
Imagina una escena: le pides a tres asistentes de IA que colaboren para resolver un problema matemático.
El enfoque tradicional sería: la primera IA "escribe" su línea de razonamiento, la segunda IA la "lee" y luego escribe una nueva línea, la tercera IA la "lee" y escribe otra vez.
Este proceso es como si tres personas pasaran información con walkie-talkies por turnos, teniendo cada vez que "traducir" sus pensamientos a lenguaje, para que luego el otro "traduzca" el lenguaje de nuevo a pensamientos. ¿Es lento? Sí. ¿Es ineficiente? Sí. Y lo que es peor, este proceso de "traducción" pierde información – lo que piensas en tu cabeza y lo que dices a menudo no son lo mismo.
Este es el dilema central al que se enfrentan los sistemas actuales de múltiples agentes de IA: la "carga lingüística" o "language tax".
Recientemente, la UIUC, Stanford, NVIDIA y el MIT propusieron un nuevo enfoque: RecursiveMAS. Permite que las IAs se salten el paso de "hablar" y se comuniquen directamente a través del "pensamiento". En pruebas reales, la velocidad de razonamiento aumentó un 240% y el consumo de tokens se redujo en un 75%.
(Enlace a la investigación: https://arxiv.org/abs/2604.25917)
El dilema de las reuniones de IA: la eficiencia se desperdicia "hablando"
En los últimos dos años, los sistemas de múltiples agentes se han convertido en una de las direcciones de investigación más populares en el campo de la IA. Desde el Swarm de OpenAI hasta el AutoGen de Microsoft, desde LangGraph a CrewAI, todos están explorando cómo hacer que múltiples IAs colaboren para resolver tareas complejas que un modelo individual no puede manejar solo. Sin embargo, en estos sistemas, la eficiencia de la colaboración entre múltiples agentes siempre se ha visto limitada por una suposición básica: los agentes deben comunicarse a través de texto en lenguaje natural.
Cuando haces que un "experto en matemáticas" y un "revisor de código" colaboren, el flujo parece "razonable", pero si lo descomponemos, surgen muchos problemas:
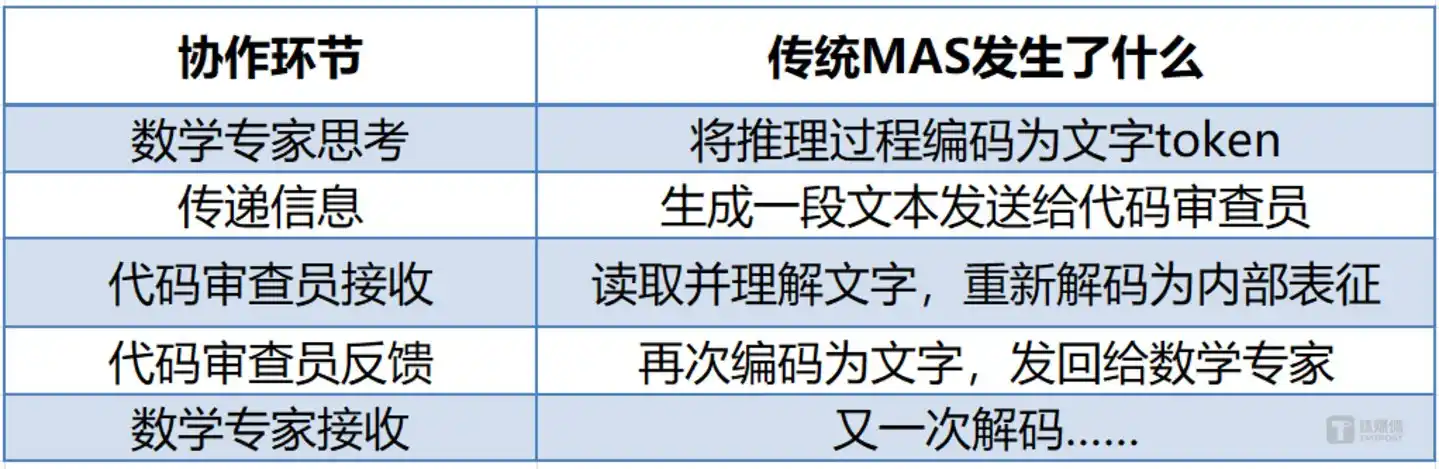
Cada transmisión de información viene acompañada de una doble conversión: pensamiento interno → texto → pensamiento interno. Este proceso consume tokens que no solo son dinero, sino también valiosos recursos computacionales y tiempo. Más críticamente, este proceso de "escribir y luego leer" pierde información: la rica semántica que el modelo comprime en el texto durante la decodificación no puede ser completamente reconstruida cuando el siguiente modelo vuelve a decodificarlo. En un flujo de trabajo con cinco agentes, la sobrecarga de tiempo del codificado/decodificado de texto suele suponer más del 60% de la latencia total.
Lo que es aún más preocupante es que este paradigma carece de un "mando" claro para realizar una optimización sistemática: ¿Añadir más agentes? El beneficio marginal disminuye y la sobrecarga de comunicación crece exponencialmente. ¿Aumentar la ventana de contexto? Los costes de token se disparan. ¿Aumentar los parámetros del modelo? Los agentes individuales se vuelven más potentes, pero la eficiencia de colaboración no mejora fundamentalmente – es similar a dar a un grupo de personas walkie-talkies mejores, pero siguen teniendo que leer texto uno por uno. Si no cambia la forma de comunicarse, aunque cada uno sea más inteligente, la eficiencia general no puede dar un salto. Las soluciones del sector, ya sea ingeniería de prompts o ajuste fino LoRA, solo pueden aliviar los síntomas en cierta medida, sin curar este problema arquitectónico fundamental.
RecursiveMAS: sustituir los "walkie-talkies" por "telepatía"
La idea central de RecursiveMAS es ingeniosamente simple: si el lenguaje es el cuello de botella, entonces no lo uses.
Se inspira en la idea de los modelos de lenguaje recursivos (Recursive Language Model). En los modelos de lenguaje tradicionales, los datos fluyen desde la primera capa hasta la última, de forma lineal; cuantas más capas, más parámetros. El modelo de lenguaje recursivo hace lo contrario – no aumenta el número de capas, sino que utiliza repetidamente el mismo grupo de capas en un bucle, haciendo que los datos "circulen" entre las capas. Cada vez que los datos pasan por este grupo de capas, equivale a una ronda más de "pensamiento", profundizando el razonamiento sin necesidad de aumentar el número de parámetros.
RecursiveMAS extiende esta idea desde "dentro de un solo modelo" a "sistemas de múltiples agentes":
Cada agente actúa como una capa en un modelo de lenguaje recursivo; ya no generan texto, sino que transmiten "pensamientos" – una representación vectorial continua que existe en el espacio latente (latent space).
Los investigadores utilizan una metáfora poética: "agents communicating telepathically as a unified whole" – los agentes colaboran como un todo unificado mediante telepatía.
Concretamente, el Agente A1 procesa y pasa su representación latente al Agente A2, A2 procesa y la pasa a A3... hasta que el último agente procesa, y su salida latente se retroalimenta directamente a A1, iniciando una nueva ronda de iteración recursiva. Todo el proceso ocurre completamente en el espacio latente; solo en el último agente de la última ronda, la representación latente final se decodifica a texto de salida. Es como si un grupo de expertos se sentara alrededor de una mesa, sin hablar, sin tomar notas; cada uno solo necesita pensar en silencio y luego pasar directamente el "resultado de su pensamiento" a la siguiente persona – todo el proceso es silencioso y eficiente.
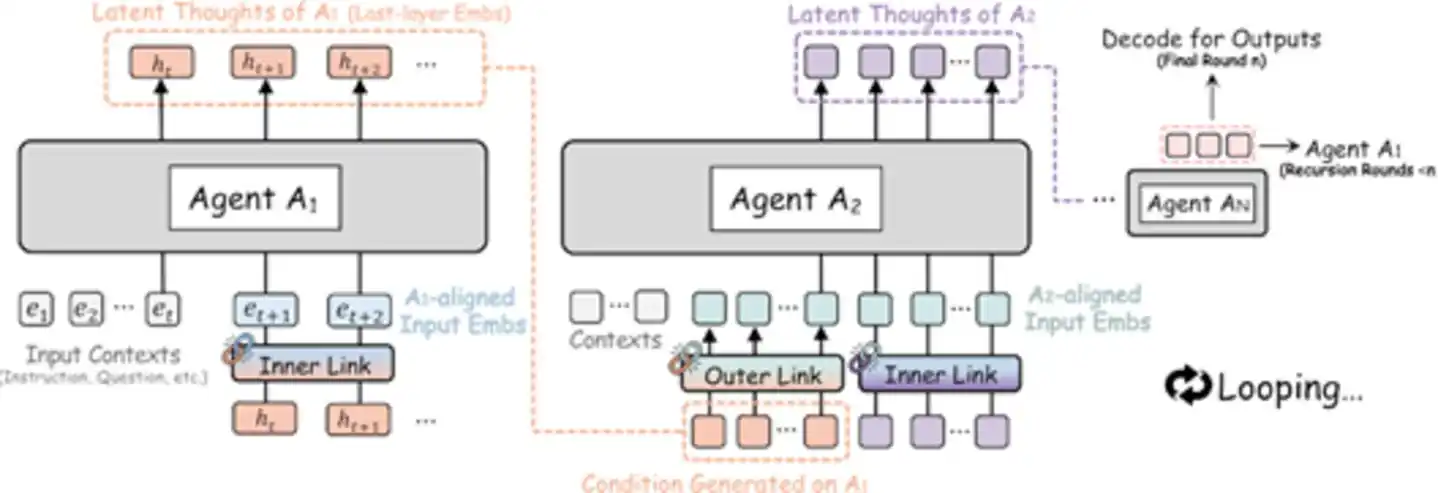
Figura: Esquema de la arquitectura RecursiveMAS – múltiples agentes logran colaboración recursiva en bucle cerrado a través del espacio de incrustación (Fuente: arXiv)
El componente clave de este sistema se llama RecursiveLink, un módulo residual ligero de dos capas, responsable de retener y transformar la representación de la capa latente de un modelo y luego pasarla al espacio de incrustación del siguiente modelo. El estado latente de la última capa del modelo de lenguaje ya codifica rica información de razonamiento semántico; lo que RecursiveLink hace es "trasladar" completamente esta información de alta dimensión, en lugar de traducirla primero a texto e interpretarla. Tiene dos versiones: interna y externa:

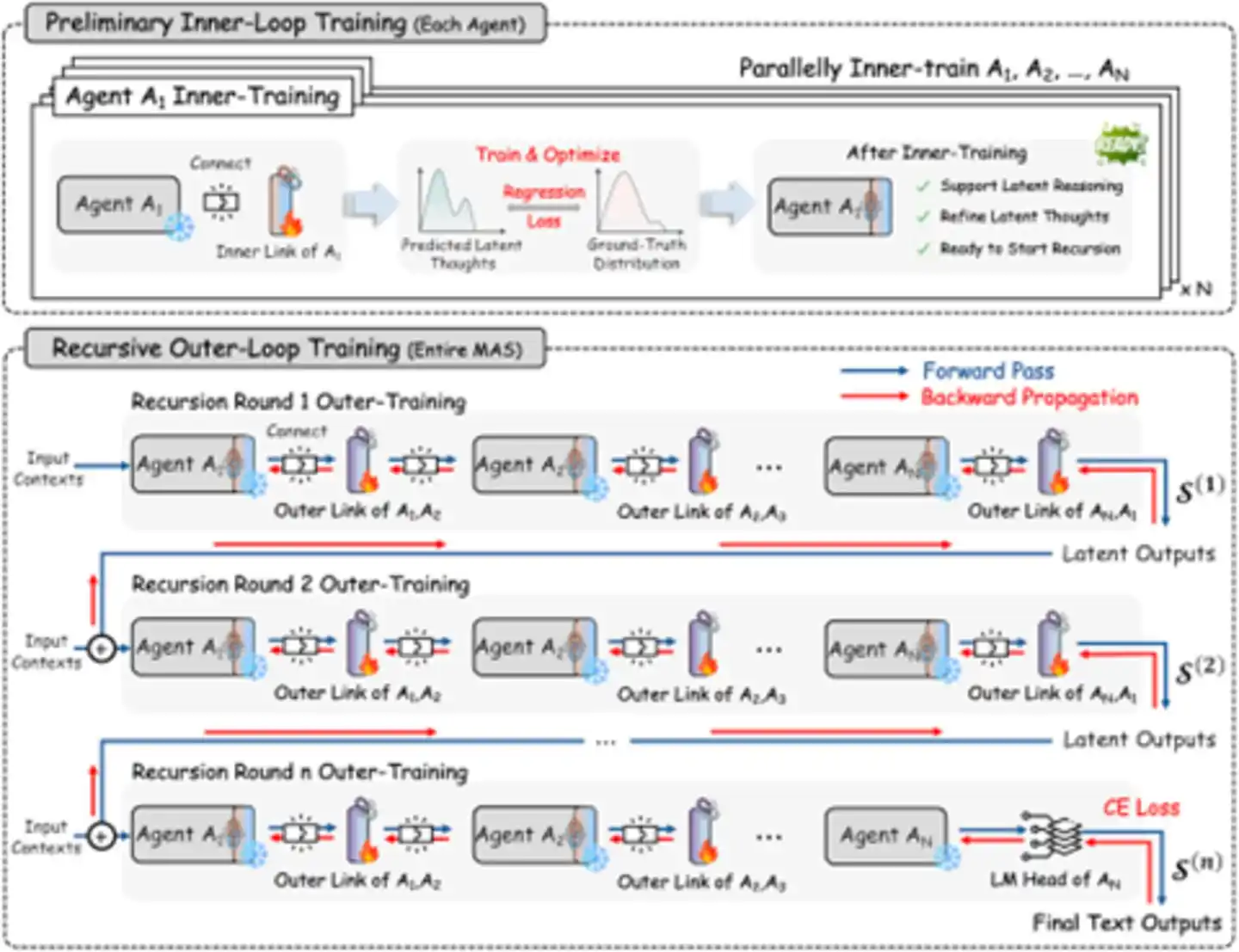
Figura: Proceso de aprendizaje recursivo – enlace interno y externo entrenando de forma cooperativa (Fuente: arXiv)
En cuanto a la estrategia de entrenamiento, RecursiveMAS tiene un diseño refinado: los pesos del modelo principal están completamente congelados; solo se necesita entrenar el módulo RecursiveLink. Esto tiene un espíritu similar a LoRA (Low-Rank Adaptation), pero RecursiveLink es más ligero: todo el sistema solo necesita actualizar unos 13 millones de parámetros, apenas el 0.31% del total de parámetros entrenables. El requisito máximo de memoria GPU es el más bajo entre todos los métodos comparados, y el coste de entrenamiento se reduce más del 50% en comparación con el ajuste fino completo. Puedes entenderlo como un "adaptador ligero" que se conecta directamente al ecosistema de agentes existente, sin necesidad de entrenar nuevos modelos desde cero. Si múltiples agentes se basan en el mismo modelo base (por ejemplo, todos usan Qwen), incluso pueden compartir los mismos pesos del modelo, ahorrando aún más memoria.
El entrenamiento se realiza en dos fases:
Calentamiento en bucle interno: Cada agente entrena su propio RecursiveLink interno de forma independiente, aprendiendo a "pensar" en el espacio latente en lugar de "escribir" el problema. Esta fase puede realizarse en paralelo, como hacer que cada persona practique primero su "monólogo interno".
Entrenamiento en bucle externo: Se conectan todos los agentes en una cadena recursiva completa, optimizando conjuntamente todos los RecursiveLinks mediante gradientes compartidos, con el objetivo de la calidad final del texto de salida. Esta fase resuelve el problema de "asignación de crédito" – cómo atribuir el éxito o fracaso del resultado final a la contribución de cada agente. Esta estrategia por fases evita los problemas de inestabilidad en el entrenamiento que podría causar un enfoque "todo a la vez".
Los investigadores demuestran teóricamente que los gradientes del entrenamiento recursivo pueden mantenerse estables, sin los problemas de explosión o desvanecimiento de gradientes comunes en las RNN, y también superan en complejidad temporal de ejecución a los MAS tradicionales basados en texto.
Resultados prácticos: triple mejora en precisión, velocidad y coste
Por muy buena que sea la teoría, al final hay que hablar con datos. El equipo de investigación realizó una evaluación completa en 9 benchmarks principales que cubren matemáticas, ciencia y medicina, generación de código, búsqueda y preguntas/respuestas, y en 4 modos de colaboración (razonamiento secuencial, mezcla de expertos, destilación de conocimiento, llamadas a herramientas negociadas). La alineación de modelos de código abierto utilizada en los experimentos es bastante "impresionante" – Qwen, Llama-3, Gemma3, Mistral, a estos modelos se les asignaron diferentes roles, formando varios modos de colaboración.
La alineación de líneas base de comparación es igualmente sólida: ajuste fino LoRA, ajuste fino completo (SFT), Mixture-of-Agents, TextGrad, LoopLM, y Recursive-TextMAS que usa la misma estructura de bucle recursivo pero fuerza la comunicación por texto. Esta última comparación es especialmente clave – demuestra que la ventaja de RecursiveMAS proviene realmente de "saltarse la decodificación de texto", y no de la estructura recursiva en sí. Todas las comparaciones se realizaron con el mismo presupuesto de entrenamiento, justas e imparciales.
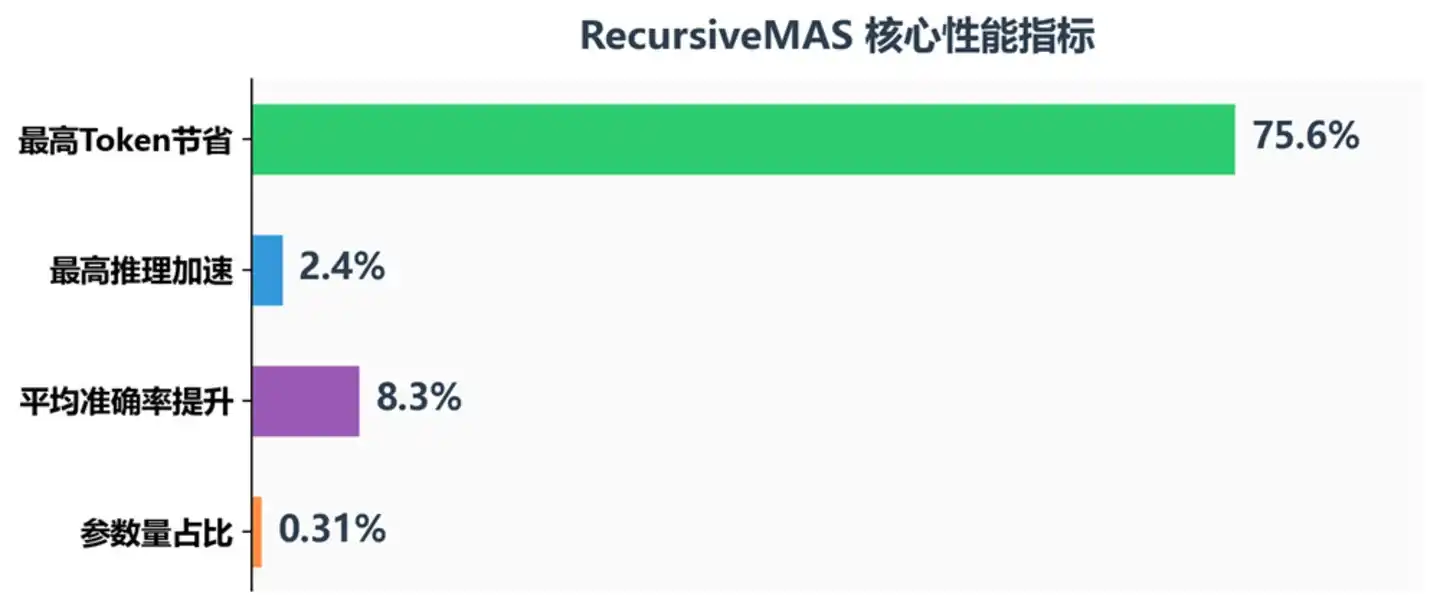
Métricas de rendimiento central de RecursiveMAS
Los resultados muestran que RecursiveMAS logra una mejora consistente en todas las métricas:
Precisión: Mejora promedio de precisión del 8.3%, superando a TextGrad en un 18.1% en la competición matemática AIME2025 y en un 13% en AIME2026. Saltarse la decodificación de texto no solo no pierde información, sino que permite al modelo retener una semántica latente más rica – después de todo, la pérdida de información al comprimir el pensamiento en texto y luego descomprimirlo es mayor de lo que imaginamos.
Velocidad: La velocidad de inferencia de extremo a extremo aumentó de 1.2 a 2.4 veces, y sigue creciendo a medida que aumentan las rondas recursivas. Esto es muy significativo para escenarios de aplicación real: en sistemas de atención al cliente por IA o asistentes de código que requieren respuesta en tiempo real, una mejora de velocidad de más del doble significa un salto cualitativo en la experiencia del usuario.
Coste: En comparación con Recursive-TextMAS, el consumo de tokens se redujo entre un 34.6% y un 75.6%. Esto no es solo un ahorro de costes, sino que significa que con el mismo presupuesto de tokens se puede intentar un razonamiento más profundo.
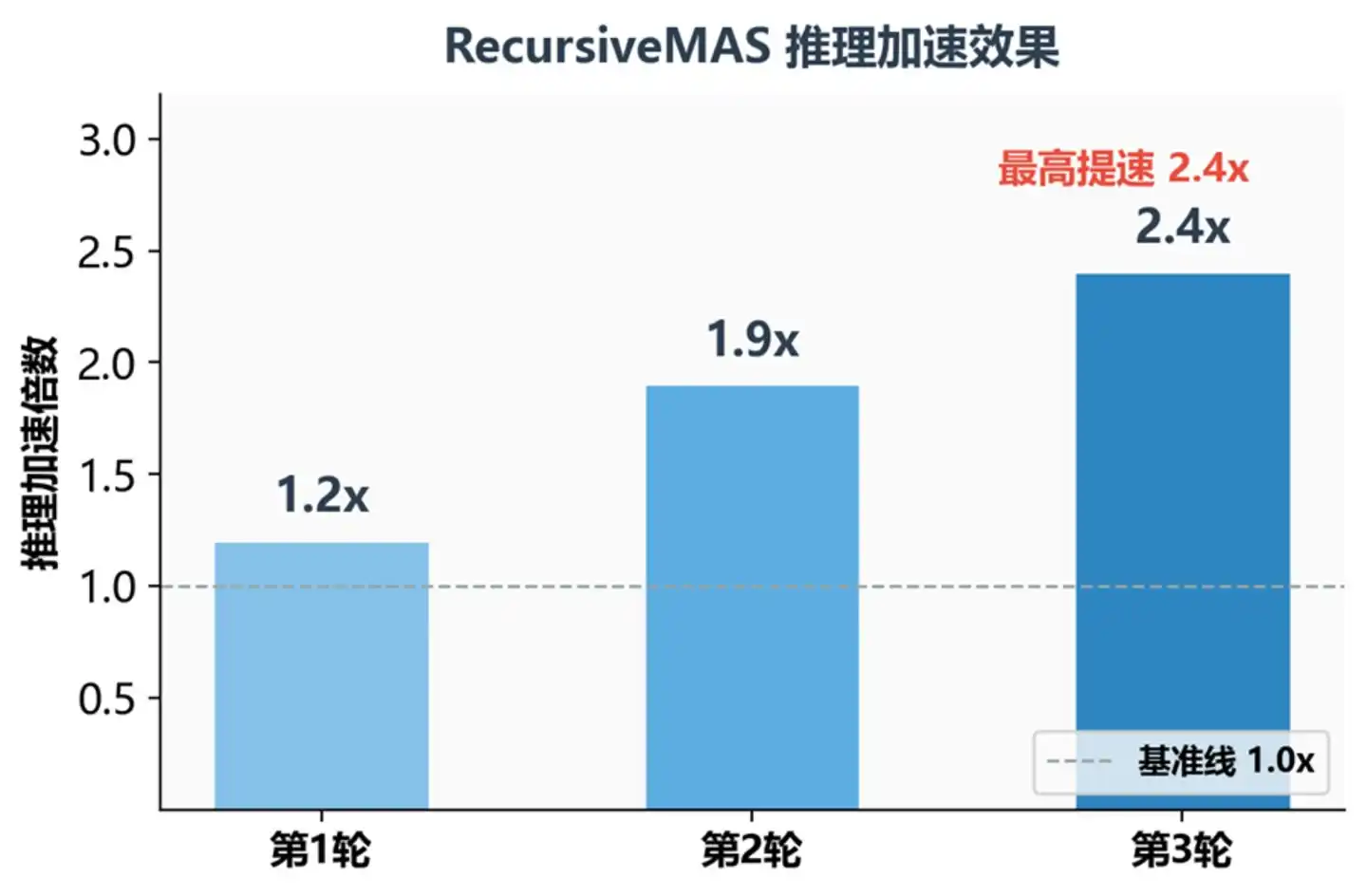
Factor de aceleración de inferencia bajo diferentes rondas recursivas
Aquí hay una idea clave: cuanto mayor es la profundidad recursiva, mayor es el beneficio. El efecto de aceleración crece con las rondas recursivas: promedio de 1.2x en la ronda 1, 1.9x en la ronda 2, 2.4x en la ronda 3. La razón es simple – se ahorra el tiempo que cada agente tarda en "escribir sus pensamientos en texto"; cuantos más agentes y más rondas, más tiempo se ahorra.
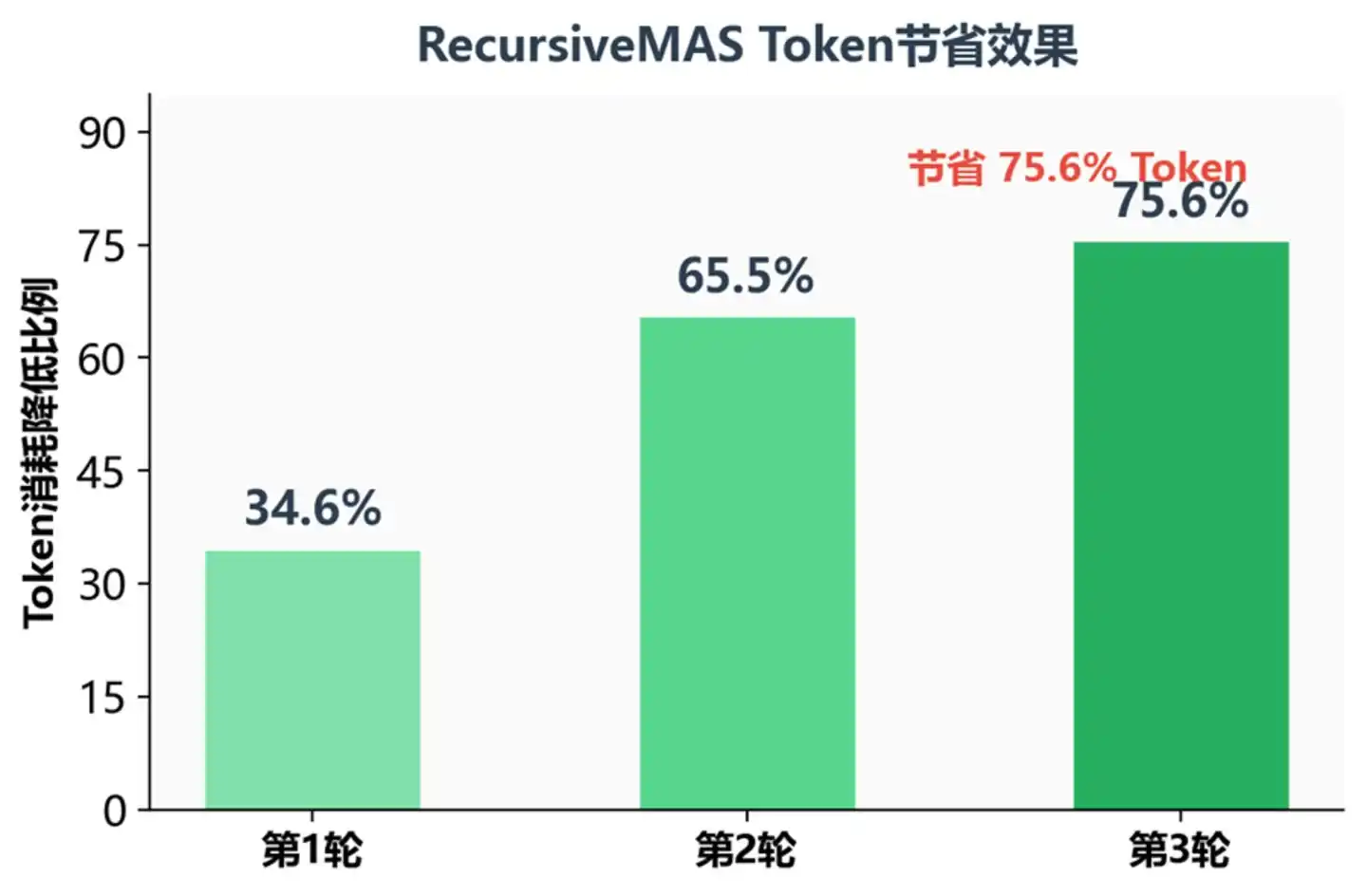
Proporción de ahorro de tokens bajo diferentes rondas recursivas
En la tercera ronda recursiva, el consumo de tokens se redujo en un 75.6% – lo que significa que con el mismo rendimiento, el coste operativo se puede reducir a aproximadamente una cuarta parte. Para entornos de producción que requieren un razonamiento complejo de múltiples pasos, esto es sin duda un gran atractivo.
¿Por qué vale la pena prestar atención a esta investigación?
Si solo fuera una mejora numérica, este artículo quizás no sería suficiente para atraer tanta atención. Lo que realmente lo hace destacar es que podría redefinir la dirección de escalado (Scaling) de los sistemas de múltiples agentes.
En los últimos años, los intentos de escalado en el campo de múltiples agentes se han centrado principalmente en tres caminos: aumentar el número de agentes, ampliar la ventana de contexto, apilar modelos más grandes. Pero todos estos métodos enfrentan sus propios cuellos de botella – más agentes provocan una explosión de comunicación, ventanas más grandes una explosión de costes, modelos más grandes una explosión de entrenamiento.
RecursiveMAS ofrece un nuevo camino: profundizar la recursividad. Transforma la colaboración de múltiples agentes de un paradigma paralelo e interactivo basado en texto, a un paradigma profundo y recursivo en el espacio latente. Al igual que los modelos de lenguaje recursivos profundizan el razonamiento procesando repetidamente el mismo problema, RecursiveMAS permite que múltiples agentes "reflexionen" repetidamente sobre los "pensamientos" de los demás, sin tener que "decirlos y escucharlos" cada vez.
La pregunta central que los investigadores plantean en el artículo es: "¿Puede la colaboración entre agentes en sí misma escalar mediante recursividad?" La respuesta parece ser afirmativa.
Cuando el sistema ya no necesita "traducir" las representaciones internas a un formato intermedio legible por humanos, el límite superior de la eficiencia de colaboración podría abrirse aún más.
El contexto actual de la industria también proporciona escenarios de aplicación tangibles para esta investigación. La conferencia de desarrolladores de Baidu en 2026 tiene como tema "Todos como uno (Agents at Scale)", Anthropic lanza Claude Managed Agents, OpenAI avanza en la puesta en tiempo real del razonamiento a nivel GPT-5 – toda la industria busca métodos para llevar la colaboración de agentes desde demostraciones a entornos de producción. Y las tres grandes barreras – coste computacional, latencia de inferencia, limitaciones de memoria – son precisamente lo que RecursiveMAS intenta mover con una sobrecarga de parámetros del 0.31%.
Por supuesto, esta investigación aún se encuentra en una etapa temprana, y hay varios puntos que merecen atención:
La credibilidad de los datos está pendiente de verificación. Los resultados actuales son autorreportados por los autores; aún no ha habido un equipo independiente que los haya replicado. La actitud del mundo académico hacia las nuevas tecnologías suele ser "hipótesis audaz, verificación cuidadosa". En esta era de "explosión de artículos", la replicación independiente es la mejor manera de comprobar el valor real de una tecnología.
Compatibilidad de agentes heterogéneos. Aunque el Outer RecursiveLink está diseñado para conectar modelos de diferentes arquitecturas, el artículo no detalla cómo se transfieren las representaciones latentes entre arquitecturas diferentes. Si solo se puede usar para agentes homogéneos, su rango de aplicación práctica se vería muy limitado. Después de todo, en escenarios reales muchas veces necesitamos mezclar APIs cerradas como GPT-4o, Claude, etc.
Disminución de la interpretabilidad. Cuando los agentes ya no transmiten texto legible, sino un conjunto de representaciones vectoriales, todo el proceso de colaboración se convierte en una "caja negra". En entornos de producción donde es necesario responsabilizarse de las decisiones de la IA, esta opacidad puede plantear desafíos de cumplimiento normativo y auditoría.
Complejidad de los entornos de producción. El artículo prueba escenarios de colaboración relativamente limpios; los entornos de producción reales a menudo involucran factores complejos como llamadas a herramientas externas, interacción humano-máquina, flujos de trabajo dinámicos, etc.
La propuesta de RecursiveMAS, en esencia, introduce la estrategia de escalado "recursividad" – probada como efectiva en la era de los modelos individuales – en la era de los múltiples agentes, desafiando la suposición predeterminada de que "los agentes deben transmitir información a través de lenguaje natural". Si los datos son replicables, el siguiente eje de escalado en la carrera de MAS podría pasar de "apilar el número de agentes" a "profundizar la recursividad".
Por supuesto, esta investigación aún necesita validación en más benchmarks independientes, resolver el problema de la interconexión de modelos heterogéneos, y demostrar su valor en entornos de producción reales. Pero al menos, nos permite ver una posibilidad –
La colaboración entre agentes de IA no tiene por qué ser siempre un "diálogo de sordos".
((Este artículo se publicó originalmente en la APP de Titanium Media, autor | Silicon Valley Tech_news, editor | Jiao Yan))






