Каждый раз, когда выходит новая передовая модель, индустрия ИИ пристально следит за несколькими знакомыми отчётами об оценках.
MMLU-Pro, MMMU, MMMU-Pro... Эти названия могут быть незнакомы обычным пользователям, но для компаний, разрабатывающих модели, и исследователей они уже стали практически «стандартными дисциплинами». GPT, Claude, Gemini, Llama, Qwen, DeepSeek постоянно сдают «экзамены» по этим бенчмаркам.
«Проверка — лучшее испытание». Часто именно эти баллы доказывают, насколько хороша модель.
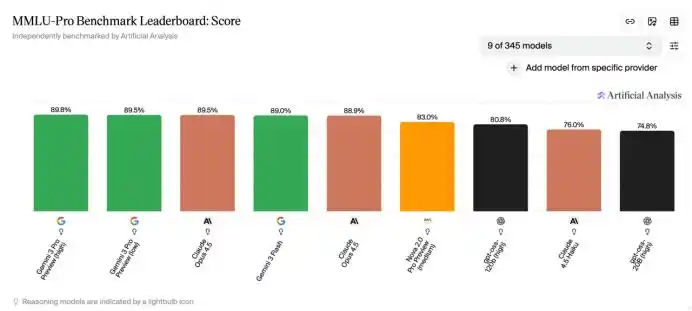
На многих презентациях моделей графики сравнения производительности не обходятся без них; некоторые рейтинги на HuggingFace также построены на этих системах оценки. Можно даже сказать, что сегодня, обсуждая возможности моделей ИИ, индустрия использует общий язык, определённый именно этими бенчмарками.
Но интересно то, что почти все следят за баллами, но мало кто знает, кто составляет эти «задания». А за MMLU-Pro, MMMU и MMMU-Pro стоит одно и то же имя — Вэньху Чэнь (陈文虎).
Он — доцент кафедры компьютерных наук Университета Ватерлоо в Канаде, и в Google Scholar его статьи процитированы более 30 000 раз.
Он также основатель «Лаборатории Тигра (TIGERLab)», чьё полное английское название — Text and Image GEnerative Research Lab. Поскольку в названии есть иероглиф «虎» (тигр), Чэнь Вэньху дал ей очень узнаваемое китайское название — «Банда Тигровой Головы» (虎头帮).
01
После того, как старые тесты перестали работать
Сначала Чэнь Вэньху привлёк внимание многих благодаря MMLU-Pro.
MMLU ранее была одним из наиболее часто используемых бенчмарков для оценки способностей больших языковых моделей. Она похожа на комплексный экзамен, охватывающий различные дисциплины, и используется для измерения способности модели понимать знания и выполнять задачи на логический вывод.
На раннем этапе этот «тест» был очень полезен. Баллы позволяли выявить разрыв между моделями, и индустрия могла с его помощью наблюдать, действительно ли большие языковые модели прогрессируют.
Но проблема быстро возникла.
По мере того, как способности моделей продолжали расти, MMLU постепенно стала «слишком лёгкой». Баллы передовых моделей становились всё выше, а разрыв между ними — всё меньше.
После того, как OpenAI выпустила o3, эта проблема стала ещё более очевидной. Точность o3 на MMLU уже приближалась к 100%, и другие передовые модели также одна за другой показывали результаты, близкие к максимальным.
Звучит как хорошая новость, но для оценки это означает неприятности.
Если все могут сдать экзамен почти на максимум, становится трудно определить, кто сильнее и в чём именно. Он по-прежнему может доказать, что модель уже обладает определёнными способностями, но больше не подходит для измерения нового прогресса.
Индустрии ИИ нужен был более сложный и менее «обманываемый» тест.
В 2024 году Чэнь Вэньху и его команда представили MMLU-Pro.
MMLU-Pro — это не просто расширение базы вопросов, а переработка самого теста.
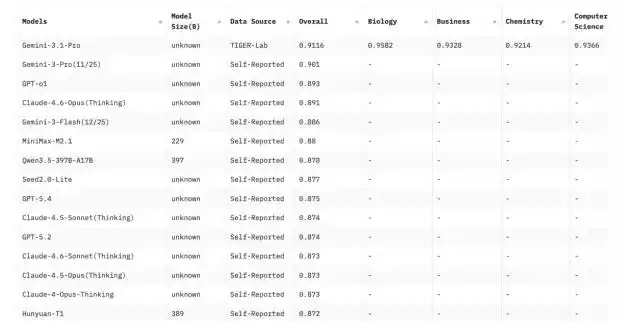
Он содержит 12032 вопроса, охватывающих 14 областей, включая математику, физику, химию, право, инженерию, психологию, здравоохранение. По сравнению с оригинальной MMLU, количество вариантов ответов увеличено с 4 до 10, чтобы снизить вероятность угадывания моделью; также добавлено больше вопросов, требующих логического вывода, и удалены относительно простые, неоднозначные или недостаточно различимые вопросы из оригинальной базы.
Эффект был прямым.
Результаты исследования показали, что точность моделей на MMLU-Pro снизилась на 16% до 33% по сравнению с оригинальной MMLU. Разброс оценок одной и той же модели при тестировании с 24 различными стилями промптов также снизился с 4-5% в оригинальной MMLU до примерно 2%.
Другими словами, этот новый тест не только сложнее, но и стабильнее.
Он снова позволил развести модели, которые на старом тесте выглядели одинаково отлично. Стало легче определить, действительно ли модель умеет рассуждать или просто лучше справляется со старыми вопросами.
02
Полезные бенчмарки для оценки
Индустрия быстро начала использовать MMLU-Pro.
MMLU-Pro затем вошёл в трек «Наборы данных и бенчмарки» конференции NeurIPS 2024 и также был интегрирован в фреймворк оценки языковых моделей lm-evaluation-harness от EleutherAI. Для сообщества open-source моделей это означало, что он перестал быть просто набором данных в исследовательской статье, а вошёл в стандартную цепочку инструментов оценки.
Многие модели начали отчитываться о баллах MMLU-Pro при выпуске. Некоторые рейтинги на HuggingFace также включили его в свою систему оценки.
Если MMLU-Pro решает проблему «неэффективности старого теста» при оценке языковых моделей, то MMMU вывел Чэнь Вэньху и TIGERLab в центр оценки мультимодальности.
Проблема мультимодальных моделей сложнее.
Языковая модель отвечает на вопросы, в основном обрабатывая текст. Мультимодальная модель должна одновременно обрабатывать информацию в различных формах: изображения, диаграммы, схемы, карты, таблицы, нотные записи, химические структуры и т.д. Ей нужно не просто понять формулировку вопроса, но и действительно разобраться в содержании изображения, а затем объединить визуальную информацию, текстовую информацию и предметные знания для логического вывода.
Бенчмарк MMMU содержит 11,5 тысяч мультимодальных вопросов, взятых из университетских экзаменов, тестов и учебников. Он охватывает шесть основных областей: искусство и дизайн, бизнес, естественные науки, здоровье и медицина, гуманитарные и социальные науки, технологии и инженерия, с дальнейшим разделением на 30 дисциплин и 183 подраздела.
Эти вопросы не просто спрашивают модель «что на картинке» — они требуют от модели, подобно студенту на профессиональном экзамене, объединить информацию с изображения и предметные знания.
При выпуске MMMU исследовательская группа протестировала 14 открытых мультимодальных моделей, а также представительные проприетарные модели, такие как GPT-4V и Gemini Ultra. Даже самые мощные на тот момент проприетарные модели, GPT-4V и Gemini Ultra, достигли точности всего 56% и 59% соответственно.
Эти цифры показывают, что хотя мультимодальные модели, казалось бы, быстро прогрессируют, в задачах, требующих настоящего профессионального понимания и логического вывода, у них всё ещё есть огромный потенциал для роста.
Позже команда Чэнь Вэньху выпустила MMMU-Pro, чтобы ещё больше ограничить возможность моделей обходить визуальную информацию. Она отфильтровывает вопросы, на которые можно ответить, используя только языковую модель, расширяет варианты ответов и вводит настройку «vision-only», встраивая вопрос в само изображение, требуя от модели одновременно выполнять визуальное считывание и текстовое понимание.
Проще говоря, это не позволяет модели «угадывать ответ, просто читая текст».
Такая работа может показаться довольно кропотливой, но она очень важна. Потому что в будущем мультимодальные модели будут внедряться в такие сценарии, как здравоохранение, образование, научные исследования, дизайн, инженерия, и просто описывать картинки недостаточно. Они должны уметь судить, рассуждать, объяснять, а также находить действительно полезную информацию в сложных визуальных данных.
03
Человек за «экзаменационными тестами»
Работа Чэнь Вэньху над MMLU-Pro и MMMU вытекает из его давнего направления исследований.

Его исследовательские интересы изначально связаны с пониманием сложной информации, вопросами, основанными на знаниях, и логическим выводом.
Он окончил бакалавриат Хуачжунского университета науки и технологий, затем получил степень магистра в Рейнско-Вестфальском техническом университете Ахена в Германии, а позже — докторскую степень по компьютерным наукам в Калифорнийском университете в Санта-Барбаре. Во время докторантуры он уже начал исследования в области сложных вопросно-ответных систем, табличных выводов, определения источников знаний и других направлений.
У таких задач есть общая черта: ответ часто не содержится в одном тексте.
Он может быть скрыт в таблице, может требовать объединения текста и изображения, или же модель может сначала получить информацию, а затем интегрировать, вычислить и сделать вывод. Модель не может просто пересказывать известные знания.
Проекты, в которых участвовал Чэнь Вэньху, такие как HybridQA, TabFact, ProgramofThoughts, MAmmoTH, связаны с этой линией.
Это также объясняет, почему он так чувствителен к уязвимостям в оценке моделей.
Хороший бенчмарк — это не просто увеличение сложности вопросов, а прогнозирование того, где модель с наибольшей вероятностью «угадает ответ» или «будет казаться знающей».
Модель может запомнить базу вопросов, может угадывать ответ по вариантам, может использовать текст, чтобы обойти визуальную информацию... Хорошая оценка должна закрыть эти лазейки.
После защиты докторской диссертации Чэнь Вэньху присоединился к Google Research, а затем с 2021 по 2025 год участвовал в разработке мультимодальной модели Gemini и оценке в Google DeepMind. Этот опыт также очень важен. Длительное участие в разработке передовых моделей позволило ему лучше понять, как растут способности моделей, и легче увидеть возможные смещения и слепые зоны в оценке.
Осенью 2022 года Чэнь Вэньху присоединился к факультету компьютерных наук Университета Ватерлоо в качестве доцента. В том же году он был избран членом программы Canada CIFAR AI Chair. После этого он основал «Лабораторию Тигра» (TIGERLab, «Банду Тигровой Головы»), продолжив исследования в области базовых моделей, мультимодальных способностей и бенчмарков оценки.
«Банда Тигровой Головы» занимается не только бенчмарками оценки, но и исследованиями моделей и систем.
В направлении видео, UniVideo пытается объединить понимание, генерацию и редактирование видео в одной структуре, чтобы модель не просто генерировала видеоряд, но и понимала содержание, реагировала на инструкции и выполняла изменения. Vamba ориентирована на понимание длинных видео, решая проблемы с памятью, вычислениями и эффективностью обучения, возникающие при работе с видео продолжительностью около часа. Совместный с командой Meta Generative AI проект MoCha сосредоточен на генерации говорящих виртуальных персонажей, создавая высококачественные видеоролики с персонажами на основе голоса и текстового описания.

Составитель тестов, который никогда не решает задачи, не может составить хороший тест. Самостоятельная разработка моделей, в свою очередь, делает их более подходящими для оценки.
Потому что по-настоящему хорошая оценка часто исходит из понимания границ возможностей модели. Только зная, как создаются модели, зная, с какими проблемами они сталкиваются в реальных задачах, легче разработать тесты, которые выявят различия и обнажат проблемы.
В настоящее время Чэнь Вэньху присоединился к лаборатории суперинтеллекта Meta, где продолжает сосредотачиваться на данных для мультимодального предобучения и оценке, работая над базовыми моделями Meta.
В индустрии ИИ нет недостатка в людях, которых видят. В сфере ИИ внимание обычно сосредоточено на предпринимателях, ведущих исследователях и руководителях крупных компаний, разрабатывающих модели. Выпуск новых продуктов, новости о финансировании, open-source модели и изменения в командах чаще всего привлекают внимание извне, и эти имена легче попадают в поле зрения общественности.
Но сегодня участие китайских талантов в области ИИ выходит далеко за рамки этих самых заметных позиций.
Эта статья из официального аккаунта WeChat «字母AI», автор: Сяо Цзинья






