A finales de 2024, un artículo titulado "Finalmente funciona el aprendizaje por refuerzo profundo en flujo continuo" (arXiv:2410.14606) generó un amplio debate en la comunidad académica. Los autores, del equipo de Mahmood de la Universidad de Alberta, dedicaron muchas páginas a describir una realidad embarazosa: el aprendizaje por refuerzo, un método que por naturaleza debería "aprender sobre la marcha", en la era de las redes neuronales profundas casi no puede lograrlo. Si simplemente se elimina el búfer de repetición (replay buffer) y se establece el tamaño de lote (batch size) en 1, el entrenamiento colapsa. Lo denominaron la "barrera del flujo continuo" (stream barrier).
Ese artículo propuso la serie de algoritmos StreamX, que, mediante hiperparámetros finamente ajustados, inicialización dispersa y varias técnicas de estabilización, apenas lograron superar este muro.
Sin embargo, menos de un año y medio después, un miembro del mismo grupo de investigación, junto con colaboradores del Instituto Openmind, ofreció una respuesta completamente diferente: la raíz de la barrera del flujo continuo no es "datos insuficientes", sino "unidad incorrecta del tamaño del paso de aprendizaje (step size)".

Título del artículo: Intentional Updates for Streaming Reinforcement Learning
Dirección del artículo: https://arxiv.org/pdf/2604.19033v1
Repositorio de código: https://github.com/sharifnassab/Intentional_RL
Un golpe de acelerador y el tamaño del bache
Imagina que estás aprendiendo a estacionar un coche. El instructor te dice que cada vez "pises el acelerador durante 0.1 segundos". El problema es que, pisando el mismo tiempo de 0.1 segundos, la distancia que avanza el coche puede variar enormemente dependiendo de si es en subida, en bajada, con el vehículo vacío o cargado. A veces se queda a un centímetro de entrar perfectamente, otras veces se queda a 30 centímetros y choca directamente contra la pared.
El tamaño del paso en el aprendizaje por gradiente tradicional hace precisamente eso: especifica cuánto deben moverse los parámetros cada vez, pero no controla en absoluto cuánto cambia realmente la salida de la función. En el entrenamiento por lotes, los errores de cientos o miles de muestras se promedian, diluyendo los casos extremos, y el problema no es tan evidente. Pero en un entorno de "flujo continuo", cada paso tiene solo una muestra, sin promedio posible. Una vez que la dirección del gradiente es inestable, la magnitud de la actualización fluctuará salvajemente — hoy avanza 30 cm, mañana retrocede 50 cm — y el proceso de aprendizaje colapsa en medio de violentas oscilaciones.
Este fenómeno de "sobrepaso y subpaso" (overshooting and undershooting) es particularmente grave en el aprendizaje por refuerzo, porque el gradiente en cada paso de tiempo no solo varía en magnitud, sino que también cambia de dirección a gran velocidad.
Redefiniendo "cuánto debe hacer un paso"
En un artículo publicado recientemente por Arsalan Sharifnassab del Instituto Openmind, junto con Mohamed Elsayed, A. Rupam Mahmood y Richard Sutton de la Universidad de Alberta, entre otros, se propone una solución que plantea el problema desde otro ángulo: En lugar de especificar cuánto deben moverse los parámetros, especifica directamente cuánto debe cambiar la salida de la función.
Esta idea no surgió de la nada. En 1967, los académicos japoneses Nagumo y Noda, en su artículo "A learning method for system identification", ya propusieron el algoritmo "Normalized Least Mean Squares" (NLMS) en el campo del filtrado adaptativo; en esencia, también utilizaban el cambio deseado en la salida para inferir el tamaño del paso, y no al revés. Solo que ese algoritmo solo era aplicable a escenarios lineales simples.
Los investigadores han extendido esta idea al aprendizaje por refuerzo profundo. Lo llaman "Actualizaciones Intencionales" (Intentional Updates): antes de cada actualización, se define claramente "qué quiero lograr con este paso", y luego se deduce inversamente qué tamaño de paso debería usarse.
Para el aprendizaje de valor (es decir, predecir la recompensa futura), definen la intención como: después de cada actualización, el error de predicción del valor del estado actual debería reducirse en una proporción fija — por ejemplo, un 5%, ni más ni menos. Para el aprendizaje de política (es decir, optimizar la acción de decisión), definen la intención como: la probabilidad de selección de la acción actual solo puede cambiar una cantidad "moderada" en cada paso.
Usando la analogía del coche: esto es como si el conductor decidiera antes de cada operación "quiero que el coche avance 20 cm", y luego calcula automáticamente cuánto debe pisar el acelerador según las condiciones actuales de la carretera (pendiente, carga), en lugar de pisar siempre la misma profundidad y dejar las cosas al azar.
El galardonado con el Premio Turing y su rompecabezas
Uno de los firmantes del artículo es Richard S. Sutton — galardonado con el Premio Turing 2024, ampliamente reconocido como "el padre del aprendizaje por refuerzo moderno".
La posición de Sutton en la comunidad académica es comparable a la de Feynman en física: no solo propuso los dos marcos fundamentales del aprendizaje por refuerzo moderno, el aprendizaje por diferencia temporal (TD learning) y el gradiente de política (policy gradient), sino que también coescribió con Andrew Barto el libro más autorizado en el campo, "Reinforcement Learning: An Introduction" (ahora en su segunda edición, disponible para lectura gratuita en línea). Compartió el Premio Turing 2024 con Barto, cuyo veredicto fue "sentar las bases conceptuales y algorítmicas del aprendizaje por refuerzo".
Tras recibir el premio, Sutton no optó por retirarse, sino que invirtió el premio en el Instituto Openmind que fundó, dedicado a financiar a jóvenes investigadores dispuestos a "explorar problemas fundamentales en un entorno libre de presión comercial". Este nuevo artículo surge precisamente de esta institución sin fines de lucro.
Y el primer autor, Sharifnassab, había publicado recientemente en ICML 2025 el marco MetaOptimize, investigando cómo ajustar automáticamente la tasa de aprendizaje en línea. El enfoque de los dos temas es muy consistente: cómo hacer que el tamaño del paso en sí mismo sea más inteligente.
Detalles del algoritmo: más simple de lo imaginado
La derivación matemática de las "Actualizaciones Intencionales" no es compleja; su fórmula central puede describirse en una frase: el tamaño del paso es igual a la "cantidad de cambio deseada en la salida" dividida por la "influencia real de la dirección del gradiente en la salida".
En el aprendizaje de valor, esta "influencia real" es la norma del vector gradiente (equivalente a medir cuán "empinada" es la región de parámetros actual): en áreas más empinadas el paso es más pequeño, en áreas más planas es más grande, garantizando así que el impacto de cada actualización en la función de valor sea consistente.
En el aprendizaje de política, la "cantidad de cambio deseada" se define como proporcional a la función de ventaja (advantage function): cuánto mejor es la acción actual respecto al promedio, la política se mueve en esa dirección en esa medida — normalizando la magnitud mediante una media móvil (running average) para asegurar que, a largo plazo, la magnitud del cambio de política se mantenga estable en un rango interpretable.
Los investigadores también combinaron esta idea central con dos prácticas de ingeniería: el escalado diagonal al estilo RMSProp (para manejar diferencias de escala entre dimensiones de parámetros) y las trazas de elegibilidad (eligibility traces) (que ayudan a propagar la señal de recompensa hacia pasos de tiempo anteriores).
Finalmente, se formaron tres algoritmos completos: Intentional TD (λ) para predicción de valor, Intentional Q (λ) para control de acciones discretas, y Intentional Policy Gradient para control continuo.



Resultados experimentales: Igualando a SAC sin depender de GPU
El artículo evaluó este conjunto de métodos en múltiples benchmarks estándar, y los resultados son impresionantes.
En tareas de control continuo de MuJoCo (incluyendo robots simulados complejos como Ant, Humanoid, HalfCheetah, etc.), el nuevo método Intentional AC, en configuración de flujo continuo (tamaño de lote = 1, sin búfer de repetición), alcanzó en múltiples ocasiones un rendimiento final cercano o incluso comparable al de SAC — un algoritmo que utiliza un gran búfer de repetición por lotes y es prácticamente el estándar de oro actual para tareas de control continuo. En cuanto a carga computacional, las operaciones de punto flotante requeridas para cada actualización de Intentional AC son aproximadamente 1/140 de las de una actualización de SAC.
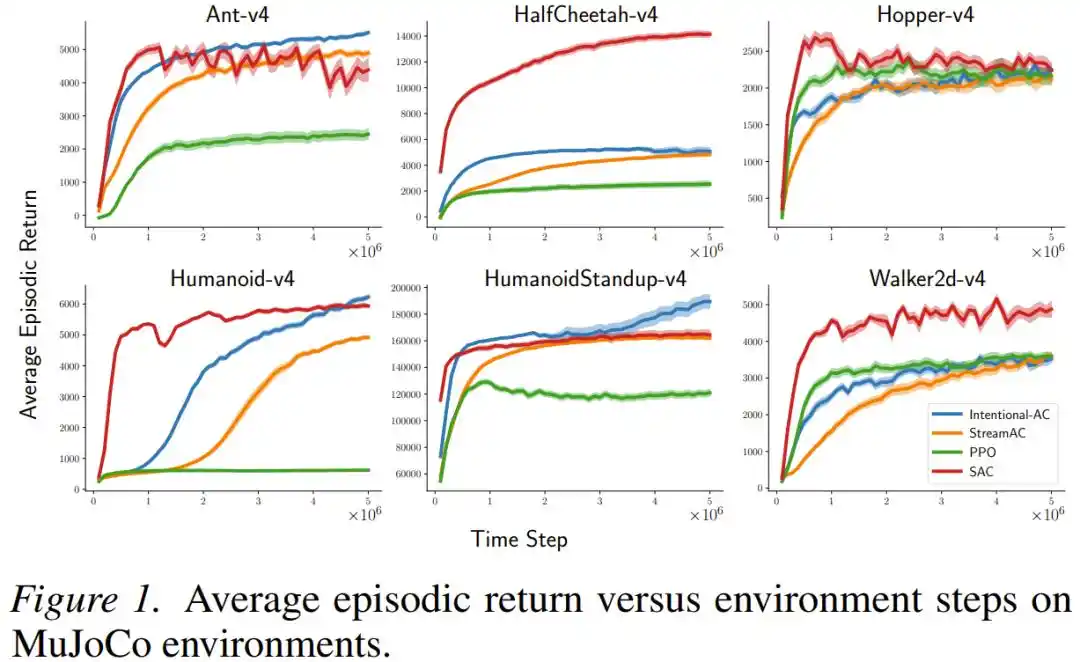
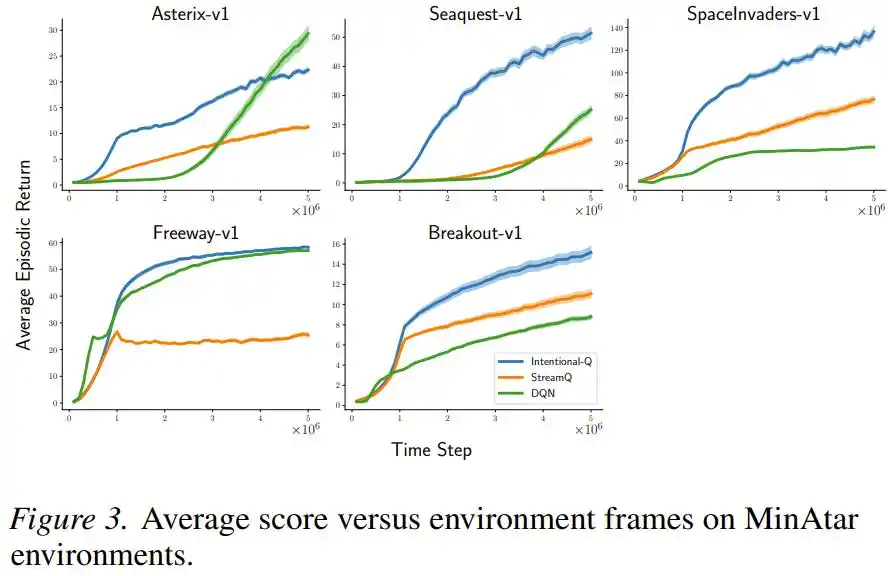
En juegos de acciones discretas de Atari y MinAtar, el rendimiento de Intentional Q-learning fue igualmente comparable al de DQN que utiliza búfer de repetición, y además se ejecutó exitosamente en todas las tareas con el mismo conjunto de hiperparámetros, sin necesidad de ajustarlos individualmente.
Los investigadores también verificaron específicamente si la "intención" realmente se lograba: midieron la relación entre la cantidad de actualización real y la esperada. En una configuración simplificada con las trazas de elegibilidad deshabilitadas, la desviación estándar de esta relación fue de solo 0.016 a 0.029, con el percentil 99 dentro de 1.07; lo que significa que en la gran mayoría de los casos, la actualización realmente logró "hacer exactamente lo que se dijo que haría".
Además, un conjunto de experimentos de ablación mostró que al eliminar la normalización RMSProp o el término σ, el rendimiento disminuyó pero siguió siendo competitivo, siendo este "escalado intencional" el principal contribuyente, y los otros componentes son auxiliares.
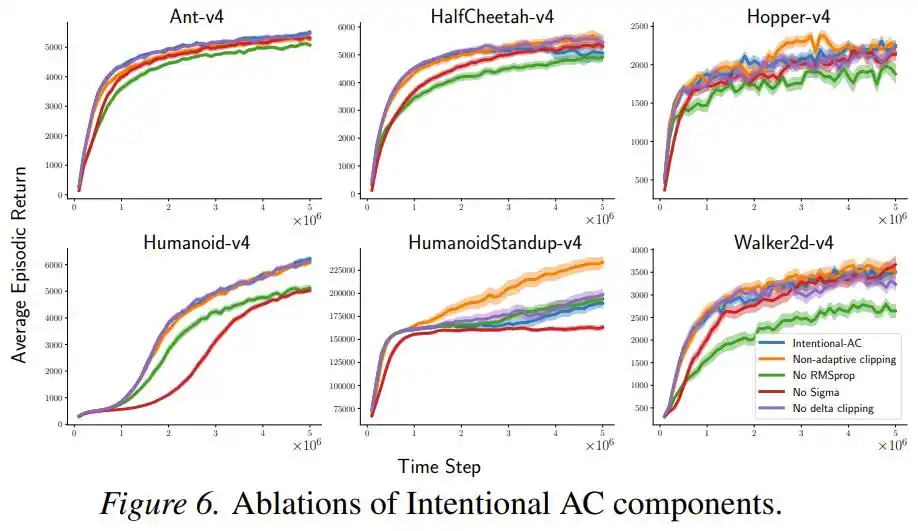
Todavía hay problemas
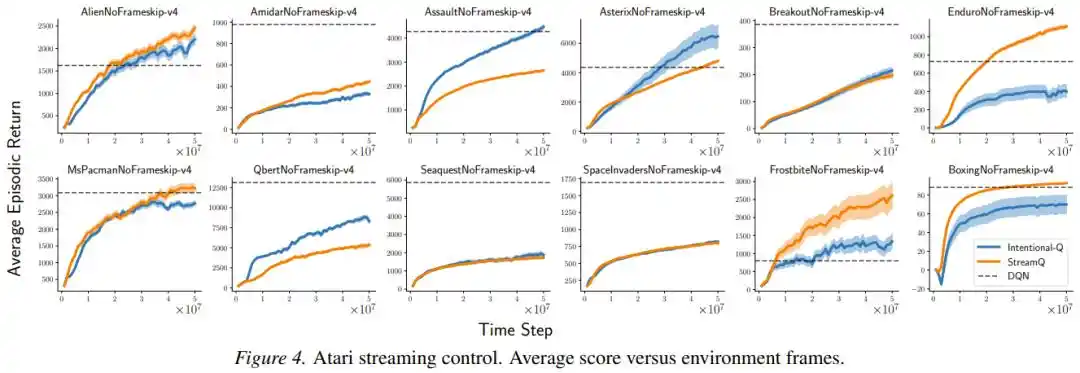
El marco de "Actualizaciones Intencionales" también mostró una ventaja notable en robustez. Cuando los investigadores eliminaron una por una las diversas técnicas de estabilización auxiliares de las que depende el método StreamX (inicialización dispersa, escalado de recompensas, normalización de entrada, LayerNorm), la degradación del rendimiento de Intentional AC fue significativamente menor que la de StreamAC original, lo que indica que el escalado intencional reduce la dependencia de "muletas" externas desde la raíz.
Pero el artículo también reconoce un problema no completamente resuelto: en el aprendizaje de política, el tamaño del paso depende de la acción muestreada actualmente, lo que implícitamente asigna diferentes "pesos" a diferentes acciones, pudiendo cambiar la dirección esperada del gradiente de política. En las tareas Humanoid y HumanoidStandup, midiendo la similitud del coseno de la dirección de actualización esperada, los investigadores encontraron que este sesgo durante las fases clave de aprendizaje era cercano a 0.96 (casi sin efecto); pero en Ant-v4, el grado de alineación cayó a una mediana de 0.63, indicando que el problema no siempre puede ignorarse.
Los autores señalan que futuras investigaciones deberían buscar estrategias de selección del tamaño del paso independientes de la acción, para que la "intención" también se mantenga insesgada en un sentido esperado. Esta es una tarea clara que queda para quienes sigan esta dirección.
Conclusión: Haciendo que la IA aprenda sobre la marcha como los humanos
El paradigma de entrenamiento actual dominante para modelos grandes depende de la digestión por lotes de cantidades masivas de datos: alimentar todo el texto y código de Internet, iterar repetidamente, hasta que finalmente emergen capacidades asombrosas. Este camino ha demostrado ser efectivo, pero es fundamentalmente "aprender primero, usar después": una vez completado el entrenamiento, el modelo se congela y no puede actualizarse continuamente a partir de cada interacción real posterior.
El aprendizaje por refuerzo en flujo continuo persigue un modo de aprendizaje completamente diferente: no depende de una gran repetición, no depende de grandes clusters de GPU, cada experiencia se convierte inmediatamente en una actualización de parámetros, de manera continua, barata y adaptativa. Esto se acerca más a la forma real de aprender de humanos y animales.
Desde el avance inicial de Elsayed y otros en 2024 de "finalmente funciona", hasta el principio de "actualizaciones intencionales" propuesto en este artículo, el aprendizaje por refuerzo profundo en flujo continuo está madurando a una velocidad sorprendente. No reemplazará a los modelos grandes entrenados por lotes, pero para robots que requieren adaptación en línea a largo plazo, dispositivos de borde (edge), y cualquier escenario de aplicación que no pueda soportar grandes búferes de repetición y clusters de GPU, esta vía se está volviendo cada vez más convincente.
El tamaño del paso no es solo un hiperparámetro, es el compromiso de la IA sobre "cuánto quiere hacer" en cada paso. Cuando ese compromiso finalmente se vuelve controlable, el aprendizaje en sí mismo se estabiliza.
Este artículo proviene del WeChat Official Account "机器之心" (ID: almosthuman2014), autor: 关注RL的





