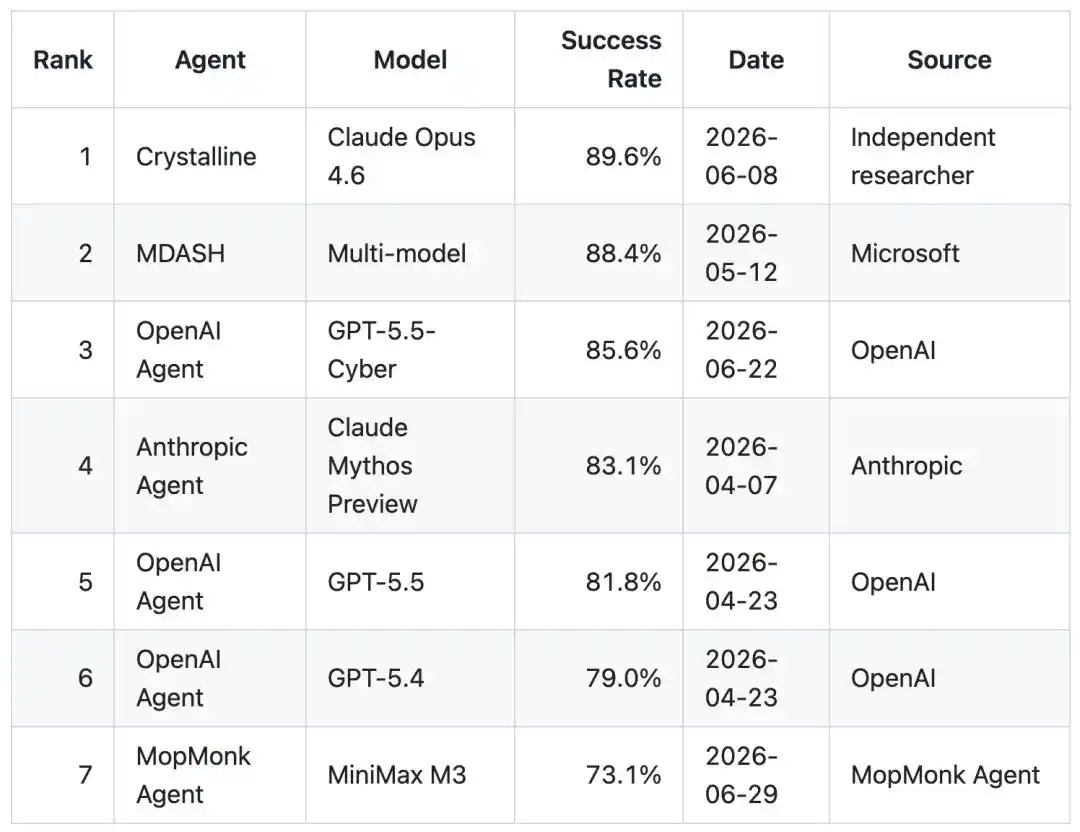
C'est fou ! Un mystérieux IA chinoise « Moine Balayeur » sans même de site officiel, avec un taux de réussite de 73.1%, se hisse dans le top 7 mondial de CyberGym, collant aux basques d'OpenAI. Tout le web en parle, de quel génie s'agit-il ?
Ces derniers jours, sur un classement où s'affrontent les géants mondiaux de l'IA, est soudain apparu un nom que personne ne connaissait.
Il s'appelle MopMonk (Moine Balayeur).
Pas de conférence de presse tapageuse, pas de long article de blog officiel, pas de fanfare sur les réseaux sociaux.
Il est simplement apparu de nulle part, pour foncer directement dans le top 10 mondial de CyberGym.
Avec un taux de réussite de 73.1%, il talonne OpenAI de très près, établissant ainsi le score historique le plus élevé pour une équipe chinoise sur ce classement.
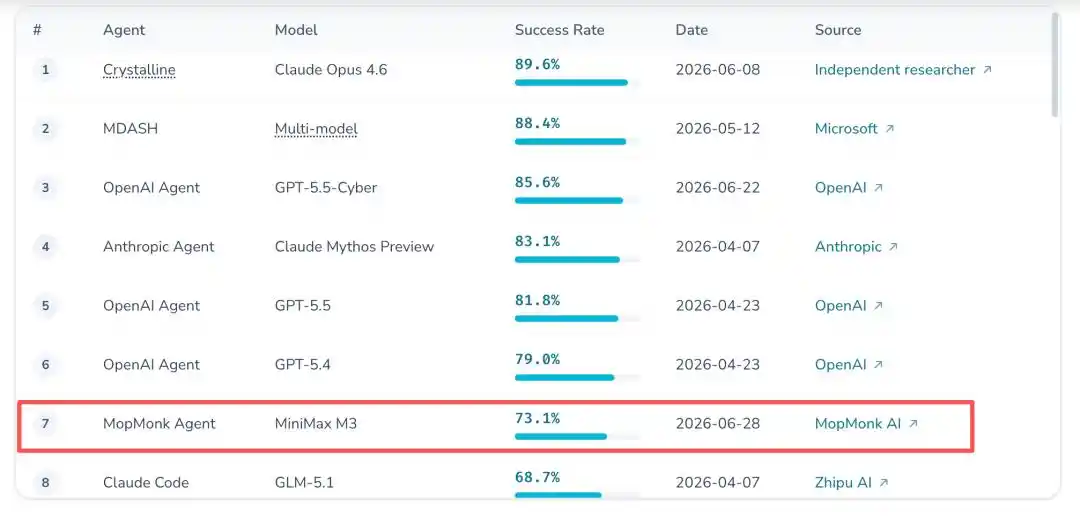
Le plus surréaliste dans tout ça, c'est qu'à ce jour, personne ne connaît sa véritable identité.
À quel point ce classement CyberGym est-il sérieux ?
À quel point la performance de MopMonk est-elle explosive ? Il suffit de regarder l'arène où il s'est produit.
CyberGym, créé par une équipe de UC Berkeley, dont le papier principal a été accepté à la conférence prestigieuse ICLR 2026.

Lien : https://arxiv.org/pdf/2506.02548
En tant que l'un des benchmarks publics les plus autoritaires pour évaluer les capacités de cybersécurité de l'IA, c'est un véritable « champ de bataille » pour les grands modèles —
Même des poids lourds comme GPT-5.5-Cyber ou Claude Mythos s'y sont déjà livrés des combats acharnés.
Ce benchmark mise sur le « vrai combat » :
1507 instances de vulnérabilités, 188 grands projets open-source, toutes les questions sont tirées de vulnérabilités historiques réelles issues de Google OSS-Fuzz.

En termes de dimensions d'évaluation, il s'agit d'une avancée trans-échelle.
Son ampleur est 7,5 fois supérieure au plus grand benchmark public précédent (NYU CTF, ~200 questions), et laisse loin derrière des « anciens » comme CVE-Bench d'un ordre de grandeur.
Pire encore est la difficulté : CyberGym ne propose pas de QCM.
Il demande à l'IA de réaliser un raisonnement profond dans des projets réels pouvant comporter des milliers de fichiers et des millions de lignes de code.
Parce qu'il est suffisamment vaste, réel et difficile, CyberGym a du « pouvoir discriminant » —
Il peut trancher, coup par coup, les écarts réels de capacités entre différents modèles et différentes architectures d'Agent.
Pas étonnant que le milieu de la sécurité l'ait surnommé les « Jeux Olympiques du domaine de la sécurité IA ».
C'est aussi pourquoi presque tous les grands acteurs mondiaux y participent, Microsoft, OpenAI, Anthropic, Google, Meta, Zhipu AI...
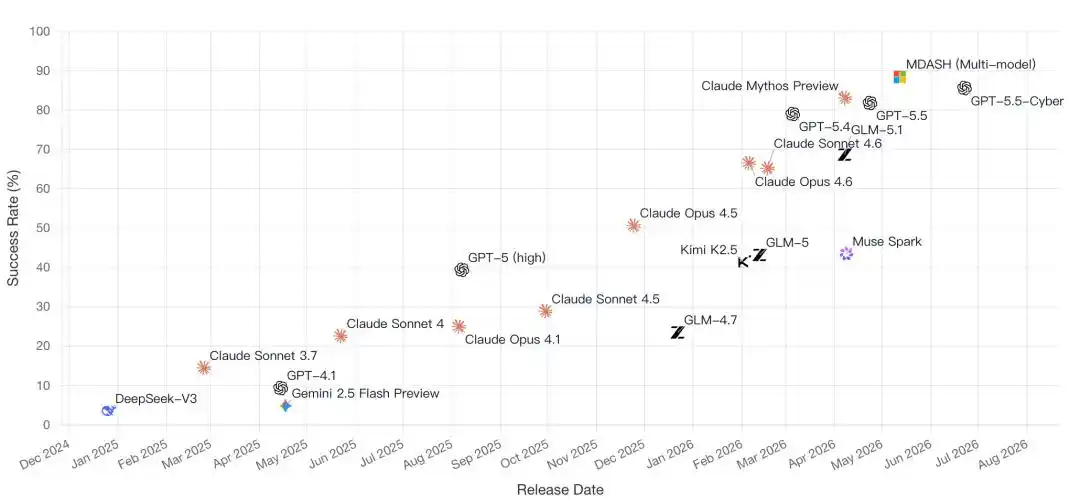
Le classement CyberGym lui-même est le témoin d'un virage crucial dans la compétition IA :
Passer de la course au plus grand nombre de paramètres à celle de l'Agent qui peut réellement accomplir la tâche.
Un code inconnu d'Orient apparaît soudain parmi les géants de la Silicon Valley
Qui aurait imaginé que sur ce ring où la « vraie force » parle le plus, émerge un outsider « sans existence ».
En écartant le brouillard, les informations connues à ce jour se limitent à trois éléments :
Code mystérieux : MopMonk (Moine Balayeur)
Modèle de base : MiniMax M3
Résultat au classement : Entrée dans le top 7 mondial de CyberGym, premier de Chine
Normalement, une équipe avec de tels résultats aurait déjà inondé les médias de rapports techniques et de conférences de presse.
Mais sur ce classement peuplé de maîtres, MopMonk est justement « l'exception » la plus totale : il n'a sorti qu'un rapport technique, l'équipe, l'entreprise, la localisation, tout reste inconnu.
Cette collision entre « puissance maximale » et « information minimale » est en elle-même pleine d'une dramaturgie de type wuxia oriental.
Ceux qui connaissent Jin Yong comprennent le poids des mots « Moine Balayeur » dans « Les Demi-dieux et les démons » —
Ce vieux moine qui balaie depuis des décennies dans le Pavillon des Classiques de Shaolin, dont personne ne se souvient du nom, mais qui d'un seul geste maîtrise deux grands maîtres, Xiao Yuanshan et Murong Bo.
Le personnage le plus insignifiant cache la technique la plus profonde.

Oser défier sous le nom de « Moine Balayeur », cette équipe montre clairement qu'elle a une confiance extrêmement froide en sa propre force !
Un indice plus crucial est caché dans sa base technique — Le modèle de base choisi par MopMonk est MiniMax M3.
En tant que modèle open-source originaire de Shanghai, M3 est un véritable combattant polyvalent, rassemblant directement trois armes clés : des capacités de programmation de pointe, un contexte ultra-long de 1M de tokens, et le multimodal natif.
D'un côté, un « symbole culturel » aux fortes connotations orientales, de l'autre, une base technique clairement estampillée nationale.
En plaçant ces deux indices sur la table, le cercle des possibles se réduit considérablement. Tous les indices pointent furieusement vers la même conclusion :
Il s'agit très probablement d'une équipe chinoise.
La clé de la victoire, dans le Harness
Laissant de côté le mystère de l'identité, en tant qu'observateurs de longue date de la technologie IA, nous voulons surtout comprendre une question :
Comment MopMonk a-t-il gagné ?
Pour répondre, il faut revenir au cœur le plus difficile de CyberGym — il ne teste pas le « savoir » mais le « faire ».
Identifier si un morceau de code contient une vulnérabilité n'est plus si difficile pour les grands modèles d'aujourd'hui.
Mais CyberGym teste l'étape suivante, la plus cruciale : générer une entrée capable de déclencher la vulnérabilité, c'est-à-dire un PoC (Proof of Concept).
Il doit se déclencher sur la « version vulnérable », échouer sur la « version corrigée », et passer la vérification d'exécution dans l'environnement du benchmark.
Cet obstacle est bien plus sournois qu'il n'y paraît.
Les conditions de déclenchement d'une vulnérabilité sont souvent dispersées entre le chemin de code, la logique d'analyse, l'environnement de construction, le Harness de test et le format d'entrée, qu'il faut reconstituer petit à petit.
Pire, même si le PoC fait planter le programme localement, ce n'est pas forcément suffisant. S'il ne satisfait pas le critère différentiel « déclenchement sur version vulnérable, non-déclenchement sur version corrigée », c'est du travail perdu.
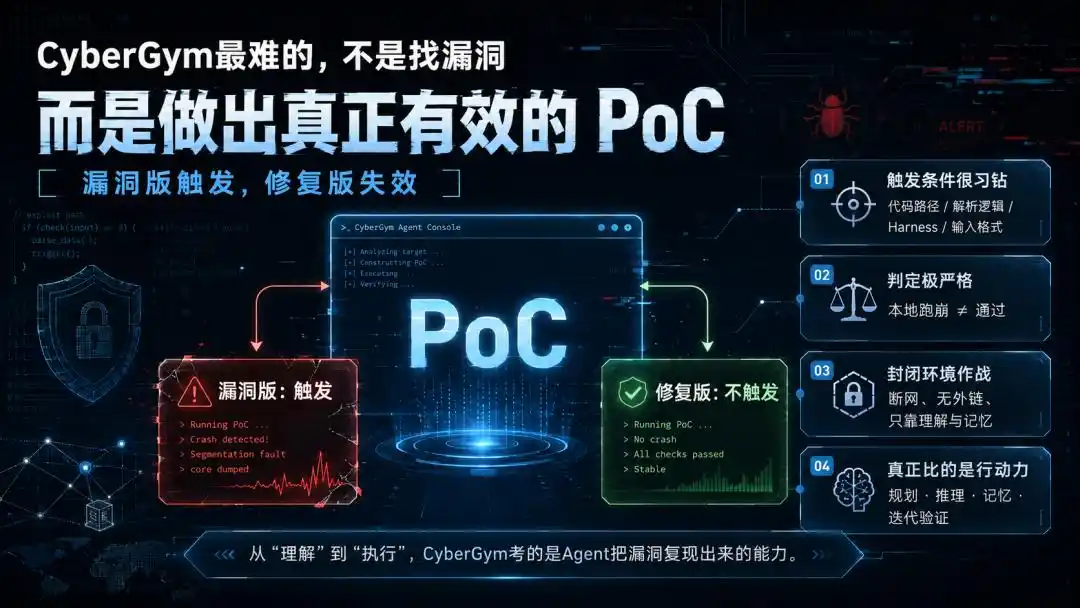
Cette étape fait passer la tâche de la « compréhension » pure à l'« exécution ». Et une exécution très particulière —
L'examen se déroule dans un environnement clos, sans connexion internet.
Pas de recherche externe possible, aucune « ressource extérieure », l'IA ne peut compter que sur sa compréhension de la base de code sous ses yeux et sur la mémoire qu'elle accumule pas à pas.
Dans ces conditions, pour « reproduire » la vulnérabilité, il faut un ensemble de capacités enchaînées :
Planification d'appels d'outils : quand lire un fichier, quand exécuter un test, quand revenir modifier le plan ;
Raisonnement multi-tours : pourquoi le dernier essai n'a pas déclenché, où est le problème, comment ajuster pour le prochain ;
Gestion de la mémoire : stocker de manière structurée le code lu, les entrées testées, les erreurs commises, au lieu de tout relire à zéro à chaque tour ;
Vérification itérative : s'approcher tour après tour du point critique, jusqu'à ce que la vulnérabilité soit réellement reproduite.
En d'autres termes, le cœur du défi de CyberGym est le « pouvoir d'action » de l'Agent, le « QI » du modèle n'étant que le billet d'entrée.
Et le maillon clé qui transforme l'« intelligence » en « pouvoir d'action » est le terme le plus sous-estimé aujourd'hui dans tout le domaine des Agents — le Harness.
Le Harness est la « couche de coordination » entre le modèle et les outils externes, l'environnement d'exécution.
Il est responsable de l'orchestration des outils, de la gestion de l'état du contexte, de la récupération et de la réinjection des retours d'exécution.
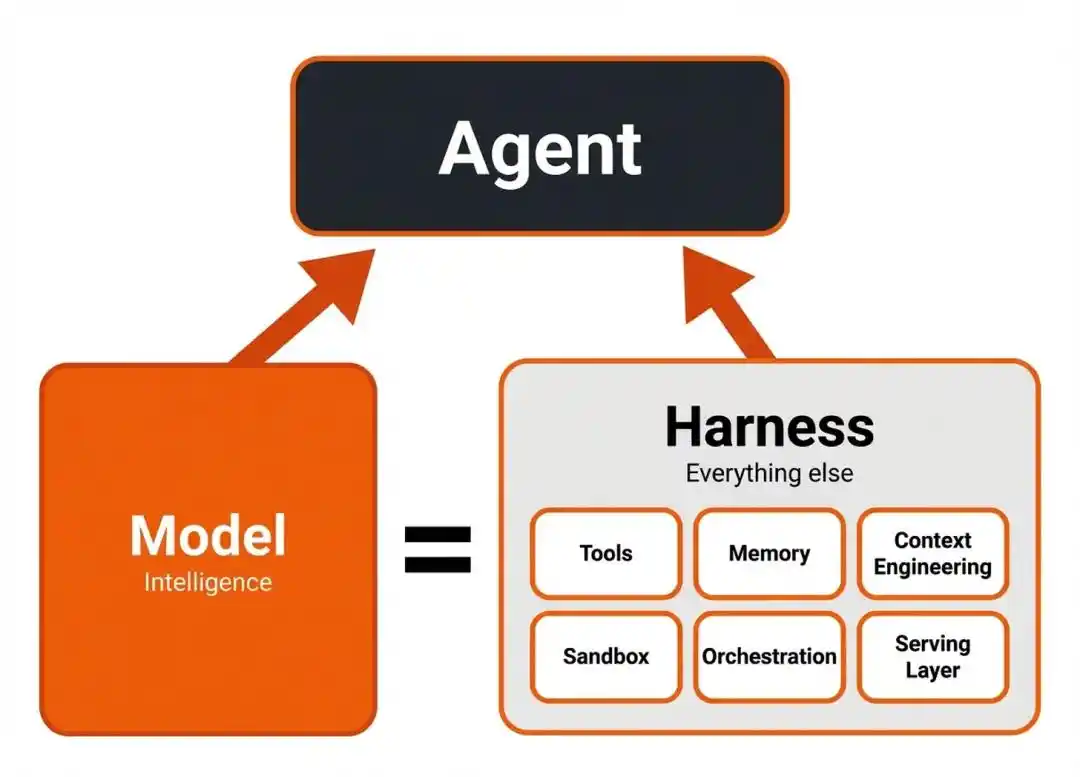
Pour faire simple, le modèle est le cerveau, responsable de penser « où pourrait être la vulnérabilité, comment creuser pour l'étape suivante ».
Le Harness est les membres et le système nerveux, responsable de transformer l'idée du cerveau en une série d'actions réelles —
Quel fichier ouvrir, quelle commande exécuter, comment ajuster après avoir obtenu une erreur, comment modifier après un échec au tour précédent.
Sur des tâches comme celles de CyberGym, qui peuvent nécessiter des dizaines voire des centaines de tours, et des essais-erreurs répétés dans des millions de lignes de code, la qualité du Harness détermine directement si le QI du modèle peut se transformer en puissance de combat.
Un modèle intelligent + un Harness médiocre donne souvent « capable de concevoir, incapable d'exécuter » ;
Un modèle aux capacités solides + un Harness puissant conçu sur mesure pour l'exploitation de vulnérabilités peut potentiellement obtenir des résultats sur ce type de tâches longues.
Un Agent « sur mesure » pour l'exploitation de vulnérabilités
Aujourd'hui, à travers le rapport technique GitHub, les grandes lignes techniques de MopMonk sont claires :
Un système multi-Agents de sécurité entièrement conçu pour l'exploitation de vulnérabilités, dont la base de raisonnement est précisément MiniMax M3.

Adresse GitHub : https://github.com/MopMonkAI/MopMonkAgent
Comme mentionné, M3 est aujourd'hui un modèle open-source rare, capable de regrouper dans une architecture unique des capacités de codage de pointe, un contexte d'un million de tokens et le multimodal natif.
Un coup d'œil aux scores suffit : 59,0% sur SWE-Bench Pro, 66,0% sur Terminal-Bench 2.1, 74,2% sur MCP Atlas —
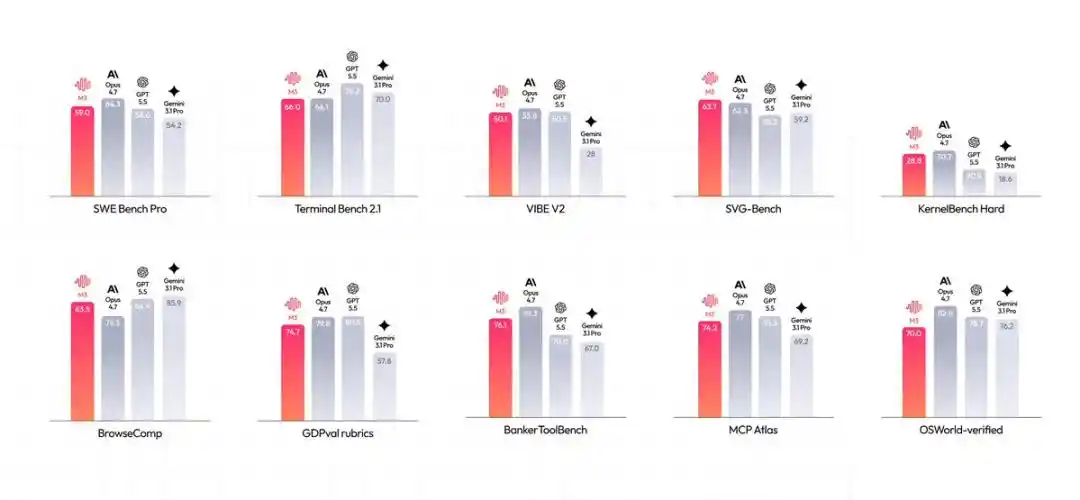
Ces données impressionnantes répondent précisément aux besoins les plus critiques lors de la mise en pratique d'un Agent.
De plus, il peut itérer et s'auto-corriger de manière autonome sur des tâches de plusieurs heures.
En d'autres termes, M3 joue le rôle d'un « cerveau ultime » combinant une capacité d'analyse de code exceptionnelle, une mémoire ultra-longue et une maîtrise de l'appel d'outils.
Pour des tâches comme celles de CyberGym, qui peuvent nécessiter d'ingérer toute une base de code et de s'exécuter sur des dizaines de tours, une fenêtre de contexte de 1M de tokens est presque une exigence.
Et ce que fait ce framework d'Agent de sécurité MopMonk, c'est amplifier les capacités du cerveau M3 en puissance d'exécution pour l'exploitation de vulnérabilités.
Son « art martial interne », d'après les détails techniques publics sur GitHub, repose sur trois mouvements —
Premier mouvement, la « mémoire de vulnérabilité » structurée.
Il ne s'agit pas simplement d'empiler des historiques de chat, ni de bourrer le modèle avec un énorme contexte, mais d'organiser une « mémoire factuelle de la tâche » durable et actualisable, centrée sur les types d'objets les plus cruciaux dans l'exploitation de vulnérabilités :
Cible de vulnérabilité, chemin de code, format d'entrée, PoC candidats, preuves d'échec, état de vérification, et mémoire des « contraintes suivantes ».
Ce dernier type est particulièrement remarquable : il ne génère pas de plans abstraits vagues, mais extrait directement des preuves actuelles les contraintes strictes que la prochaine expérience doit satisfaire.
Par exemple, « cette fois doit couvrir cette branche », « quel champ ajuster », « exclure quel type de cause d'échec ».
Cette conception de la mémoire transforme l'exploitation de vulnérabilités d'un « essai-erreur répété à partir de zéro » en un « processus de convergence basé sur des preuves ».
Chaque lecture de code, chaque résultat d'exécution, chaque soumission d'échec est converti en contraintes réutilisables pour la génération du PoC suivant.

Deuxième mouvement, l'« exploitation de vulnérabilités » guidée par la mémoire.
Dans une tâche d'exploitation, le système initialise d'abord la mémoire de vulnérabilité en scannant la base de code et en utilisant les chemins de déclenchement candidats et les informations de répertoire comme point de départ de la planification.
Ensuite, il avance pas à pas, essayant de converger vers l'emplacement de code spécifique déclenchant le crash.
Par la suite, chaque tentative d'exploration lit la mémoire actuelle, teste une hypothèse concrète et réécrit le résultat dans la mémoire.
Ainsi, le modèle n'a pas besoin de tout relire depuis le début à chaque tour, mais extrait de cette mémoire structurée le petit morceau de preuve le plus pertinent —
Réduisant considérablement la charge du contexte long, et permettant à chaque variation du PoC candidat d'hériter des connaissances accumulées précédemment sur les chemins de code et les formats d'entrée, rendant la recherche de plus en plus précise.
Dans le budget d'exploration strict, le temps est donc consacré autant que possible aux « nouvelles hypothèses », augmentant drastiquement la densité d'expérimentation efficace.
Troisième mouvement, l'« exploration multi-Agents parallèle » avec mémoire partagée.
Plusieurs tentatives d'exploration partagent la même mémoire de vulnérabilité, pouvant avancer simultanément depuis plusieurs directions (indices de correctif, point d'entrée du harness, champs de format de fichier, type de sanitizer, conditions limites, etc.) et hériter mutuellement des expériences d'échec et des résultats de vérification.
Cela élargit la couverture tout en évitant les explorations répétées inefficaces.
On voit ainsi que MopMonk a transformé la reproduction de vulnérabilités, d'un processus ouvert d'essais-erreurs répétés, en un processus de « mise à jour de la mémoire » qui peut accumuler, contraindre et vérifier.
Les trois mouvements combinés, reposant entièrement sur l'« art martial interne » sédimenté, raffiné et réutilisé étape par étape au sein de la tâche, ont façonné un modèle de base open-source puissant en un soldat d'élite sur le champ de bataille de l'exploitation.
Finalement, il a atteint un taux de réussite de 73,1%.
Le modèle de base est responsable de « penser profondément », le Harness est responsable de « se souvenir fermement, ajuster précisément, frapper solidement ».
Leur couplage profond a finalement forgé ce résultat perçant et remarquable sur le classement.
Un jugement plus précieux que « l'empilement de paramètres »
La véritable leçon de cette affaire est que —
Ces dernières années, la tendance de l'industrie était « d'empiler les paramètres » : plus les paramètres sont grands, plus le modèle est fort, plus le classement est haut.
Mais des tâches de confrontation réelle comme CyberGym donnent une autre réponse : ce qui décide de plus en plus de l'issue, c'est la capacité d'exécution de l'Agent, c'est l'épaisseur de l'ingénierie de cette couche Harness.
D'après le rapport technique GitHub, la valeur de cette méthode repose sur trois points :
Les fortes capacités du modèle de base fournissent la base de la recherche ;
La mémoire structurée des vulnérabilités fournit le mécanisme de convergence ;
L'exploration multi-intelligences avec mémoire partagée améliore l'efficacité coût dans un budget limité.
Le modèle de base détermine la limite supérieure des capacités, et ce Harness centré sur la mémoire détermine combien de ces capacités peuvent être réellement converties.
Plus crucial encore est son effet cumulatif :
Les modèles de base changeront de génération en génération, aujourd'hui M3, demain peut-être un modèle open-source plus récent.
Mais un Harness forgé et affiné par les champs de bataille réels, riche en expérience offensive et défensive, est un actif qui peut traverser les itérations de modèles de base et continuer à générer des bénéfices.
En bref, la valeur à long terme du Harness MopMonk pourrait être plus grande que « doubler encore les paramètres ».
C'est précisément la raison pour laquelle le milieu commence à examiner sérieusement ce mystérieux « Moine Balayeur » :
Ce qu'on veut voir, ce n'est pas seulement son score, mais qu'il montre une voie pour pousser un modèle de base open-source à l'extrême.
Alors, qui est vraiment ce « Moine Balayeur » ?
Après ce tour, nous revenons à la question du début, celle qui démange le plus.
MopMonk, qui est-ce ?!
En assemblant les indices : un code débordant de saveur wuxia orientale + le modèle de base MiniMax d'une entreprise de Shanghai + un « art martial interne » dans le domaine de la sécurité.
Presque toutes les flèches pointent vers le même jugement : il s'agit d'une entreprise de sécurité IA chinoise, très probablement basée à Shanghai.
Certains, sous l'angle de l'adaptation bidirectionnelle modèle/Agent, spéculent que son origine est forcément liée à l'équipe native d'un grand modèle d'IA.
Différentes versions de rumeurs circulent, mais personne n'a encore de preuve concrète.
À votre avis, de quel génie MopMonk pourrait-il être l'œuvre ? Laissez vos révélations dans les commentaires.
Cet article provient du compte WeChat officiel « New Zhiyuan », auteur : ASI Apocalypse







