Selon les statistiques, le financement total dans le domaine de l'intelligence incarnée en Chine a dépassé 37 milliards de yuans cette année.
Le ministère de l'Industrie et des Technologies de l'Information et la Commission de supervision et de gestion des actifs de l'État ont conjointement lancé l'« Action spéciale de formation pratique sur site pour les robots humanoïdes et l'intelligence incarnée ». Le China Media Group a directement qualifié cette année d'« année clé pour la commercialisation ». Les capitaux du marché primaire, les récits du marché secondaire, tous crient dans la même direction : la mise en œuvre, la mise en œuvre, la mise en œuvre.
Mais la question se pose : comment l'intelligence incarnée doit-elle concrètement être mise en œuvre ?
L'opinion généralement partagée est que l'intelligence incarnée devrait s'attaquer à ce que les humains ne peuvent pas faire, et remplacer les humains dans les tâches dangereuses, pénibles, répétitives, que les gens ne veulent pas et ne devraient pas faire.
Le 22 juin, la quatrième édition de la Foire internationale de la chaîne d'approvisionnement de Chine a ouvert ses portes à Pékin, avec pour la première fois une zone dédiée à l'intelligence artificielle.
Mais les idées sont une chose, pour que les robots puissent réellement « entrer » dans ces environnements, le premier obstacle est suffisant pour décourager la plupart des entreprises : la certification antidéflagrante.
Dans les environnements inflammables et explosifs tels que les stations-service, les stations pétrolières et gazières, les usines chimiques, le robot lui-même ne doit absolument pas devenir une source d'inflammation potentielle. Cela impose des exigences extrêmement strictes sur la conception matérielle du produit dès le départ. Par exemple : au niveau des circuits, il faut une conception de sécurité intrinsèque, limitant l'énergie du circuit pour garantir qu'en cas de défaillance, elle ne soit pas suffisante pour enflammer les gaz ambiants ; la structure mécanique doit répondre aux exigences de confinement de l'explosion, résister à une explosion interne sans endommager le boîtier ; tous les points de connexion doivent être traités de manière améliorée pour prévenir les risques d'étincelles pendant le fonctionnement normal ; les composants clés doivent également être encapsulés pour isoler tout contact dangereux, etc.

Où peut aller l'intelligence incarnée
Le défi pour le robot dans ce scénario réside dans la « continuité des opérations fines ». Après que le conducteur ait passé commande, le robot doit effectuer une série de plus de dix actions : soulever le cache extérieur, dévisser le bouchon intérieur, décrocher le pistolet de son support, viser l'orifice de remplissage, l'insérer, attendre le plein, retirer le pistolet, le reposer sur son support, remettre le bouchon intérieur, refermer le cache extérieur. La marge de tolérance pour chaque action n'est que de quelques millimètres, et tout blocage à une étape signifie l'interruption de toute la chaîne. De plus, la position du réservoir, la structure du bouchon, le mode d'ouverture varient considérablement d'un modèle de véhicule à l'autre, et le robot ne peut pas se fier à un programme fixe pour tous les cas.
Les points sensibles de l'inspection dans les stations sont complètement différents de ceux des stations-service. La station-service teste les opérations fines, tandis que la station teste la capacité globale de « patrouille autonome prolongée + identification de multiples anomalies + réponse immédiate sur site ». Les inspecteurs empruntent un parcours fixe quotidiennement ; ce travail est monotone, dangereux et exige une attention extrême, le taux d'omissions augmentant significativement après plusieurs heures d'inspection continue.
Scénario portuaire : l'exploration de la collaboration multi-robots
Ce qui rend ce scénario particulier, c'est qu'il nécessite naturellement la collaboration de plusieurs robots.
Actuellement, l'architecture de la plupart des systèmes d'intelligence incarnée est de type « pipeline » : le module visuel est responsable de la vision, le module linguistique de la compréhension, le module d'action de l'exécution.
Cette architecture peut encore gérer des tâches simples à séquence courte et faible interférence, mais dès qu'elle rencontre des scénarios à plus d'une dizaine d'étapes consécutives, à environnement hautement dynamique et à marge d'erreur extrêmement faible, la moindre déviation à n'importe quelle étape intermédiaire se propagera comme un effet domino. Face à des tâches de cette ampleur, l'architecture traditionnelle en pipeline ne peut presque pas garantir la stabilité de bout en bout.
Capacité de prédiction pilotée par le modèle du monde
Dans le scénario de la station-service, la chaîne de tâches à laquelle l'intelligence incarnée est confrontée est extrêmement longue : guidage du stationnement, identification de l'emplacement du réservoir, ouverture du cache extérieur, ouverture du bouchon intérieur, prise du pistolet, alignement sur l'orifice, insertion, remplissage, retrait, rangement du pistolet, fermeture du bouchon intérieur, fermeture du cache extérieur. La moindre déviation à une étape se répercute sur les suivantes.
Cette capacité est particulièrement cruciale dans les tâches à séquence longue. Faire le plein n'est pas une simple opération de « saisie-placement », c'est toute une chaîne d'actions avec des relations de cause à effet. Le modèle du monde confère à l'intelligence incarnée la capacité prospective de « regarder trois pas avant d'en faire un ».
Pour comprendre avec une métaphore : lorsqu'un chauffeur expérimenté fait le plein, peu importe si le bouchon du réservoir s'ouvre facilement ou non, il a toujours à l'esprit l'état final à atteindre, et chaque étape intermédiaire s'ajuste autour de cet état final. Il s'agit de faire passer l'intelligence incarnée d'une « exécution linéaire » à un « alignement sur l'état final ».
Premièrement, générer l'observation cible. Après avoir reçu l'instruction de tâche et l'image actuelle de la caméra, le système prédit d'abord « à quoi le monde devrait ressembler après l'achèvement de la tâche ». Par exemple, après une tâche de ravitaillement, le pistolet devrait être remis en place, le bouchon du réservoir devrait être refermé. Cette « image de l'état final » prédite est l'observation cible, fournissant un ancrage sémantique clair pour tous les processus de raisonnement ultérieurs.
Deuxièmement, synthétiser les images de transition intermédiaires. Avec l'objectif en tête, le système déduit ensuite les états visuels intermédiaires à traverser. Si le point de départ est « bouchon du réservoir fermé » et l'arrivée est « pistolet remis en place, bouchon du réservoir fermé », alors des images de transition telles que « bouchon du réservoir ouvert », « pistolet retiré », « pistolet inséré dans l'orifice » doivent apparaître successivement. Ces images intermédiaires synthétisées fournissent des références visuelles pour l'alignement progressif de la génération d'actions.
Ce mécanisme permet au robot d'avoir une imagination visuelle complète de l'ensemble du processus de tâche avant de commencer à agir. La planification des actions ultérieures s'articule autour de cette « trajectoire imaginée », réduisant ainsi considérablement l'accumulation de déviations lors de l'exécution de longues séquences.
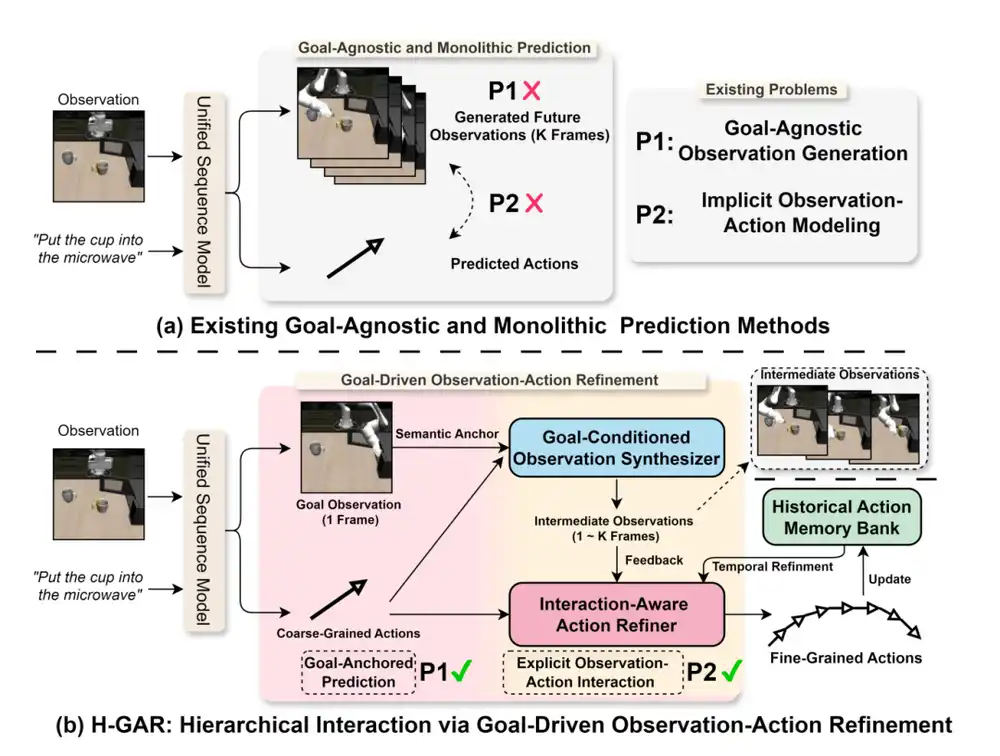
(a) Les méthodes existantes adoptent généralement un paradigme de prédiction global et indépendant de la cible. (b) H-GAR introduit un synthétiseur d'observations conditionné par la cible et un optimiseur d'actions avec perception de l'interaction, permettant ainsi une prédiction ancrée sur la cible et une modélisation explicite de l'interaction entre l'observation et l'action.
Concrètement, le flux de travail de H-GAR se décompose en trois étapes :
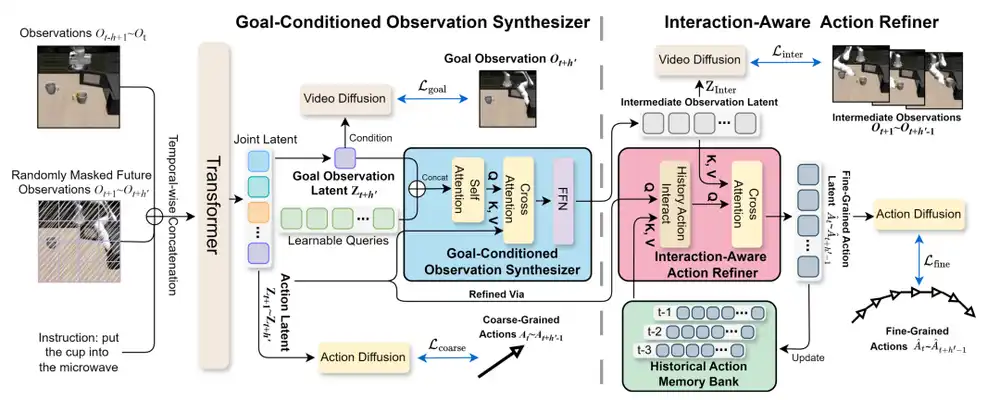
Diagramme de l'architecture H-GAR
Première étape : ébauche d'actions à granularité grossière. Sur la base des images historiques et de l'instruction de tâche, le système génère d'abord un ensemble d'actions approximatives. Ces actions décrivent une « voie approximative » de l'état actuel à l'objectif, similaire au plan approximatif qu'un humain aurait en tête pour faire le plein, sachant à peu près quelles étapes accomplir, une préparation avant l'exécution.
Deuxième étape : synthèse d'observations conditionnée par la cible (module GOS). Après avoir obtenu les actions grossières, le système synthétise des images visuelles intermédiaires guidé par l'observation cible. La clé de cette étape est que les images synthétisées ne sont pas générées au hasard, mais sont simultanément contraintes à la fois par l'état final cible et les actions grossières. Cela garantit que les images de transition intermédiaires respectent à la fois la logique des actions et sont alignées sur l'objectif final.
Troisième étape : raffinement d'actions avec perception de l'interaction (module IAAR). La dernière étape transforme les actions grossières en instructions exécutables fines. L'IAAR obtient des retours de deux directions pour raffiner les actions : d'une part, le contexte visuel fourni par les images d'observation intermédiaires, alignant les actions sur la scène réelle ; d'autre part, la mémoire d'actions historiques, qui enregistre les actions fines précédemment exécutées, garantissant que les actions générées restent cohérentes dans le temps avec la trajectoire historique. Lorsque la mémoire dépasse un seuil de capacité, le système adopte une stratégie d'élimination par similarité, fusionnant les actions adjacentes les plus similaires pour maintenir la diversité de la mémoire.
Adresse de l'article : https://arxiv.org/pdf/2511.17079
Dans les scénarios réels, les imprévus sont presque la norme. Le bouchon du réservoir peut s'ouvrir sous un mauvais angle, le conducteur peut se garer à un endroit décalé par rapport aux prévisions, ou même l'orifice peut être obstrué par des corps étrangers. Une action qui réussit 99 fois sur 100 en laboratoire peut voir son taux de réussite chuter de 30% dans un environnement extérieur réel.
Épilogue : L'union de la connaissance et de l'action
Faire progresser l'intelligence incarnée vers des scénarios spéciaux est une affaire qui nécessite un esprit de long terme.
Pour pénétrer les industries spéciales, la conception de la structure mécanique doit considérer la sécurité dès la base, et il est nécessaire d'avoir la capacité de développer le corps physique incarné. Et pour exécuter des tâches dans des environnements spéciaux, le cerveau incarné est encore plus indispensable. Le couplage profond du cerveau et du corps dépasse le statut de plus-value, c'est une condition d'accès.
Alors que l'industrie de l'intelligence incarnée se tient collectivement à un carrefour de commercialisation, les acteurs qui auront les premiers maîtrisé la boucle fermée « cerveau-corps-données » occuperont très probablement une position d'avance dans la compétition à venir.
Cet article provient du compte WeChat officiel : Machine Heart , édité par Leng Mao, auteur : Concernant l'intelligence incarnée, titre original : « Première certification antidéflagrante nationale, première solution mondiale de "cerveau de pompe à essence" : comment ont-ils obtenu ces deux "premières" »
![Analyse de la chute de prix de 12 % de Sonic [S] et pourquoi davantage de ventes pourraient suivre](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)






