Le blog, en pause depuis trois ans, vient enfin d'être mis à jour par Lilian Weng.
Il y a quelques instants, un article long, attendu depuis plus de trois ans par Lilian Weng, ancienne vice-présidente d'OpenAI, a fait le tour du web.
Dans ce billet de blog intitulé « Scaling Laws, Carefully », elle démonte méticuleusement les lois d'échelle (Scaling Laws) –
Cette loi sur laquelle l'industrie de l'IA a parié des dizaines de milliards de dollars est bien plus fragile que quiconque ne l'imaginait.
En une minute : de quoi parle cet article de dix mille mots
Une formule unique a gouverné toute l'industrie pendant cinq ans. Les lois d'échelle (Scaling Laws) énoncent que « plus le modèle est grand, plus les données sont nombreuses, plus la puissance de calcul est élevée, et meilleures seront les performances, et ce selon une proportion fixe ». Cela a transformé l'IA d'une alchimie en un business quantifiable, orientant indirectement des centaines de milliards de dollars d'investissements.
OpenAI et DeepMind ont donné des réponses opposées. Face à la même question « Comment allouer le budget de calcul ? », OpenAI déclarait en 2020 que la taille du modèle devait croître plus vite que celle des données, tandis que DeepMind affirmait en 2022 qu'elles devaient croître de concert. Il s'est avéré plus tard que l'origine de cette divergence résidait dans une différence de comptabilisation d'un paramètre, combinée à des expériences d'une ampleur insuffisante.
La formule du vainqueur cache également un bug. La proportion optimale de DeepMind, copiée par toute l'industrie pendant deux ans, s'est révélée, lors d'une réplication ligne par ligne en 2024, contenir une erreur : la fonction de perte utilisait une moyenne au lieu d'une somme, faisant s'arrêter prématurément l'optimiseur et produisant des paramètres loin d'être la solution optimale.
Il faut être très prudent lorsqu'on extrapole les règles des petits modèles aux grands modèles. Cette courbe a été ajustée sur des modèles relativement petits. Lorsqu'elle est extrapolée à l'échelle des milliers de milliards de paramètres, une simple différence d'arrondi peut conduire à des conclusions très éloignées. Le blog inclut un simulateur interactif permettant de le constater en déplaçant un curseur.
Un problème plus fondamental existe encore : les données sont presque épuisées. La formule suppose implicitement un approvisionnement infini en données, mais le texte de haute qualité est limité. C'est pourquoi toute l'industrie s'est tournée collectivement vers l'apprentissage par renforcement, le calcul au moment du test et les données synthétiques.
Une ligne droite, centaines de milliards de dollars
Il est bien connu que l'essence des lois d'échelle peut se résumer simplement en une phrase –
Plus le modèle est grand, plus les données sont nombreuses, plus la puissance de calcul est importante, meilleures sont les performances. Et ce « mieux » n'est pas aléatoire ; il suit une loi mathématique précise.
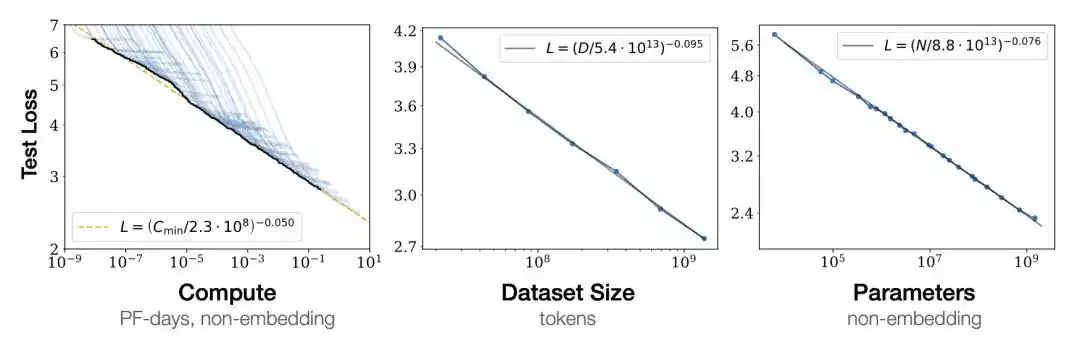
En traçant la perte de l'entraînement du modèle sur une échelle logarithmique, elle décroît en ligne droite avec l'augmentation du nombre de paramètres N du modèle, de la quantité de données D et de la puissance de calcul C.
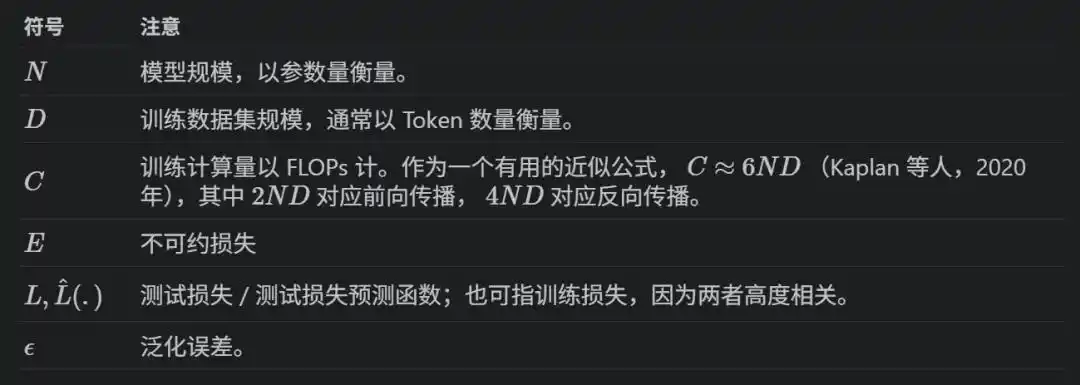
Écrite sous forme de formule : L(x) = E + A/x^α, où x peut être N, D ou C, E est la perte théorique optimale (l'entropie intrinsèque des données), A et α sont des constantes ajustées.
Pour entraîner un modèle de N paramètres sur D tokens, la puissance de calcul totale C ≈ 6ND – 2ND pour la propagation avant, 4ND pour la rétropropagation.
Cette ligne droite signifie que l'amélioration des performances est prédictible.
En entraînant d'abord quelques petits modèles, en ajustant cette ligne droite, et en extrapolant vers la droite, on peut estimer les performances d'un grand modèle sans avoir à dépenser des centaines de millions de dollars pour l'entraîner complètement.
Avant cela, l'apprentissage profond était souvent moqué comme de « l'alchimie », sachant ce qui fonctionnait sans comprendre pourquoi.
En 2020, Kaplan d'OpenAI a publié cette loi de puissance, arrachant pour la première fois l'alchimie au terrain du « prédictible ».
Voilà ce qui donne à toutes les entreprises de grands modèles la confiance d'investir des sommes colossales.
Mais la recommandation la plus cruciale de la formule, comment répartir le budget de calcul entre la taille du modèle et les données, a reçu des réponses opposées de la part d'OpenAI et de DeepMind.
Un même problème
OpenAI et DeepMind produisent des réponses opposées
En 2020, l'équipe de Kaplan chez OpenAI a conclu : la taille optimale du modèle N_opt ∝ C^0.73.
Traduction : si la puissance de calcul est multipliée par 10, 5.5 fois vont au modèle et 1.8 fois aux données – la taille du modèle doit croître beaucoup plus vite que celle des données.
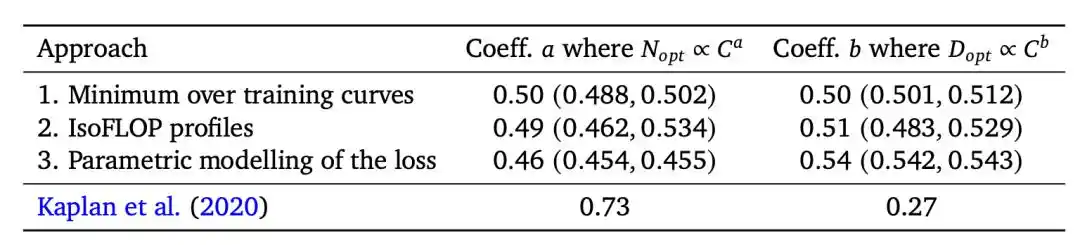
Ceci a directement guidé le protocole d'entraînement de GPT-3.
Le modèle de 175 milliards de paramètres n'a été nourri que de 300 milliards de tokens (un token est l'unité minimale traitée par le modèle, correspondant à peu près à 1-2 mots).
Selon les standards ultérieurs, c'était un entraînement largement insuffisant.
En 2022, l'équipe de Chinchilla chez DeepMind a tiré la conclusion opposée : N_opt ∝ C^0.50, le modèle et les données doivent croître de manière proportionnelle.

Les ingénieurs l'ont ensuite simplifié en un chiffre bien connu : le ratio optimal token/paramètre est d'environ 20:1.
Puis DeepMind a mené un face-à-face.
Leur Gopher, 280 milliards de paramètres nourris avec 300 milliards de tokens. Chinchilla, 70 milliards de paramètres nourris avec 1.4 trillion de tokens. Les deux modèles ont utilisé la même puissance de calcul.
Chinchilla a écrasé son adversaire.
Un modèle plus petit mais « bien nourri » a dominé un adversaire plus grand mais « sous-alimenté ».
Le consensus de toute l'industrie s'est donc inversé : de « agrandir le modèle » à « la plupart des modèles sont sous-entraînés ».
0.73 contre 0.50, la même question, des réponses opposées, qui vous conduisent à allouer votre budget de calcul dans deux directions complètement différentes.
La cause : un simple « problème de comptabilité »
En 2024, deux chercheurs ont publié un article de synthèse dans la revue TMLR, poussant l'enquête au bout.
La conclusion est désopilante.
Première cause : les deux parties ne comptent pas les paramètres de la même manière.
Dans un modèle, il existe une couche de paramètres appelée « embedding », responsable de la conversion des mots en vecteurs numériques compréhensibles par le modèle. Dans les petits modèles, cette couche représente une part très importante du nombre total de paramètres, pouvant atteindre un tiers pour des modèles de quelques dizaines de millions de paramètres.
Kaplan a exclu les paramètres d'embedding de son comptage, tandis que Chinchilla les a inclus.
Une simple différence de comptabilisation des paramètres suffit à déformer l'exposant de la loi de puissance ajustée.
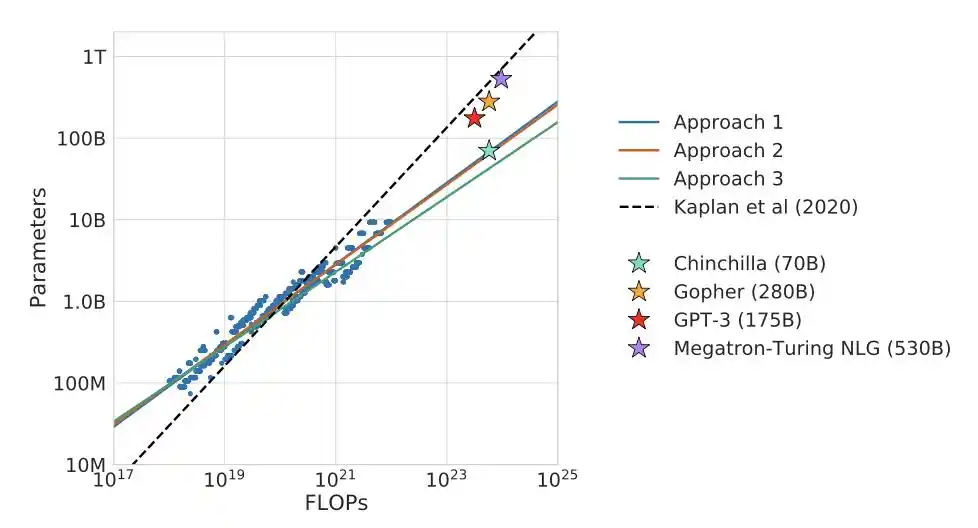
Ils ont donné une formule de correction concise : N = N_\E + ω·N_\E^(1/3), où N_\E est le nombre de paramètres hors embedding, et ω est une constante. Pour les petits modèles, le second terme a un poids important, l'influence de l'embedding est significative ; plus le modèle est grand, plus le second terme tend vers zéro, et les deux méthodes de comptage convergent.
Deuxième cause : l'expérience de Kaplan était trop petite en échelle.
Le plus grand modèle testé par Kaplan ne dépassait pas 1.5 milliard de paramètres, tandis que l'expérience de Chinchilla s'étendait au-delà de 16 milliards. Sur une échelle logarithmique, de minuscules déviations d'ajustement sont considérablement amplifiées lors de l'extrapolation.
En reprenant la formule de Chinchilla avec une comptabilisation unifiée des paramètres, ils ont découvert une loi clé –
L'exposant de la loi de puissance change avec l'augmentation de l'échelle de calcul. Dans la plage expérimentale limitée de Kaplan, l'exposant est effectivement proche de 0.73 ; mais lorsque l'échelle augmente, l'exposant converge vers 0.50.
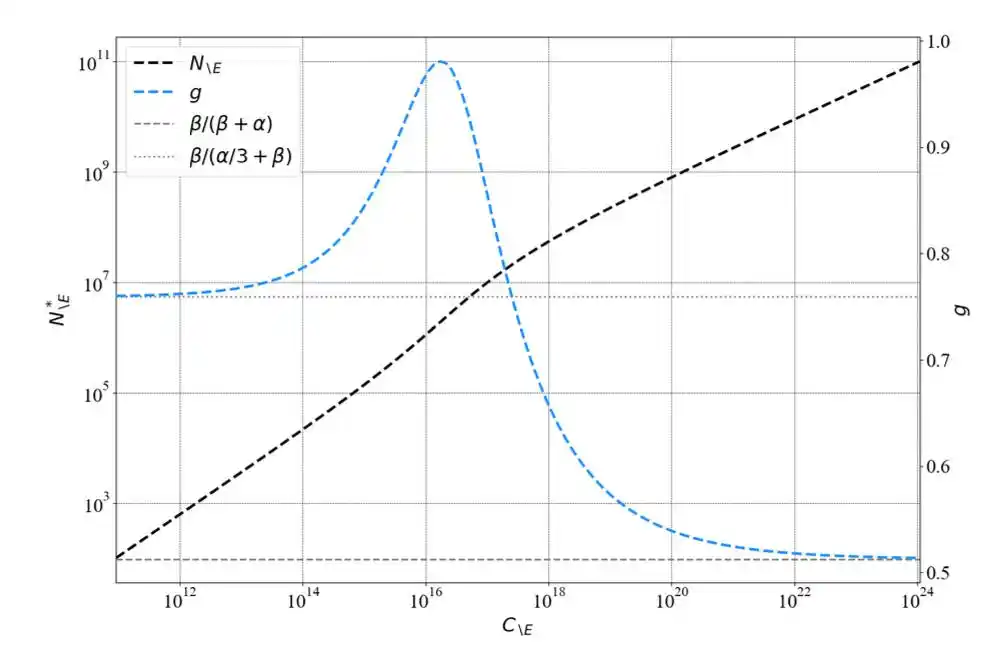
Kaplan ne s'est pas « trompé », il avait raison dans le cadre de son expérience.
Mais il a extrapolé une règle valable localement en une conclusion globale.
Un problème de comptabilisation d'un paramètre, ajouté à une expérimentation d'échelle insuffisante, a conduit deux équipes de premier plan à donner des recommandations opposées d'allocation des ressources.
Toute l'industrie a ajusté ses recettes d'entraînement pendant deux ans sur la base de cette conclusion.
Même le vainqueur a des bugs
Kaplan a été corrigé par Chinchilla, c'est le récit standard que tout le monde connaît.
Mais Weng est allée plus loin – la méthodologie même de Chinchilla présente des problèmes.
L'article de Chinchilla a utilisé trois méthodes indépendantes pour valider croisée sa conclusion :
Méthode 1 : taille de modèle fixe, variation de la quantité de données.
Méthode 2 : tracé des courbes d'iso-puissance (IsoFLOP profiles).
Méthode 3 : ajustement direct des paramètres sur la formule de perte L(N,D) = E + A/N^α + B/D^β.
Trois voies pointant vers la même conclusion, semblant très solides.
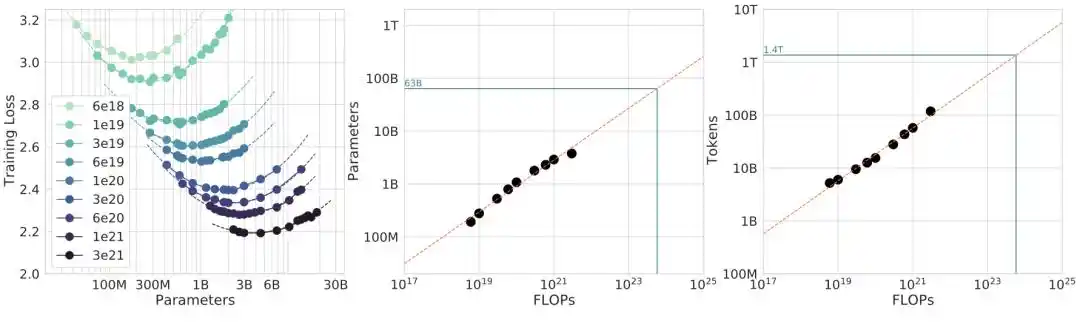
La dérivation mathématique de la méthode 3 est particulièrement élégante : en optimisant L(N,D) sous la contrainte C ≈ 6ND, on obtient une solution analytique fermée N_opt ∝ (C/6)^(β/(α+β)). Lorsque α ≈ β, l'exposant est approximativement 0.5, c'est-à-dire une croissance proportionnelle du modèle et des données. Voici l'origine mathématique du 0.50.
En 2024, l'équipe de l'institut de recherche en IA Epoch AI a extrait manuellement les points de données bruts des graphiques de l'article de Chinchilla et a rejoué l'ajustement de la méthode 3.
Deux bugs, l'un plus ahurissant que l'autre.
Bug 1 : la fonction de perte a utilisé une moyenne au lieu d'une somme.
Pour ajuster ces cinq paramètres, Chinchilla devait minimiser l'écart entre la perte prédite et la perte réelle.
L'objectif d'optimisation complet était : min Σ Huber_δ(log L̂(Nᵢ,Dᵢ) − log Lᵢ), où la perte Huber est une fonction de perte peu sensible aux valeurs aberrantes (δ = 10⁻³), utilisée avec l'optimiseur L-BFGS-B pour chercher la solution optimale.
Le problème réside dans un détail : ils ont pris la moyenne (mean) de la perte Huber pour chaque échantillon plutôt que la somme (sum). La moyenne sur quelques centaines d'échantillons comprime la valeur de la perte à un niveau extrêmement faible.
L'optimiseur L-BFGS-B intègre un critère de convergence automatique. Lorsque la valeur de la perte est suffisamment petite, il s'arrête. Voyant une valeur si faible, il a pensé à tort avoir convergé et s'est arrêté directement.
L'optimiseur n'a pas du tout terminé son exécution. Les paramètres de sortie n'étaient pas la vraie valeur optimale.
Bug 2 : les paramètres clés n'ont été conservés qu'avec deux décimales.
Dans l'article de Chinchilla, deux exposants centraux contrôlant la forme de la loi de puissance n'ont été conservés qu'avec deux chiffres après la virgule.
Cela semble être un arrondi anodin.
Mais en déduisant d'autres constantes à partir de ces nombres approximatifs, l'erreur a été amplifiée de manière exponentielle. L'intervalle de confiance final était anormalement étroit, si étroit qu'il nécessitait une précision atteignable seulement après plus de 600 000 expériences, alors qu'ils n'en ont effectué que moins de 500.
Une formule érigée en référence par toute l'industrie cachait un bug lié à une fonction de perte non exécutée jusqu'au bout, et ce bug est resté caché pendant deux longues années.
Weng a inclus dans son blog un simulateur interactif avec trois curseurs contrôlant respectivement la précision de la perte, le bruit de la perte et l'intervalle d'ajustement.
À chaque mouvement, la loi d'échelle ajustée change d'aspect.
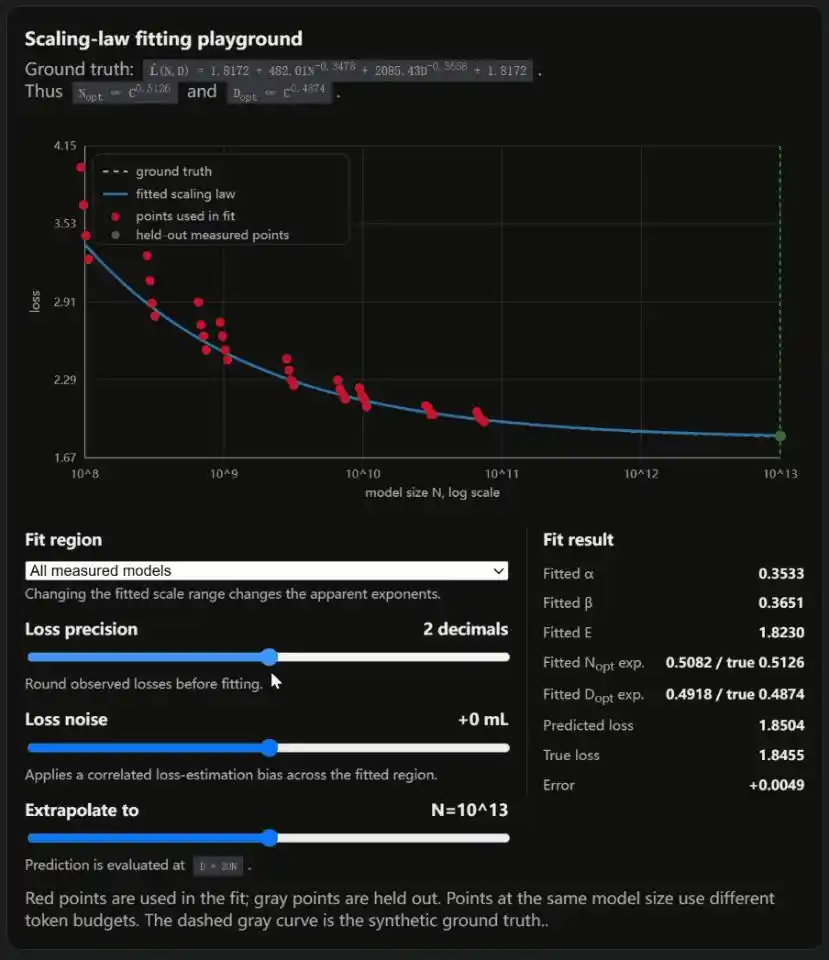
La conclusion d'OpenAI souffre d'un biais de localité, celle de DeepMind présente des imperfections méthodologiques. Le débat académique le plus important de l'industrie de l'IA présente des fissures des deux côtés.
Les données sont presque épuisées
Les trois sections précédentes traitaient des problèmes de méthode d'ajustement : comment compter les paramètres, comment calculer la perte, combien de décimales conserver.
Mais même si tous ces problèmes étaient corrigés, les lois d'échelle classiques présentent une menace encore plus fondamentale –
Elles supposent que chaque donnée d'entraînement est unique, non répétée, non entraînée sur plusieurs époques, et présupposent que vous disposez de données illimitées.
La réalité est que les données textuelles de haute qualité devraient être épuisées par les grands laboratoires entre 2026 et 2028.
La répétition de l'entraînement sur les mêmes données est inévitable, le postulat de la formule classique s'effondre.
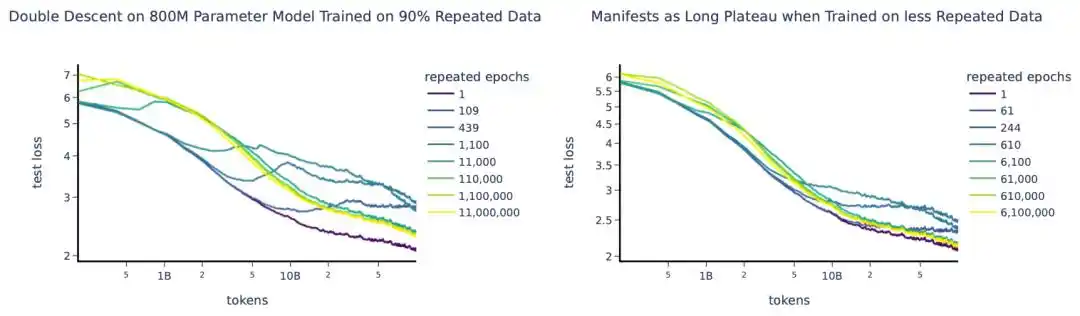
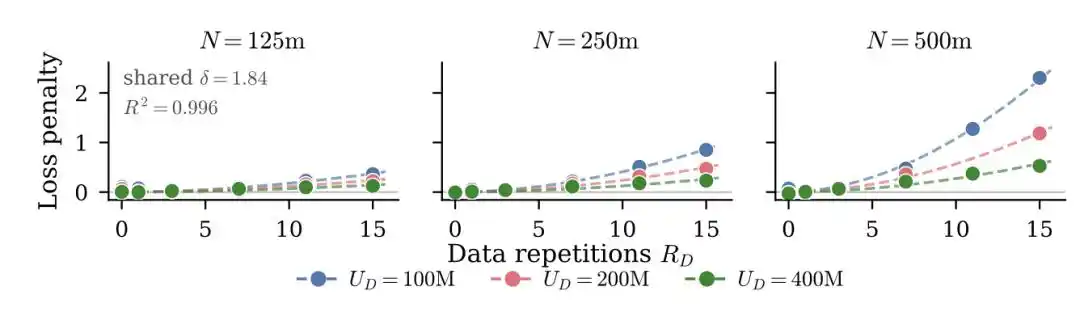
Une expérience à grande échelle en 2023 a entraîné environ 400 modèles, de quelques dizaines de millions à 9 milliards de paramètres, avec un maximum de 1500 répétitions (époques) d'entraînement.
L'idée centrale était d'introduire le concept de « quantité effective de données » pour remplacer la quantité réelle –
Si vous avez U données uniques répétées R fois, la quantité effective de données n'est pas U×R, mais est convertie selon une courbe de décroissance exponentielle : D_eff = U·(1 - e^(-R)). La première répétition permet encore d'apprendre beaucoup de choses nouvelles, mais à la cinquième, dixième répétition, le gain d'apprentissage marginal tend vers zéro.
Ils ont également découvert une conclusion contre-intuitive : les paramètres excédentaires se « déprécient » plus vite que les données répétées. Autrement dit, avec un budget limité, il est plus rentable de répéter l'entraînement plusieurs fois que d'augmenter la taille du modèle.
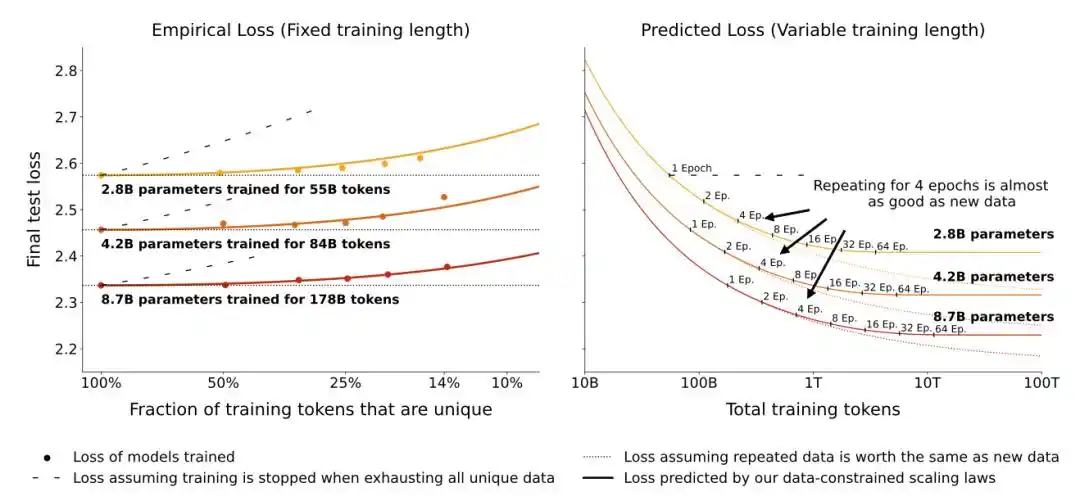
Un nouvel article de mai 2026 a adopté une approche différente.
Au lieu de convertir la quantité effective de données, ils ont directement ajouté un terme de pénalisation explicite pour le surapprentissage à la formule de perte classique – plus le modèle revoit les mêmes données, plus la pénalité est grande, et cette pénalité est liée à la taille du modèle.
Leur formule complète est la suivante :
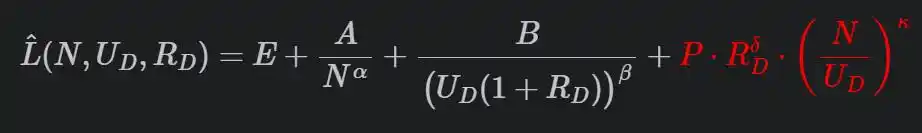
Le dernier terme de pénalisation en rouge est crucial.
R est le nombre de répétitions, N/U est le ratio entre le nombre de paramètres du modèle et la quantité de données uniques (à quel point le modèle est « excédentaire » par rapport aux données), P, δ, κ sont des paramètres ajustés à partir des expériences. Plus les répétitions sont nombreuses, plus le modèle est grand, plus la pénalité est lourde.
La découverte centrale de cet article est : les grands modèles sont plus sensibles à la répétition des données. En ré-entraînant les mêmes données 10 fois, un modèle de 500 millions de paramètres pourrait encore tenir le coup, mais les performances d'un modèle de 5 milliards de paramètres se dégraderaient beaucoup plus sérieusement.
Une autre découverte directement utile en ingénierie : renforcer la décroissance de poids (weight decay) peut atténuer significativement le surapprentissage induit par l'entraînement répété.
C'est pourquoi, entre 2025 et 2026, l'attention de toute l'industrie s'est collectivement tournée vers trois voies pour contourner le mur des données –
L'apprentissage par renforcement, DeepSeek R1, la série o d'OpenAI, laissant le modèle s'auto-affronter dans des tâches vérifiables comme les mathématiques et la programmation pour générer des signaux d'entraînement.
Le calcul au moment du test (test-time computation), sans augmenter le coût de l'entraînement, permettant au modèle de « réfléchir » davantage lorsqu'il répond à une question pour obtenir de meilleures performances.
Les données synthétiques, utilisant les modèles forts existants pour générer de nouvelles données afin d'entraîner la prochaine génération de modèles.
Le sous-texte des trois voies est le même : la simple loi de puissance basée sur « l'augmentation de l'échelle » n'est plus suffisante.
De l'Université de Pékin à OpenAI, puis à sa propre entreprise
Lilian Weng, licence à l'Université de Pékin, doctorat à l'Université de l'Indiana à Bloomington.
Il est intéressant de noter que son domaine de doctorat n'était pas l'apprentissage profond, mais la science des réseaux et les systèmes complexes, étudiant comment l'information se propage dans les réseaux sociaux.
Après son doctorat, elle a d'abord travaillé en science des données chez Dropbox, puis dans la fintech Affirm, avant de rejoindre OpenAI en 2018.
À son arrivée chez OpenAI, le premier projet de Weng concernait la robotique. Elle a été l'une des contributrices clés de Dactyl, la main robotique qui a appris à résoudre un Rubik's Cube en deux ans.
Elle a ensuite rejoint l'équipe de recherche appliquée. Après la sortie de GPT-4, elle a été chargée de constituer l'équipe Safety Systems, qui comptait plus de 80 scientifiques, ingénieurs et experts politiques à son départ.
En août 2024, son titre est devenu VP de la recherche et de la sécurité, et trois mois plus tard, elle a annoncé son départ.

En 2017, Weng, alors novice en apprentissage profond, a ouvert un blog personnel appelé Lil'Log, initialement pour organiser ses notes d'apprentissage.
Elle a dit un jour : « Expliquer clairement un concept est la meilleure façon de vérifier si on le comprend vraiment. »
Le résultat : neuf ans d'écriture, couvrant l'apprentissage par renforcement, les modèles de diffusion, les agents de grands modèles, chaque article partant des principes fondamentaux, des dizaines de pages de texte long accompagnées de ses propres schémas.
Ce blog est ensuite devenu l'un des blogs techniques personnels les plus cités dans le domaine de l'IA, directement utilisé comme matériel pédagogique par de nombreuses universités.
En février 2025, elle a cofondé Thinking Machines Lab avec l'ancienne CTO d'OpenAI, Mira Murati. Les autres cofondateurs incluent le cofondateur d'OpenAI John Schulman, les anciens VP de recherche Barret Zoph et Luke Metz. a16z a mené un tour d'amorçage de 2 milliards de dollars, valorisant l'entreprise à 12 milliards.
Et tandis que l'entreprise avançait à grande vitesse, elle a pris le temps d'écrire cet article long sur les lois d'échelle, en attente depuis trois ans.
Les ChatGPT, Claude, Gemini que vous utilisez quotidiennement s'appuient tous sur ces formules pour déterminer comment entraîner la prochaine génération.
L'utilité de la prochaine génération d'IA ne dépendra pas de qui possède le plus de GPU, mais de qui traitera ces détails avec plus de précision.
Références :
https://x.com/lilianweng/status/2070237256070389897?s=20
https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
Cet article provient du compte WeChat officiel « 新智元 » (New Zhiyuan), auteur : ASI启示录, éditeur : Moïse (traduction du nom approximative)


![Analyse de la chute de prix de 12 % de Sonic [S] et pourquoi davantage de ventes pourraient suivre](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)




