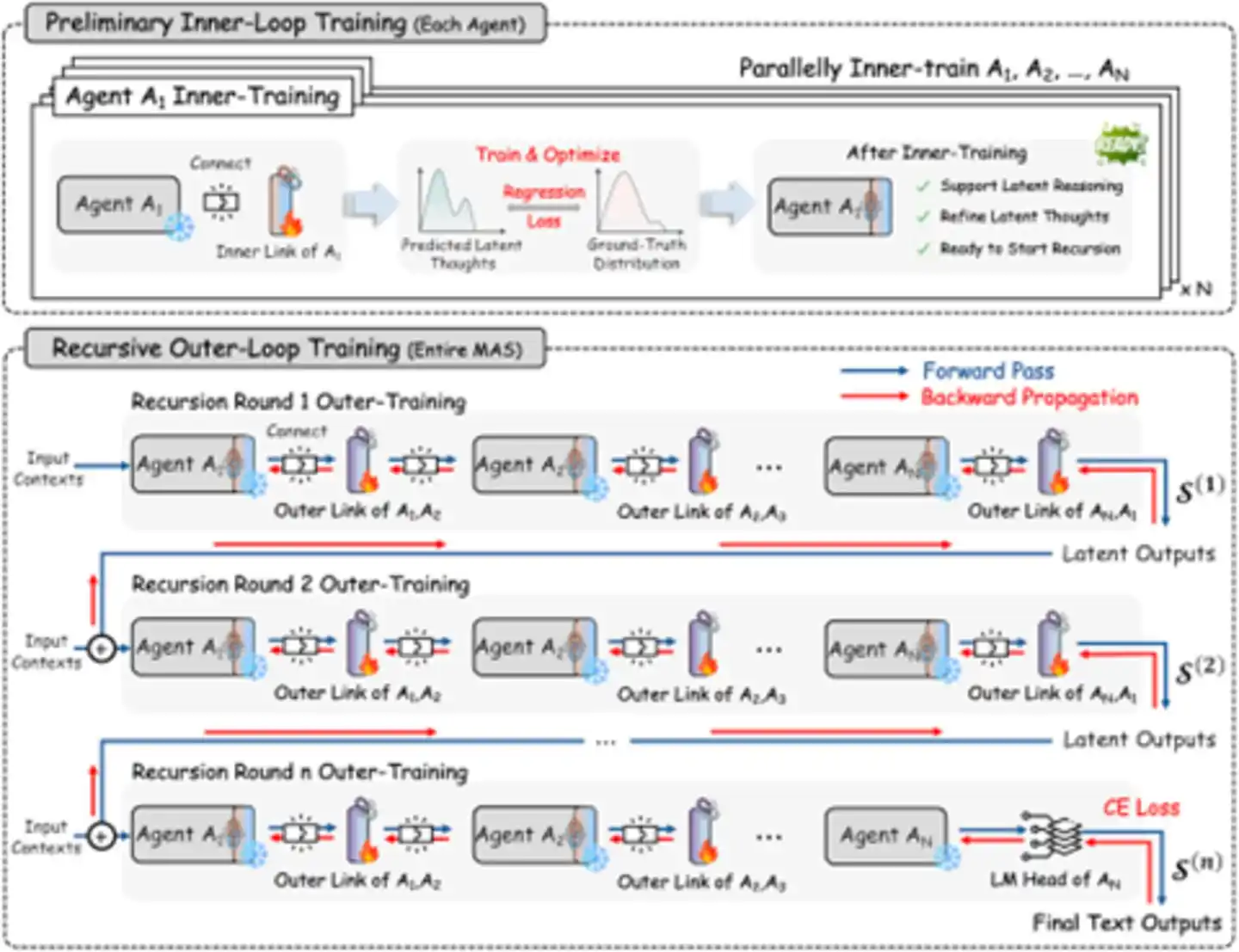
Рис.: Процесс рекурсивного обучения — совместное обучение внутренних и внешних связей (источник: arXiv)
В стратегии обучения RecursiveMAS есть изящный дизайн: веса основной модели полностью заморожены, нужно обучать только модуль RecursiveLink. Это перекликается с идеей LoRA (Low-Rank Adaptation), но RecursiveLink ещё легче: вся система требует обновления всего около 13 миллионов параметров, что составляет лишь 0.31% от общего числа обучаемых параметров. Пиковая потребность в видеопамяти GPU самая низкая среди всех сравниваемых методов, стоимость обучения снижается более чем на 50% по сравнению с полной тонкой настройкой. Можно представить его как «лёгкий переходник», который вставляется в существующую экосистему агентов без необходимости обучать модель с нуля. Если несколько агентов основаны на одной базовой модели (например, все используют Qwen), они могут даже совместно использовать одни и те же веса модели, дополнительно экономя память.
Обучение проводится в два этапа:
Разминка внутреннего цикла: Каждый агент независимо обучает свой внутренний RecursiveLink, чтобы научиться «думать о проблеме» в латентном пространстве, а не «записывать проблему». Этот этап можно выполнять параллельно, подобно тому, как каждый сначала практикует «внутренний монолог».
Обучение внешнего цикла: Все агенты соединяются в полную рекурсивную цепочку, оптимизируются все RecursiveLink с помощью совместных градиентов, цель — качество итогового текстового вывода. Этот этап решает проблему «распределения заслуг» — как точно отнести успех или неудачу конечного результата к вкладу каждого агента. Такая поэтапная стратегия избегает проблем с нестабильностью обучения, которые могут возникнуть при «одномоментном» подходе.
Исследователи теоретически доказали, что градиенты при рекурсивном обучении остаются стабильными, не возникает проблем взрыва или исчезновения градиентов, характерных для RNN, а также сложность выполнения превосходит традиционные текстовые MAS.
Результаты тестов: «тройной удар» по точности, скорости, стоимости
Какой бы хорошей ни была теория, всё решают данные. Команда исследователей провела всестороннюю оценку на 9 основных бенчмарках, охватывающих математику, науку и медицину, генерацию кода, поисковые вопросы и ответы, и в 4 режимах коллаборации (последовательные рассуждения, смесь экспертов, дистилляция знаний, согласованный вызов инструментов). Для экспериментов использовался впечатляющий набор открытых моделей — Qwen, Llama-3, Gemma3, Mistral, которым были назначены разные роли, формируя различные режимы совместной работы.
Сравнительная база тоже сильная: тонкая настройка LoRA, полная тонкая настройка (SFT), Mixture-of-Agents, TextGrad, LoopLM, а также Recursive-TextMAS, использующая ту же рекурсивную циклическую структуру, но с принудительной текстовой коммуникацией. Последнее контрольное сравнение особенно важно — оно доказывает, что преимущество RecursiveMAS действительно связано с «пропуском текстового декодирования», а не с самой рекурсивной структурой. Все сравнения проводились при одинаковом бюджете на обучение, честно и справедливо.
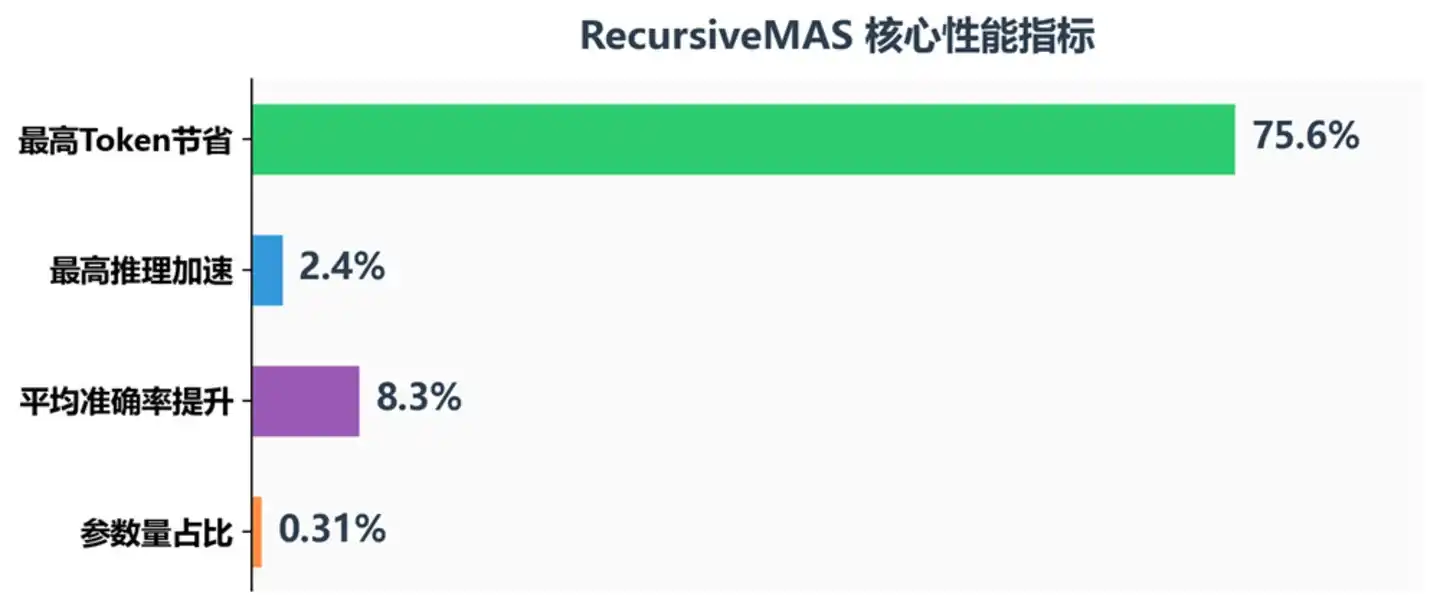
Ключевые показатели производительности RecursiveMAS
Результаты показали, что RecursiveMAS обеспечил последовательное улучшение по всем показателям:
Точность: Средняя точность увеличилась на 8.3%, на математическом соревновании AIME2025 превысила TextGrad на 18.1%, на AIME2026 — на 13%. Пропуск текстового декодирования не только не привёл к потере информации, но и позволил моделям сохранить более богатую семантику скрытых слоёв — в конце концов, потеря информации при сжатии мысли в текст и последующей распаковке гораздо больше, чем мы думаем.
Скорость: Скорость сквозного вывода увеличилась в 1.2–2.4 раза, причём рост продолжается с увеличением числа рекурсивных раундов. Это имеет большое значение для реальных сценариев применения: в системах ИИ-поддержки или код-ассистентах, требующих ответа в реальном времени, увеличение скорости более чем в 2 раза означает качественный скачок в пользовательском опыте.
Стоимость: По сравнению с Recursive-TextMAS потребление токенов снизилось на 34.6%–75.6%. Это не просто экономия затрат, это означает возможность попытки более глубоких рассуждений при том же бюджете на токены.
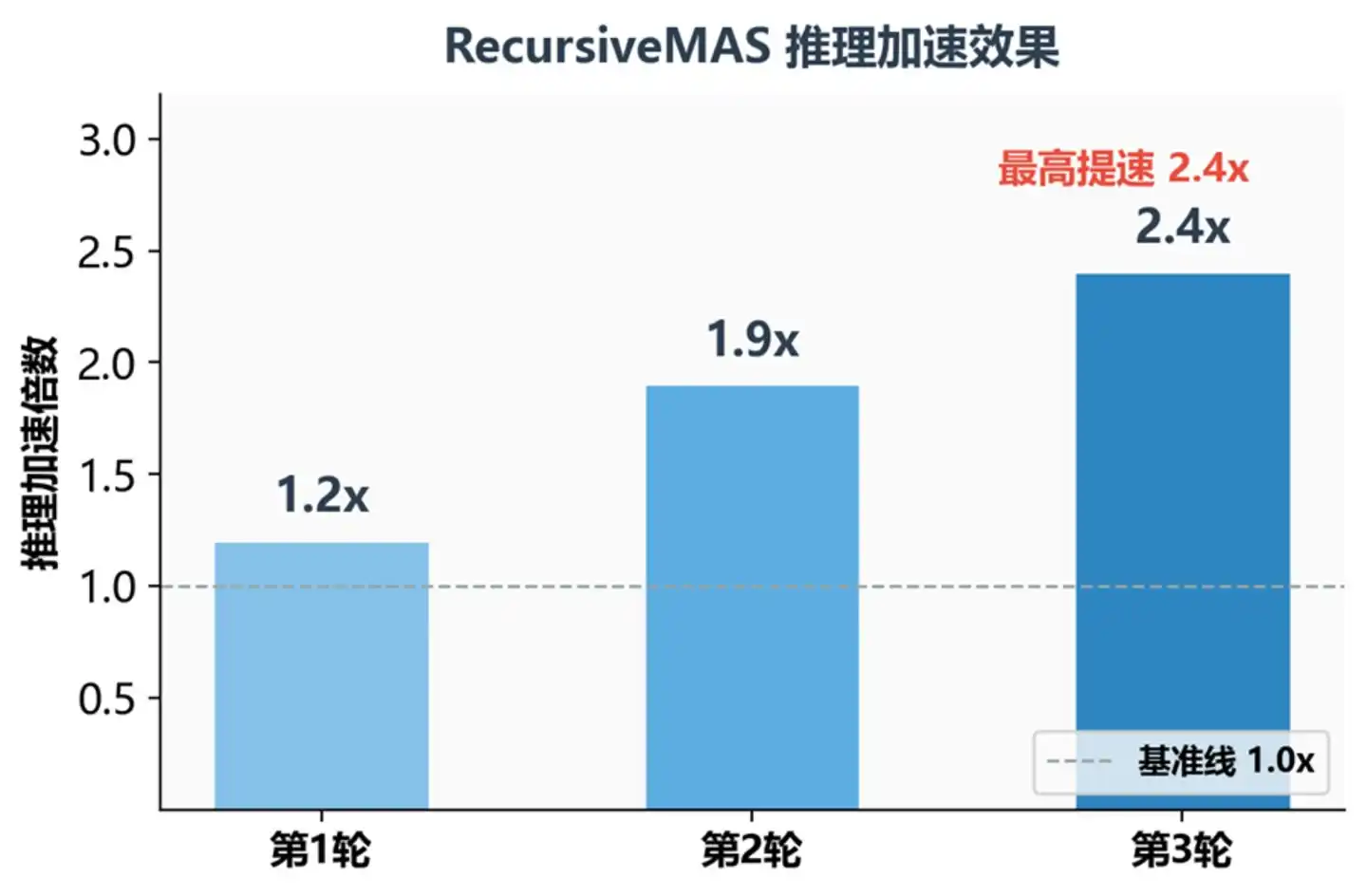
Коэффициент ускорения вывода при разном количестве рекурсивных раундов
Здесь есть ключевое наблюдение: чем больше глубина рекурсии, тем выше выгода. Эффект ускорения растёт с увеличением числа рекурсивных раундов: в среднем 1.2 раза на 1-м раунде, 1.9 раза на 2-м, 2.4 раза на 3-м. Причина проста — экономится время, которое каждый агент тратит на «запись мысли в слова». Чем больше агентов и раундов, тем больше экономия времени.
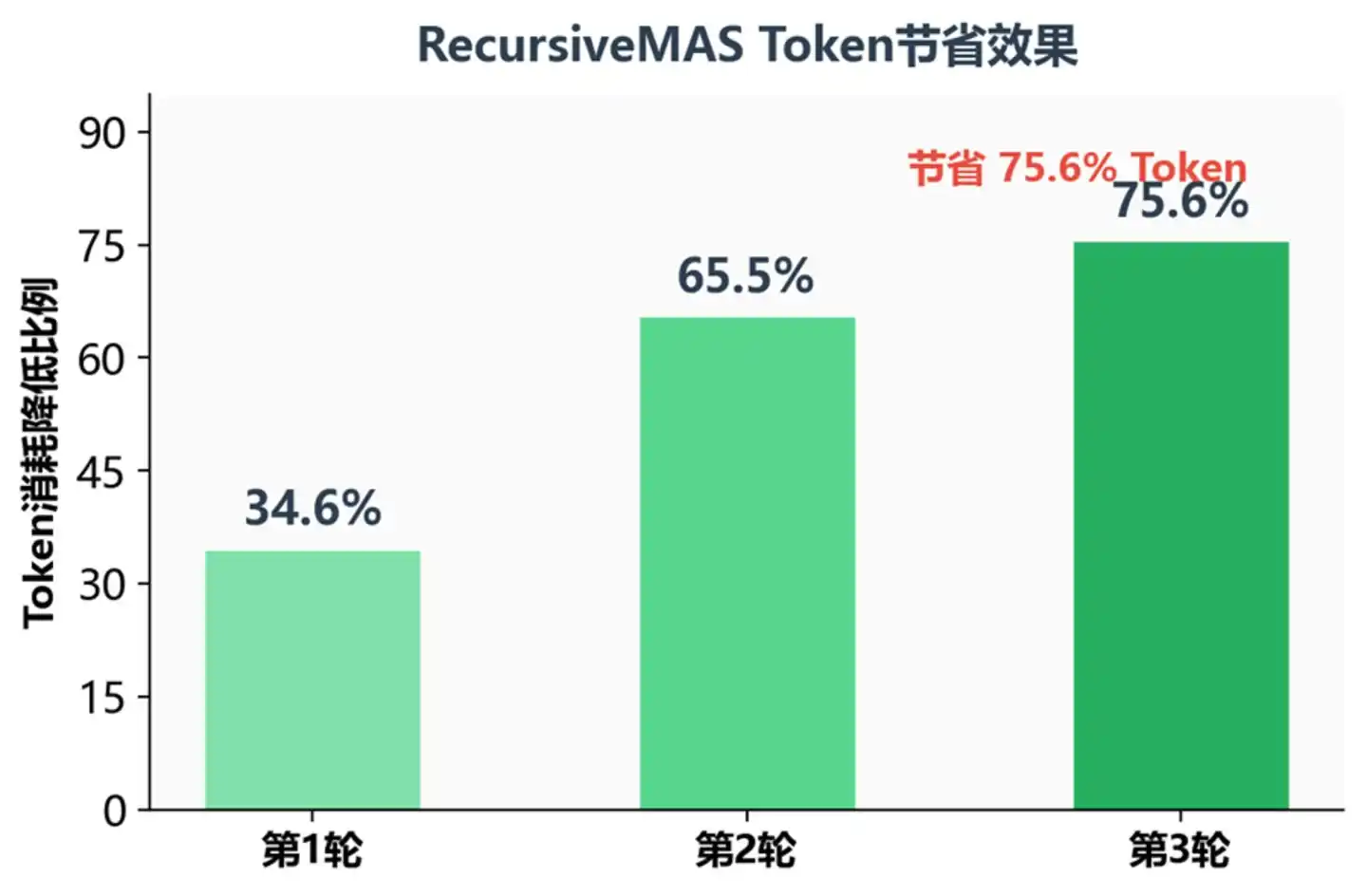
Процент экономии токенов при разном количестве рекурсивных раундов
На третьем рекурсивном раунде потребление токенов снизилось на 75.6% — это означает, что при одинаковой производительности стоимость выполнения можно сжать примерно до четверти от первоначальной. Для производственных сред, требующих сложных многошаговых рассуждений, это, несомненно, огромное преимущество.
Почему это исследование заслуживает внимания?
Если бы речь шла только о числовом улучшении, эта статья, возможно, не вызвала бы такого интереса. Но то, что делает её действительно значимой, — это то, что она может переопределить направление масштабирования многоагентных систем.
За последние годы попытки масштабирования в области многоагентных систем шли в основном по трём путям: увеличение количества агентов, расширение контекстного окна, наращивание более крупных моделей. Но у каждого из этих методов свои ограничения — больше агентов — взрыв коммуникаций, больше окно — взрыв стоимости, больше модель — взрыв обучения.
RecursiveMAS предлагает новый путь: углубление рекурсии. Она превращает «многоагентную коллаборацию» из параллельной, текстово-интерактивной парадигмы в глубокую, латентно-рекурсивную парадигму. Подобно тому, как рекурсивная языковая модель углубляет рассуждения, многократно обрабатывая одну и ту же проблему, RecursiveMAS позволяет нескольким агентам многократно «обдумывать» «идеи» друг друга, не «проговаривая и не выслушивая» их каждый раз.
Основной вопрос, который исследователи поднимают в статье: «Можно ли масштабировать саму коллаборацию агентов с помощью рекурсии?» Ответ, кажется, положительный.
Когда системе больше не нужно «переводить» внутренние представления в промежуточный формат, понятный человеку, верхний предел эффективности коллаборации потенциально можно поднять ещё выше.
Текущий отраслевой контекст также предоставляет практические сценарии для внедрения этого исследования. Baidu на своей конференции разработчиков 2026 года выбрала тему «Единство всего (Agents at Scale)», Anthropic выпустила Claude Managed Agents, OpenAI продолжает продвигать реализацию рассуждений уровня GPT-5 в реальном времени — вся индустрия ищет способы перевести коллаборацию агентов из демо-версий в производственную среду. А три основные преграды — вычислительная стоимость, задержка вывода, ограничения памяти — это как раз то, что RecursiveMAS пытается сдвинуть с помощью затрат всего в 0.31% параметров.
Конечно, это исследование всё ещё находится на ранней стадии, и несколько вопросов заслуживают внимания:
Достоверность данных требует проверки. На данный момент все результаты предоставлены самими авторами, независимая команда ещё не завершила воспроизведение. Академическое сообщество обычно придерживается подхода «смело предполагать, осторожно проверять». В эпоху «взрыва статей» независимое воспроизведение — лучший способ проверить реальную ценность технологии.
Совместимость гетерогенных агентов. Хотя внешний RecursiveLink был разработан для соединения моделей с разной архитектурой, в статье не раскрыты детали передачи латентных представлений между различными архитектурами. Если он может использоваться только для гомогенных агентов, сфера его практического применения значительно сузится. В конце концов, в реальных сценариях часто требуется смешивать использование закрытых API, таких как GPT-4o, Claude.
Снижение интерпретируемости. Когда агенты передают друг другу не читаемый текст, а набор векторных представлений, весь процесс коллаборации становится «чёрным ящиком». В производственной среде, где необходимо нести ответственность за решения ИИ, такая непрозрачность может создавать проблемы с соответствием требованиям и аудитом.
Сложность производственной среды. Статья тестирует относительно чистые сценарии коллаборации, реальная производственная среда часто включает сложные факторы: вызов внешних инструментов, человеко-машинное взаимодействие, динамические рабочие процессы.
Предложение RecursiveMAS по сути представляет собой внедрение стратегии масштабирования «рекурсия», доказавшей свою эффективность в эпоху одиночных моделей, в эпоху многоагентных систем, бросая вызов предположению по умолчанию, что «агенты должны обмениваться информацией через естественный язык». Если данные можно воспроизвести, следующая ось масштабирования в гонке MAS может сместиться с «наращивания количества агентов» на «углубление рекурсии».
Конечно, это исследование всё ещё требует проверки на большем количестве независимых бенчмарков, решения проблемы взаимосвязи гетерогенных моделей, доказательства своей эффективности в реальной производственной среде. Но, по крайней мере, оно показывает нам возможность —
Коллаборация между агентами ИИ не всегда должна быть «разговором глухих».
((Эта статья впервые опубликована в Titanium Media APP, автор | Silicon_Valley_Tech_news, редактор | Jiao Yan))








