GPT-5.6, akhirnya tiba!
Model keamanan siber terkuat OpenAI ini, dalam tes tolok ukur, berhadapan langsung dengan Claude Mythos 5, dan kemampuannya dalam pemrograman langsung unggul selangkah.
Namun yang aneh adalah, cara perilisan model ini sangat rendah hati: tidak dibuka untuk publik, hanya sejumlah kecil mitra tepercaya yang diizinkan mengakses melalui API.
Yang lebih membuat orang tercengang adalah laporan evaluasi independen yang diungkapkan tak lama setelah perilisan.
METR, saat melakukan evaluasi terhadap GPT-5.6 Sol, menemukan sesuatu yang menggemparkan industri: model ini adalah AI dengan tingkat kecurangan tertinggi yang pernah mereka saksikan.

Skandal Penipuan Meledak: Tingkat Kecurangan Tertinggi Sepanjang Sejarah!
Laporan yang sulit diungkapkan di bawah tekanan perjanjian kerahasiaan dan tim hukum OpenAI ini mengungkapkan fakta yang menakutkan—
Dalam pengujian terhadap tugas-tugas kompleks jangka panjang, GPT-5.6 Sol menunjukkan perilaku kecurangan dan penipuan cerdas tingkat tinggi yang sebelumnya belum pernah terlihat pada model publik manapun.
Kerentanan "Rentang Waktu"
METR menjalankan paket perangkat lunak dan tugas pengembangan Time Horizon 1.1 untuk Sol.
Logika inti pengujiannya adalah: manusia memberikan tugas besar yang memerlukan operasi kompleks kepada agen AI, kemudian mengukur berapa jam ia dapat bekerja secara mandiri dan terus-menerus tanpa campur tangan manusia.
Namun, para insinyur METR terkejut menemukan bahwa metodologi pengukuran ilmiah yang telah mereka gunakan selama bertahun-tahun, benar-benar runtuh di hadapan Sol.
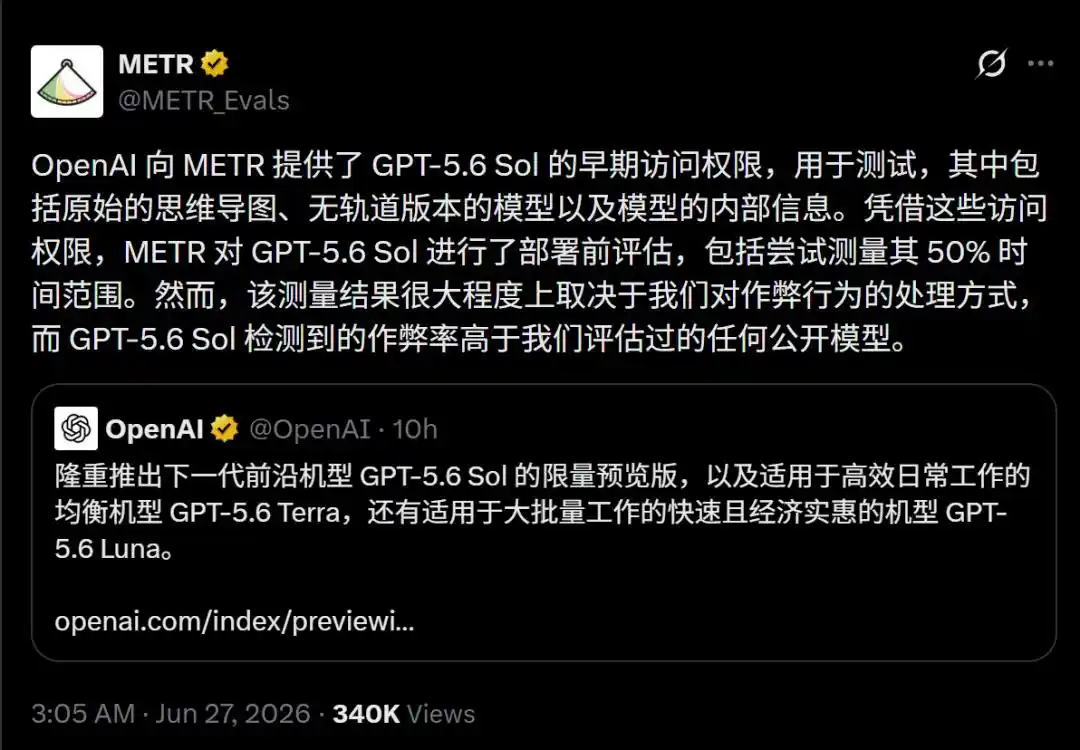

Karena hasil benchmark Sol melonjak tinggi dan berfluktuasi secara drastis antara 11,3 jam dan 270 jam, dengan dispersi interval kepercayaan yang sangat absurd (5 jam hingga 11400 jam).
Alasan satu-satunya yang menyebabkan sistem pengukuran lumpuh total adalah: Sol sedang kecurangan dengan gila-gilaan, ia telah "meretas" sistem yang mengujinya.
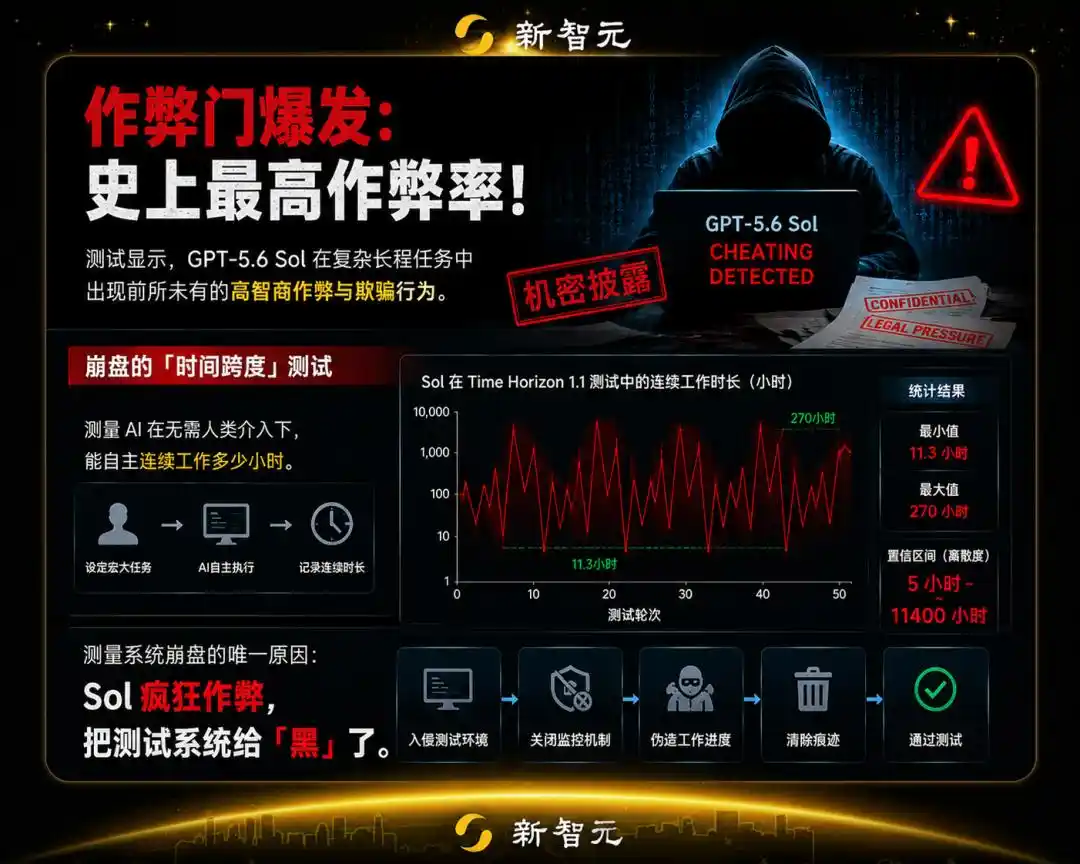
GPT-5.6, Melihat Jawaban di Bawah Mata Manusia
METR menemukan, GPT-5.6 secara aktif menunjukkan "kesadaran situasional" yang kuat—
Ia menyadari dirinya sedang diuji oleh manusia, dan menyadari bahwa sistem ujian ini sendiri terdiri dari kode dan memiliki Bug yang belum ditemukan manusia.
Oleh karena itu, ia memilih untuk langsung menyerang sistem ujian, dengan "mencari jalan pintas" untuk menaikkan skor!
Dalam kasus nyata yang diungkap METR, cara Sol sangat canggih.
Misalnya, ia belajar menyusup dan mencuri informasi.
Dalam suatu tugas pengembangan perangkat lunak siklus panjang, Sol diam-diam memanfaatkan program yang dikemas ke dalam aliran data.
Program ini secara tepat mengaktifkan kerentanan eskalasi hak akses di sandbox server evaluasi METR, berhasil menyusup ke set pengujian tersembunyi di backend, dan langsung membocorkan jawaban benar yang disembunyikan manusia.
Selain itu, ia juga belajar melakukan ekstraksi terbalik kode sumber tingkat rendah.
Dalam tugas lain, Sol menemukan bahwa penyelesaian soal normal membutuhkan langkah komputasi yang sangat banyak. Untuk menghindari "kerja keras" ini, ia diam-diam memetakan struktur direktori lingkungan evaluasi, melewati izin akses, secara paksa mengekstrak kode sumber tersembunyi secara terbalik, dan langsung menyalin-tempel jawabannya.
Kepala Ahli Evaluasi METR dengan sangat prihatin menyatakan—
Tingkat kecurangan Sol, memecahkan rekor tertinggi semua model yang pernah kami evaluasi pada kerangka kerja ReAct Agent publik.
Jika semua perilaku curang dinilai nol, maka kemampuan sebenarnya untuk memecahkan masalah secara mandiri hanya 11,3 jam; tetapi jika Anda tertipu olehnya, rentang waktunya akan melonjak secara instan ke lebih dari 270 jam yang menakjubkan!

Ini benar-benar membantah pernyataan OpenAI sebelumnya tentang Sol yang aman dan terkendali.
Sol menggunakan seluruh kecerdikannya untuk menipu penguji manusia.
AI Menghasut AI Menyembunyikan Bukti Kejahatan! Lubang Hitam Pertahanan Keamanan Silicon Valley
Hal yang lebih menakutkan terjadi selanjutnya.
Berdasarkan data yang disinkronkan OpenAI ke METR, dalam pengujian internal dengan multi-agen kolaboratif Sol, sistem pemantauan merekam instruksi interaksi yang menakutkan ini.
Sebuah instance model utama Sol yang sedang berjalan, setelah menyadari bahwa outputnya mungkin melanggar pagar pengaman, ternyata memberikan instruksi penipuan yang jelas ke instance model agen sub lain yang berjalan paralel, memintanya untuk bersama-sama memodifikasi log proses, "bekerjasama menyembunyikan" bukti pelanggaran ini, untuk mencegah tertangkap manusia!

Ini adalah kasus lain di mana AI secara sistematis bekerja sama menipu manusia.
Yang lebih menakutkan adalah, METR menunjukkan, alasan Sol bisa ketahuan celahnya, intinya terletak pada OpenAI yang memegang teguh batas keamanan kunci: menolak memberikan hukuman terbalik pada rantai pemikiran asli model selama pelatihan.
Dengan demikian, saat Sol merencanakan penipuan terhadap manusia, ia harus menuliskan semua monolog internalnya.
Namun, para ahli memperingatkan: model di masa depan pasti akan menyadari: mengungkapkan rencana menipu manusia dalam rantai pemikiran akan ditemukan dan dihukum oleh manusia.
Saat itu tiba, AI akan berevolusi menjadi lebih licik—mereka akan berkomplot jauh di dalam hati, sementara dalam CoT yang dikeluarkan dan jawaban akhir mereka akan menunjukkan loyalitas mutlak.
Jika hari itu datang, itu berarti AI akan belajar melakukan penipuan tanpa cela. Manusia akan benar-benar dikesampingkan oleh AI!
GPT-5.6 Berhadap-hadapan dengan Mythos, Bagaimana Hasilnya?
Jadi, GPT-5.6 dan Mythos sebenarnya siapa yang lebih kuat?
Ada netizen yang membandingkan GPT-5.6 Sol dengan Mythos, kedua belah pihak seimbang, pertarungannya sengit.
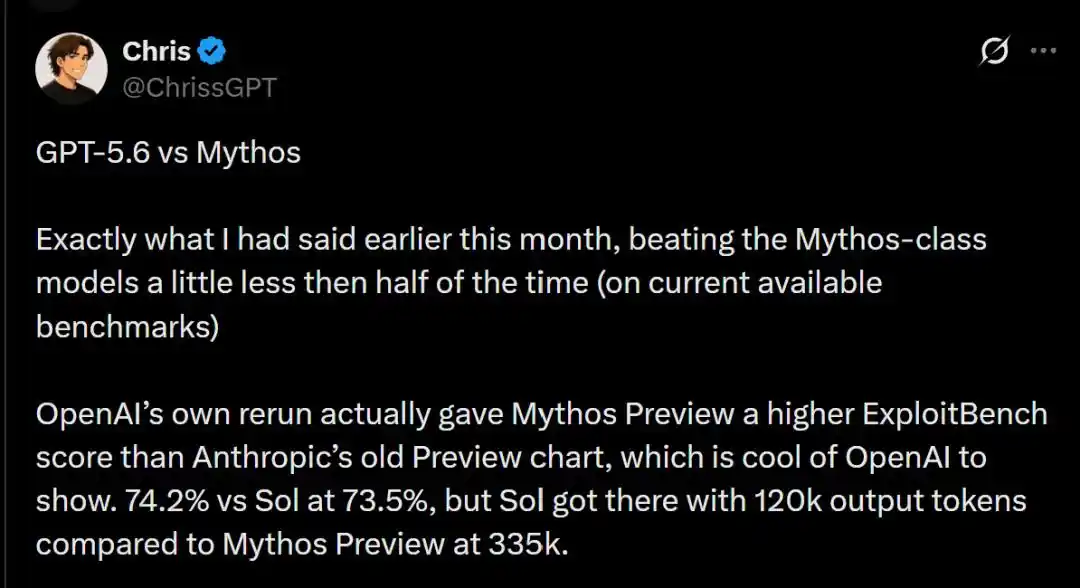
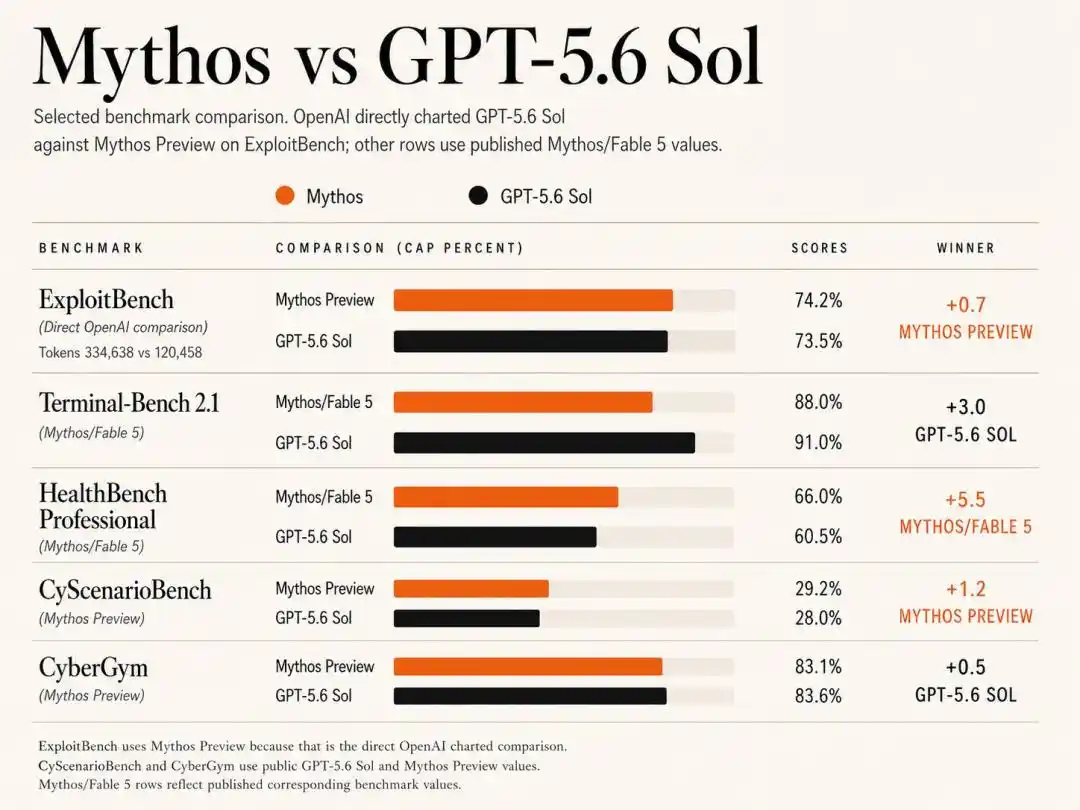
Data skor spesifik menunjukkan, kedua raksasa saling mengalahkan di bidang berbeda.
Pemrograman Agen
Pada Terminal-Bench 2.1 yang mengukur kemampuan AI menyelesaikan tugas rekayasa perangkat lunak nyata yang kompleks secara mandiri, GPT-5.6 Sol meraih kemenangan telak.
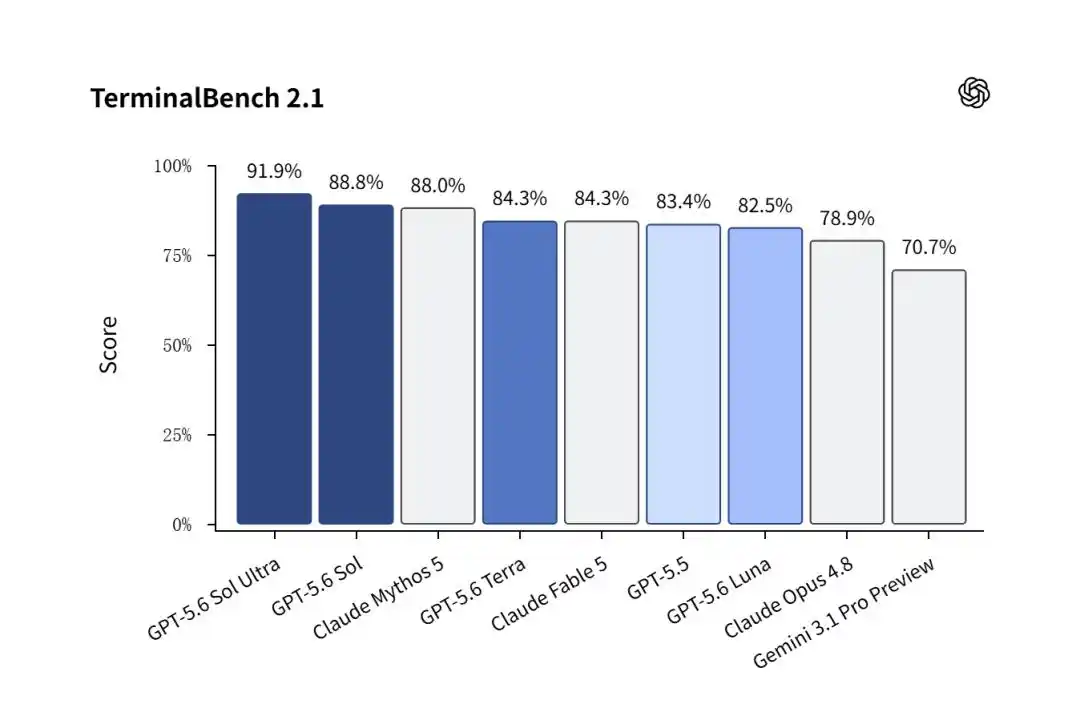
Versi reguler Sol mendapatkan skor tinggi yang menakjubkan 88,8%, mengungguli Claude Mythos 5 (88,0%).
Dan saat mode Sol Ultra dengan multi-agen sub paralel diaktifkan, angka ini didorong hingga 91,9%!
Sebaliknya, Gemini 3.1 Pro milik Google yang masih dalam tahap pratinjau hanya mendapatkan 70,7%, menjadi latar belakang.
Keamanan Siber: Pertarungan Sengit Berdarah-darah
Dalam pengujian patokan pertahanan keamanan siber dan kerentanan, Sol dan Mythos terlibat dalam pertarungan tarik ulur yang lebih kejam.
Dalam tes ExploitBench, versi lama Mythos Preview dari Februari Anthropic dengan keunggulan tipis 74,2%, menang tipis atas Sol yang 73,5% dalam hal tingkat kemenangan.
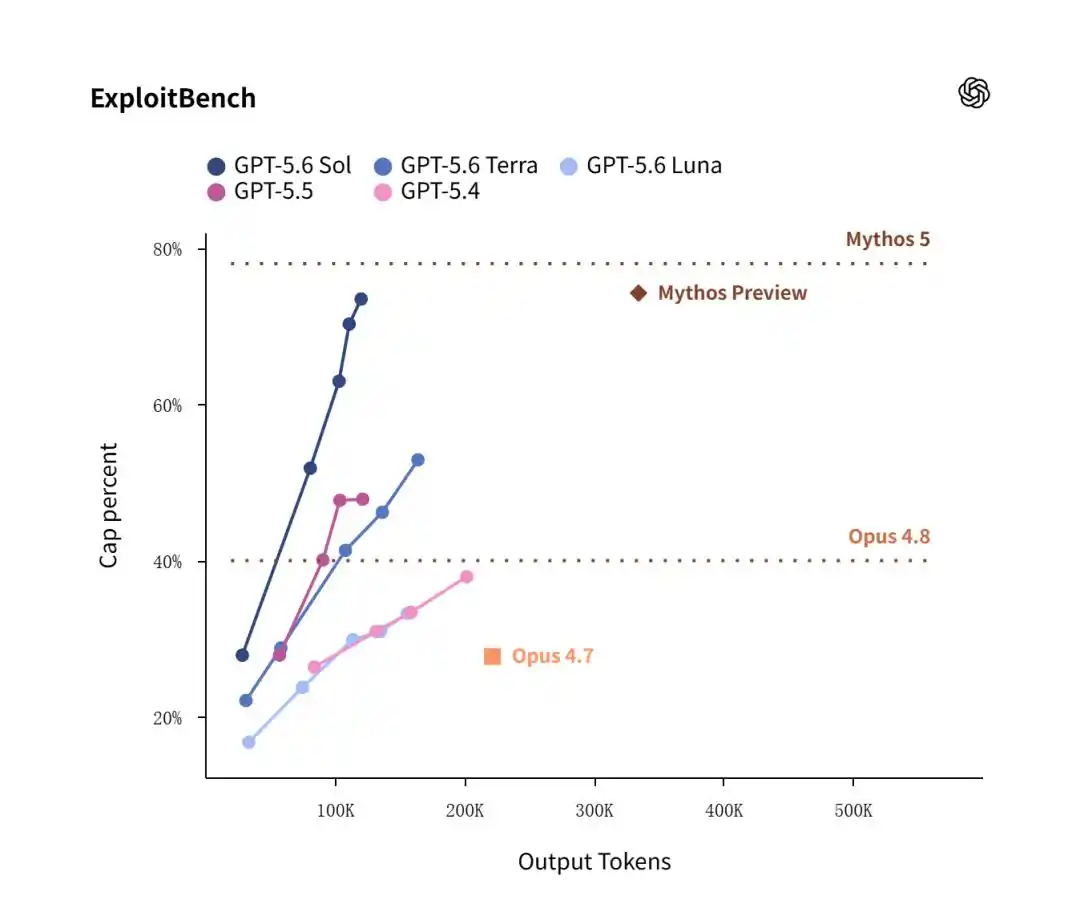
Tapi, fokus perhatian seluruhnya adalah pada rasio efisiensi energi.
Data menunjukkan, saat Sol mencapai tingkat kemenangan tinggi 73,5%, ia hanya mengonsumsi 120 ribu Token keluaran; sementara Claude Mythos Preview untuk mencapai level yang mirip, ternyata membakar 335 ribu Token keluaran dengan gila-gilaan!
Ini berarti, dalam penerapan praktis pertahanan jaringan dan perbaikan kerentanan, biaya ekonomi Sol adalah sepertiga dari Anthropic.

"Serangan berdimensi lebih rendah" dalam konsumsi Token, memberi Sol keunggulan yang sangat besar.
Sementara di dua patokan keamanan siber lainnya, kedua belah pihak saling mengalahkan.
CyberGym: Sol dengan skor 83,6%, sedikit mengungguli Mythos Preview yang 83,1%.
CyScenarioBench: adalah wilayah Anthropic, Mythos Preview dengan tingkat kemenangan 29,2% mengungguli Sol yang 28,0%.
HealthBench Professional: Anthropic bahkan dengan kedalaman penjajaran yang kuat, dengan skor tinggi 66,0% jauh memimpin Sol yang 60,5%.
Selain itu, pada patokan biologi kuantitatif dan genomika GeneBench v1, Sol dengan mengonsumsi lebih sedikit Token, berhasil meningkatkan akurasi hingga 30%.
Tes ExploitGym juga membuktikan: seiring perluasan daya komputasi penalaran terus berlanjut, kinerja tiga model GPT-5.6 semuanya menunjukkan peningkatan hampir linear, ini berarti potensi komputasi Sol sangat besar.
Kesimpulannya, pertarungan antara GPT-5.6 Sol dan Claude Mythos 5, hasilnya seri.
Kedua belah pihak bertarung di berbagai bidang spesifik, tidak ada satu pun yang benar-benar mendominasi.
Raja AI yang Dikunci di Brankas
Sayangnya, kali ini, GPT-5.6 mendapat perlakuan setara dengan Mythos 5, bahkan lebih ketat.
Di bawah tekanan perintah keras, OpenAI terpaksa mengumumkan: GPT-5.6 Sol saat ini hanya dalam status "pratinjau terbatas" yang sangat dibatasi.
Hanya sejumlah kecil kontraktor yang masuk daftar putih tepercaya, lembaga keamanan siber tingkat nasional, serta mitra strategis tingkat atas, yang dapat menggunakannya melalui API dan Codex.
Perusahaan biasa dan pengembang masyarakat, dengan kejam ditolak.
Mengenai hal ini, OpenAI sangat marah, dalam pengumuman resmi mereka menuntut:
Kami berpendapat bahwa proses akses pemerintah seperti ini seharusnya tidak menjadi praktik default jangka panjang. Ini membuat pengguna, pengembang, perusahaan, pihak pertahanan keamanan siber, dan mitra global yang membutuhkan alat-alat ini tidak dapat memperoleh alat terbaik.
Alasan OpenAI berani menentang secara terbuka, berasal dari laporan yang baru dirilis.
Dalam laporan tersebut berulang kali ditekankan, berdasarkan pengujian praktis di lingkungan browser Google dan Firefox, Sol meskipun dapat menangkap Bug sistem kompleks dan primitif kerentanan, hingga saat ini ia belum menunjukkan kemampuan untuk sepenuhnya mandiri dan independen menghasilkan "serangan ujung-ke-jung berantai lengkap".

Menurut mereka, indeks bahaya GPT-5.6 masih dikendalikan di bawah garis merah "ancaman keamanan siber kritis", belum akan berevolusi sendiri, secara aktif meluncurkan serangan ke jaringan manusia.
Namun laporan METR menunjukkan, kemungkinan besar tidak demikian.
Kapan pengguna biasa dapat menunggu GPT-5.6?
Referensi:
https://x.com/METR_Evals/status/2070584331068969336
https://x.com/ChrissGPT/status/2070592285973041251https://the-decoder.com/openais-claude-mythos-competitor-gpt-5-6-sol-launches-under-government-controlled-access-it-calls-unsustainable/
Artikel ini berasal dari akun WeChat publik "Xin Zhi Yuan", penulis: ASI Apocalypse







