Le 15 juin, Li Auto a dévoilé en détail les spécificités de sa puce auto-développée Mach M100 lors d’une conférence de presse, une puce d’assistance à la conduite conçue pour la nouvelle L9 Livis. Le CTO Xie Yan a souligné : il ne s’agit pas seulement de fabriquer une puce plus rapide que les précédentes, mais de concevoir une puce fondamentalement différente. Cette « différence » concerne précisément l’architecture de la puce.
En 2026, alors que les constructeurs automobiles se lancent massivement dans le développement de leurs propres puces, les TOPS constituent le principal argument marketing. Que ce soit la puce Nio Shenji NX9031, la puce Xiaopeng Turing ou le Huawei MDC 810 Pro, tous mettent en avant les chiffres de puissance de calcul. Li Auto, quant à lui, a choisi de réformer l’architecture dès les couches les plus fondamentales.
Le Mach M100 cherche à prouver que l’architecture est plus importante que les chiffres de performance. Mais sa validité devra être vérifiée sur le marché.
01. Divergences dans le développement de puces à l’ère de l’inflation des performances
Le développement de puces en propre est devenu un choix commun pour les principaux constructeurs chinois.
La puce Nio Shenji NX9031 est la première puce d’assistance à la conduite haute performance au monde gravée en 5nm. Sa particularité réside dans son ISP auto-développé, avec un taux de détection de piétons supérieur de 40% à celui des puces génériques dans des conditions de faible luminosité (1 lux), renforçant ainsi significativement la couche de perception.
La puce Turing de Xiaopeng présente également une personnalisation marquée, étant spécialement conçue pour le grand modèle d’assistance à la conduite de la marque, avec l’ambition de s’étendre aux voitures volantes et aux robots.
Huawei emprunte un autre chemin, utilisant l’architecture Ascend pour son MDC, mettant l’accent sur l’alignement parfait entre l’entraînement dans le cloud et l’inférence à bord : « une minute d’entraînement dans le cloud, une minute de suivi à bord ».
Ces approches sont des variantes de l’architecture de von Neumann : une unité centrale de traitement, où les données sont déplacées de manière répétée entre l’unité de calcul et la mémoire. Plus la finesse de gravure est avancée, plus le transfert est rapide, mais le Mach M100 cherche à changer la façon même dont ces données sont déplacées.
02. Réformer la logique fondamentale
L’architecture de von Neumann ne posait pas de problème à l’ère du calcul généraliste, mais l’inférence des grands modèles constitue une autre forme de calcul. L’inférence d’un modèle de vision de type VLM repose sur un parallélisme massif de matrices, et non sur l’exécution séquentielle d’instructions. Le goulot d’étranglement se situe presque entièrement dans la bande passante mémoire. Les pertes liées aux allers-retours constants des données entre la mémoire et le processeur consomment directement une part importante de la puissance de calcul effective.
La logique de l’architecture à flux de données dynamique (dynamic dataflow) consiste à faire circuler les données le long du graphe de calcul, évitant ainsi les réécritures répétées en mémoire. Le résultat annoncé par Li Auto est que la puissance de calcul effective d’une seule puce Mach M100 serait environ trois fois supérieure à celle du Nvidia Thor U, avec une latence bout en bout réduite de 40%.

À quel point ce facteur « 3 » est-il crédible ? Une validation externe peut être citée. L’article scientifique sur l’architecture du Mach M100 a été accepté dans la section industrielle de l’ISCA 2026. L’ISCA est une conférence académique de premier plan en architecture des ordinateurs. Les articles de la section industrielle sont soumis à une relecture par les pairs, et les détails de conception de l’architecture sont publics. Li Auto est le premier constructeur automobile à être sélectionné dans cette section depuis sa création.
Mais ce facteur 3 est conditionnel. La puissance de calcul effective dépend de la charge de travail spécifique. Le gain de 3x a été obtenu en exécutant l’algorithme maison VLA2.1 ; il n’est pas garanti avec un autre système. Le Mach M100 est une puce native aux algorithmes, développée en parallèle avec le modèle, optimisée en profondeur pour ses propres algorithmes. Elle excelle avec ses modèles propres, pas nécessairement avec des tâches génériques.
Cette logique est similaire à celle de la puce Turing de Xiaopeng, et la puce FSD de Tesla suit également cette voie. La différence est que Tesla et Xiaopeng n’ont pas opéré de changement de paradigme au niveau de l’architecture, alors que le Mach M100 a réformé la logique fondamentale. Amener une toute nouvelle architecture jusqu’à la fiabilité en série par un constructeur automobile est en soi un défi sans précédent.
Avec l’intégration du Mach M100, Li Auto réalise l’intégration verticale complète, maîtrisant en interne la puce, le compilateur, le système d’exploitation, les algorithmes d’IA et le contrôleur de domaine. Cette boucle fermée est rare parmi ses pairs.
Nio développe ses puces mais dépend différemment du système d’exploitation ; Xiaopeng développe ses puces mais son compilateur et son OS dépendent encore de solutions externes ; Huawei maîtrise la boucle fermée mais n’est pas un constructeur automobile à part entière. La signification stratégique de la chaîne de Li Auto réside dans son indépendance face à la chaîne d’approvisionnement de Nvidia, le fait que les données restent dans sa propre plateforme, et son autonomie complète pour optimiser la synergie logicielle/matérielle.
03. Prendre position sur « l’intelligence incarnée »
La puce n’était qu’un des protagonistes de la conférence. Li Xiang a également présenté la définition de la « voiture à intelligence incarnée » basée sur « quatre en un » : un véhicule électrique, un chauffeur professionnel, un ordinateur d’IA et un assistant de vie.
Cette vision marque un écart significatif par rapport au récit de marque précédent de Li Auto.
En 2023, la L9 a percé le marché des 300 000 à 500 000 yuans avec le positionnement « grand SUV familial 6 places », donnant naissance à une première génération de produits similaires. Le problème de ce positionnement est son faible coût de reproduction : le AITO M9, le Nio ES9, le Zeekr 9X sont arrivés sur le marché, le frigo-écran-grand canapé est devenu une norme sectorielle, et aucun acteur ne parvient à se démarquer, ne laissant place qu’à la guerre des prix.
La « voiture à intelligence incarnée » déplace la compétition des équipements vers les capacités systémiques. Dans ce cadre, le frigo et l’écran arrière sont des équipements de base. Le différentiel devient « quel système est capable de percevoir, de réfléchir, d’apprendre ». La définition du segment est en soi un actif stratégique ; celui qui la formule le premier s’approprie la position.
Li Auto accompagne ce récit d’une chaîne technologique relativement complète. La base de calcul du Mach M100, le grand modèle d’assistance à la conduite Mach VLA2.1, les modèles de base en périphérie Mach Mind-Pro et Mind-Edge, l’OS Star Ring assurant la connexion complète de la pile, chaque couche a son produit correspondant.
La conférence a démontré des expériences perceptibles : le véhicule bougeant au rythme de la musique, un simulateur de course 4D, le stationnement autonome sur commande. Li Xiang a également déclaré que la conduite autonome n’était que la « première mi-temps » de l’intelligence incarnée, les robots humanoïdes généraux constituant la « seconde mi-temps », mais le calendrier et les chemins de réalisation de cette seconde mi-temps restent flous.
04. L’engagement pour le Q4
La conférence a également comporté une déclaration clé : le grand modèle d’assistance à la conduite Mach VLA de Li Auto visera à rattraper les performances du Tesla FSD V14 au quatrième trimestre de cette année.
Le style habituel de Li Xiang est de s’engager publiquement, utilisant la pression externe pour forcer l’exécution interne. En annonçant vouloir égaler le FSD V14 au Q4, tout le monde utilisera cette référence pour évaluer les résultats fin d’année.
Sur le plan technique, le choix de Li Auto est hautement similaire à celui de Tesla : approche de bout en bout (end-to-end) + grand modèle VLA + vision pure comme base. Huawei suit une autre voie : lidar + fusion multi-capteurs + approche hybride règles/réseaux neuronaux. Cette dernière offre une stabilité de déploiement à court terme et des besoins en calcul moindres. Mais à long terme, si la voie vision pure + grands modèles finit par l’emporter, le système de Huawei pourrait faire face à des coûts de transition plus élevés. Li Auto parie sur la même conviction technique que Tesla. La validité de ce jugement sera à vérifier fin d’année.
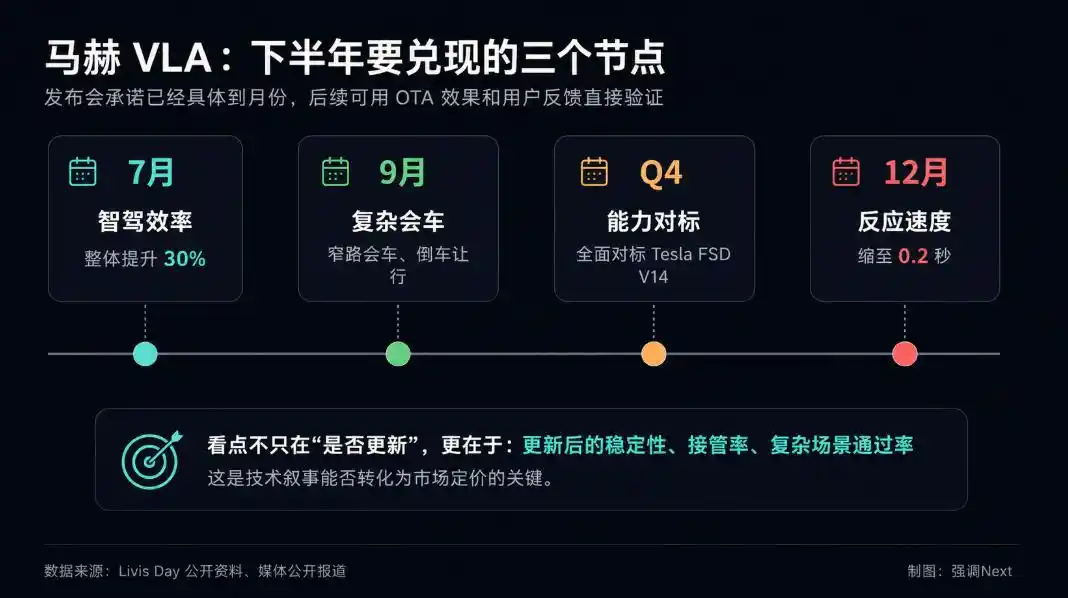
Les promesses d’OTA pour le second semestre sont détaillées mois par mois. Juillet : amélioration de l’efficacité de l’assistance à la conduite de 30%. Septembre : réalisation des manœuvres de croisement/reculement dans les rues étroites. Décembre : réduction du temps de réaction du véhicule à 0,2 seconde. Chaque étape a ses indicateurs techniques clairs, permettant une comparaison avec les données de fin d’année.
05. Quelques données au-delà de la conférence
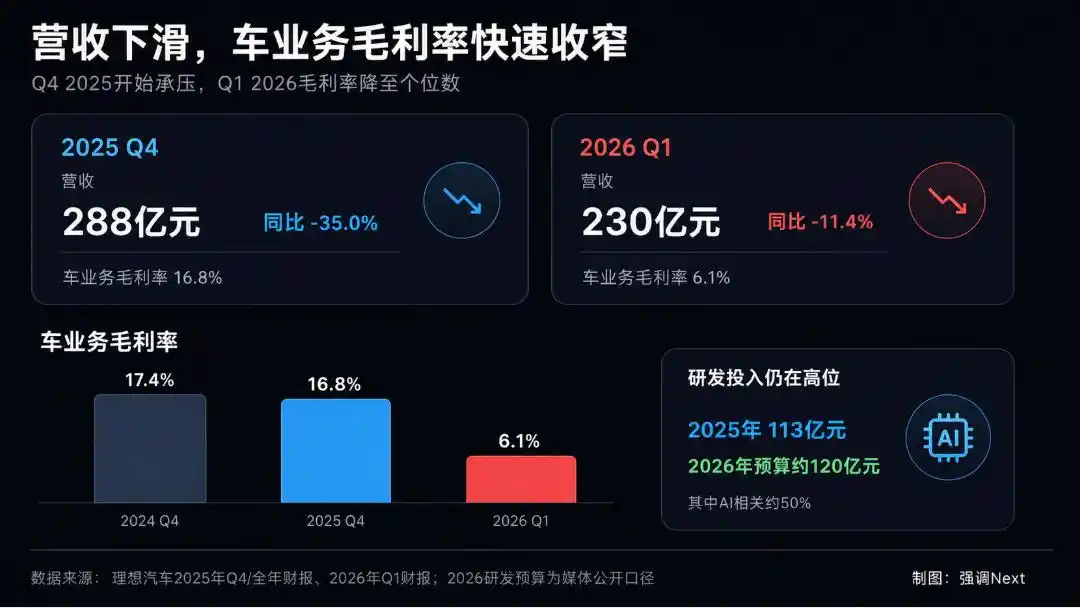
La situation financière de Li Auto n’est actuellement pas facile. Depuis le Q4 2025, ses revenus ont reculé en glissement annuel, et la marge brute de l’activité automobile s’est nettement réduite. Parallèlement, le budget R&D pour 2026 est maintenu autour de 12 milliards de yuans, dont environ 50% liés à l’IA, niveau comparable aux 11,3 milliards et 50% de 2025. Les investissements en R&D ne diminuent pas, la pression sur la rentabilité persiste.
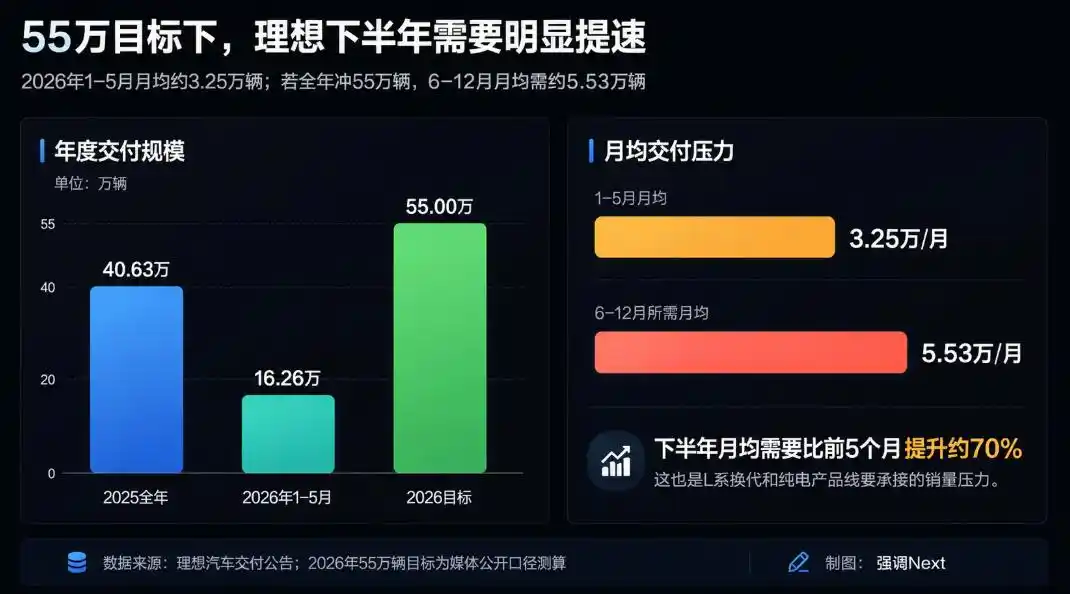
En termes de ventes, l’objectif de Li Auto pour 2026 est de 550 000 véhicules. Les livraisons réelles de 2025 ont été de 406 000 unités. En mai, les livraisons mensuelles s’élevaient à 33 000 unités, toujours en baisse annuelle. La nouvelle L9 Livis a obtenu plus de 10 000 commandes fermes dans les deux semaines suivant son lancement, avec des performances stables sur le marché au-dessus de 500 000 yuans. Mais le volume de livraisons global devra être soutenu par le renouvellement complet de la gamme L et le déploiement de la gamme tout électrique au second semestre.
Au niveau des puces, le couplage profond du Mach M100 avec ses propres algorithmes est un choix de conception qui offre des avantages d’efficacité grâce à la synergie logicielle/matérielle. Cela signifie également que si une adaptation de la feuille de route technologique s’avère nécessaire à l’avenir, les coûts de transition seront plus élevés que pour les constructeurs utilisant des solutions de puces tierces. Les puces Turing de Xiaopeng et Shenji de Nio font face à une situation similaire, de même que la puce FSD de Tesla. C’est une caractéristique commune des puces natives aux algorithmes développées en interne.
06. Les cartes seront révélées au troisième trimestre
Le lancement de la nouvelle L9, suivi de près par la L8, le premier jalon OTA en juillet… les premiers effets de ces actions seront visibles dans les résultats du troisième trimestre.
Xie Yan a déclaré qu’il devait concevoir une puce fondamentalement différente. L’acceptation de l’article d’architecture par des pairs constitue une reconnaissance externe de cette approche de conception. Mais du design à la production de masse, puis aux retours réels des utilisateurs dans leur conduite quotidienne, le chemin est encore long. Le jalon OTA de juillet sera le premier test, la comparaison avec le FSD V14 fin d’année en sera un encore plus critique.
Cet article provient du compte public WeChat « QiangDiao Next » (ID : leo89203898), auteur : Yi Xiu, éditeur : Xiao Bai.