Este año, los tres gigantes estadounidenses de la IA han estado añadiendo algunas etiquetas "de ciencia ficción" a sus productos de modelos.
OpenAI dice que ChatGPT ha aprendido a "soñar"; Anthropic quiere equipar a Claude con una "Wiki personal" integrada; y Google afirma haber dotado a Gemini de una "memoria de diez años incorporada de forma nativa".
Tres enfoques que, aunque parecen no tener mucha relación, compiten por lo mismo: el Contexto.
Al principio, el Contexto era solo un parámetro técnico poco relevante que medía cuántos caracteres podía leer el modelo de una vez. Hoy, su significado se está ampliando: es un activo del usuario, un permiso de herramienta, el estado en tiempo real del progreso de una tarea y, sobre todo, cuánto te conoce realmente la IA.
Según las estadísticas del «Instituto de Investigación Deep Flow», desde principios de año, OpenAI, Anthropic y Google han lanzado más de 40 importantes actualizaciones de productos y funciones relacionadas con el Contexto, lo que significa que, en promedio, cada tres o cuatro días se presenta una nueva capacidad al mercado.
Desde ventanas de contexto largo hasta Memory entre sesiones, pasando por capacidades de operación en navegadores, escritorios e interfaces gráficas, casi todos los cambios más importantes en los productos de IA de los últimos dos años han girado en torno al Contexto.
Una guerra por el "Contexto" ya ha comenzado, y esto está reconfigurando silenciosamente el foso competitivo de la era de la IA.
1. Tres saltos en los límites del Contexto: desde ventanas largas hasta entornos reales
La competencia más temprana por el Contexto se desarrolló en la "longitud del texto".
En la era de los Chatbots, el Contexto significaba principalmente cuánta información podía procesar el modelo de una vez. Una ventana más larga permitía al modelo manejar tesis, repositorios de código, incluso documentos completos de proyectos. Así, OpenAI, Anthropic y Google iniciaron una carrera armamentística por la ventana de contexto.
En mayo de 2023, Anthropic llevó la ventana de contexto de Claude de 9K a 100K (equivalente a unas 75.000 palabras), permitiendo por primera vez "subir un libro entero". En noviembre de 2023, OpenAI siguió con los 128K de GPT-4 Turbo. Tres meses después, Google llevó la ventana de Gemini 1.5 Pro al nivel del millón.
En menos de un año, el Contexto pasó de decenas de miles a millones de tokens.
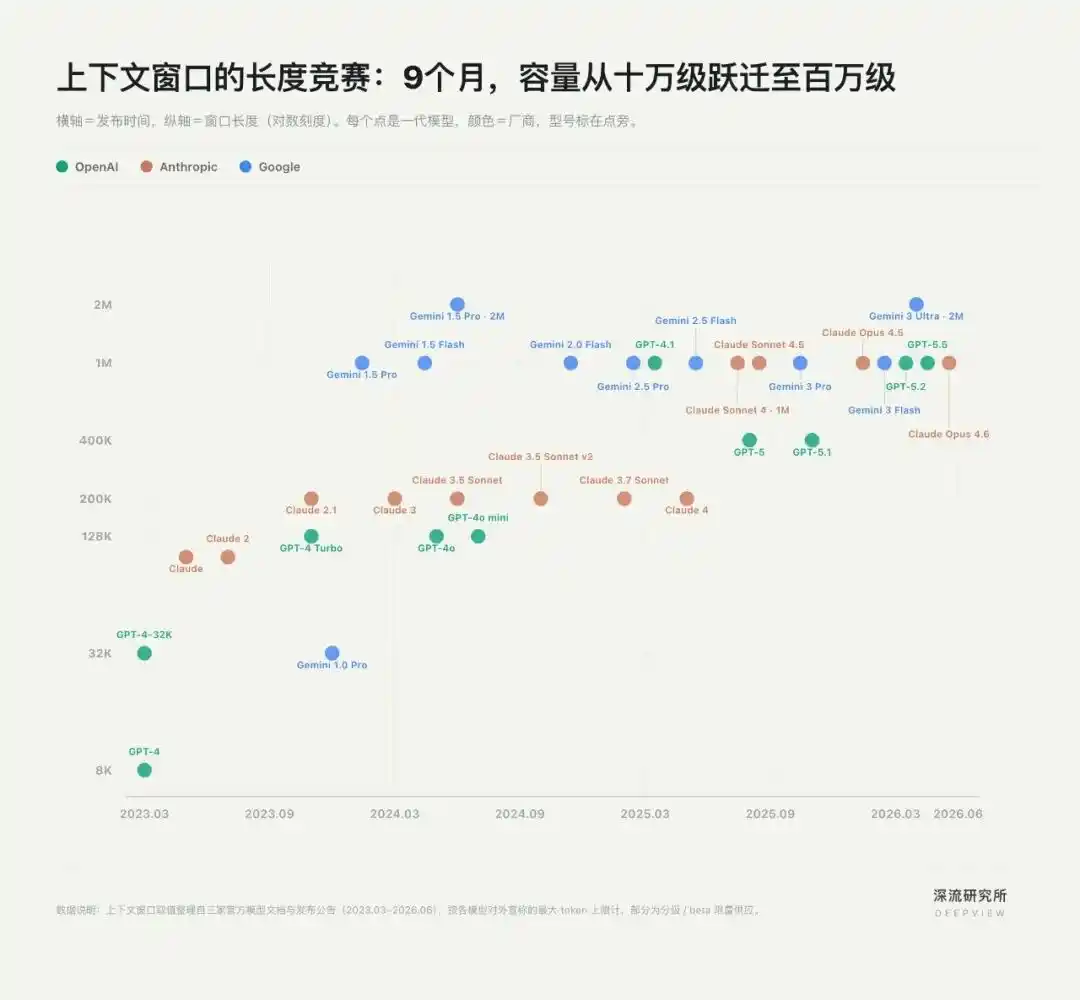
Las ventanas largas resolvieron el problema del "ancho de banda" de la IA, pero esta carrera pronto mostró sus limitaciones: que el modelo pueda ver más información no significa que pueda comprender mejor la tarea.
Especialmente cuando los productos de IA pasaron de Chatbots a Agentes, los límites del Contexto comenzaron a cambiar. Ya no era solo el texto de entrada en una conversación, sino un flujo de estado que se acumula y actualiza de forma dinámica en el ciclo de tareas.
El foco de la competencia también se desplazó: de "cuánto puede saber el modelo de una vez" a "qué puede recordar a largo plazo". Memory se convirtió en la forma de producto típica de esta etapa.
A principios de 2024, OpenAI introdujo la memoria entre sesiones para ChatGPT, permitiendo al modelo recordar las preferencias, antecedentes y necesidades a largo plazo del usuario. Luego, Anthropic y Google complementaron sucesivamente las capacidades de memoria de Claude y Gemini.
El Contexto comenzó a tener una dimensión temporal. La IA ya no solo procesaba la entrada actual, sino que también intentaba establecer continuidad entre las interacciones del usuario de hoy, la semana pasada y el mes pasado. Solo una IA con Contexto a largo plazo puede convertir interacciones discretas en una relación continua.
Sin embargo, Memory responde a "qué sucedió en el pasado", pero no aborda otra pregunta más crucial: ¿qué está sucediendo ahora?
El verdadero punto de inflexión llegó en la segunda mitad de 2025.
A partir de agosto de ese año, las tres empresas llevaron casi simultáneamente el frente de batalla del Contexto al navegador: Anthropic lanzó Claude for Chrome, Google integró Gemini en Chrome, y OpenAI presentó el navegador independiente de IA ChatGPT Atlas.
El navegador es una mina natural de Contexto. Contenido web, intención de búsqueda, estado de inicio de sesión, formularios, historial, pestañas y la tarea que el usuario está ejecutando, todo se acumula en el navegador. Lo más importante es que este Contexto es más en tiempo real, más continuo y más cercano al lugar real de la tarea.
Antes, la forma en que la IA obtenía Contexto era esencialmente esperar a que el usuario proporcionara los materiales: subir archivos, ingresar instrucciones, autorizar memoria, conectar fuentes de datos.
Al entrar en el navegador, la lógica cambió. La IA comenzó a ingresar al entorno de trabajo del usuario, observando el estado de la página, comprendiendo el progreso de la tarea, captando la intención de la operación y ejecutando el siguiente paso en la interfaz real.
Este es el tercer salto en los límites del Contexto: pasó de ser datos estáticos ingresados desde el lado del modelo, a ser estados dinámicos capturados por el Agente en entornos GUI, web y del sistema.
La ventana larga determina cuánta información puede contener el modelo de una vez; Memory determina si el modelo puede comprender al usuario a través del tiempo; las capacidades de navegador, productos de escritorio y GUI determinan si el modelo puede ingresar al lugar real de la tarea.
Los tres juntos constituyen la línea principal de la competencia de productos de IA en los últimos dos años: el Contexto ya no es solo un problema de capacidad del modelo, sino que gradualmente se convierte en un problema de entrada al producto, de relación con el usuario y de acumulación de activos.
2. El Contexto se convierte en un nuevo campo de batalla: tres caminos para el "Trío de Élite" de la IA estadounidense
Cuando el Contexto pasa de ser un parámetro del modelo a un activo del usuario, el núcleo de la competencia se convierte en: ¿quién puede obtener, organizar y utilizar el Contexto de manera más estable?
En torno a esto, OpenAI, Anthropic y Google han tomado tres caminos diferenciados.
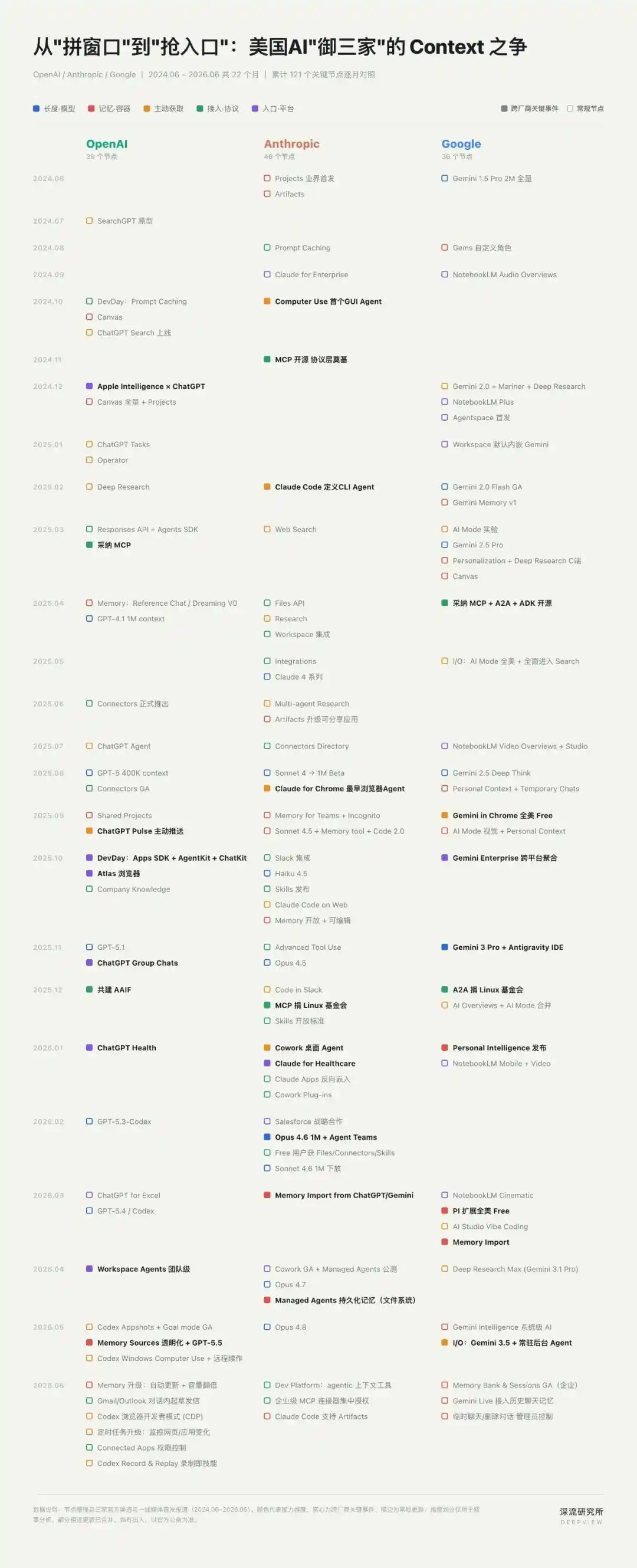
ChatGPT es la fuente de Contexto más central para OpenAI.
Los recuerdos, preferencias, historial de tareas y registros de uso de herramientas que los usuarios dejan en cada conversación se acumulan gradualmente bajo la misma cuenta de ChatGPT.
Esta cuenta es diferente de las cuentas tradicionales de Internet. Las cuentas tradicionales registran estado de inicio de sesión, relaciones de suscripción e información de pago; la cuenta de ChatGPT registra el "historial del usuario comprendido por la IA".
Es un activo de usuario nativo de la IA. Su valor no solo se manifiesta en respuestas más personalizadas, sino también en reducir los costos de arranque en frío, mantener el estado de las tareas y reutilizar la misma comprensión del usuario en diferentes escenarios de producto.
Para OpenAI, al carecer de un ecosistema de datos nativo como el de Google, debe hacer que los usuarios generen continuamente nuevo Contexto dentro del ecosistema ChatGPT.
Por lo tanto, las acciones de producto de OpenAI en los últimos dos años han estado constantemente ampliando el radio de tareas que la cuenta de ChatGPT puede cubrir: el SDK de Apps permite que aplicaciones de terceros entren en ChatGPT, Atlas incorpora el navegador a ChatGPT, y el recién integrado Codex lleva las tareas de programación al mismo flujo de trabajo.
El camino especial de OpenAI es que no toma primero la entrada para luego conectar la IA; parte de ChatGPT como punto de origen y atrae inversamente escenas como aplicaciones, navegador y programación al mismo sistema de cuentas.
ChatGPT ya no es solo una entrada de conversación, sino un centro que reúne, utiliza y actualiza el Contexto.
En comparación, Anthropic carece tanto de entradas para consumidores finales como de datos de usuarios existentes a gran escala.
Su camino es ingresar en escenarios verticales de alto valor como Coding y Agent, y fortalecer en ellos la capacidad de Claude para obtener Contexto de manera activa.
Para Claude, el Contexto no es un texto ingresado por el usuario, sino un entorno que cambia dinámicamente en el lugar de la tarea: repositorios de código, sistemas de archivos, salidas de terminal, páginas del navegador, bases de datos, documentación del proyecto y la retroalimentación después de cada paso de ejecución.
Por lo tanto, Anthropic enfatiza más la proactividad en la obtención del Contexto. El modelo no debería solo esperar la entrada del usuario, sino también ingresar activamente al entorno, leer el estado y obtener retroalimentación durante la ejecución de la tarea.
En octubre de 2024, Anthropic lanzó Computer Use, permitiendo a Claude mover el cursor, hacer clic en botones e ingresar texto según capturas de pantalla.
Según la declaración oficial, Claude 3.5 Sonnet es el primer modelo de IA de vanguardia que ofrece públicamente capacidad de uso de computadora.
Esto significa que cuando el Contexto existe en páginas web, formularios, interfaces de sistemas backend y software local, en lugar de en APIs estructuradas, Claude también puede ingresar al entorno a través de GUI, observar el estado y ejecutar operaciones.
Un mes después, Anthropic lanzó MCP. Este protocolo abierto que conecta asistentes de IA con herramientas y fuentes de datos externas está definido oficialmente como conectar asistentes de IA a "los sistemas donde están los datos", incluyendo bibliotecas de contenido, herramientas empresariales y entornos de desarrollo.
Su valor radica en que permite a Claude dejar de depender de que los usuarios copien y peguen, y en su lugar acceder a herramientas y fuentes de datos externas de manera estandarizada.
Estas dos capacidades corresponden a dos caminos para que Anthropic obtenga Contexto:
Computer Use ingresa a la interfaz a través de GUI, MCP conecta sistemas a través de protocolos. Uno ingresa al lugar de la tarea, el otro conecta herramientas externas, permitiendo juntos que Claude obtenga Contexto dinámico.
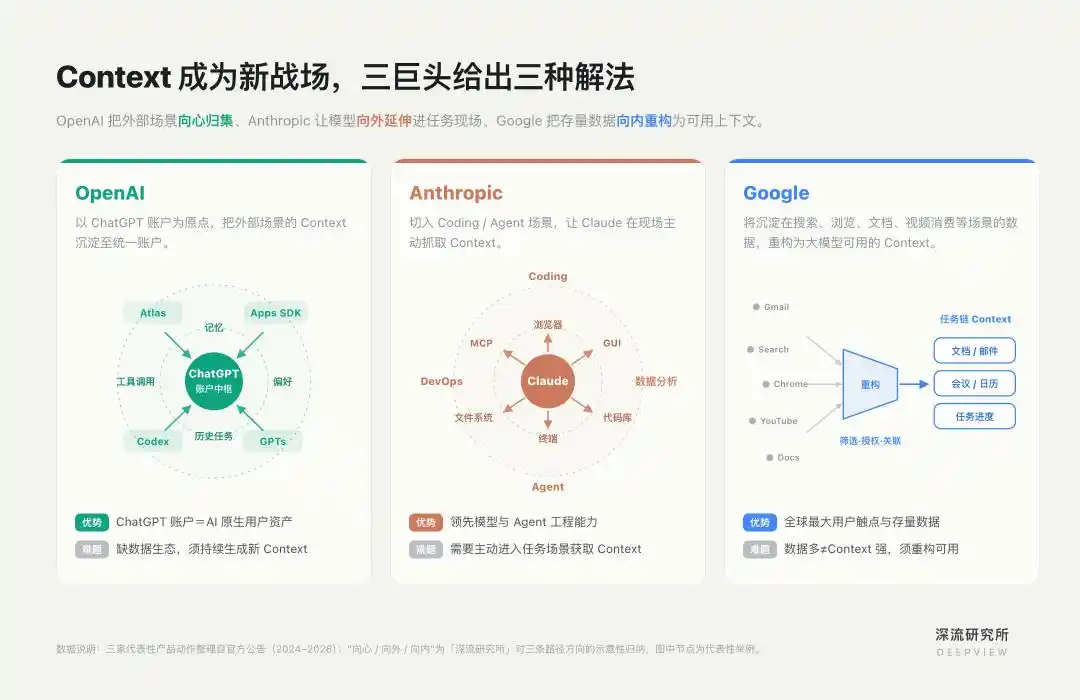
Veamos a Google. A menudo se dice que Google es una de las empresas con más Contexto. No le faltan entradas ni datos. Productos como Chrome, Gmail, YouTube y Search constituyen uno de los mayores puntos de contacto con usuarios a nivel mundial.
Pero desde la perspectiva de la IA, tener muchos datos no equivale a tener un Contexto fuerte.
Google ha acumulado en el pasado datos de búsqueda, navegación, correo electrónico, documentos, ubicación, consumo de video, etc., principalmente para servir a la clasificación de búsquedas, entrega de anuncios, recomendación de contenido y colaboración en oficinas. Son esencialmente señales de comportamiento necesarias para el funcionamiento del sistema.
Lo que un Agente necesita es el contexto de la tarea que puede ser comprendido, razonado e invocado por el modelo.
Solo cuando el modelo puede determinar qué información es relevante para la tarea actual, cuál está obsoleta, cuál puede ser invocada y cómo se relacionan estas piezas de información entre sí, los datos se convierten realmente en Contexto.
Google no enfrenta un simple "acceso a datos", sino una reestructuración de datos. Necesita re-seleccionar, relacionar, autorizar y transformar los datos antiguos dispersos en diferentes productos y que sirven a diferentes objetivos del sistema, en un contexto personal utilizable para Gemini.
La dificultad de esta ingeniería no es menor que la de OpenAI para acumular Contexto de nuevo o la de Anthropic para ingresar al lugar de la tarea.
En los últimos dos años, las acciones de producto de Google no han sido empezar de cero, sino reformar hacia adentro desde sus posiciones existentes. El núcleo de este camino es organizar datos fragmentados en cadenas de tareas.
En mayo de 2024, Gemini 1.5 Pro ingresó a la barra lateral de Workspace, permitiendo que el modelo primero invoque el contexto actual en escenarios de trabajo como Gmail, Docs, Drive.
En julio de 2025, la app Gemini comenzó a conectarse con herramientas como Gmail, Drive, Calendar, expandiendo el Contexto de una sola aplicación a tareas entre aplicaciones.
En enero de 2026, Personal Intelligence lanzó su versión beta, incorporando aún más datos personales como Gmail y Photos al contexto personalizado de Gemini.
La estrategia de Contexto de Google no es "tenemos muchos datos, así que lideramos naturalmente".
Lo que realmente debe completar es una ingeniería de "hacer los datos utilizables": transformar los datos de comportamiento acumulados en el pasado, que sirvieron a objetivos sistémicos como búsqueda, publicidad y recomendación, en un Contexto comprensible, autorizable y accionable para la era de la IA.
3. De la "escala de red" a la "profundidad individual": el foso competitivo de la era de la IA ha cambiado
En los últimos dos años, OpenAI, Anthropic y Google han acelerado la acumulación y explotación del Contexto, construyendo en torno a él capacidades de adquisición, organización y uso, intentando formar nuevas barreras competitivas.
Pero un cambio aparentemente contradictorio también ha ocurrido simultáneamente: este año, las tres empresas han hecho coincidentemente que Memory sea transparente, explicable e incluso transferible.
En marzo de 2026, Anthropic y Google lanzaron sucesivamente Memory Import, permitiendo a los usuarios migrar recuerdos entre ChatGPT, Gemini y Claude.
Luego, OpenAI, a través de Memory Sources, permitió a los usuarios ver qué recuerdos, historiales de chat o fuentes de datos externas se invocaron detrás de una respuesta personalizada.
Si el Contexto es el activo más importante de la era de la IA, ¿por qué las plataformas comienzan a abrir sus permisos?
La respuesta está en que lo que Memory Import realmente abre es solo el Contexto superficial: preferencias del usuario, resúmenes de recuerdos históricos, versiones comprimidas del historial de conversaciones.
Esta información está altamente estructurada y es fácil de describir en lenguaje natural. Migrarla no presenta un alto umbral técnico.
Lo realmente difícil de migrar es otro tipo de Contexto: estado de la tarea, permisos de herramientas, acceso a sistemas empresariales, retroalimentación en tiempo real desde el lugar de ejecución.
Este Contexto está profundamente incrustado en los productos y entornos del sistema, y no se puede transferir completamente con un simple prompt.
Esto también muestra que la lógica competitiva de la era de la IA es diferente a la de la era de Internet.
La forma básica de Internet es la red. Conecta personas, contenido, productos, servicios e información en nodos. Cuantos más nodos y conexiones, más valioso es el producto. Por lo tanto, el foso más fuerte de la era de Internet fue el efecto de red, donde el valor provenía de que más personas lo usaran.
La forma básica de la IA se acerca más a una nueva computadora, o un nuevo sistema de procesamiento de información.
Su valor de primer orden no es conectar a más personas, sino comprender información, procesar tareas, invocar herramientas y completar acciones. Una IA, incluso si solo sirve a un usuario, también puede crear un gran valor.
Por lo tanto, el foso competitivo de la era de la IA está pasando de la "escala de red" a la "profundidad individual". Esta barrera de "profundidad individual" proviene principalmente de tres niveles:
Primero, el interés compuesto del Contexto. Cada vez que la IA completa una tarea, comprende mejor los hábitos de expresión, criterios de juicio, fuentes de información y flujos de trabajo del usuario. En la siguiente ejecución, el costo de arranque en frío será menor.
Segundo, la incrustación de permisos y cadenas de herramientas. Cuando un usuario autoriza a la IA su correo electrónico, documentos, repositorios de código, etc., la IA deja de ser solo una herramienta de preguntas y respuestas reemplazable, sino que ingresa al lugar real de la tarea.
Tercero, la formación de relaciones de confianza. Cuanto más compleja y valiosa es la tarea, es menos probable que el usuario se la confíe fácilmente a una IA desconocida. Solo una IA que lo comprenda a largo plazo, conozca sus límites y pueda continuar el contexto puede ser autorizada para ejecutar el siguiente paso.
Si los productos de Internet compiten por la entrada de atención, entonces los productos de IA compiten por la entrada de tareas.
Una vez que una IA ingresa continuamente en el flujo de trabajo del usuario, acumula contexto y obtiene permisos de ejecución, el costo de migración ya no es solo cambiar de aplicación, sino restablecer una relación de tarea en la que se es comprendido, autorizado y confiado.
Los cambios en los productos nacionales también pueden entenderse bajo esta lógica.
Tomemos a Tencent como ejemplo. En la era de Internet, acumuló cadenas de relaciones, contenido, ecosistema de servicios y entradas de alta frecuencia; en la era de la IA, el valor de estos activos reside precisamente en si pueden ser reorganizados como Contexto comprensible, invocable y ejecutable por un Agente.
Ya sea WorkBuddy accediendo a escenarios de trabajo como documentos, reuniones y WeChat Empresarial, o el intento del "Xiao Wei" de WeChat de invocar mini programas y servicios dentro del ecosistema de WeChat, en esencia, se trata de transformar contenido, relaciones y procesos que originalmente servían a las personas en entornos de tarea a los que la IA puede acceder.
Como juzga Yao Shunyu, científico principal de IA de Tencent: El Contexto parece ser un activo de datos, pero en esencia es una manifestación integral de la capacidad del producto, la capacidad de ingeniería y la capacidad de coordinación organizativa.
En la era de Internet, el foso competitivo dependía de la escala. En la era de la IA, el foso debería depender más de la eficiencia de conversión:
Quien pueda transformar más rápido el ecosistema existente en un entorno de trabajo para la IA, quien permita que la IA acumule una comprensión más profunda del usuario en cada tarea, es más probable que establezca nuevas barreras.
Esto es también lo que realmente merece atención en la guerra por el Contexto.
Este artículo proviene de la cuenta oficial de WeChat "Instituto de Investigación Deep Flow", autor: Jiang Feng.






