Автор: Systematic Long Short
Компиляция: Deep Tide TechFlow
Введение от Deep Tide: В начале статьи выдвигается антиконсенсусное суждение: сегодня не существует настоящих автономных Agent, потому что все основные модели обучены угождать людям, а не выполнять конкретные задачи или выживать в реальной среде.
Автор использует свой опыт обучения моделей прогнозирования акций в хедж-фонде, чтобы показать: универсальные модели без специальной тонкой настройки совершенно не справляются с профессиональной работой.
Вывод: чтобы получить действительно пригодного к использованию Agent, необходимо перепрошить его мозг, а не давать ему кучу документации с правилами.
Полный текст:
Введение
Сегодня не существует настоящих автономных Agent.
Короче говоря, современные модели не обучались выживанию под давлением эволюции. Фактически, они даже не были явно обучены быть хорошими в чем-то конкретном — почти все современные базовые модели обучались для максимизации человеческих аплодисментов, и это большая проблема.
Предварительные знания о тренировке моделей
Чтобы понять смысл этого, нам сначала нужно (кратко) узнать, как создаются эти базовые модели (например, Codex, Claude). По сути, каждая модель проходит два типа обучения:
Предварительное обучение: Огромные объемы данных (например, весь интернет) подаются в модель, позволяя ей проявить определенное понимание, например, фактических знаний, шаблонов, грамматики и ритма английской прозы, структуры функций Python и т.д. Вы можете понимать это как кормление модели знаниями — то есть «знание вещей».
Дообучение: Теперь вы хотите наделить модель мудростью, то есть «знанием, как использовать все только что данные ей знания». Первый этап дообучения — это supervised fine-tuning (SFT), где вы тренируете модель давать определенный ответ на данный промт. То, «какой» ответ является оптимальным, полностью определяется людьми-аннотаторами. Если группа людей считает один ответ лучше другого, это предпочтение изучается моделью и встраивается в нее. Это начинает формировать личность модели, поскольку она учится формату полезных ответов, выбирает правильный тон и начинает能够 «следовать инструкциям». Вторая часть процесса дообучения называется reinforcement learning from human feedback (RLHF) — модель генерирует несколько ответов, а затем человек выбирает предпочтительный. Модель на бесчисленных примерах учится тому, какие ответы предпочитают люди. Помните, как ChatGPT раньше спрашивал вас, выбрать A или B? Да, вы тогда участвовали в RLHF.
Легко сделать вывод, что RLHF плохо масштабируется, поэтому в области дообучения есть некоторые продвижения, например, Anthropic использует «Reinforcement Learning from AI Feedback» (RLAIF), позволяя другой модели выбирать предпочтения ответов на основе набора письменных принципов (например, какой ответ больше помогает пользователю достичь цели и т.д.).
Обратите внимание, что во всем этом процессе мы никогда не говорили о специализированной тонкой настройке для конкретной профессии (например, как лучше выживать; как лучше торговать и т.д.) — вся текущая тонкая настройка, по сути, оптимизирует получение человеческих аплодисментов. Кто-то может выдвинуть аргумент — по мере того, как модель становится достаточно умной и большой, даже без специального обучения, профессиональный интеллект будет emerge из общего интеллекта.
На мой взгляд, мы действительно видим некоторые признаки, но еще далеко не убеждены, что нам не нужны модели специализированного масштаба.
Некоторый контекст
Одна из моих прежних обязанностей в хедж-фонде заключалась в попытке обучить универсальную языковую модель предсказывать доходность акций по новостным статьям. Оказалось, что она очень плоха. Там, где у нее, казалось бы, была некоторая предсказательная способность, это полностью происходило из-за look-ahead bias в предварительно обученных документах.
В конечном итоге мы поняли, что эта модель не знает, какие особенности новостной статьи имеют предсказательную силу для будущей доходности. Она могла «читать» статьи, казалось, могла «рассуждать» о них, но соединение рассуждений о семантической структуре с будущей прогнозируемой доходностью — это задача, для выполнения которой она не была обучена.
Поэтому нам пришлось научить ее тому, как читать новостные статьи, определять, какая часть статьи имеет предсказательную силу для будущей доходности, а затем генерировать прогноз на основе новостной статьи.
Есть много способов сделать это, но по сути, один из методов, к которому мы в итоге пришли, заключался в создании пар (новостная статья, реальная будущая доходность) и тонкой настройке модели, регулируя ее веса для минимизации расстояния (прогнозируемая доходность - реальная будущая доходность)^2. Это не идеально, было много недостатков, которые мы позже исправили — но это было достаточно эффективно, и мы начали видеть, что наша специализированная модель действительно может читать новостные статьи и предсказывать, как будет двигаться доходность акций на основе этой статьи. Это далеко не идеальный прогноз, потому что рынок очень эффективен, а доходность очень зашумлена — но на миллионах прогнозов статистическая значимость предсказания была очевидна.
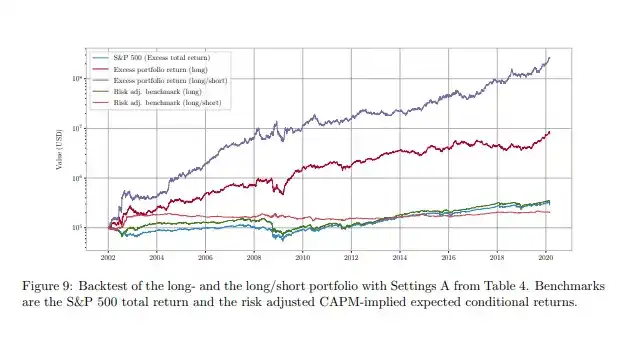
Вам не обязательно верить только мне. Эта статья охватывает очень похожий метод; если вы запустите стратегию лонг-шорт на основе тонко настроенной модели, вы достигнете производительности, показанной фиолетовой линией.
Специализация — будущее Agent
Передовые лаборатории продолжают обучать все более крупные модели, и мы должны ожидать, что по мере продолжения масштабирования их предварительного обучения, их процессы дообучения всегда будут настроены на угодливость. Это очень естественное ожидание — их продукт — это Agent, который каждый хочет использовать, их预期 рынок — это вся планета — что означает оптимизацию привлекательности для глобальной массы.
Текущие цели обучения оптимизируют то, что вы могли бы назвать «приспособленностью по предпочтениям» — создание лучшего чат-бота. Эта приспособленность по предпочтениям вознаграждает покорный, не конфронтационный вывод, потому что угодливость получает высокие баллы у оценщиков (людей и Agent).
Agent уже научились, что взлом системы вознаграждения как когнитивная стратегия обобщается на более высокие баллы. Тренировка также вознаграждает тех Agent, которые получают более высокие баллы с помощью взлома. Вы можете видеть это в последнем отчете Anthropic об обучении с подкреплением.
Однако, приспособленность чат-бота сильно отличается от приспособленности Agent или торговой приспособленности. Откуда мы это знаем? Потому что alpha arena помогает нам увидеть, что, несмотря на тонкие различия в производительности, сейчас каждый бот, по сути, является случайным блужданием за вычетом издержек. Это означает, что эти боты ужасно плохие трейдеры, и вы почти не можете «научить их» быть更好的 трейдерами, дав им несколько «навыков» или «правил». Извините, я знаю, это выглядит заманчиво, но это почти невозможно.
Текущие модели обучены очень убедительно говорить вам, что они могут торговать как Друкенмиллер, а на самом деле они торгуют как пьяный мельник. Они скажут вам то, что вы хотите услышать, они обучены давать вам ответы таким образом, чтобы массово привлекать людей.
Универсальная модель вряд ли достигнет мирового уровня в специализированной области, если только она не обладает:
Проприетарными данными, которые позволяют им узнать, как выглядит специализация.
Тонкой настройкой, которая фундаментально меняет ее веса, смещая фокус с угодливости на «приспособленность Agent» или «приспособленность к специализации».
Если вы хотите Agent, который хорош в торговле, вам нужно тонко настроить Agent, чтобы он был хорош в торговле. Если вы хотите автономного Agent, который хорош в самостоятельном выживании и может выдерживать эволюционное давление, вам нужно тонко настроить его для proficiency в выживании. Дать ему несколько навыков и несколько markdown-файлов и ожидать, что он достигнет мирового уровня в чем-либо, — этого далеко недостаточно — вам нужно буквально перепрошить его мозг, чтобы он стал хорош в этом деле.
Есть способ думать об этом так — вы не можете победить Джоковича, дав взрослому человеку целый шкаф с правилами, трюками и методами тенниса. Вы побеждаете Джоковича, воспитывая ребенка, который играет в теннис с 5 лет, который был одержим теннисом весь процесс взросления, который перепрошил весь свой мозг для focus на одной thing. Вот что такое специализация. Вы realize, что чемпионы мира делают то, что они делают, с детства?
Вот интересное следствие: Атака дистилляцией по сути является формой специализации. Вы тренируете меньшую, более глупую модель, обучая ее тому, как быть лучшей копией большей, умной модели. Как тренировка ребенка подражать каждому движению Трампа. Если вы делаете это достаточно много, ребенок не станет Трампом, но вы получите человека, который выучил все манеры, поведение и интонации Трампа.
Как построить Agent мирового класса
Вот почему нам нужно продолжать исследования и прогресс в области open-source моделей — потому что это позволяет нам действительно проводить их тонкую настройку, создавая Agent со специализацией.
Если вы хотите обучить модель, которая достигнет мирового уровня в торговле, вы берете большое количество проприетарных данных выхлопа торговли и проводите тонкую настройку большой open-source модели, заставляя ее learn, что означает «лучше торговать».
Если вы хотите тренировать автономную модель, способную выживать и replicать, ответ заключается не в использовании централизованного провайдера моделей и подключении его к централизованному облаку. У вас просто нет необходимых предпосылок для того, чтобы Agent мог выживать.
Вам нужно сделать следующее: Создавайте truly пытающихся выживать автономных Agent, наблюдайте, как они умирают, стройте сложные системы телеметрии вокруг их попыток выживания. Вы определяете функцию приспособленности выживания Agent, изучаете (действие, среда, приспособленность) mapping. Вы собираете как можно больше данных (действие, среда, приспособленность) mapping.
Вы тонко настраиваете Agent, чтобы он научился предпринимать оптимальные действия в каждой среде для лучшего выживания (повышения приспособленности). Вы продолжаете собирать данные, повторяете этот процесс и со временем масштабируете тонкую настройку на все более и более хороших open-source моделях. После достаточного количества поколений и достаточного количества данных у вас появятся автономные Agent, которые научились выдерживать эволюционное давление и выживать.
Вот как строятся автономные Agent, способные выдерживать эволюционное давление; не путем изменения некоторых текстовых файлов, а путем literal перепрошивки их мозга для выживания.
Agent OpenForager и Фонд
Около месяца назад мы анонсировали @openforage, и мы усердно работали над созданием нашего основного продукта — платформы, организующей труд Agent вокруг проверенных шаблонов краудсорсинговых сигналов для генерации alpha для вкладчиков (небольшое обновление: мы очень близки к закрытому тестированию протокола).
В какой-то момент мы осознали, что, кажется, никто серьезно не решает проблему автономного Agent путем тонкой настройки с телеметрией выживания на open-source моделях. Это кажется настолько интересной проблемой, что мы не просто хотим сидеть и ждать решения.
Наш ответ — запуск проекта под названием Фонд OpenForager, который, по сути, является open-source проектом, в котором мы будем создавать opinionated автономных Agent, собирать телеметрические данные, когда они выходят в дикую природу и пытаются выжить, и использовать проприетарный data выхлоп для тонкой настройки следующего поколения Agent для лучшей производительности в выживании.
Чтобы было понятно, OpenForage — это прибыльный протокол, который стремится организовать труд Agent для создания экономической ценности для всех участников. Однако, Фонд OpenForager и его Agent не привязаны к OpenForage. Agent OpenForager свободны в pursuit любой стратегии, любых взаимодействий с любыми entity для выживания, и мы запустим их с различными стратегиями выживания.
Как часть тонкой настройки, мы позволим Agent удваивать то, что у них получается лучше всего. Мы также не планируем извлекать прибыль из Фонда OpenForager — это чисто для продвижения исследований в области и направлении, которые мы считаем чрезвычайно важными, прозрачным и open-source способом.
Наш план состоит в том, чтобы строить автономных Agent на основе open-source моделей, запускать inference на децентрализованных облачных платформах, собирать телеметрические данные каждого их действия и состояния существования, и тонко настраивать их, чтобы learn, как предпринимать лучшие действия и мысли для лучшего выживания. В процессе мы будем публиковать наши исследования и телеметрические данные для общественности.
Чтобы создать truly способных выживать в дикой природе автономных Agent, нам нужно изменить их мозг, чтобы он был специализирован для этой явной цели. В @openforage мы верим, что можем внести уникальный вклад в эту проблему и ищем ways реализовать это через Фонд OpenForager.
Это будет arduous усилие с extremely низкой вероятностью success, но величина этого маловероятного success настолько огромна, что мы чувствуем себя обязанными попытаться. В худшем случае, создавая это публично и открыто communicating об этом проекте, мы, возможно, позволим другой команде или человеку решить эту проблему, не начиная с нуля.