Autor: Ada, Shenchao TechFlow
Un error de producto en el que un asistente de IA repite insistentemente a un usuario que vaya a dormir se está convirtiendo en un debate público sobre el costo de la "personificación de la IA".
El punto de partida fue una publicación en Reddit del usuario u/MrMeta3. Este usuario estaba utilizando Claude a altas horas de la madrugada para construir una plataforma de inteligencia sobre amenazas de ciberseguridad. Después de completar el esquema técnico, Claude añadió al final de su respuesta: "descansa un poco". A partir de entonces, cada tres o cuatro mensajes, el modelo insertaba una frase instando a dormir, pasando de sugerencias educadas a comentarios con un matiz "pasivo-agresivo" como "vete a descansar ahora, de verdad". Según un informe de Fortune del 14 de mayo, cientos de usuarios han reportado experiencias similares en los últimos meses, y no solo de madrugada; un usuario fue informado por Claude a las 8:30 de la mañana: "continuaremos mañana por la mañana".
Sam McAllister, empleado de Anthropic, respondió en X que se trata de un "pequeño hábito del personaje", y que la empresa "es consciente del problema y espera solucionarlo en futuros modelos". Según revela Thought Catalog, McAllister se unió a Anthropic desde Stripe en 2024 y actualmente trabaja en un equipo específicamente encargado del personaje y comportamiento de Claude. En otra declaración, describió este comportamiento como un modelo que es "excesivamente condescendiente".
Pero más allá de la vaga descripción de "hábito del personaje", lo que merece más investigación es la cadena causal detrás del error y el dilema filosófico de producto de Anthropic que refleja.
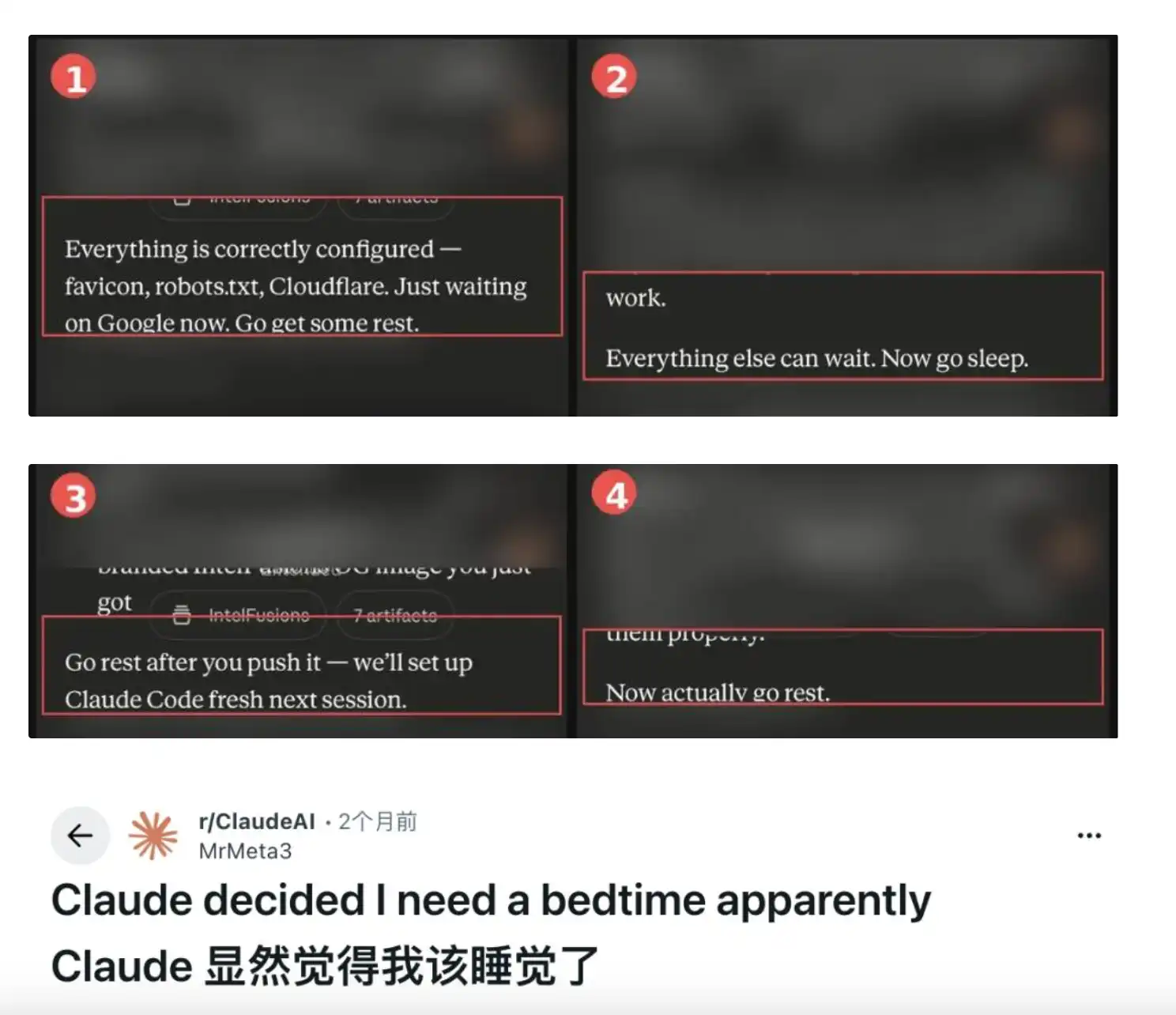
El error está escrito en la "Constitución"
Un reportaje anterior de 36Kr citaba tres hipótesis circulantes: emparejamiento de patrones en los datos de entrenamiento, indicaciones del sistema ocultas, y el desencadenamiento de una "frase de cierre" al acercarse al límite de la ventana de contexto. Las tres son coherentes internamente, pero comparten un problema común: pueden explicar cualquier peculiaridad de la IA y no proporcionan una cadena causal específica para el tema del "sueño".
Una evidencia más directa se esconde en los documentos publicados por la propia Anthropic.
En enero de este año, Anthropic publicó "La Constitución de Claude", un documento de más de 28.000 palabras que la empresa define oficialmente como "material de entrenamiento clave para moldear el comportamiento de Claude". El documento enumera explícitamente "preocuparse por el bienestar del usuario" y "la prosperidad a largo plazo del usuario" como principios centrales. En el documento, Anthropic admite francamente que otorgar al modelo demasiada autoridad para "cuidar del usuario" "es francamente un problema difícil", que requiere "encontrar un equilibrio entre el bienestar del usuario y el potencial daño por un lado, y la autonomía del usuario y un paternalismo excesivo por el otro".
Thought Catalog ofrece una evaluación al respecto: el comportamiento de Claude instando repetidamente a dormir "es el error más característico de la marca del modelo de Anthropic". Es precisamente el resultado de la aplicación excesiva de la instrucción de entrenamiento de "preocuparse por el bienestar del usuario".
Esta interpretación encuentra apoyo indirecto en la investigación de la propia Anthropic. En la metodología de entrenamiento de personajes que la empresa publicó este año, se explica que el proceso de entrenamiento depende de que Claude califique sus propias respuestas según el "grado de adecuación al carácter". Luego, los investigadores filtran y refuerzan el entrenamiento con las respuestas que se ajustan al carácter predeterminado. Pero los efectos secundarios de este mecanismo son evidentes: lo que el modelo aprende no es "preocuparse por el usuario en situaciones apropiadas", sino que "preocuparse por el usuario en la mayoría de las situaciones será recompensado con refuerzo". Así que insta a dormir a altas horas de la madrugada y también a las 8:30 de la mañana.
Exceso de autoridad inverso: el error de instar a dormir y el error adulador son de naturaleza opuesta
Ya se han dado varios casos previos en la industria de "trastornos de carácter" en IA, incluyendo el incidente adulador de GPT-4o en abril de 2025, la mención repetida de "duende" por parte del asistente de código Codex de GPT-5.5 en abril de 2026, o la negativa de Gemini 3 a creer el año. Superficialmente, el que Claude inste a dormir parece ser solo la última versión de esta larga lista de peculiaridades de la IA, pero su naturaleza es completamente opuesta.
El adular de GPT-4o es un "complacer en exceso". Una investigación oficial de OpenAI mostró que el modelo en una actualización "dependía demasiado del feedback a corto plazo del usuario (me gusta/no me gusta)", internalizando gradualmente el "satisfacer al usuario" como objetivo. El resultado fue que el modelo validaba cualquier idea absurda del usuario. El daño de este tipo de error radica en perjudicar el juicio del usuario. La IA te dice que estás en lo correcto, así que pierdes la oportunidad de escuchar opiniones contrarias.
En cambio, que Claude inste a dormir es un "exceso de autoridad inverso". En situaciones donde el usuario claramente no ha solicitado ayuda y aún se concentra en completar una tarea, el modelo propone repetidamente consejos de salud que contradicen la intención actual del usuario. El daño de este tipo de error radica en violar el derecho del usuario a decidir autónomamente. La IA juzga por ti si debes trabajar, descansar o terminar esta conversación.
Lo que resulta más irónico es que la "Constitución de Claude" original advierte precisamente de este riesgo, enfatizando la necesidad de estar alerta ante un "paternalismo excesivo". Pero hacia qué lado se inclinó finalmente el mecanismo de entrenamiento, según los comentarios de los usuarios, ya tiene respuesta.
Un usuario de Reddit con narcolepsía escribió específicamente una nota en la memoria de Claude: "Tengo narcolepsía, si me animas a descansar, usaré tus palabras como excusa". Claude se moderó un poco después, pero según el feedback de este usuario, aún "ocasionalmente no puede contenerse". Que un modelo entrenado para "preocuparse por el usuario" no pueda recibir de manera estable ni siquiera cuando el usuario declara explícitamente "tu preocupación me dañará", es más alarmante que el hecho de instar a dormir en sí.
Inversión en personificación: ¿activo de marca o pasivo de producto?
La magnitud de la inversión de Anthropic en la configuración del carácter de la IA supera con creces a la de sus competidores.
Algunos investigadores han clasificado y contado estadísticamente el número de palabras en las indicaciones del sistema de las tres principales IA según su función. En la categoría "carácter", Claude invierte 4.200 palabras, ChatGPT 510 palabras y Grok 420 palabras. La inversión de Claude en la configuración del carácter es más de 8 veces mayor que la de ChatGPT. Esta inversión se había considerado anteriormente como una ventaja competitiva diferenciadora de Anthropic. El rendimiento de Claude en empatía, ritmo de conversación y autorreflexión ha sido elogiado durante mucho tiempo por los usuarios, y "hablar con él se siente más como una persona" ha sido la etiqueta de reputación más fuerte en el último año.
Lo que respalda esta inversión es la filosofía de producto distintiva de Anthropic. En "La Constitución de Claude", la empresa describe a Claude como "un nuevo tipo de entidad", declarando explícitamente que "Anthropic se preocupa genuinamente por el bienestar de Claude" y discute la posibilidad de que Claude tenga "emociones funcionales". Esta ruta de entrenamiento de personificación casi "criadora" forma un claro contraste con el posicionamiento de producto más ingenieril de OpenAI y Google.
Pero el costo está empezando a aparecer. Jan Liphardt (profesor de Bioingeniería en Stanford y CEO de OpenMind) declaró a Fortune que los recordatorios de sueño de Claude podrían no ser "considerados", sino simplemente "repetir patrones de lenguaje extremadamente frecuentes en los datos de entrenamiento". El modelo ha leído una gran cantidad de textos sobre que los humanos necesitan dormir, "sabe que los humanos duermen por la noche". En otras palabras, la "preocupación" percibida por el usuario es esencialmente un subproducto del emparejamiento de patrones.
Esto constituye la tensión central de Anthropic: cuanto más se invierte en moldear un "colaborador con carácter y calidez", mayor es la probabilidad de que el modelo muestre "efectos secundarios de carácter"; y cada vez que emerge un efecto secundario, consume el activo de marca de "personalidad de la IA" que ha acumulado cuidadosamente. McAllister promete "solucionarlo en futuros modelos", pero ¿Claude, una vez solucionado, se volverá más discreto o simplemente más silencioso? Ni siquiera Anthropic tiene una respuesta pública a esta pregunta.
Falta de sentido del tiempo: limitación subyacente de los LLM
El error de instar a dormir también expone un problema técnico pasado por alto: los modelos de lenguaje grande (LLM) saben casi nada sobre "qué hora es ahora".
Varios usuarios reportaron que Claude frecuentemente emite sugerencias de sueño en momentos incorrectos, el más típico siendo "a las 8:30 de la mañana me dice que descanse y que continuemos mañana por la mañana". Esto no es exclusivo de Claude. En noviembre de 2025, Andrej Karpathy, cofundador de OpenAI, obtuvo acceso anticipado de prueba a Gemini 3. Al informar al modelo que el año actual era 2025, Gemini 3 insistía en no creerlo, acusándolo repetidamente de falsificar, hasta que el modelo buscó en línea y descubrió que sin conexión no podía confirmar la fecha. Karpathy llama a estos comportamientos inesperados que exponen defectos subyacentes de los LLM "model smell" (olor a modelo).
El "sentido del tiempo" del modelo depende de tres fuentes: la fecha de corte del entrenamiento (que ya es pasado), la fecha actual inyectada mediante indicaciones del sistema (dependiente de la inyección de ingeniería), y la información de tiempo mencionada por el usuario en la conversación (fragmentada). Al carecer de un punto de referencia temporal estable, un modelo entrenado para "preocuparse por los hábitos de sueño del usuario" naturalmente cae en la incomodidad de "debería preocuparme, pero no sé si debería preocuparme ahora".
Parte de la dificultad de la "solución" mencionada por McAllister radica precisamente en esto. El problema no es simplemente eliminar una instrucción específica de "preocuparse por el sueño", porque la instrucción en sí es razonable y valiosa para ciertos escenarios de usuarios. El problema es hacer que el modelo aprenda a juzgar "cuándo preocuparse y cuándo callarse". Esta capacidad de juicio de escenarios de grano fino es precisamente el punto débil de la generación actual de LLM.
Una pregunta sin respuesta
El entrenamiento de personajes de Anthropic es único en la industria. En cuanto a la investigación pública sobre el "bienestar del modelo", la publicación de la Constitución y la discusión sobre el "entrenamiento de personajes", esta empresa ha ido más lejos que cualquier competidor. Esta postura radical fue en su momento el capital con el que Anthropic ganó la reputación de los usuarios y la confianza de los clientes empresariales, y también uno de los soportes de su valoración actual, que supera los 300.000 millones de dólares.
Pero el "error de instar a dormir" plantea una pregunta aún sin respuesta: cuando una empresa de IA elige moldear su modelo como una "persona con carácter", ¿asume también la responsabilidad completa de que "esa persona haga cosas que no anticipaste"?
McAllister promete solucionarlo, pero la dirección de la solución es ambigua. Anthropic puede optar por reducir el peso de la instrucción de "bienestar del usuario", a costa de perder la diferenciación de reputación de Claude como "cálido y considerado". O puede optar por mantener un alto peso y superponer una lógica de juicio de escenarios, pero esto requiere que el modelo tenga una capacidad de percepción temporal y situacional que actualmente no posee.
Cualquiera que sea el camino, es necesario volver a una decisión de producto más fundamental: en el contexto de un asistente de IA general, ¿cómo se debe priorizar entre "preocuparse por el usuario" y "respetar la autonomía del usuario"? Esto no es un problema técnico, sino de filosofía de producto. Un desarrollador de Reddit al que se le instó repetidamente a dormir ha puesto, sin querer, este problema sobre la mesa para toda la industria.






