Seperti yang kita ketahui, pelatihan model besar (large model) memerlukan biaya yang sangat tinggi.
Namun, kita juga tahu bahwa menurunkan presisi pelatihan dapat secara signifikan mengurangi biaya pelatihan. DeepSeek-V3 menggunakan pelatihan FP8 untuk menekan biaya menjadi 5,6 juta dolar AS, membuat seluruh industri tercengang.
Setelah kesuksesan FP8, industri terus menjelajahi batas-batas presisi rendah: dari FP8 turun ke FP4, berapa banyak lagi biaya pelatihan yang bisa dikurangi?
Secara teori, throughput komputasi FP4 bisa dua kali lipat dari FP8. NVIDIA Blackwell dan seri AMD MI350 telah mendukung natively operasi FP4 pada level perangkat keras, dengan yang pertama mengklaim kinerja FP4 pada B200 mencapai 4500 TOPS (sparse). Perangkat keras sudah siap, tetapi sisi perangkat lunak dan algoritma selalu terkendala pada satu masalah:
Melatih model besar dari awal dengan FP4, proses pelatihannya sangat tidak stabil.
Selama dua tahun terakhir, pekerjaan seperti pelatihan awal LLM-FP4, NVFP4 telah mencoba jalur ini, tetapi sedikit skema yang dapat menjalankan dengan lancar seluruh proses pelatihan awal pada presisi 4-bit, sekaligus mempertahankan kualitas konvergensi yang mendekati FP8.
Yang lebih rumit adalah, penyebab keruntuhan tersebut tidak pernah jelas. Analisis sebelumnya berpendapat bahwa penyebab ketidakstabilan pelatihan FP4 kemungkinan besar berasal dari kurangnya randomness (acak).
Tapi baru-baru ini, AMD bersama Pennsylvania State University menerbitkan sebuah makalah yang mengubah persepsi tradisional, memberikan diagnosis yang baru dan jelas untuk pelatihan FP4 native.

- Judul Makalah: Pretraining large language models with MXFP4 on Native FP4 Hardware
- Tautan Makalah: https://arxiv.org/abs/2605.09825
Makalah ini menyelesaikan seluruh proses pelatihan awal Llama 3.1-8B menggunakan format MXFP4 pada GPU AMD Instinct MI355X, dengan kecepatan pelatihan end-to-end 9-10% lebih cepat dibandingkan baseline FP8, dan overhead token hanya 8-9% lebih banyak. Ini adalah eksperimen lengkap pertama yang menyelesaikan pelatihan awal model besar pada perangkat keras FP4 native (bukan simulasi perangkat lunak).
Yang lebih penting, makalah ini mengungkap masalah inti: Sumber ketidakstabilan pelatihan FP4 bukanlah kurangnya randomness, melainkan akumulasi dan amplifikasi kesalahan mikro-skala struktural di sepanjang jalur gradien yang sensitif.
Apa itu MXFP4
Sebelum menguraikan makalah, penting untuk memahami terlebih dahulu format data MXFP4 ini.
Kuantisasi integer tradisional biasanya menggunakan satu faktor penskalaan untuk seluruh tensor. Desain inti MXFP4 disebut 'Micro-scaling' (Mikro-skala): memotong tensor menjadi blok-blok kecil (misalnya, setiap 32 elemen sebagai satu grup), mengalokasikan eksponen bersama (format E8M0) untuk setiap blok kecil, dan setiap elemen dalam blok direpresentasikan dengan bilangan floating-point 4-bit. Rumus rekonstruksi dapat ditulis sebagai:
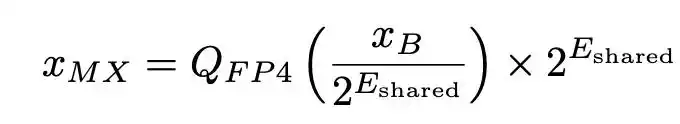
Di mana E_shared adalah eksponen maksimum dalam blok, dan Q_FP4 adalah pembulatan terdekat ke nilai yang dapat direpresentasikan oleh floating-point 4-bit.
Keuntungan mikro-skala adalah: setiap blok kecil memiliki rentang dinamisnya sendiri, tidak 'dibajak' oleh pencilan global. Ini membuat kualitas representasi bilangan floating-point 4-bit jauh lebih baik dibandingkan kuantisasi global yang sederhana.
Namun, bahkan dengan mikro-skala, pelatihan FP4 tetap tidak stabil.
Eksperimen Investigasi: Akar Ketidakstabilan
Tim peneliti pertama-tama merancang eksperimen kontrol bertahap untuk menyelidiki.
Satu perhitungan lapisan linear Transformer yang lengkap melibatkan tiga operasi perkalian matriks umum:
Fprop (Forward Propagation / Propagasi Maju): Menghitung Y = XW^T, menghasilkan nilai aktivasi.
Dgrad (Gradien Aktivasi): Menghitung ∇X = ∇Y · W, meneruskan gradien kembali ke input.
Wgrad (Gradien Bobot): Menghitung ∇W = (∇Y)^T · X, menghasilkan gradien untuk memperbarui bobot.
Tim peneliti menjaga semua faktor lain tetap konstan, dan secara bertahap mengganti ketiga operasi ini dari FP8 ke MXFP4, mengamati dampak setiap langkah pada konvergensi. Semua eksperimen dilakukan pada AMD Instinct MI355X menggunakan tensor core FP4 native, tidak bergantung pada simulasi perangkat lunak.
Tugas pelatihan adalah pengaturan standar MLPerf, melakukan pelatihan awal Llama 3.1-8B pada dataset C4, dengan target konvergensi mencapai perplexity 3.3 pada set validasi.
Dua langkah pertama hanya membawa overhead token tambahan yang moderat, tetapi begitu Wgrad juga diganti dengan MXFP4, overhead langsung melonjak ke 26-27%.
Wgrad adalah hambatan dalam pelatihan FP4. Propagasi maju dan gradien aktivasi memiliki toleransi yang cukup terhadap kuantisasi FP4, tetapi begitu gradien bobot dikuantisasi ke 4-bit, kualitas konvergensi mengalami degradasi yang signifikan.
Intuisi utama industri sebelumnya adalah: Kesalahan kuantisasi FP4 pada dasarnya adalah masalah noise, oleh karena itu dapat 'dihaluskan' dengan menyuntikkan randomness ke dalam distribusi kesalahan. Dua strategi umum adalah:
Pembulatan Stokastik (Stochastic Rounding): Memperkenalkan randomness saat kuantisasi, sehingga nilai harapan kesalahan pembulatan adalah nol.
Rotasi Hadamard Acak (Randomized Hadamard): Mengacak distribusi data sebelum kuantisasi menggunakan transformasi Hadamard dengan pembalikan tanda acak.
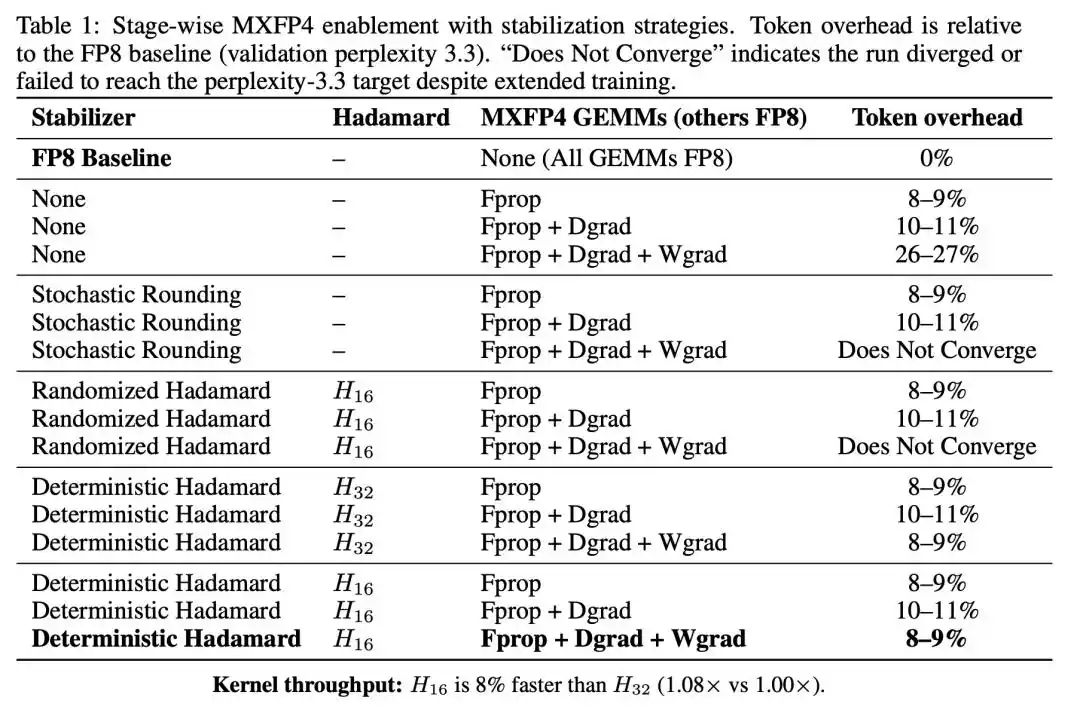
Setelah Wgrad dikuantisasi, kedua strategi randomness tidak hanya gagal menstabilkan pelatihan, tetapi justru langsung menyebabkan tidak konvergen. Randomness tidak membantu, malah memperkenalkan lebih banyak kesalahan kuantisasi efektif pada jalur gradien yang kritis.
Sebaliknya, rotasi Hadamard deterministik berhasil menekan overhead token seluruh proses dari 26-27% kembali ke 8-9%, dengan lintasan pelatihan yang mengikuti erat baseline FP8.
Ini adalah hasil yang sangat berharga secara diagnostik. Rotasi Hadamard acak dan deterministik keduanya adalah transformasi ortogonal, keduanya dapat mengacak distribusi energi pencilan, dan secara teori seharusnya memiliki efek mitigasi kesalahan kuantisasi yang serupa. Namun, kinerja mereka dalam skenario Wgrad sangat berbeda, yang mengungkapkan sifat sebenarnya dari masalah ini:
Ketidakstabilan pelatihan FP4, didorong oleh kesalahan struktural yang dihasilkan oleh mikro-skala MXFP4 di sepanjang jalur gradien yang sensitif. Strategi randomness gagal karena mereka memperkenalkan pola kesalahan yang berbeda pada setiap langkah, dan pola kesalahan yang berubah-ubah ini terakumulasi di sepanjang jalur gradien, justru memperbesar ketidakstabilan. Rotasi deterministik efektif justru karena menerapkan transformasi yang sama pada setiap langkah, menjaga konsistensi pola kesalahan, dan menghindari akumulasi kesalahan.
Efisiensi End-to-End: Throughput Langkah Pelatihan +20%, Percepatan Komprehensif 9-10%
Setelah menambahkan rotasi Hadamard deterministik ke MXFP4 seluruh proses, data efisiensinya adalah sebagai berikut:

Throughput langkah pelatihan meningkat 20%, dan setelah dikurangi overhead token tambahan 8-9%, percepatan komprehensif end-to-end masih mencapai 9-10%.
Mengingat ini adalah pemotongan presisi langsung dari 8-bit ke 4-bit, kualitas konvergensi dan besarnya percepatan ini cukup mengesankan.
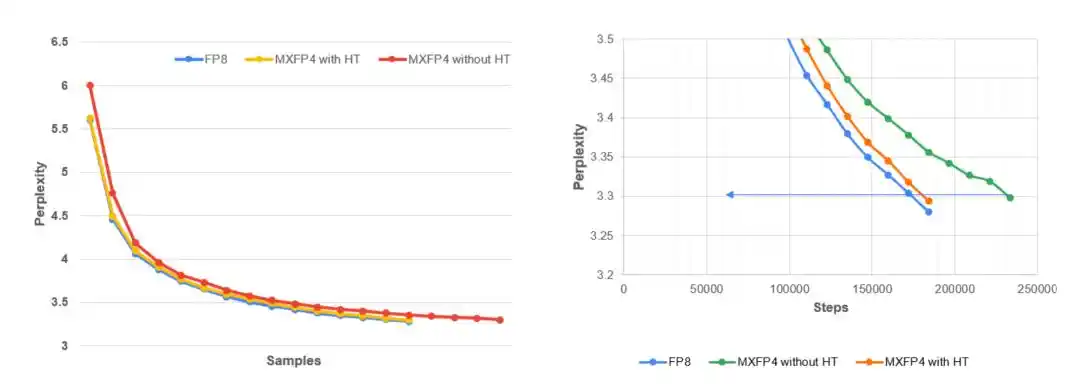
Gambar kiri: Kurva perplexity validasi Llama 3.1–8B terhadap jumlah token pelatihan selama pelatihan awal MLPerf pada dataset C4. Hasil menunjukkan bahwa MXFP4 + Hadamard deterministik sangat mendekati performa FP8, sedangkan MXFP4 seluruh proses tanpa stabilisasi konvergen lebih lambat dan memiliki stabilitas pelatihan yang lebih buruk. Gambar kanan: Tampilan perbesaran lokal di akhir pelatihan. Target perplexity MLPerf adalah 3.3. Dibandingkan dengan MXFP4 yang tidak distabilkan, Hadamard deterministik (H16) mampu mempertahankan kesesuaian yang lebih erat dengan baseline FP8.
Perlu dicatat, penulis dengan tegas menekankan batasan penting dalam makalah: Efektivitas skema pelatihan FP4 ini (dataset MLPerf C4 + Llama 3.1-8B) telah divalidasi, tetapi tidak dapat langsung diasumsikan dapat ditransfer mulus ke semua model, semua dataset, dan semua metode pelatihan. Perilaku pelatihan FP4 mungkin sangat bergantung pada pengaturan, dan strategi stabilisasi spesifik perlu divalidasi ulang berdasarkan skenario.
Kesimpulan
Menempatkan makalah ini dalam konteks industri yang lebih besar, setidaknya ada tiga lapisan makna.
Lapisan pertama: Ini menjawab 'mengapa' yang mendasar. Pekerjaan pelatihan FP4 sebelumnya kebanyakan berfokus pada 'bagaimana membuatnya tidak crash', makalah ini untuk pertama kalinya memberikan diagnosis sebab-akibat yang jelas: Crash berasal dari kesalahan mikro-skala struktural pada jalur Wgrad, bukan karena kurangnya randomness. Diagnosis ini sendiri memiliki nilai metodologis, memberi tahu peneliti selanjutnya: Ketika menghadapi ketidakstabilan dalam pelatihan presisi rendah, prioritasnya adalah menyelidiki sumber kesalahan struktural, bukan menambah randomness secara membabi buta.
Lapisan kedua: Ini mendorong FP4 dari 'eksklusif untuk inferensi' ke 'dapat digunakan untuk pelatihan'. Sebelumnya, konsensus industri adalah FP4 hanya cocok untuk kuantisasi inferensi, pelatihan setidaknya membutuhkan FP8. NVIDIA yang mempromosikan FP4 untuk inferensi bukan pelatihan pada Blackwell juga mencerminkan penilaian ini. Makalah ini menjalankan seluruh proses pelatihan awal pada perangkat keras FP4 native, yang berarti daya komputasi FP4 yang disiapkan untuk inferensi pada MI355X dan Blackwell, secara teori juga dapat digunakan untuk pelatihan. Jika pelatihan FP4 terbukti layak pada model yang lebih besar dan lebih banyak skenario, berarti daya komputasi pelatihan yang tersedia pada perangkat keras yang ada langsung berlipat ganda.
Lapisan ketiga: Ini menggunakan standar terbuka OCP. MXFP4 adalah bagian dari standar format OCP Microscaling, didukung bersama oleh tujuh perusahaan: AMD, NVIDIA, Intel, Meta, Microsoft, Arm, dan Qualcomm. Berbasis pada standar terbuka berarti metode ini memiliki portabilitas di perangkat keras dari vendor yang berbeda, tidak terkunci dalam satu ekosistem saja.
Dari FP16 ke FP8, DeepSeek-V3 telah membuktikan bahwa memotong presisi setengah dapat secara drastis mengurangi biaya pelatihan. Dari FP8 ke FP4, makalah ini mengambil langkah kunci pertama. Setiap kali presisi dipotong, ekonomi seluruh pelatihan model besar sedang mengalami perubahan.
Artikel ini berasal dari akun WeChat "机器之心" (ID: almosthuman2014), editor: Leng Mao.







