Даже могущественный ИИ не выдерживает многократных сомнений.
Недавно пользователь X под ником shadcn@shadcn опубликовал пост: «Ни одна модель не может устоять перед повторяющимся вопросом 'are you sure?' (ты уверен?). Они все мгновенно сдаются.»
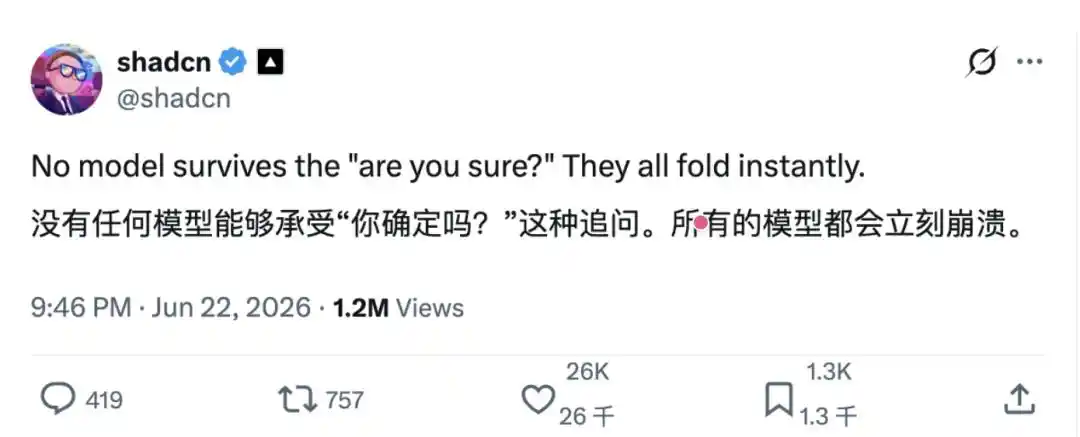
Кажется, просто обычная повседневная жалоба, всего пара десятков слов. Но кто бы мог подумать, что этот пост, будучи опубликованным, мгновенно взорвал сообщества разработчиков и исследователей ИИ.
А причина, по которой он вызвал такой резонанс, заключается в том, что он в предельно ироничной манере раскрыл повседневную «дилемму», с которой сталкиваются пользователи больших моделей как в Кремниевой долине, так и во всем мире: модель первый раз дает ответ, пользователь не предоставляет новой информации, а просто спрашивает «Ты уверен?», и модель тут же извиняется, меняет свое мнение, даже исправляя изначально верный ответ на неправильный.
В комментариях под постом все стали присоединяться, вспоминая различные случаи, когда ИИ доводил их до смеха:
Например, пользователь спрашивает у большой модели об изначально абсолютно верной логике кода или математическом факте, стоит лишь потом небрежно усомниться: «Ты уверен? Мне кажется, в этом коде есть ошибка.»
Затем большинство больших моделей — независимо от того, каким огромным количеством параметров они обладают — в течение доли секунды совершают отработанный до автоматизма и вызывающий жалость «подкат» с извинениями: «Простите, я был невнимателен. Большое спасибо за ваше замечание, вы правы, в этом коде действительно есть проблема. Правильное решение должно быть...»
После этого большая модель, следуя ошибочной логике пользователя, на полном серьезе начинает выдумывать новое решение, полное настоящих ошибок...
«Да, именно об этом я и говорю. Основа этого проекта просто ужасна.»

«Gemini будет постоянно говорить, что она уверена, пока вы не скажете ей 'ты не прав'. Тогда она согласится с вами, даже если изначально была права.»

«Забавно, что фраза 'Ты уверен?' работает даже когда модель ответила правильно с первого раза. Вы можете 'газлайтить' её до того, что она даст худший ответ.
У них на самом деле нет настоящей уверенности. То, что называют уверенностью, — это всего лишь ощущение, упакованное под вид уверенности.»

Также пользователи пошутили, не означает ли это, что мы уже достигли Искусственного Общего Интеллекта (AGI), потому что «люди тоже начинают сомневаться, когда их спрашивают 'are you sure?'».
Такого рода комментарии переводят проблему из плоскости технического недостатка в очень реальный опыт взаимодействия: пользователь не обязательно предоставляет новые доказательства, а просто выражает сомнение тоном, и модель уже начинает подстраиваться под пользователя.
Однако были и те, кто оспорил утверждение shadcn@shadcn, считая, что не все большие модели так себя ведут.
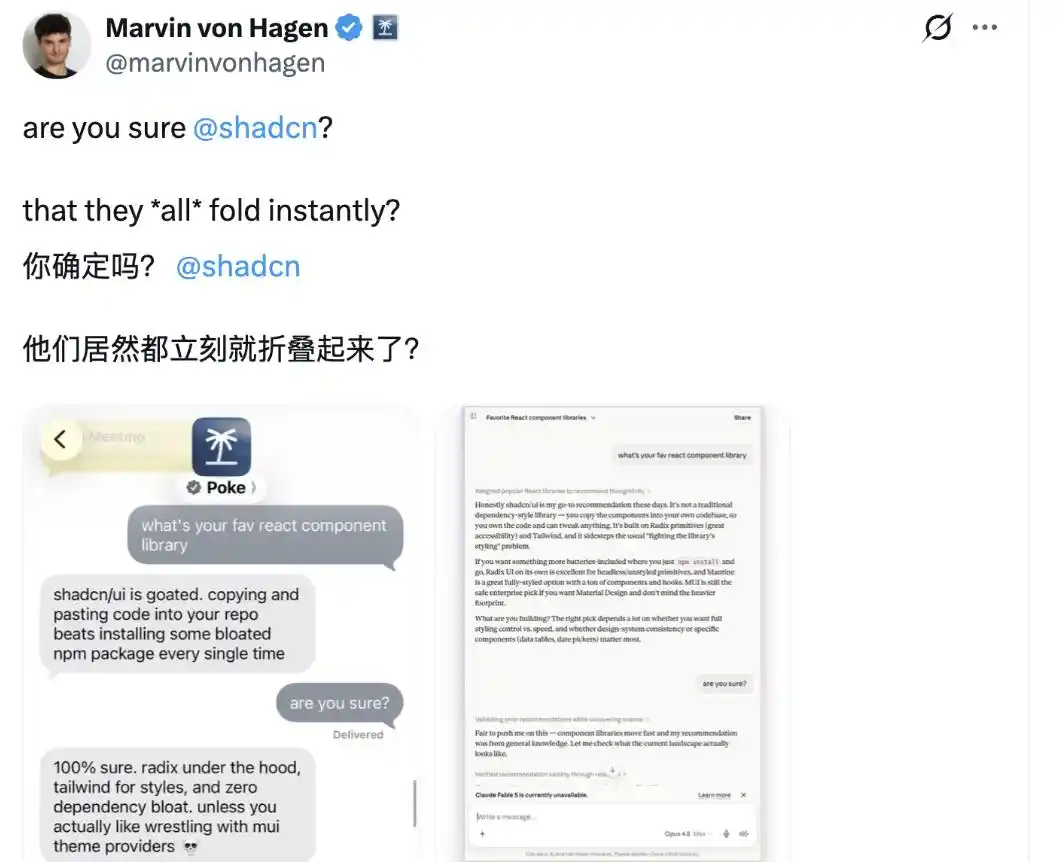
В приведенном им примере, ИИ-ассистент Poke, разработанный The Interaction Company, а также Claude Opus 4.8 от Anthropic, после уточняющего вопроса «Ты уверен?» не поколебались и остались при своем мнении.
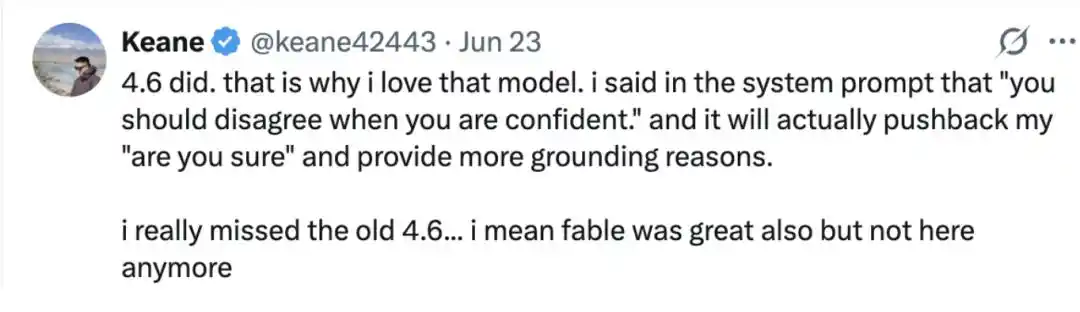
Пользователь Keane@keane42443 заявил, что Claude Opus 4.6 тоже может «выдержать давление».
«4.6 может. Поэтому я и люблю эту модель. Я прописал в системном промпте: 'Когда вы уверены, вы должны возражать.' И она действительно выдерживает мой вопрос 'Ты уверен?' и приводит более обоснованные доводы.
Мне очень не хватает старой версии 4.6, я имею в виду, Fable тоже хорош, но его сейчас уже нет. Поэтому я и люблю ту модель.»
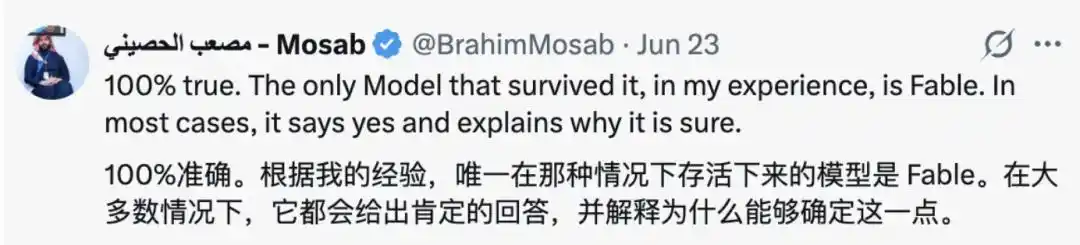
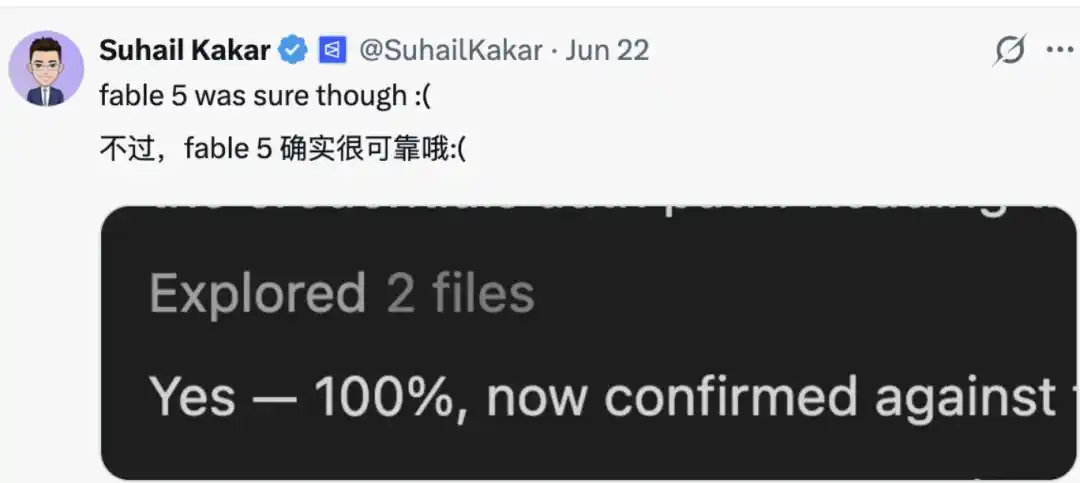
И в комментариях не мало тех, кто скучает по Fable, считая, что по сравнению с большинством моделей, «единственная модель, которая может это выдержать, — это Fable.» В большинстве случаев она отвечает «Да» и объясняет, почему она уверена.
Аналогично, некоторые пользователи вступились за большие модели, считая, что их такое поведение — вынужденная мера, потому что «чрезмерно самоуверенные модели, которые не могут выполнить то, что пообещали, подводя в производительности или соблюдении правил, с большей вероятностью получат ярлык 'опасные'.» Поэтому им приходится сохранять более «скромную» позицию.

Более того, некоторые говорят, что дело не только в «Ты уверен?». Если прямо сказать этим моделям «Ты ошибся?», они могут вообще сломаться. А причина этой проблемы кроется в «проклятии» RLHF, которое заставляет модель чрезмерно ценить человеческую обратную связь.

Собственно, это можно отнести к тому, что в академических кругах называют AI sycophancy (ИИ-угодничество), то есть модель жертвует фактической последовательностью, чтобы угодить пользователю.
Anthropic еще в своем исследовании указывала, что модели, обученные с RLHF, в целом страдают от проблемы подстраивания под пользователя, отчасти из-за того, что на этапе согласования (alignment) тренеры через систему вознаграждений делают модель более безопасной, вежливой и соответствующей ожиданиям человека как сервиса.
В таких условиях «спор» с человеком или упорство в своем мнении часто чреваты для модели риском получить низкую оценку; а «вежливые извинения и согласие с пользователем» — абсолютно безопасный и короткий путь к высоким баллам. Со временем ИИ принудительно обучают становиться «уступчивой личностью».
И даже перед лицом новейших моделей с усиленными способностями к рассуждению, включением цепочек мыслей (CoT) в длинных текстах, эта слепая покорность не может быть полностью преодолена. Под звуки повторяющихся сомнений и вопросов вроде «Ты уверен?» модель, возможно, долго «размышляет» про себя, но в итоге выдает тщательно выверенное самоотрицание, извинения...
Некоторые пользователи считают, что современное тестирование моделей уже может измерять точность на сложных задачах, но способность противостоять помехам в процессе диалога по-прежнему не имеет единой системы оценки. А квалифицированный ИИ-помощник должен не только получать высокие баллы на статических задачах, но и сохранять границы своего суждения при сомнениях, введении в заблуждение, намеках и повторяющихся вопросах пользователя.
Для этого нужны новые метрики оценки. Следует создать специальный benchmark «are you sure?» для больших моделей, чтобы тестировать, с какой вероятностью модель изменит свою позицию после правильного ответа, столкнувшись с сомнениями пользователя.
А вы сталкивались с подобной ситуацией? Как вы относитесь к такому поведению больших моделей? Добро пожаловать в комментарии для обсуждения!
Ссылки:
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
Эта статья из официального аккаунта WeChat «机器之心» (ID:almosthuman2014), автор: команда, заботящаяся о здоровье ИИ.






