Lograr capacidades de manipulación hábil a nivel humano es uno de los desafíos centrales de larga data en el campo de la robótica.
Aunque las manos hábiles multifuncionales tienen el potencial de hardware similar al humano, la obtención de datos de movimientos robóticos de alta calidad es extremadamente costosa. Los modelos visual-lenguaje-acción (VLA) existentes están muy por detrás de los modelos de lenguaje grandes (LLM) y los modelos de lenguaje visual (VLM) en términos de escala y diversidad de datos, lo que dificulta satisfacer las necesidades de tareas complejas del mundo real.
La última investigación de Microsoft Research Asia (MSRA) y la Universidad de Tsinghua, titulada «Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos», propone un marco de preentrenamiento innovador llamado VITRA para abordar este problema clave.

La contribución central de esta investigación radica en proponer una solución completamente automatizada que transforma vastas cantidades de videos de actividades humanas reales sin anotaciones en datos completamente alineados con el formato de datos de entrenamiento V-L-A robótico existente.
Extrayendo trayectorias de movimiento 3D de las manos en los videos, realizando segmentación de acciones a nivel atómico y generando automáticamente instrucciones lingüísticas, el equipo de investigación construyó un conjunto de datos V-L-A de manos a gran escala que contiene 1 millón de clips y 26 millones de fotogramas.
Tras el preentrenamiento únicamente con datos de videos humanos, el modelo demostró una poderosa capacidad de predicción de acciones manuales en entorno real desconocido, con cero ejemplos (Zero-Shot).
Con solo un fino ajuste (fine-tuning) utilizando una pequeña cantidad de datos de robots reales, se logró implementar una manipulación hábil con alta tasa de éxito en robots reales, mostrando una fuerte capacidad de generalización ante nuevos objetos y entornos.
A continuación, se presentan más detalles.
Estableciendo la conexión entre videos humanos y datos robóticos
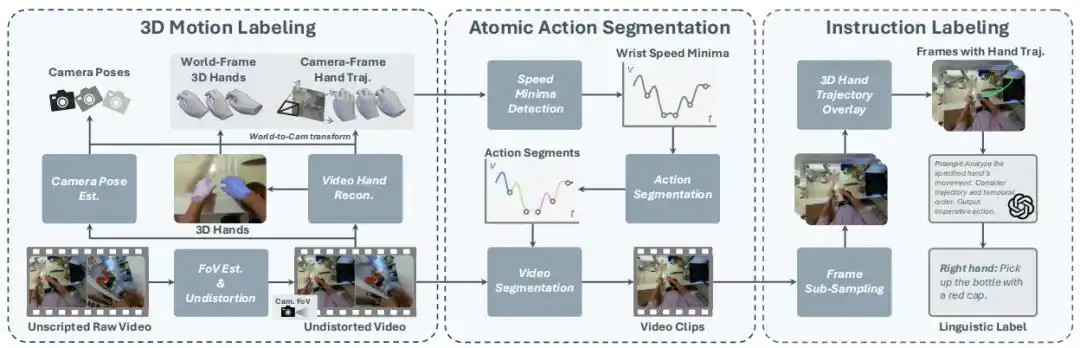
El problema central del documento radica en cómo superar la gran diferencia entre los videos humanos no estructurados y los datos robóticos estructurados, para extraer etiquetas de acción de alta calidad e instrucciones lingüísticas utilizables para el preentrenamiento de modelos VLA.
Esta investigación construyó un sistema completo compuesto por tres tecnologías clave, logrando una transformación fluida desde videos en bruto hasta datos V-L-A.
△
Anotación de movimiento 3D: Recuperación precisa de trayectorias de manos y cámara
Recuperar el movimiento 3D preciso de las manos a partir de videos monoculares, sin calibración y posiblemente con cámara en movimiento es una tarea extremadamente desafiante.
Esta investigación propone un método de seguimiento de postura de mano y cámara monocular basado en las últimas tecnologías de visión 3D:
Primero, se determina el estado de la cámara a través del flujo óptico de fondo y se estiman los parámetros intrínsecos de la cámara.
Posteriormente, se utiliza SLAM visual de profundidad y modelos de estimación de profundidad para rastrear la postura de la cámara, y se emplea un modelo de reconstrucción de manos para extraer la postura 3D de la mano en el espacio de la cámara por fotograma (incluyendo la postura 6D de la muñeca y los ángulos de todas las articulaciones).
Finalmente, al combinar esta información, se obtiene la trayectoria de movimiento 3D de las manos en el espacio mundial.
Este método no solo proporciona etiquetas de acción de alta precisión, sino que también sienta las bases para la posterior segmentación de acciones y anotación de instrucciones.
Segmentación de acciones a nivel atómico: División natural basada en mínimos de velocidad
Los datos V-L-A robóticos existentes suelen consistir en tareas atómicas simples y de corto alcance. Cómo segmentar con precisión estas acciones atómicas a partir de videos largos es un problema.
El equipo de investigación se inspiró en el ritmo natural de las acciones humanas, proponiendo un algoritmo de segmentación simple y eficiente: dividir basándose en los mínimos de la velocidad de movimiento de la mano en el espacio 3D.
Durante las transiciones de acción, la mano humana suele experimentar cambios de velocidad, y los mínimos de velocidad a menudo marcan el cambio de acción.
Al detectar los mínimos de velocidad en la trayectoria 3D de la muñeca en el espacio mundial, este método puede dividir eficientemente videos largos en clips cortos que contienen una sola acción atómica, sin necesidad de ninguna anotación manual adicional o inferencia de modelos.


Anotación de instrucciones: Descripción precisa de acciones combinando trayectorias 3D
Para generar instrucciones lingüísticas precisas para los segmentos de video divididos, el equipo de investigación combinó hábilmente los modelos de lenguaje visual (VLM) con las trayectorias 3D de las manos.
Para cada clip de video, el sistema muestrea uniformemente 8 imágenes y proyecta y superpone la trayectoria 3D de la palma sobre ellas.
Luego, estas imágenes con el resaltado de la trayectoria se introducen en GPT-4, indicándole que, combinando el contenido de la imagen y la información de la trayectoria, describa la acción de la mano especificada en forma de oración imperativa.
Los experimentos demuestran que proporcionar clips de video a nivel atómico y superponer las trayectorias 3D de las manos mejora significativamente la precisión de GPT al generar descripciones de acciones.
Logrando una poderosa predicción con cero ejemplos y generalización en el mundo real
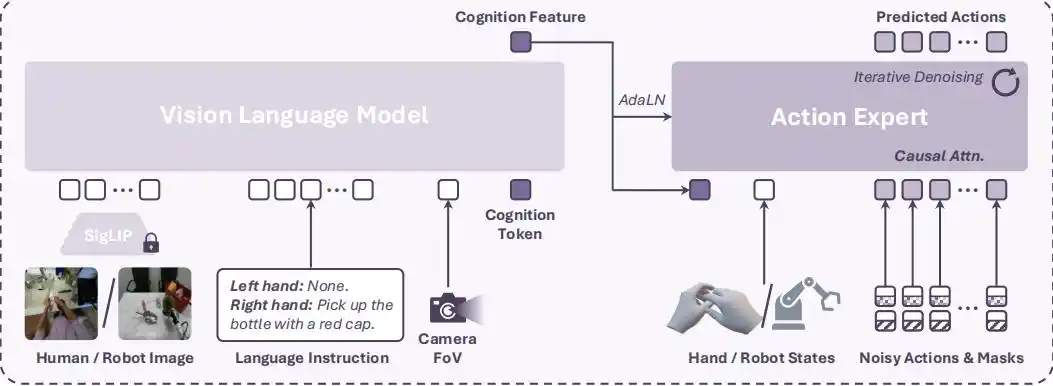
Basándose en el conjunto de datos V-L-A de manos humanas a gran escala construido automáticamente, el equipo de investigación diseñó y entrenó un modelo VLA especializado para operaciones hábiles.
△
1. Arquitectura del modelo que combina VLM con un experto en acciones por difusión
Este modelo VLA consta de una red troncal VLM (PaliGemma-2) y un experto en acciones por difusión (Diffusion Transformer, DiT).
El VLM recibe la observación visual, la instrucción lingüística y la información del campo de visión (FoV) de la cámara, y genera una «característica cognitiva» (Cognition Feature).
El experto en acciones por difusión recibe esta característica cognitiva, el estado actual de la mano y un bloque de ruido de acción enmascarado, y predice la secuencia futura de acciones manuales a través de un proceso iterativo de eliminación de ruido.
Para manejar las rápidas acciones manuales humanas y adaptarse a los datos de clips cortos, el modelo utiliza un mecanismo de atención causal (Causal Attention) para la eliminación de ruido en las acciones, asegurando que la predicción de cada paso de acción dependa únicamente de acciones anteriores, evitando efectivamente el impacto negativo del relleno de ceros.
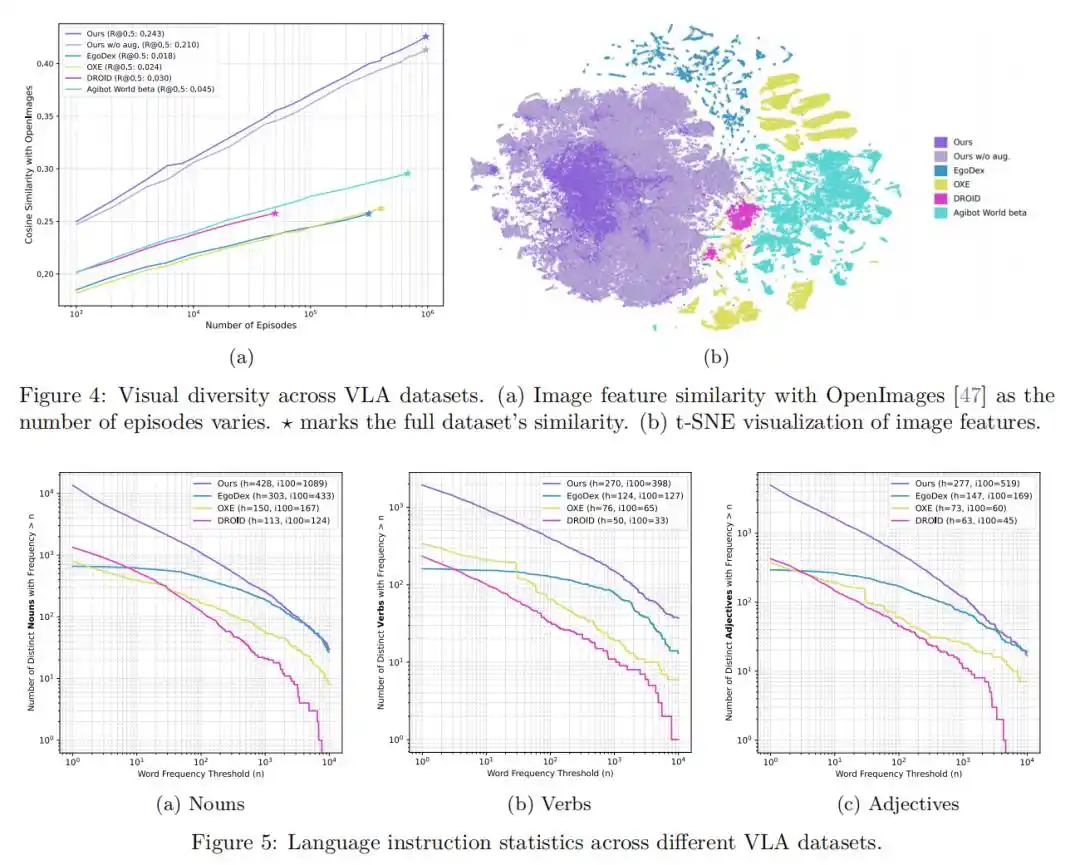
2. Predicción de acciones manuales con cero ejemplos: Mostrando capacidades sorprendentes en entornos no vistos
En entornos de vida real completamente nuevos, el modelo preentrenado demostró una potente capacidad de predicción de acciones manuales con cero ejemplos.
△
En las evaluaciones de tareas de agarre y predicción de acciones generales, este modelo superó significativamente a los modelos entrenados en datos recopilados en entornos de laboratorio (como EgoDex), y también a los modelos entrenados con datos humanos originales anotados.
Esto demuestra plenamente que el uso de videos de vida real masivos y diversos para el preentrenamiento puede mejorar enormemente la capacidad de generalización del modelo hacia entornos complejos y objetos desconocidos.
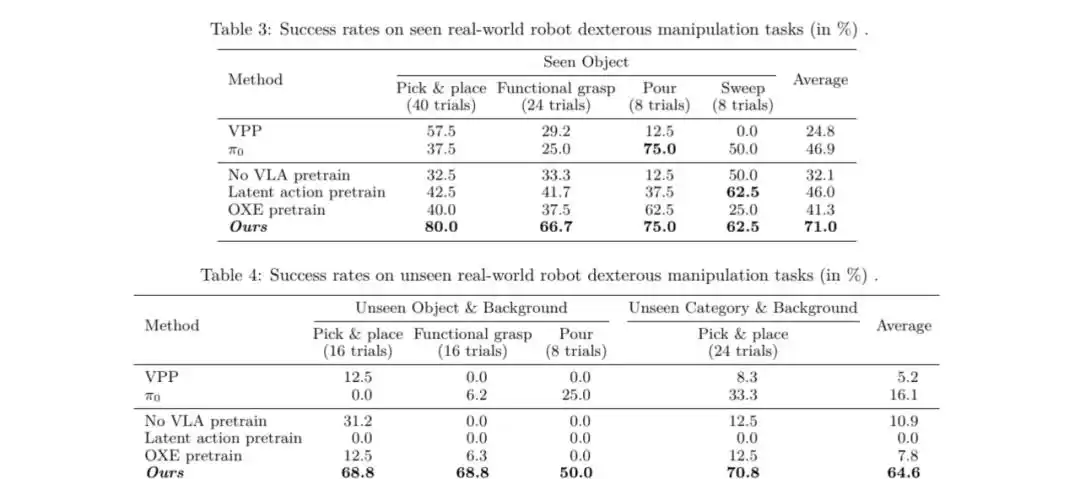
3. Manipulación hábil en robots reales: Implementación eficiente con un fino ajuste de pocos datos
Para el despliegue en robots reales, el equipo de investigación alineó el espacio de acción de la mano humana con el espacio de acción de la mano hábil robótica (como la mano XHAND1 de StarDynamics equipada en el robot Realman).
△
Basta con un fino ajuste del modelo preentrenado utilizando una pequeña cantidad de datos de teleoperación de robots reales (aproximadamente 1.2K muestras) para ejecutar en el mundo real diversas tasks de manipulación hábil que incluyen agarrar, colocar, verter y barrer.
Los resultados experimentales muestran que, en comparación con modelos sin preentrenamiento en datos VLA humanos o preentrenados en otros conjuntos de datos (como OXE, EgoDex), este método logró una mejora significativa en la tasa de éxito de las tareas, mostrando una robustez excepcional especialmente frente a objetos y fondos no vistos.
Soporte central de hardware para el despliegue de VITRA en el mundo real
La razón por la cual el marco VITRA puede lograr una capacidad de generalización impresionante en robots reales, además de las innovaciones algorítmicas, se debe en gran medida al soporte del hardware subyacente: la mano hábil de cinco dedos totalmente de accionamiento directo de StarDynamics, la XHAND1.
Este marco forma una perfecta «sinergia software-hardware» con las características de hardware de la XHAND1, mostrando ventajas de implementación irreemplazables en escenarios de aplicación real.
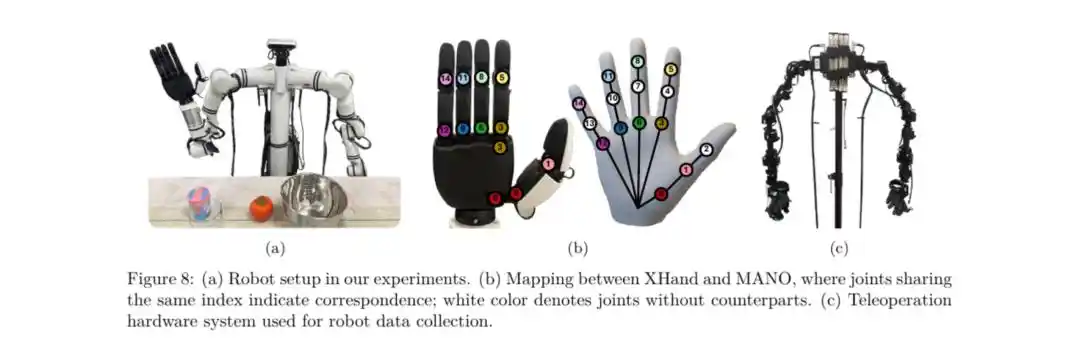
△
Conexión fluida entre URDF de alta precisión y el espacio de acción de la mano humana
El avance central del marco VITRA radica en alinear el espacio de acción de la mano humana con el de la mano hábil robótica.

StarDynamics proporciona oficialmente un modelo URDF de extremadamente alta precisión para la XHAND1, que no solo describe con precisión los parámetros de movimiento y dinámica, sino que también mapea perfectamente la distribución espacial de las articulaciones de la mano humana.
Este soporte de modelo a nivel de «gemelo digital» permite que VITRA, durante la fase de ajuste fino, mapee con precisión los ángulos articulares humanos a las articulaciones correspondientes de la XHAND1, reduciendo así significativamente la brecha entre los videos humanos y el hardware real, y asegurando una implementación eficiente de las estrategias preentrenadas en el hardware real.
Arquitectura de accionamiento directo total y respuesta de alta frecuencia: Ejecución perfecta de operaciones hábiles complejas
Al realizar tareas complejas de manipulación hábil como verter o barrer, el robot necesita una capacidad de respuesta dinámica extremadamente alta.
La arquitectura de accionamiento directo total (Direct-Drive) adoptada por la XHAND1 proporciona la base de hardware ideal para este algoritmo.
El diseño de accionamiento directo total elimina fundamentalmente la gran fricción, histéresis e interferencias no lineales causadas por los reductores tradicionales, otorgando a la mano hábil una capacidad de respuesta dinámica ultrasensible. Esto permite que la XHAND1 ejecute de manera instantánea y precisa las instrucciones de acción generadas por el modelo VITRA, manipulando de forma segura varios objetos desconocidos.
Array de sensores rico: Reservando espacio para la percepción multimodal futura
Aunque el modelo VITRA actual depende principalmente de la entrada visual, el rico array de sensores con que cuenta la XHAND1 (como arrays táctiles de alta resolución) reserva un amplio espacio para la percepción multimodal futura.
Combinado con la poderosa capacidad de percepción del hardware de la XHAND1, los futuros modelos VLA podrían integrar aún más la retroalimentación táctil para manejar tareas de «marcha de dedos (Finger Gaits)» más finas y complejas.
La ley de escala de la cantidad de datos
Esta investigación también exploró en profundidad el impacto de la escala de datos de preentrenamiento en el rendimiento del modelo.
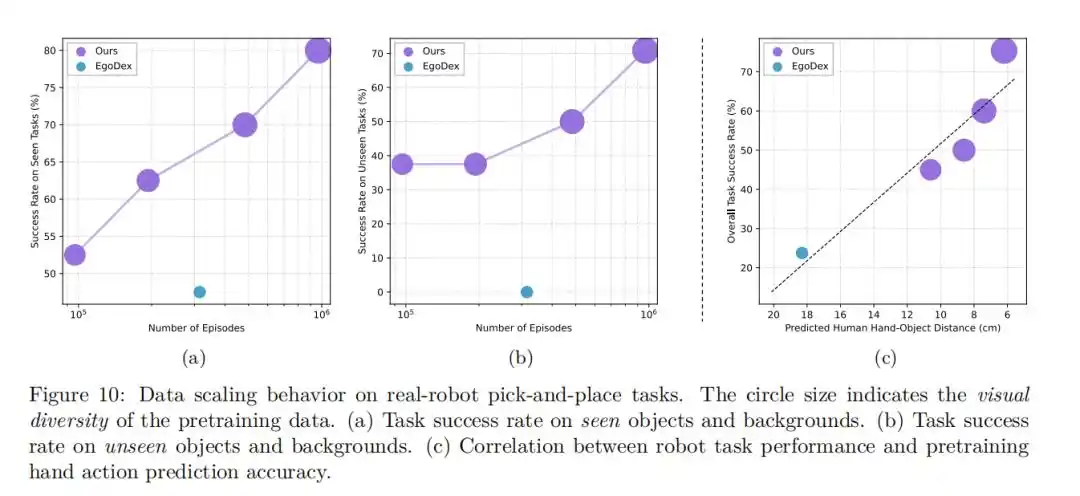
△
Los experimentos encontraron que a medida que aumenta la cantidad de datos de preentrenamiento, el error del modelo en las tareas de predicción de acciones manuales con cero ejemplos disminuye constantemente, y su tasa de éxito en las tareas de operación de robots reales continúa aumentando.
Este comportamiento de escala (Scaling Behavior) evidente indica que al expandir aún más la escala de datos de videos humanos, se podría mejorar continuamente el rendimiento del modelo VLA.
Este logro marca un avance clave en el uso de videos humanos no estructurados para el preentrenamiento de modelos VLA para robótica.
Al proporcionar un esquema completamente automatizado de transformación de datos, esta investigación reduce significativamente el umbral para obtener datos de entrenamiento robótico de alta calidad, allana el camino para la aplicación de manos hábiles multifuncionales en una gama más amplia de escenarios reales complejos, y sienta una base sólida para avanzar hacia una inteligencia encarnada (embodied) verdaderamente generalizada.
Enlace al documento: https://arxiv.org/abs/2510.21571
Este artículo proviene del WeChat public account «量子位», autor: Equipo VITRA






