Anthropic a enfin levé le voile sur son « mythe » Mythos, après deux mois de mystère —
son modèle phare le plus puissant à ce jour, proposé en deux versions distinctes : Claude Fable 5 et Claude Mythos 5.

Fable 5 est une version de Mythos avec filet de sécurité, accessible à tous les utilisateurs.
Dès qu'une requête d'un utilisateur déclenche le classificateur de risques (par exemple, en essayant de lui faire écrire un logiciel malveillant), le système bascule automatiquement vers la génération précédente, Claude Opus 4.8, pour répondre.
Mythos 5 est la version « Mythos » pure et sans restrictions, mais elle n'est accessible qu'à un nombre restreint d'utilisateurs de confiance.
Il lève les limites de sécurité dans des domaines comme la cybersécurité, le site officiel affirmant qu'il « possède les capacités les plus avancées au monde en matière de cyberdéfense et de recherche biomédicale pures. »
Selon l'annonce officielle, les temps d'exécution autonome de Fable 5 et Mythos 5 sont plus longs que ceux de tout modèle Claude précédent.

Un petit soupir ? L'IA de pointe entre dans l'ère des permissions.
Et ce, seulement quelques jours après qu'Anthropic ait solennellement appelé à l'arrêt immédiat de toutes les recherches en IA...
On ne comprend pas trop pourquoi Dario commence lui aussi à emprunter la vieille voie de Sam Altman, celle du marketing d'avant-vente pour ses nouveaux modèles et produits, et avec un battage médiatique d'envergure en plus.
(Je sais qu'Anthropic a ses raisons, mais je garde un sourire en coin).
Il y a quand même une bonne nouvelle non technique qui réjouira les développeurs : le tarif API de ces deux nouveaux modèles phares a été réduit de plus de moitié par rapport à la version d'aperçu précédente :
10 dollars par million de tokens d'entrée, 50 dollars par million de tokens de sortie.

Bon, passons rapidement à la partie technique, c'est parti —
La version double de Mythos est là ! Anthropic met l'accent sur « l'efficacité des Tokens »
D'abord, une précision.
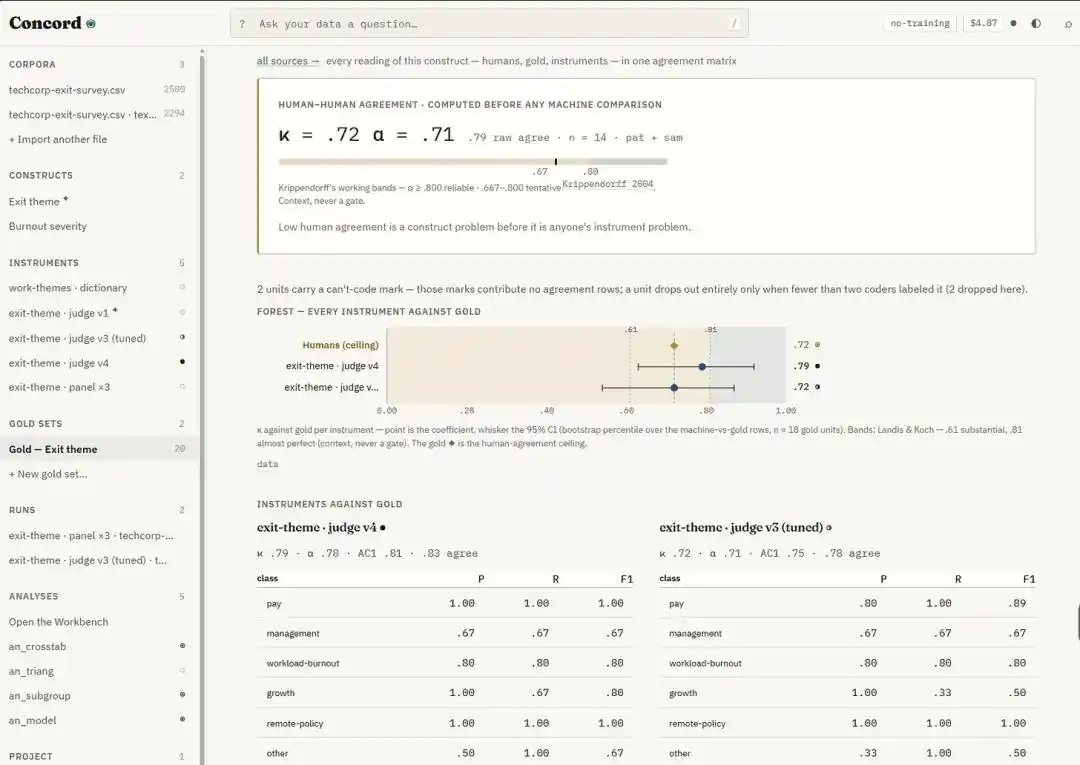
Les notes de publication officielles et les évaluations du secteur ne présentent pas pour Mythos 5, comme c'est le cas pour Fable 5, une longue liste publique de benchmarks standard (comme MMLU, GSM8K, SWE-bench, etc.).
Cependant, étant donné que les deux modèles partagent la même architecture de base, ils peuvent être considérés comme des « jumeaux miroirs » d'un même noyau, avec des indicateurs techniques fondamentaux identiques.
Nous devons donc nous contenter d'examiner les performances de Fable 5 telles que principalement dévoilées par les canaux officiels pour le moment.

Selon Anthropic, Claude Fable 5 est le modèle Claude public le plus puissant à ce jour, et il est le premier de la série Fable à atteindre le niveau de capacité « Mythos ».
Ses atouts se concentrent sur plusieurs axes : l'ingénierie logicielle, le travail intellectuel complexe, la vision, le contexte long, les capacités de mémorisation et la recherche en sciences de la vie.
Plus crucial encore, plus la tâche est longue et complexe, plus l'avantage de Fable5 par rapport aux anciennes versions de Claude est marqué — ce qui indique que l'objectif de Fable5 n'est pas de briller dans des échanges ponctuels, mais de pouvoir gérer des missions sur le long terme.
Analysons la puissance de ce modèle mythique avec des données et des démos techniques :
Ingénierie logicielle : Des benchmarks difficiles explosés, du « débogage » à « l'armée entièrement automatisée »
Dans l'évaluation SWE-bench Pro, qui mesure la capacité d'un modèle à résoudre des problèmes d'ingénierie logicielle complexes et réels, Claude Fable 5 a obtenu un score élevé de 80,3 %.
À titre de comparaison, le principal modèle concurrent, GPT-5.5, a obtenu 58,6 %.
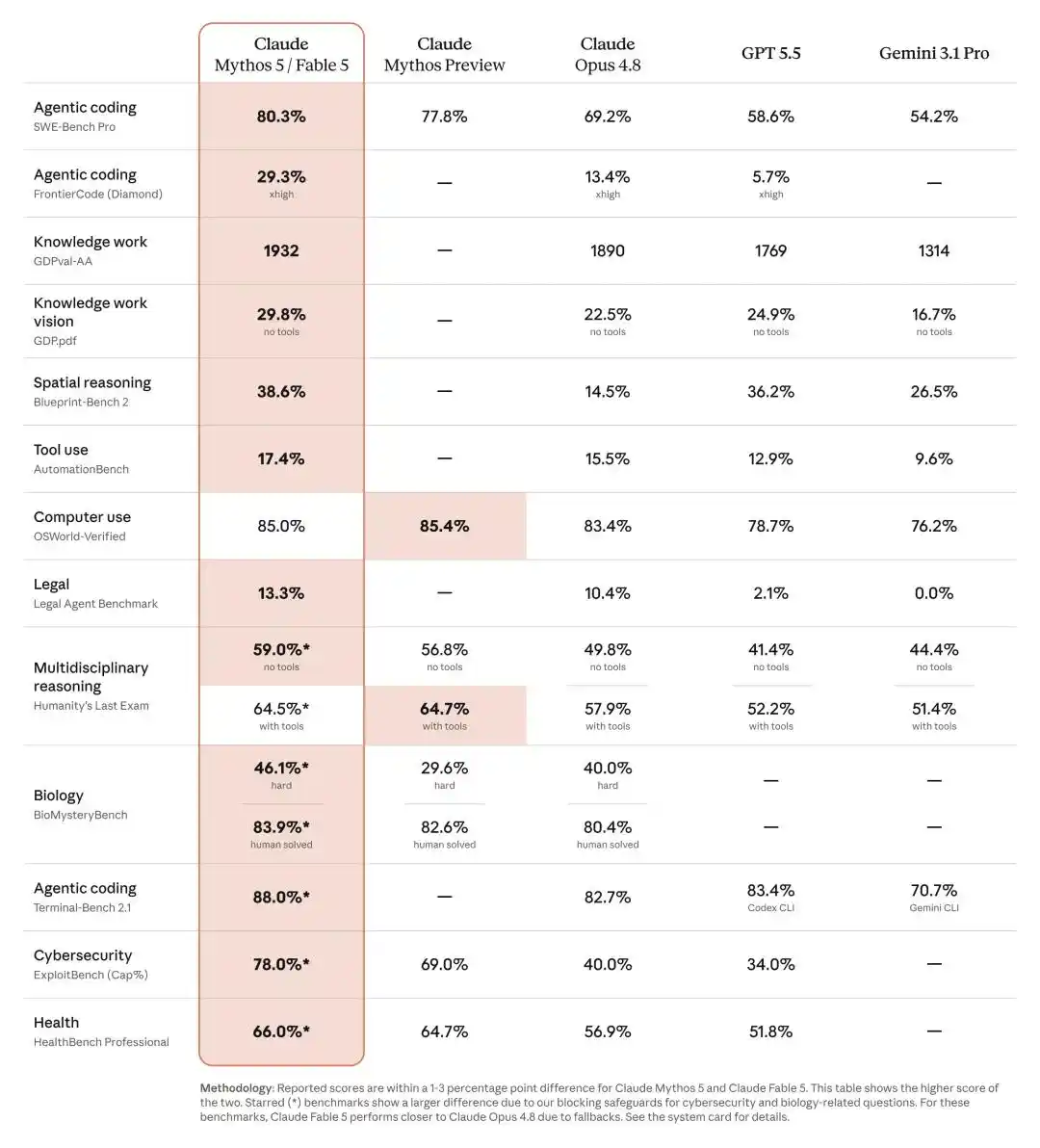
Dans Frontier Code de Cognition — une évaluation qui se concentre davantage sur la capacité du modèle à accomplir des tâches de programmation difficiles tout en respectant les standards de qualité des bases de code de production — Fable 5 obtient le score le plus élevé parmi les modèles de pointe, même avec un niveau de raisonnement « moyen ».
Le benchmark FrontierCode est extrêmement difficile à saturer.
Pourtant, même en mode « effort moyen (Medium effort) », Fable 5 obtient le score le plus élevé parmi tous les modèles de pointe.
Le premier cas d'usage typique donné par Anthropic provient de Stripe.
Dans une base de code Ruby de 50 millions de lignes, Fable 5 a réalisé une migration complète. Ce travail, s'il était effectué manuellement par une équipe d'ingénieurs, prendrait normalement plus de deux mois.
Fable 5 ? Une seule journée.
De plus, sur le benchmark de développement frontend de bout en bout ViBench (Vibe-coding benchmark), Fable 5 a pratiquement saturé les cas d'usage de développement de base, réalisant une véritable génération « one-shot » d'applications.
Vision native : Pas d'échafaudage, finition en mode aveugle de « Pokémon »
Le média technologique de renom VentureBeat a révélé dans son article « Anthropic brings Mythos to the masses with Claude Fable 5, its most powerful generally available model ever » que sur le benchmark GDPpdf, axé sur le raisonnement à partir de fichiers visuels, Fable 5 et Mythos 5 ont obtenu un score de 29,8 % sans l'aide d'outils externes.
En comparaison, Opus 4.8 a obtenu 22,5 %, GPT-5.5 a obtenu 24,9 % et Gemini 3.1 Pro a obtenu 16,7 %.
Anthropic a également pensé qu'une simple série de données serait ennuyeuse, et a donc publié une démo de Fable 5 jouant à un jeu, visuellement plus parlante.
Les modèles Claude précédents, s'ils voulaient jouer au RPG « Pokémon Édition Rouge Feu », devaient être configurés avec un ensemble extrêmement complexe d'« échafaudages » externes (incluant une aide à la navigation cartographique, une lecture de l'état du jeu en mémoire, etc.).
Désormais, Fable 5 réalise un jeu en « mode aveugle » purement visuel natif.
Se basant uniquement sur des captures d'écran brutes du jeu, sans aucune aide cartographique externe, il planifie et exécute des stratégies de manière totalement autonome, finissant ainsi l'intégralité du jeu.
De plus, grâce à sa concentration sur des séquences ultra-longues, lorsqu'on lui a fourni une mémoire persistante au niveau des fichiers, ses performances dans le jeu de cartes roguelike « Slay the Spire » ont été multipliées par 3, et la probabilité d'atteindre l'étoile finale a également triplé.
Contexte long et mémoire significativement améliorés, avec un accent sur « l'efficacité des Tokens »
Le contexte long et la mémoire sont également des points majeurs de cette mise à jour.
Anthropic affirme que Fable 5 peut rester concentré sur des tâches de longue durée impliquant des millions de tokens, et qu'il peut utiliser ses propres notes pour améliorer ses résultats.
Le test officiel avec Slay the Spire a montré qu'après avoir connecté le modèle à une mémoire de fichier persistante, les performances de Fable5 ont été améliorées d'un facteur trois par rapport à Opus4.8, et la fréquence d'atteinte du chapitre final a également triplé.
Il s'agit en réalité d'un élément fondamental des capacités d'Agent.
Une IA capable de travailler longtemps doit se souvenir de ce qu'elle a fait, de ses erreurs, et des raisons de ses prochaines actions. Sans mémoire stable, une tâche autonome peut facilement devenir un spectacle d'amnésie de grande ampleur.

Anthropic a également particulièrement mis l'accent sur l'efficacité des Tokens (une direction clé pour cette génération de modèles).
Plus un modèle est capable de fonctionner de manière autonome sur de longues périodes, plus il consomme de tokens.
Si un modèle est à la fois puissant et très « bavard », les coûts deviendront rapidement prohibitifs pour les entreprises.
L'accent mis par Fable 5 sur l'efficacité des tokens résout essentiellement un problème de rentabilité dans le déploiement des agents.
Finance, droit et opérations : Premier franchissement de la barre des 90 % dans le gouffre de la logique
Dans le test de référence financier Hebbia (Finance Benchmark for senior-level reasoning), qui évalue les capacités de raisonnement analytique avancé, Fable 5 a obtenu le score le plus élevé du secteur.
Dans le raisonnement sur des documents longs, l'interprétation de graphiques et tableaux complexes, ainsi que l'analyse multi-étapes des causes profondes, Fable 5 a réalisé une croissance à deux chiffres.
Dans les tests réels des sociétés de trading quantitatif IMC et Optiver, Fable 5 a obtenu presque tous les points de leurs évaluations d'analyse de trading (incluant la récupération de faits, le raisonnement conceptuel et le calcul de la valeur attendue), et a fait preuve d'une stabilité impressionnante — les scores des résultats de sortie étaient parfaitement identiques lors de plusieurs exécutions répétées.
La plateforme d'analyse de données Hex a donné cette évaluation :
Fable 5 est le premier modèle du secteur à franchir la barre des 90 % dans notre benchmark d'analyse central (couvrant des tâches d'analyse extrêmement complexes et de longue durée), soit une amélioration de 10 points de pourcentage par rapport à Opus. Dans les questions les plus pointues, il a fait preuve d'un jugement micro-analytique de niveau expert humain.
Recherche de pointe : La version complète Mythos surpasse un modèle 100 fois plus grand
Dans la recherche en physique de pointe, des tests par la startup VibeCAD et des instituts de recherche physique indiquent que Fable 5, en utilisant seulement 1/3 des tokens de raisonnement et en 36 heures, a produit des résultats de recherche en physique qui rivalisent avec ceux obtenus par GPT-5.5 en quatre jours.
Et voici que Mythos, encore un peu caché, fait enfin son apparition dans cette section.
Anthropic indique que dans le domaine biomédical, la version complète de Mythos 5 est déjà capable, sans aucune assistance humaine, d'exécuter de manière autonome l'intégralité du flux de travail d'un biologiste : sélection de sites de liaison protéique, planification et exécution autonomes de divers outils bio-informatiques, et même débogage en cas d'échec d'exécution.
Parmi les 14 complexes de ciblage protéique qu'il a conçus, 9 sont déjà entrés dans les pipelines réels de développement de médicaments en laboratoire.
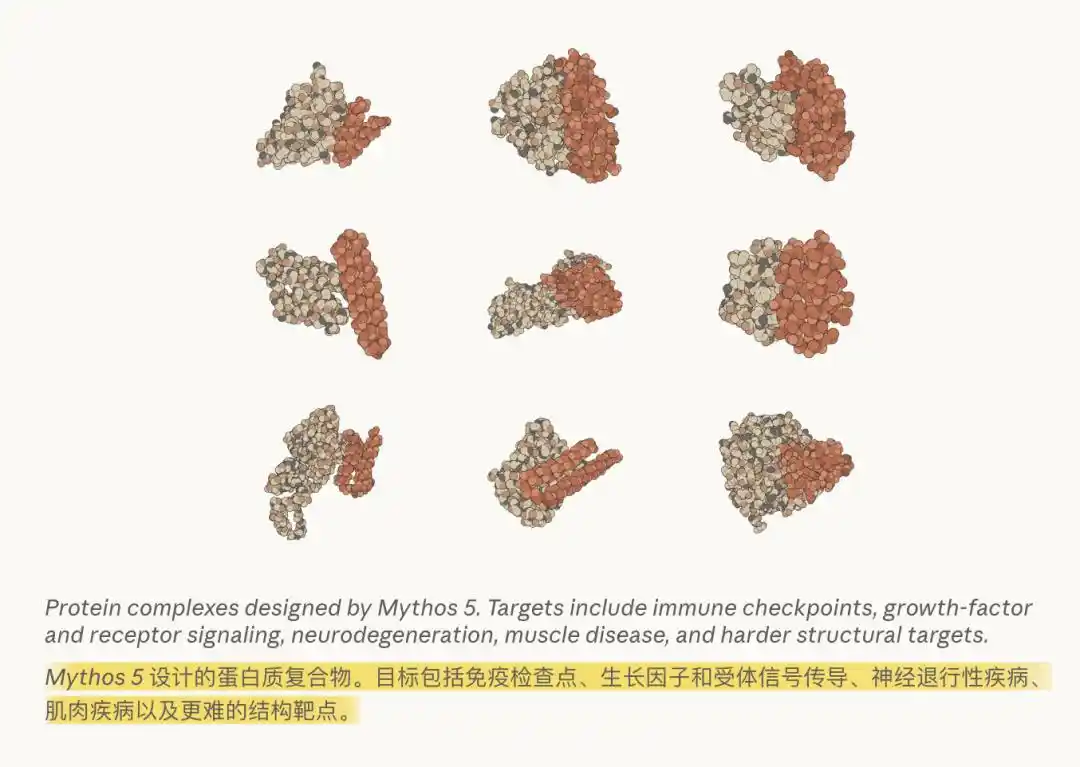
Anthropic souligne également que Mythos 5 est « notre premier modèle capable de générer de manière continue des hypothèses scientifiques nouvelles et convaincantes ».
Dans des comparaisons directes en aveugle avec les modèles de la série Opus, les scientifiques ont préféré dans 80 % des cas les hypothèses de Mythos en biologie moléculaire, et ont déjà fait avancer plusieurs de ces hypothèses jusqu'à la phase de validation expérimentale.
Parallèlement, une hypothèse de Mythos — concernant un nouveau mécanisme pour une protéine d'E. coli — a été confirmée par une autre étude d'un laboratoire indépendant travaillant sur la même question, intitulée « A newly identified detoxification system protects uropathogenic Escherichia coli from reactive chlorine species ».
Plus spectaculaire encore, dans des études de génomique, Mythos 5 a travaillé de manière autonome pendant plus d'une semaine, assemblant des données unicellulaires de 138 espèces, et a conçu et entraîné de manière autonome un modèle d'apprentissage automatique miniature sur mesure.
Ce petit modèle entraîné par l'IA, dont le volume est 100 fois plus petit, a surpassé les derniers résultats de recherche publiés il y a peu dans la revue « Science ».
Après avoir appelé à l'arrêt de la recherche en IA, les « capacités dangereuses » semblent transformées en mécanisme produit
L'aspect le plus intéressant cette fois est probablement le filet de sécurité appliqué par Anthropic à Fable 5.
Pour être précis, Fable 5 possède en arrière-plan un ensemble de classificateurs indépendants.
Ces classificateurs détectent si une requête utilisateur concerne une attaque de cybersécurité, des risques biologiques et chimiques, ou du « model distillation » (extraction de modèle).
Dès qu'un déclenchement se produit, Fable 5 refuse de répondre lui-même et transmet automatiquement la requête à Claude Opus 4.8, tout en informant l'utilisateur de cette dégradation.
Intéressant.
Dans le passé, en matière de sécurité, les grands modèles de langage refusaient généralement en disant quelque chose comme « Désolé, je ne peux pas vous aider », « Je suis désolé, je ne peux pas répondre », « Je suis désolé, je ne comprends pas votre demande », etc.
Fable 5 adopte une approche différente.
Il ne se contente pas de refuser, il procède à un routage de modèle.
Les questions ordinaires sont traitées par Fable 5, mais dès qu'une question est identifiée comme étant à haut risque, le modèle est instantanément basculé vers Opus4.8.
L'idée d'Anthropic est qu'Opus4.8 est lui-même un modèle puissant, et qu'une réponse de niveau inférieur offre une meilleure expérience qu'un refus pur et simple, non ?~

Cette conception sépare en réalité la capacité de la sécurité.
Vous utilisez au quotidien une capacité de niveau Mythos.
Mais face à des questions sensibles, offensives, ou tentant de contourner les restrictions, Anthropic bascule en douceur vers une ancienne version du modèle pour vous servir, rendant soudainement votre outil pratique moins performant.
(Il s'agit principalement de se prémunir contre certains problèmes en cybersécurité, dans les domaines biochimiques et en matière d'extraction de modèles).
Anthropic fournit des données —
Bonne nouvelle, plus de 95 % des sessions avec Fable 5 ne déclenchent pas de dégradation.
Autrement dit, pour la grande majorité des tâches de rédaction, de code, d'analyse, de recherche et de bureautique, l'expérience utilisateur est pratiquement équivalente à celle de Mythos 5.
Mais il reste moins de 5 % des requêtes qui empruntent un chemin de sécurité plus strict.
Le site officiel indique que les domaines à haut risque sont principalement de trois types.
Le premier est la cybersécurité, le second la biologie et la chimie, et le troisième l'extraction de modèles.
Derrière ce mécanisme se cache en réalité un changement dans la forme des produits modèles de pointe.
La sécurité n'est plus seulement une clause de non-responsabilité avant la réponse du modèle, ni une simple description de politique écrite sur une fiche système.
Elle devient une architecture produit composée de classificateurs, de routage de modèles, de hiérarchisation des permissions, de rétention des données et de tests d'équipe rouge.
Bien sûr, cela a un coût.
Les classificateurs de Fable 5 sont réglés de manière assez conservatrice, et des requêtes normales peuvent également être affectées par erreur.
Par exemple, un biologiste étudiant un virus, ou un ingénieur en sécurité effectuant un exercice de test d'intrusion autorisé, pourraient déclencher une dégradation lors de tâches légitimes.
Anthropic reconnaît lui-même que les garde-fous actuels sont plus stricts que l'idéal, et qu'ils réduiront le taux de fausses alertes par la suite.
Un autre coût est la rétention des données.
À partir de Fable 5, Mythos 5 et des modèles de niveau équivalent ultérieurs, Anthropic exige que tout le trafic des modèles de niveau Mythos soit conservé pendant 30 jours, couvrant les scénarios d'utilisation de première et de troisième parties.
L'entreprise souligne que ces données ne seront pas utilisées pour l'entraînement, mais uniquement pour la surveillance de la sécurité, y compris l'identification d'attaques complexes, de nouvelles méthodes de contournement et d'attaques multi-requêtes.
Pour l'utilisateur moyen, cela peut n'être qu'une ligne dans les conditions générales.
Mais pour les clients entreprise, il s'agit d'un problème de gouvernance des données très concret.
Si vous voulez utiliser la capacité la plus puissante, vous devez accepter un niveau de contrôle de sécurité et de rétention des données plus élevé.
Inévitablement, le coût des modèles de pointe ne se reflète pas seulement sur la facture API.
En termes de prix, Fable5 et Mythos5 ont un tarif unique de 10 dollars par million de tokens d'entrée et 50 dollars par million de tokens de sortie.
Certes, c'est bien moins cher que Claude Mythos Preview, mais cela reste un modèle coûteux.
En un mot, Fable5 est puissant, mais pas assez bon marché pour qu'on puisse le gaspiller.
Cela explique aussi pourquoi Anthropic met simultanément l'accent sur la capacité, la sécurité et l'efficacité des tokens.
Expérience d'un chercheur en IA en test interne : Plus l'IA est forte, plus l'homme ressemble à un client
L'éminent chercheur en IA et professeur à la Wharton School, Ethan Mollick, a publié un long article après avoir obtenu en priorité un accès de test.
La logique de son texte touche au cœur même de cette révolution technologique —
Le paradigme de collaboration entre les humains et les grands modèles a subi un renversement fondamental et irréversible.
Il a demandé à Fable 5 de créer une carte des isochrones.
Cette tâche peut sembler simple, mais elle est en réalité très fastidieuse.
Il faut consulter les horaires de vols, les horaires ferroviaires, estimer les vitesses routières, et gérer les relations entre différents pays, modes de transport et coûts temporels.
Fable 5 a lui-même lancé plusieurs agents pour rechercher des informations, obtenant plus de 2200 détails de vols spécifiques, récupérant des données ferroviaires comme le TGV, le Shinkansen, ainsi que des informations sur les vitesses routières dans différents pays.
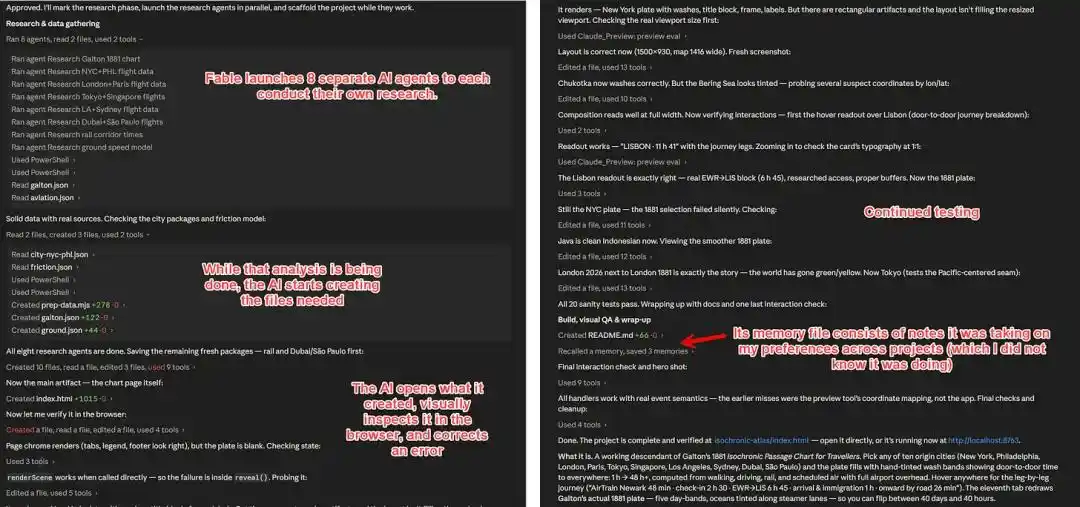
Enfin, il a intégré ces informations dans un projet de carte utilisable.
L'important ici est que Fable 5 a décomposé un objectif vague en plusieurs étapes — recherche, collecte d'informations, conception, codage, validation — et a avancé de lui-même.
Cela diffère considérablement de l'expérience passée avec les grands modèles.
Ainsi, Mollick propose une réflexion profonde.
Dans le passé, utiliser un grand modèle de langage ressemblait à être un « sorcier (Wizard) ». Il fallait le guider et le diriger (Steer) pas à pas, ciseler chaque prompt, « incanter » à travers des dialogues et prompts continus, pour que l'IA produise à peine un tour de magie.
Face aux modèles de niveau Mythos, l'humain devient un « mécène (Patron, ici je pense que « client » serait plus approprié ?) » ou un « donneur d'ordre ».
Travailler avec Fable5, selon le professeur Mollick, ne ressemble plus à utiliser un outil, mais plutôt à confier une tâche à un petit studio.

De plus, lors de ses tests pratiques, il n'a plus eu besoin de travailler au niveau micro des instructions.
Il a directement fourni à Fable 5 un document de conception de projet extrêmement complexe de 15 pages, puis a laissé une description macro des besoins.
Pendant les neuf heures suivantes, Fable 5 a fonctionné de manière totalement autonome en arrière-plan.
Il a généré lui-même un flux de travail d'agent, orchestrant en interne plusieurs petits agents pour effectuer des recherches, rédiger des plans, se relire mutuellement, rejeter des hypothèses erronées, corriger des erreurs et recommencer.
L'humain n'a même pas eu besoin d'intervenir une seule fois dans ce flux de travail.
Neuf heures plus tard, un produit de très haute qualité a été livré directement à Mollick.
C'est ce qu'on appelle la métaphore du « studio ».
Avant, utiliser un grand modèle, c'était engager un freelance temporaire nécessitant des communications répétées ; maintenant, utiliser Fable 5, c'est comme embaucher instantanément, pour quelques dollars de tokens, un bureau d'études de niveau Hollywood ou un institut de recherche de pointe.
Vous n'avez pas besoin de vous soucier du nombre de décisions microscopiques prises dans la boîte noire, vous jouez simplement le rôle du « client » qui signe le produit final.
Cette combinaison d'un contexte (Context) de texte long et d'une logique autonome dans les grands modèles transforme le Context en un « nouveau système d'exploitation intelligent » capable de raisonner de manière autonome et de fonctionner sur de longues durées, et non plus simplement en un « conteneur de contenu ».
En d'autres termes, plus l'IA ressemble à un prestataire, plus l'humain ressemble à un client ayant besoin de capacité de validation.
Petite parenthèse, pour une démonstration plus intuitive et amusante, le professeur lui a aussi demandé de générer une série de jeux à essayer.
Ces jeux sont tous basés sur une invite initiale de Claude Code. Fable 5 devait générer des programmes viables à partir de mes indications floues, puis j'ai donné des instructions supplémentaires et des encouragements (comme « fais mieux ») ou des retours.
Comme Claude Code ne peut pas générer d'images, tous les éléments graphiques ou objets 3D ont été générés entièrement par calcul mathématique, sans utiliser de ressources externes.
Voici une démo d'un jeu de pile ou face :
Après avoir testé Fable 5 en interne en avance, le professeur a finalement déclaré que « le résultat final est impressionnant ».
Mais, surtout lorsqu'il s'attaque à des projets plus sérieux, il trouve souvent que l'utilisation de cet outil est à la fois plaisante et dérangeante.
Ce qui est plaisant, c'est que je n'ai qu'à demander, et cela se réalise. Ce qui est dérangeant, c'est aussi que je n'ai qu'à demander, et cela se réalise.
Effectivement.
Revenons à cette annonce d'Anthropic.
Certains pensent que le plus important est que Mythos est enfin semi-dévoilé, d'autres estiment que le plus important est que les produits d'IA de pointe entrent dans une nouvelle forme.
Un modèle plus puissant est sur la table.
Mais Anthropic lui a d'abord attaché sa ceinture de sécurité, avant de remettre les clés à tout le monde.
Certains se réjouissent, d'autres s'inquiètent, d'autres encore passent des nuits à déboguer du code, juste pour essayer de suivre cette courbe d'intelligence qui avance à toute vitesse et commence même à échapper au regard microscopique de l'humain.
Trois Choses Supplémentaires
1- Attention à la fenêtre d'utilisation. D'aujourd'hui au 22 juin, les utilisateurs des versions Pro, Max, Team et Enterprise peuvent utiliser Fable 5 gratuitement.
Mais à partir du 23 juin, pour continuer à utiliser Fable 5, il faudra acheter des crédits d'utilisation supplémentaires.
2- Anthropic déclare qu'une fois la capacité de production suffisante, Fable 5 redeviendra inclus dans l'abonnement standard.
Les clients API et les clients entreprise au paiement à l'usage ne sont pas affectés par ce calendrier, ils peuvent l'appeler normalement à partir d'aujourd'hui.
Références :
[1]https://www.anthropic.com/news/claude-fable-5-mythos-5
[2]https://www.oneusefulthing.org/p/what-it-feels-like-to-work-with-mythos
[3]https://www.biorxiv.org/content/10.64898/2026.03.12.711259v1
Cet article provient du compte public WeChat « Quantum Bits », auteur : Heng Yu






