Written by: KarenZ, Foresight News
Original title: Plain Language Breakdown of X's New Recommendation Algorithm: From "Data Fishing" to "Scoring"
Has Musk changed Twitter's recommendation system from "manually stacking rules and mostly heuristic algorithms" to "purely relying on AI large models to guess what you like"?
On January 20, Twitter (X) officially disclosed the new recommendation algorithm, which is the logic behind the "For You" timeline on the Twitter homepage.
Simply put, the current algorithm is: mixing "content posted by people you follow" and "content from the entire network that might suit your taste," then sorting it based on a series of your previous actions on X, such as likes, comments, etc., according to its appeal to you. After two rounds of filtering, it eventually becomes the recommended information flow you see.
Below is the core logic translated into plain language:
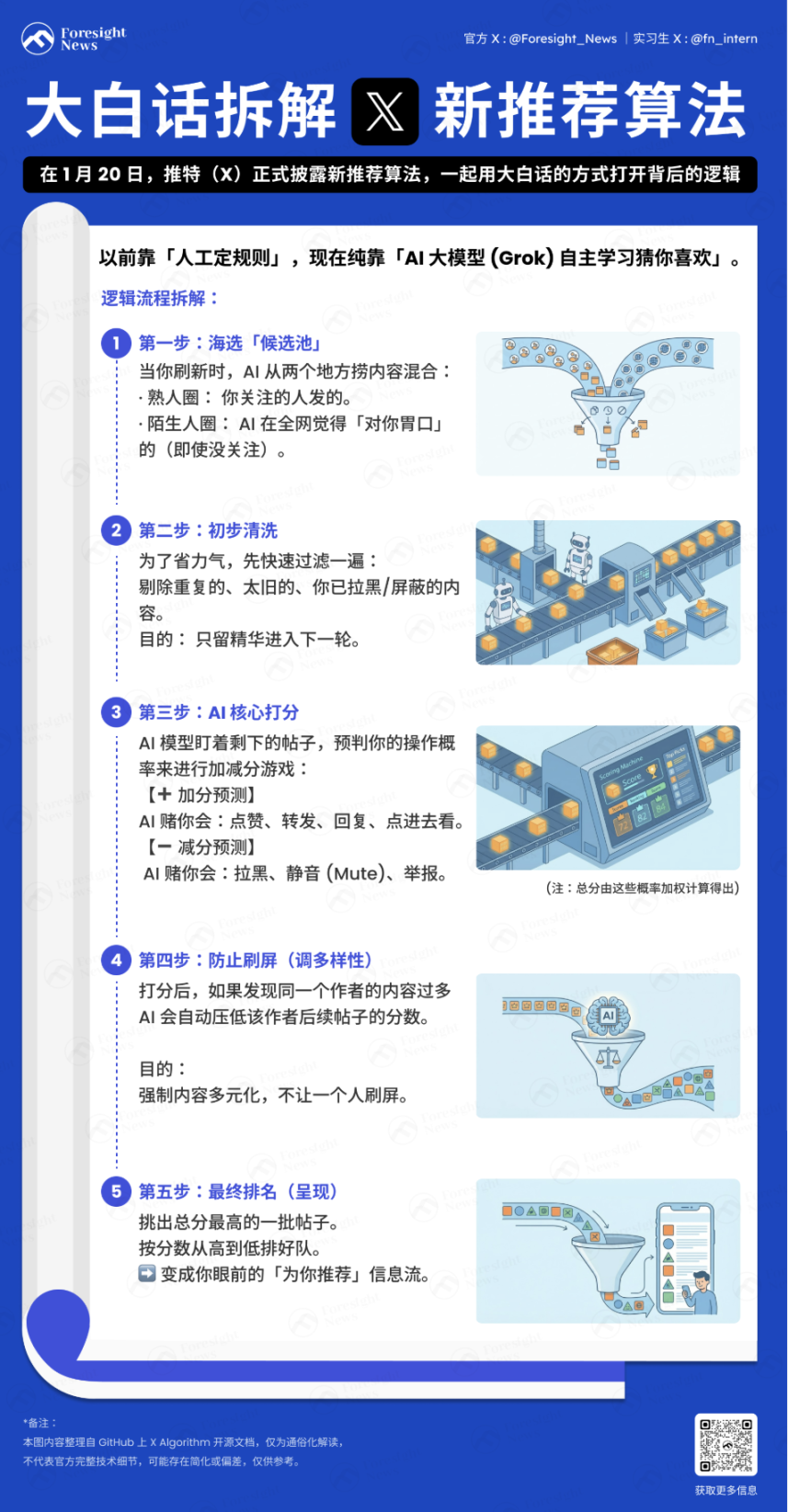
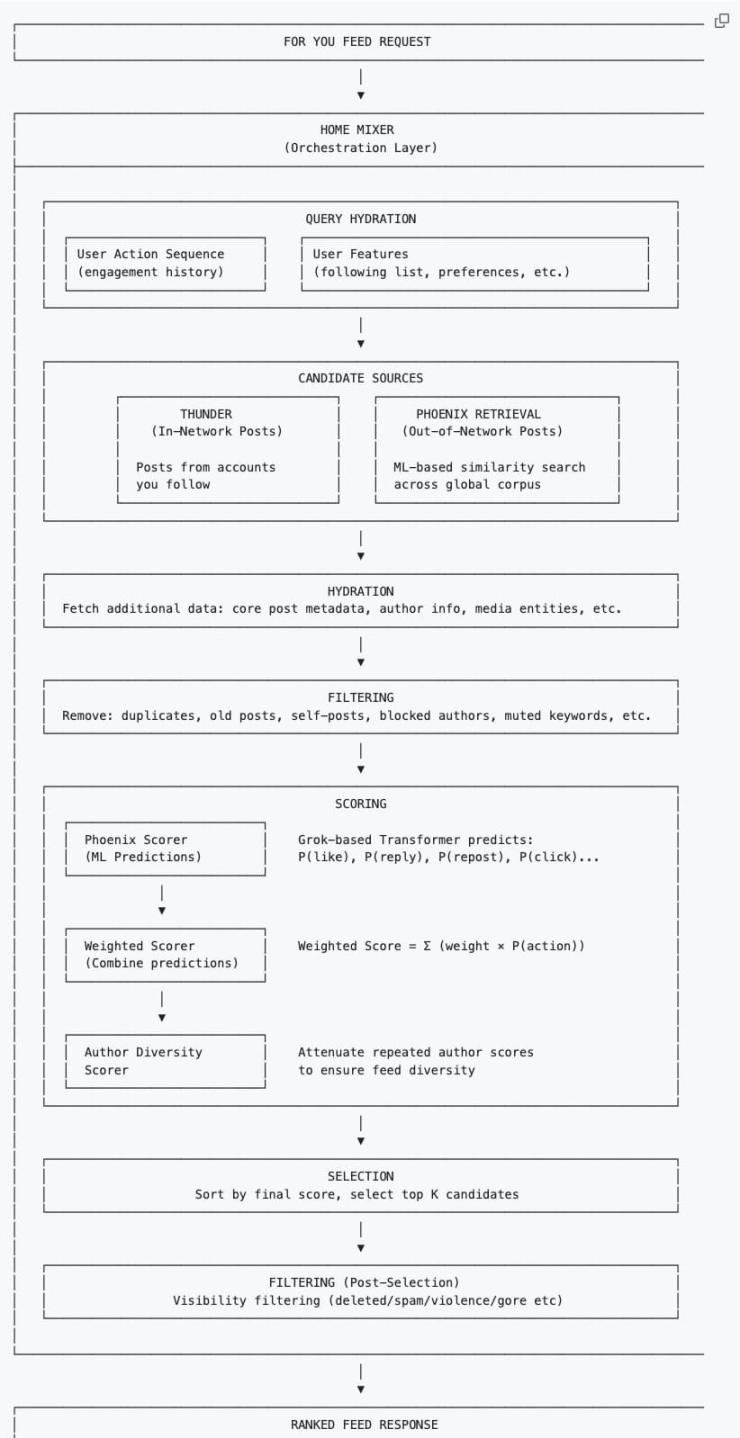
Building a Profile
The system first collects the user's contextual information to build a "profile" for subsequent recommendations:
-
User behavior sequence: Historical interaction records (likes, retweets, dwell time, etc.).
-
User features: Follow list, personal preference settings, etc.
Where does the content come from?
Every time you refresh the "For You" timeline, the algorithm fetches content from the following two sources:
-
Inner Circle (Thunder): Tweets from people you follow.
-
Outer Circle (Phoenix): Posts from people you don't follow, but which the AI, based on your taste, fishes out from the vast sea of people as posts you might be interested in (even if you don't follow the author).
These two piles of content are mixed together to form the candidate tweets.
Data Completion and Preliminary Filtering
After fishing up thousands of posts, the system pulls the complete metadata of the posts (author information, media files, core text). This process is called Hydration. Then it performs a quick cleaning round, eliminating duplicate content, old posts, posts the user themselves posted, content from blocked authors, or content containing muted keywords.
This step is to save computing resources and prevent invalid content from entering the core scoring phase.
How is scoring done?
This is the most crucial part. The Transformer model based on Phoenix Grok scrutinizes each remaining candidate post after filtering and calculates the probability of you performing various actions on it. It's a game of adding and subtracting points:
Plus points (Positive feedback): The AI thinks you are likely to like, retweet, reply, click on the image, or click to view the profile.
Minus points (Negative feedback): The AI thinks you are likely to block the author, mute, or flag the post.

Final Score = (Like probability × weight) + (Reply probability × weight) – (Block probability × weight)...
It is worth noting that in the new recommendation algorithm, the Author Diversity Scorer usually intervenes after the AI calculates the final score. When it detects multiple pieces of content from the same author in a batch of candidate posts, this tool automatically "downgrades" the score of that author's subsequent posts, making the authors you see more diverse.
Finally, sort by score and pick the batch of posts with the highest scores.
Secondary Filtering
The system re-checks the top-scoring posts, filters out violations (such as spam, violent content), deduplicates multiple branches of the same thread, and finally arranges them in order from highest to lowest score, becoming the information flow you see.
Summary
X has removed all manually designed features and most heuristic algorithms from the recommendation system. The core advancement of the new algorithm lies in "letting the AI autonomously learn user preferences," achieving a leap from "telling the machine what to do" to "letting the machine learn how to do it itself."
First, recommendations are more accurate, and "multi-dimensional prediction" fits real needs better. The new algorithm relies on the Grok large model to predict various user behaviors—not only calculating "whether you will like/retweet" but also calculating "whether you will click the link to view," "how long you will stay," "whether you will follow the author," and even predicting "whether you will report/block." This refined judgment allows the recommended content to fit users' subconscious needs with unprecedented precision.
Second, the algorithm mechanism is relatively fairer and can, to some extent, break the curse of "big account monopoly," giving new and small accounts more opportunities: The old "heuristic algorithm" had a fatal problem: big accounts, relying on historically high interaction volumes, could get high exposure no matter what content they posted, while new accounts, even with high-quality content, were buried due to "lack of data accumulation." The candidate isolation mechanism allows each post to be scored independently, unrelated to "whether other content in the same batch is a hit." At the same time, the Author Diversity Scorer also reduces the spamming behavior of subsequent posts by the same author in the same batch.
For X the company: This is a cost-reducing and efficiency-increasing measure, using computing power to replace manpower, and using AI to improve retention. For users, we are dealing with a "super brain" that constantly tries to read our minds. The more it understands us, the more we rely on it. But precisely because it understands us too well, we will sink deeper into the "information cocoon" woven by the algorithm and become more easily targeted by emotionally charged content.
Twitter:https://twitter.com/BitpushNewsCN
Bitpush TG Discussion Group:https://t.me/BitPushCommunity
Bitpush TG Subscription: https://t.me/bitpush





