Si un jour vous tombez sur le nom de Max Planck dans une liste de rétractations, vous penserez probablement avoir atterri sur un site parodique universitaire.
Après tout, ce n'est pas un auteur ordinaire. Planck est le fondateur de la théorie quantique, lauréat du prix Nobel de physique en 1918, et l'un des noms les plus importants de l'histoire scientifique du XXe siècle.
Mais un nouvel article indique que deux articles publiés par Planck en 1940 et 1942 ont été marqués comme "retracted" (rétractés) sur la plateforme numérique de Springer.


Titre de l'article : The Curious Case of Max Planck retracted papers. When past scientific practices meet contemporary publishing norms Adresse de l'article : https://arxiv.org/abs/2605.17534
Le plus drôle, d'après l'enquête des auteurs de l'article, c'est que ces deux articles n'ont pas été rétractés pour fraude, erreur ou inconduite académique, mais ont été victimes d'une erreur algorithmique.
01
Tout a commencé par une "Liste des rétractations de lauréats du prix Nobel" sur le site Retraction Watch (site d'enregistrement des problèmes de publication académique).
En tant que chercheur en histoire de la physique, l'auteur a été surpris de voir Max Planck dans cette liste, car ces deux articles provenaient de la revue scientifique allemande « Die Naturwissenschaften ». À cette époque, Planck était déjà un physicien mondialement reconnu, et il était difficile pour l'auteur de croire que ces articles avaient vraiment été rétractés de son vivant, ou qu'il existait plus tard des raisons suffisantes pour une rétractation.

Lien : https://retractionwatch.com/retractions-by-nobel-prize-winners/
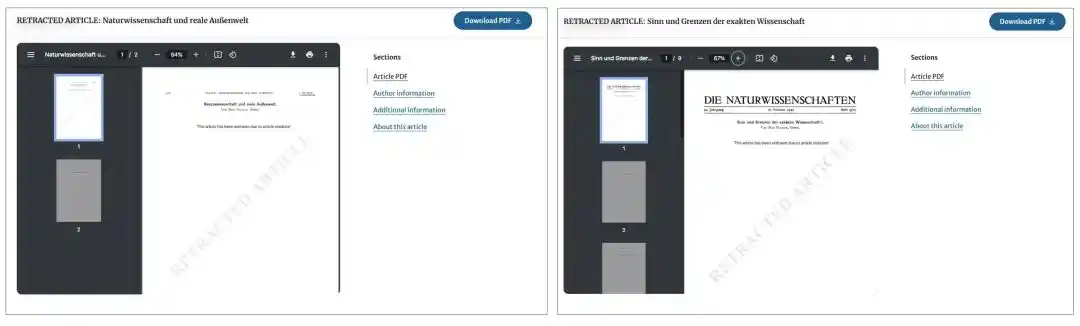
L'explication fournie sur la plateforme Springer est assez vague. Le titre de la page le marque comme "RETRACTED ARTICLE" (article rétracté), mais le PDF mentionne "This article has been withdrawn due to article violation" ; la formulation sur la page web est plus explicite, indiquant que l'article a été rétracté pour "copyright violation" (violation du droit d'auteur).
Autrement dit, il s'agit probablement d'un incident créé par un mélange de problèmes de droit d'auteur, d'archivage numérique et de gestion des métadonnées par la plateforme — ces deux anciens articles ont été traités comme des problèmes de droit d'auteur ou de publication dupliquée par le système/l'éditeur dans les bases de données modernes.
Revenons à l'écosystème de l'édition scientifique de la première moitié du XXe siècle. « Die Naturwissenschaften » a été fondée en 1913, publiée par Julius Springer Verlag, un peu comme la version germanophone de « Nature » : c'était une revue scientifique hebdomadaire couvrant les progrès en sciences naturelles, médecine et technologie. Elle publiait à la fois des articles techniques, des discours, des rapports de conférences, ainsi que des discussions sur la philosophie des sciences et sa signification culturelle.
Les deux articles de Planck eux-mêmes n'étaient pas des articles de recherche rapportant de nouvelles expériences ou théories, mais plutôt des réflexions philosophiques sur la nature de la connaissance scientifique.
L'article de 1942, « Le sens et les limites des sciences exactes », est particulièrement typique. Il s'agissait à l'origine d'un discours prononcé par Planck en 1941 à la Kaiser-Wilhelm-Gesellschaft de Berlin, qui a ensuite circulé sous diverses formes : publié sous forme de brochure en 1942, également paru dans « Europäische Revue » et « Die Naturwissenschaften », puis inclus en 1943 dans un recueil de discours et d'articles de Planck.
Aujourd'hui, ce parcours serait facilement identifié par une plateforme ou un système de droits d'auteur comme une "publication dupliquée". Mais à l'époque, la diffusion multicanale d'une idée scientifique, d'un discours à une revue, d'une brochure à un recueil, faisait partie intégrante de la diffusion des idées scientifiques.
L'article de 1940, « Sciences naturelles et monde extérieur réel », est encore plus étrange. L'auteur de l'étude n'a trouvé aucune preuve de sa publication ailleurs. Une explication possible avancée par l'auteur est la suivante : quelques mois plus tôt dans la même revue, un autre auteur, Aloys Müller, avait publié un article du même titre, discutant de la position philosophique de Planck ; Planck a ensuite répondu avec un article portant le même titre, engageant ainsi le débat d'idées.
Dans la culture éditoriale de l'époque, cela ne posait évidemment aucun problème, c'était même une posture de dialogue explicite. Mais pour les systèmes ultérieurs d'indexation numérique, de gestion des droits d'auteur et des métadonnées, deux titres identiques peuvent être identifiés comme un cas suspect de duplication.
L'article souligne également que ces deux articles "rétractés" sont même devenus des pages blanches sur la plateforme Springer. Normalement, même si un article est rétracté, le texte original est conservé, avec simplement l'ajout d'une note de rétractation pour préserver l'intégrité des archives scientifiques. Mais ici, l'article de deux pages de 1940 et celui de neuf pages de 1942 ont été effacés sur la plateforme numérique. Pour lire l'original aujourd'hui, il ne faut pas aller chez Springer, l'éditeur original, mais se tourner vers l'Internet Archive à but non lucratif.

02
À ce stade, l'affaire dépasse le simple côté amusant de "Planck rétracté par erreur". C'est un véritable déraillement des infrastructures modernes de publication académique : lorsque des documents historiques entrent dans des plateformes d'édition numérique modernes, qui a le droit de décider ce qui constitue une "publication dupliquée", une "violation du droit d'auteur", et ce qui doit rester visible ?
L'auteur de l'article estime que des concepts comme "publication dupliquée" ou "auto-plagiat" ne sont pas des normes éthiques académiques éternelles et immuables. Ce sont des catégories modernes, liées à la bibliométrie, à l'évaluation de la recherche, au transfert des droits d'auteur et aux plateformes d'édition commerciale qui se sont développées depuis la fin du XXe siècle. L'article précise clairement que l'"auto-plagiat" est un concept relativement récent, qui a émergé avec les systèmes d'évaluation de la productivité académique basés sur le nombre de publications depuis les années 1990.
C'est aussi un point familier dans le système académique d'aujourd'hui : le problème n'est pas seulement "quel est le contenu", mais aussi "comment le contenu est représenté par le système".
Un article historique entrant dans une base de données est décomposé en objets structurés : DOI, titre, auteur, statut des droits d'auteur, étiquette de rétractation, fichier PDF, historique des citations, etc. Dès qu'une plateforme traite les anciennes littératures automatiquement ou semi-automatiquement selon les règles contemporaines, elle risque de transformer des pratiques éditoriales normales du passé en infractions d'aujourd'hui.
Ce décalage est particulièrement préoccupant à l'ère de l'IA.
Lorsque nous parlons aujourd'hui de données d'entraînement, de nettoyage des données, de bases de données bibliographiques, de graphes de connaissances et de RAG, nous supposons souvent que les connaissances numérisées sont stables, consultables et exploitables. Mais cette affaire nous rappelle que les archives numériques ne sont pas un "miroir du passé" neutre, mais un ensemble de filtres porteurs de logiques commerciales, d'hypothèses juridiques et de règles de plateforme. Les données peuvent être renommées, reclassées par la plateforme, voire remplacées par des pages blanches.
Un système moderne de droits d'auteur et de bibliométrie a rétroactivement jugé suspectes des pratiques normales de diffusion scientifique de l'ère pré-numérique. Plus grave encore, ce jugement ne s'est pas arrêté au niveau de l'étiquetage, mais a directement affecté l'accessibilité des documents historiques.
Pour le système de production de connaissances qui entre dans l'ère de l'IA, une étiquette erronée, un PDF manquant, un traitement opaque des droits d'auteur peuvent tous être amplifiés dans les modèles, les moteurs de recherche et les outils académiques. Les futurs assistants IA ne sauront pas nécessairement que l'article de Planck a été "rétracté par erreur", ils ne verront peut-être que cette étiquette froide "retracted" dans la base de données.
Alors que la mémoire scientifique est de plus en plus confiée aux bases de données, aux éditeurs, aux règles des plateformes et aux infrastructures commerciales, pourrons-nous encore voir avec précision le passé de la science ?
Lien de référence : https://www.science.org/content/article/why-have-papers-one-history-s-most-famous-physicists-been-retracted
Cet article provient du compte WeChat officiel "Machine Heart" (ID : almosthuman2014), auteur : Focus on Academics