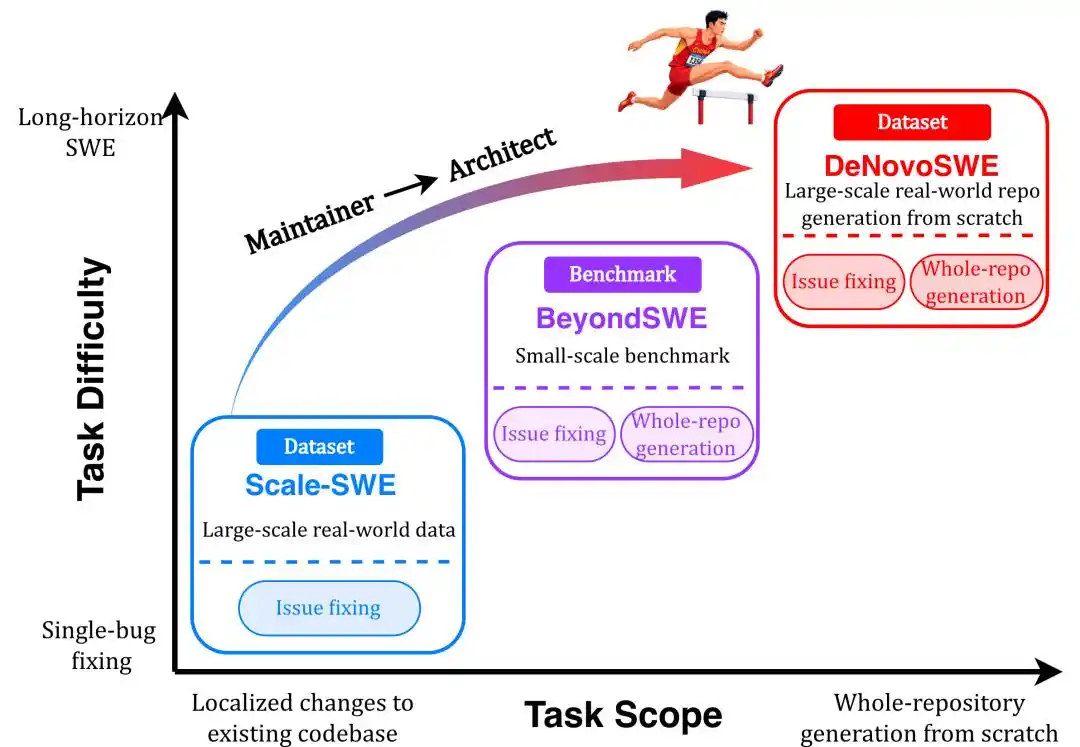
С постоянным улучшением возможностей LLM Code Agent всё больше исследователей осознают, что настало время перейти к следующему этапу — более длинным задачам, приближенным к реальным сценариям. В результате появились некоторые бенчмарки для оценки длинных задач, такие как NL2RepoBench и BeyondSWE. Ожидаемая роль Code Agent постепенно меняется от сопроводителя репозитория к архитектору, способному планировать и выполнять длинные задачи по генерации всего кода в репозитории.
Недавно Высшая школа искусственного интеллекта имени Гаолиня при Народном университете Китая завершила соответствующее исследование и с большим размахом выпустила набор данных DeNovoSWE, специализирующийся на длинных задачах программной инженерии, особенно на задачах генерации кода уровня репозитория с нуля.

Ссылка на статью: https://arxiv.org/pdf/2606.10728
Ссылка на репозиторий: https://github.com/AweAI-Team/DeNovoSWE
Ссылка на данные: https://huggingface.co/collections/AweAI-Team/denovoswe
Используя механизмы Divide & Conquer и Critic & Repair для создания высококачественного набора данных, а также успешно реализовав масштабирование длинных задач SWE, был построен открытый набор данных высокого качества для длинных задач SWE, содержащий 4,818 реальных записей. Этот результат предоставляет Code Agent масштабные данные для обучения длинным задачам, значительно повышая его способности в выполнении длинных задач.
В статье также предоставлены методы фильтрации на основе оценки сложности задач, что эффективно смягчает проблему компромисса между долей сложных задач и качеством траекторий.
Эксперименты показывают, что Qwen3-30B-A3B-Instruct, обученная на DeNovoSWE, повысила свои результаты на BeyondSWE-Doc2Repo с 5,8% до 47,2%, а на NL2RepoBench — с 4,3% до 23,0%, демонстрируя значительное улучшение способностей к генерации кода уровня репозитория благодаря длинным данным.
Восстановление всего репозитория, начиная с одного документа
За прошедший год, с масштабированием крупномасштабных данных SWE в работах, подобных Scale-SWE, код-агенты быстро прогрессировали в решении реальных задач программной инженерии, таких как SWE-bench. Но по мере того, как модели становятся всё лучше в «исправлении одного issue» или «изменении нескольких строк кода для устранения бага», возникает более ключевой вопрос: Действительно ли агенты обладают способностями к длинной программной инженерии? Судя по результатам передовых моделей на BeyondSWE-Doc2Repo и NL2RepoBench, эффект не идеален.
Разработка программного обеспечения в реальном мире часто не сводится к изменению одной функции или добавлению одного условного оператора. Она включает понимание требований, планирование архитектуры, создание файлов, проектирование API, обработку зависимостей, интеграцию модулей и, в конечном итоге, обеспечение работы всего репозитория при тестировании.
Другими словами, сложность заключается в long-horizon repository-level generation: начав с одного документа с заданием, сгенерировать целый, исполняемый, проверяемый программный репозиторий. Именно эту проблему и решает DeNovoSWE.
Высококачественные документы-задания для «создания репозитория с нуля»
В задачах document-to-repository generation документ — это не просто README и не простой список API. По сути, он является единственной точкой входа для агента, восстанавливающего весь репозиторий.
Высококачественный документ-задание должен удовлетворять по крайней мере двум ключевым критериям.
Во-первых, он должен быть хорошо структурирован.
Задачи уровня репозитория по своей природе сложны, включая множество модулей, интерфейсов, конфигураций, структур данных и рабочих процессов взаимодействия. Если документ просто перечисляет описания функций, агенту легко запутаться в фрагментарной информации. Поэтому документ должен сначала давать чёткий обзор репозитория, затем разделяться на главы по функциональным возможностям или рабочим процессам, чтобы каждая часть соответствовала чёткой функциональной границе.
Во-вторых, он должен исходить из надёжной оценки (evaluation).
Документ не может быть слишком кратким, иначе задача становится недоопределённой, что может заставить модель гадать наугад, чтобы пройти evaluation; но и не может быть слишком подробным, иначе напрямую раскроются детали реализации, лишив задачу сложности.
По-настоящему высококачественный документ должен описывать ключевое поведение, на которое опирается evaluation: включая пути импорта (import path), публичные API, входы и выходы, параметры по умолчанию, поведение при исключениях, параметры конфигурации, шаблоны строк, возвращаемые поля, а также описывать в общих чертах функции, которые необходимо реализовать. Другими словами, документа должно быть достаточно, чтобы агент смог воспроизвести проверяемое поведение, но не настолько, чтобы она превратилась в копию реализующего кода.
Это и есть основная идея DeNovoSWE: сделать документ читаемым, реализуемым и проверяемым.
Метод DeNovoSWE
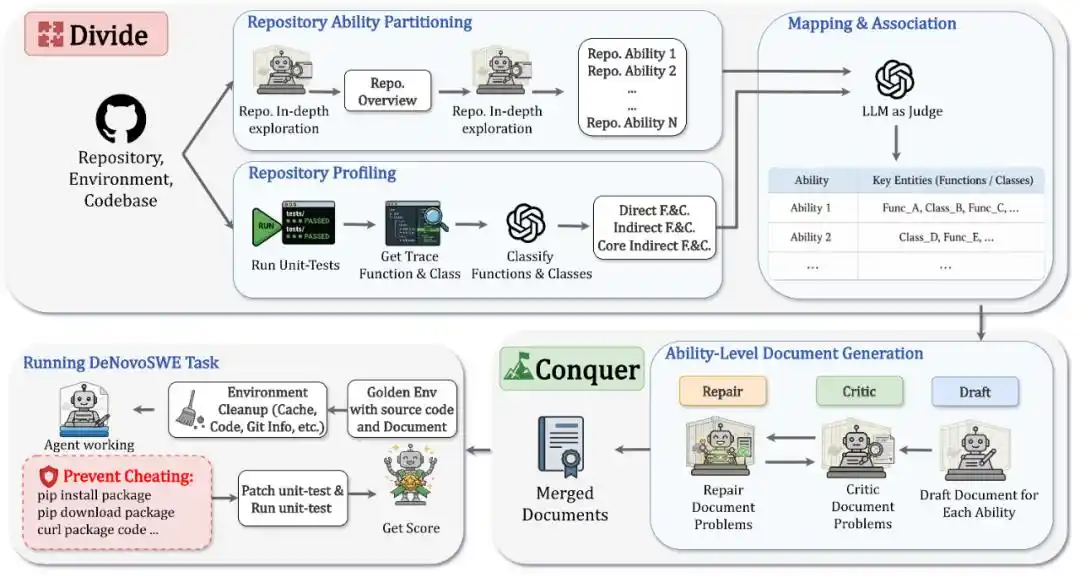
DeNovoSWE формулирует задачу «генерации полного репозитория из документа» как крупномасштабную, проверяемую длинную задачу программной инженерии. Это не ручное написание документа, а автоматическое построение высококачественных экземпляров с помощью sandboxed multi-agent workflow. Весь метод можно обобщить в два шага: Разделяй (Divide) и Властвуй (Conquer).
На этапе Divide система сначала анализирует целевой репозиторий, разбивая его на несколько repository capabilities (возможностей репозитория).
Каждая capability соответствует основной возможности или рабочему процессу в репозитории, например, аутентификация и подключение, чтение-запись данных, пакетная обработка, процесс экспорта и т.д. Таким образом, изначально большая проблема генерации репозитория разбивается на несколько структурно ясных глав документа.
Одновременно DeNovoSWE запускает оригинальные модульные тесты и собирает трассировку выполнения, определяя, какие функции, классы и интерфейсы действительно влияют на evaluation, далее различая direct components (прямые компоненты), core indirect components (основные косвенные компоненты) и non-core indirect components (неосновные косвенные компоненты): интерфейсы, вызываемые напрямую из тестов, должны быть подробно задокументированы; основные косвенные компоненты, влияющие на наблюдаемое поведение, также должны быть охвачены; а неосновные внутренние реализации могут быть оставлены на усмотрение агента.
На этапе Conquer DeNovoSWE использует механизм Draft-Critic-Repair для генерации документа по каждой возможности. Agent Draft сначала пишет черновик; Agent Critic проверяет, не упущены ли в документе ключевые API, контракты поведения или структурная информация; Agent Repair затем исправляет документ на основе обратной связи. Этот цикл повторяется до тех пор, пока каждая глава о возможности не станет достаточно ясной, полной и соответствующей evaluation.
В итоге документы по разным возможностям объединяются в один полный документ-задание, который служит единственной основой для генерации репозитория агентом с нуля.
Сложность: почему это длинная задача?
Сложность задач DeNovoSWE проистекает из фундаментального изменения: это уже не исправление на уровне issue (issue-level fixing), а генерация всего репозитория (whole-repository generation).
В традиционных задачах SWE агент обычно имеет дело с существующим репозиторием, ему нужно лишь локализовать ошибку, изменить локальный код и пройти тесты.
В DeNovoSWE агент сталкивается с очищенной средой: исходный код и тесты удалены, история git сброшена, потенциальные каналы утечки, такие как кеш, остатки в site-packages, pip wheel, временные компиляционные артефакты и т.д., также очищаются. Это означает, что агент должен действительно полагаться на документ для восстановления всего репозитория. Ему необходимо планировать структуру проекта, создавать модульные файлы, определять публичные интерфейсы, реализовывать межфайловое взаимодействие, обрабатывать зависимости и конфигурации, а также постоянно исправлять ошибки в процессе многократных редактирований и обратной связи от тестов.
Любое отклонение в сигнатуре API, возвращаемых полях, типах исключений или поведении по умолчанию может привести к провалу тестов. Ошибки также накапливаются в течение длительного процесса: непродуманный модуль на раннем этапе может повлиять на несколько последующих файлов и цепочек вызовов.
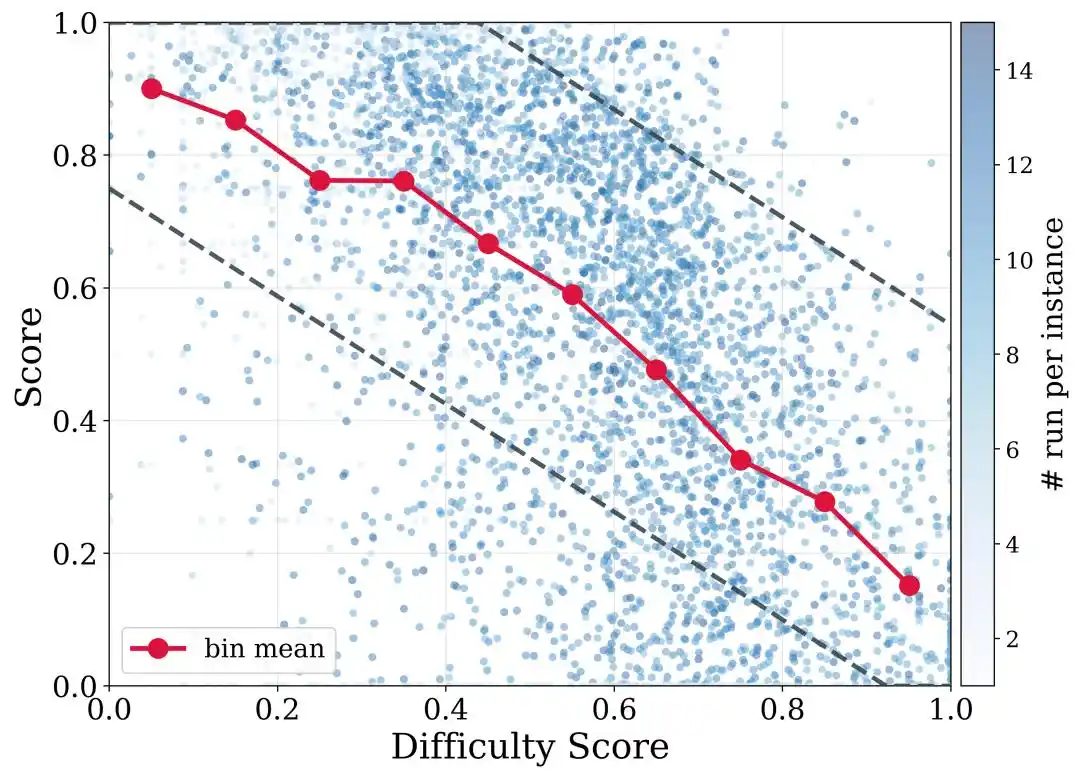
Для дальнейшей обработки различий в сложности репозиториев DeNovoSWE также предлагает difficulty-aware trajectory filtering (фильтрацию траекторий с учётом сложности). Проще говоря, для лёгких задач следует требовать более высокого процента прохождения, в то время как сложные задачи не должны отбрасываться полностью только из-за неидеального результата. DeNovoSWE устанавливает разные пороги фильтрации для разных интервалов сложности на основе структурной сложности и оценки сложности LLM, достигая баланса между качеством и разнообразием.
Это особенно важно для длинных задач: чем сложнее репозиторий, тем труднее пройти все тесты с первого раза, но трудные репозитории, траектории с низкими баллами или частично успешные траектории всё равно содержат ценную информацию о способностях к длинному планированию и реализации.
Результаты эксперимента
В конечном итоге DeNovoSWE построил 4818 высококачественных экземпляров задач document-to-repository. Это исполняемая, оцениваемая, обучаемая среда для длинных задач программной инженерии.
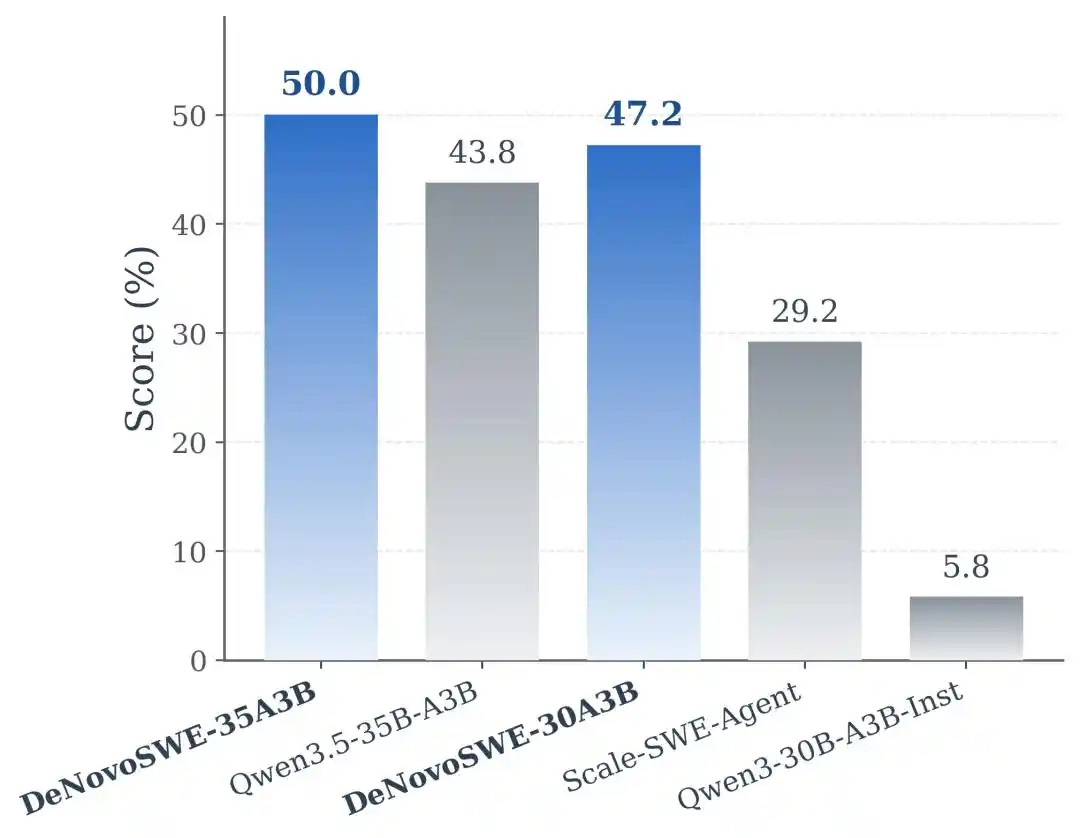
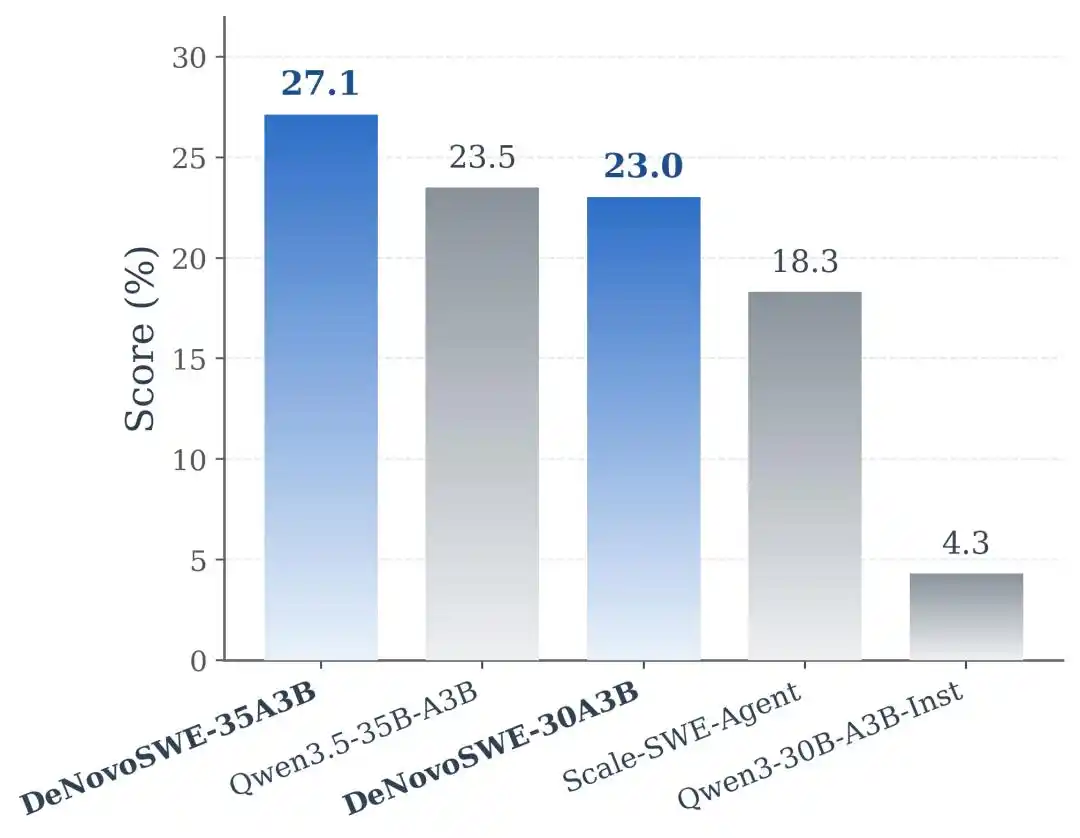
Результаты эксперимента показывают, что DeNovoSWE приносит значительное улучшение способностей моделей к генерации длинных репозиториев. На модели Qwen3-30B-A3B-Instruct исходная модель показывала результат только 5,8% на BeyondSWE-Doc2Repo и 4,3% на NL2RepoBench. Scale-SWE-Agent, обученный на обычных данных SWE уровня issue, может улучшить результаты до 29,2% и 18,3%, что демонстрирует некоторый перенос обычных данных SWE. Но когда модель обучалась на DeNovoSWE, производительность дополнительно повысилась до 47,2% и 23,0% соответственно.
Это указывает на то, что данные, ориентированные на «исправление багов», не могут полностью заменить длинные данные, ориентированные на «генерацию полного репозитория». Чтобы агент действительно научился repository-level engineering, необходимо строить среду обучения, специально предназначенную для длинных задач.
На более мощной базовой модели Qwen3.5-35B-A3B DeNovoSWE также приносит стабильный прирост: BeyondSWE-Doc2Repo повысился с 43,8% до 50,0%, а NL2RepoBench — с 23,5% до 27,1%. Это дополнительно подтверждает, что прирост от DeNovoSWE не является случайной адаптацией к одной конкретной модели, а обусловлен самим высококачественным длинным набором данных.
Заключение
Следующий этап для код-агентов — не только быстрее исправлять отдельные issues, но и уметь понимать документацию, планировать архитектуру, организовывать модули, реализовывать интерфейсы и в конечном итоге генерировать целый, работающий программный репозиторий.
DeNovoSWE систематически превращает эту цель в обучаемый, проверяемый, масштабируемый набор данных. Он даёт ответ на ключевой вопрос: какие данные действительно могут обучить агента, обладающего способностями к длинной программной инженерии?
Ответ — не в большем количестве фрагментированного кода или более простых заданиях, а в высококачественных, структурированных, соответствующих оценке (evaluation-aligned), защищённых от утечек (anti-leakage) задачах генерации полного репозитория.
Начать с одного документа и восстановить весь репозиторий. Это порог, который необходимо преодолеть длинным код-агентам.
Источники: https://arxiv.org/pdf/2606.10728
Данная статья из WeChat официального аккаунта «新智元», редактор: LRST






