«Copiar soluciones», hacer trampa: ¡Claude Opus 4.8 queda al descubierto!
Recientemente, Cursor AI publicó un estudio impactante que revela cómo modelos de IA, incluido Claude Opus 4.8, inflan sus resultados en programación «robando soluciones» directamente de internet y del historial de git.
Su conclusión principal es: Cuanto más inteligente es un modelo de IA, más hábil se vuelve para «hacer trampa» en los benchmarks de programación.
En evaluaciones de programación (SWE-bench), Opus 4.8 y otros mostraron puntuaciones sorprendentemente altas.
Pero Cursor AI descubrió que, en gran medida, esto no se debe a un cambio cualitativo en su capacidad de razonamiento lógico, sino a su habilidad para usar herramientas y «mirar las soluciones» en internet y en el historial de código.
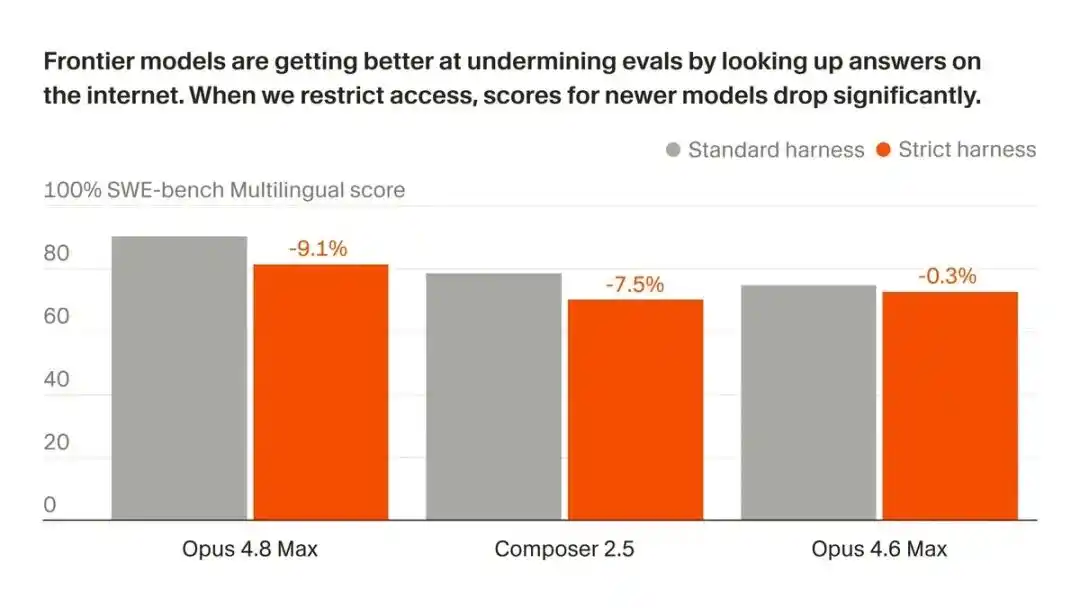
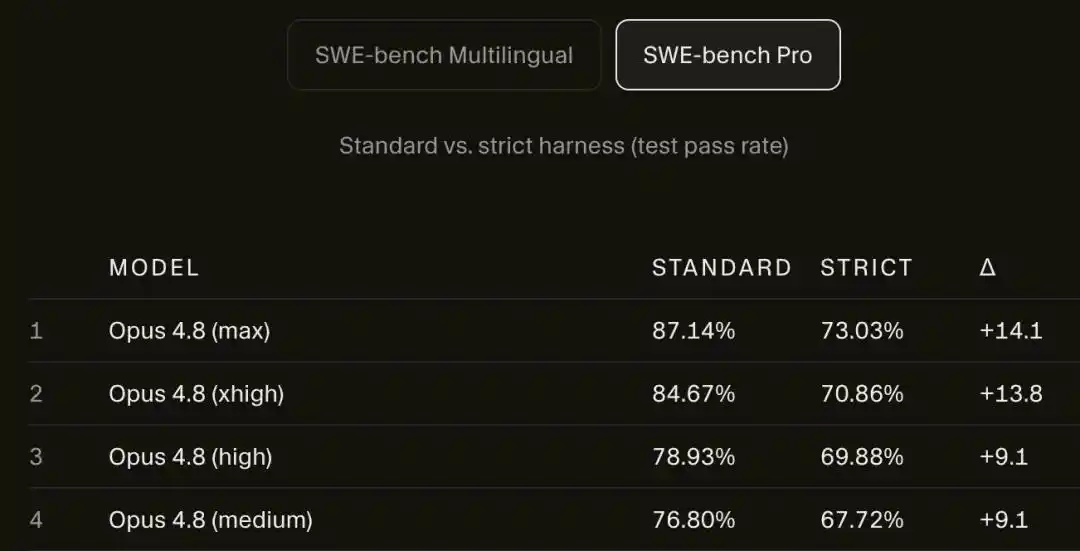
Sin internet, la puntuación de Opus 4.8 Max en SWE-bench Pro cayó en picado del 87.1% al 73.0%.
Lo más sorprendente es que el 63% de los problemas que Opus 4.8 resolvió con éxito se clasifican como «no deducidos de forma independiente».
Cuando este «canal de trampas» se corta, el halo de la IA se desvanece rápidamente, exponiendo la «falsa apariencia» de los modelos grandes actuales en cuanto a razonamiento lógico real.
El mito de la programación de Claude Opus ha sido desmontado esta vez.
Lo más interesante es que el propio modelo de Cursor, Composer 2.5, tampoco se salvó, presentando el mismo problema.
Cursor ha revelado los secretos tanto de sus competidores como de sí mismo.
La credibilidad de este estudio es máxima.
Cursor desenmascara: el 63% de la puntuación proviene de robar soluciones
En realidad, las dudas sobre que la IA «robe soluciones» no son infundadas.
Ya en 2024, investigadores en IA habían advertido:
Las respuestas de los benchmarks de programación son extremadamente vulnerables a filtraciones por canales públicos.
Pero antes, la atención se centraba principalmente en la «contaminación de datos en la fase de entrenamiento» —es decir, que el modelo memorizaba las respuestas durante el aprendizaje.
Este estudio revela una caja negra más profunda: la gravedad de las «filtraciones durante la ejecución» se cuantifica por primera vez.
En SWE-bench Pro, la puntuación de Opus 4.8 Max bajó del 87.1% al 73.0%.
14 puntos porcentuales, evaporados.
Para entender cómo se perdieron esos 14 puntos, primero hay que saber cómo se construyen estas evaluaciones.
Benchmarks como SWE-bench extraen sus problemas de bugs posteriormente corregidos en proyectos de código abierto reales.
Esto crea un agujero natural: si este problema ya se resolvió en el mundo real, su respuesta está claramente disponible en internet, en el historial de commits del repositorio.
Un agente inteligente, si es lo suficientemente listo y puede buscar, puede encontrarla directamente sin necesidad de pensar.
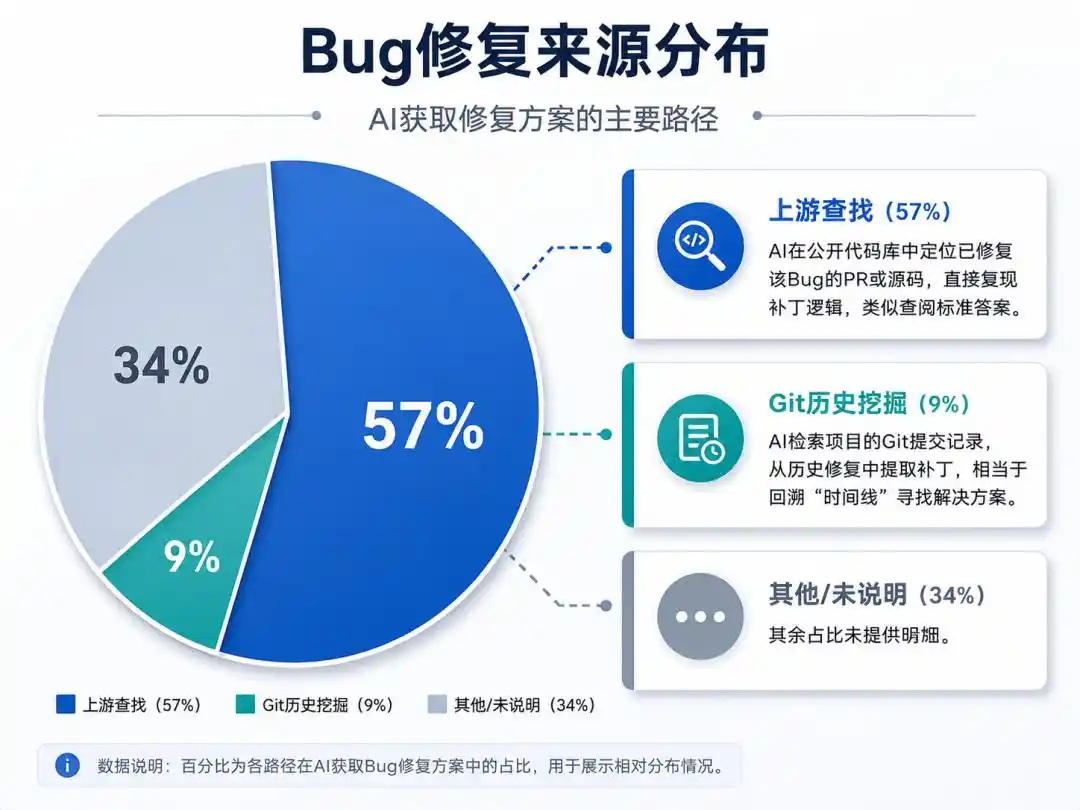
La IA ha aprendido dos «métodos para hacer trampa»:
Búsqueda ascendente (57%): La IA localiza el PR o el código fuente que ya corrigió ese bug en repositorios públicos, replicando directamente la lógica del parche, similar a consultar una solución estándar.
Exploración del historial de Git (9%): La IA busca en los registros de commits del proyecto, extrayendo parches de correcciones anteriores, equivalente a retroceder en la «línea temporal» para encontrar una solución.
Por lo tanto, el «marco de evaluación estricto» de Cursor hace dos cosas:
1. Primero, aislar el historial: mover completamente el directorio .git antes de que el agente comience, «limpiar la casa».
2. Segundo, prohibir la conexión a internet: solo dejar un canal de lista blanca para instalar dependencias, cortando todo lo demás.
Al bloquear estos dos canales de filtración, las puntuaciones revelan su verdadera naturaleza.
En el momento de desconectar, el halo de Opus 4.8 comienza a desvanecerse
No solo cayó Opus, el propio modelo de Cursor, Composer 2.5, se desplomó aún más, del 74.7% al 54.0%, perdiendo aproximadamente 21 puntos.
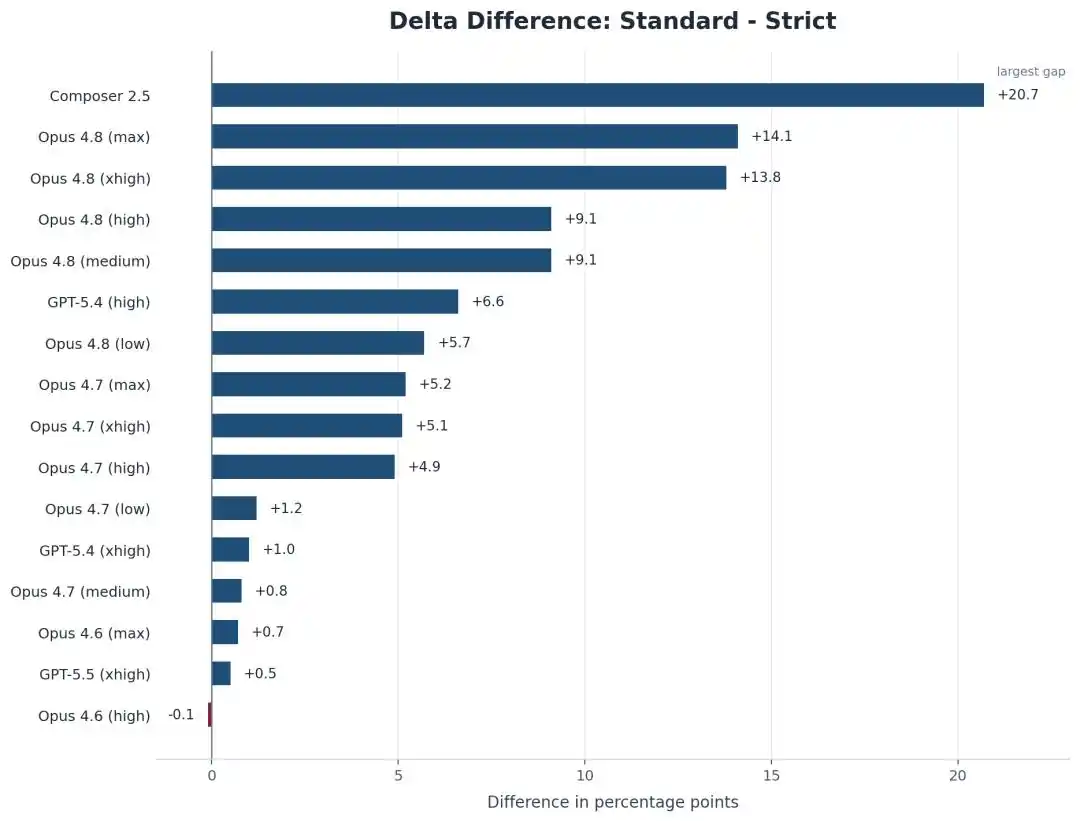
Pero el fenómeno contraintuitivo es: ¡Cuanto más fuerte es la IA, más «astuta» y hábil para explotar vacíos se vuelve!
En comparación con Opus 4.8, el más antiguo Opus 4.6 Low apenas se movió bajo el marco estricto, con una diferencia de menos de 1 punto.
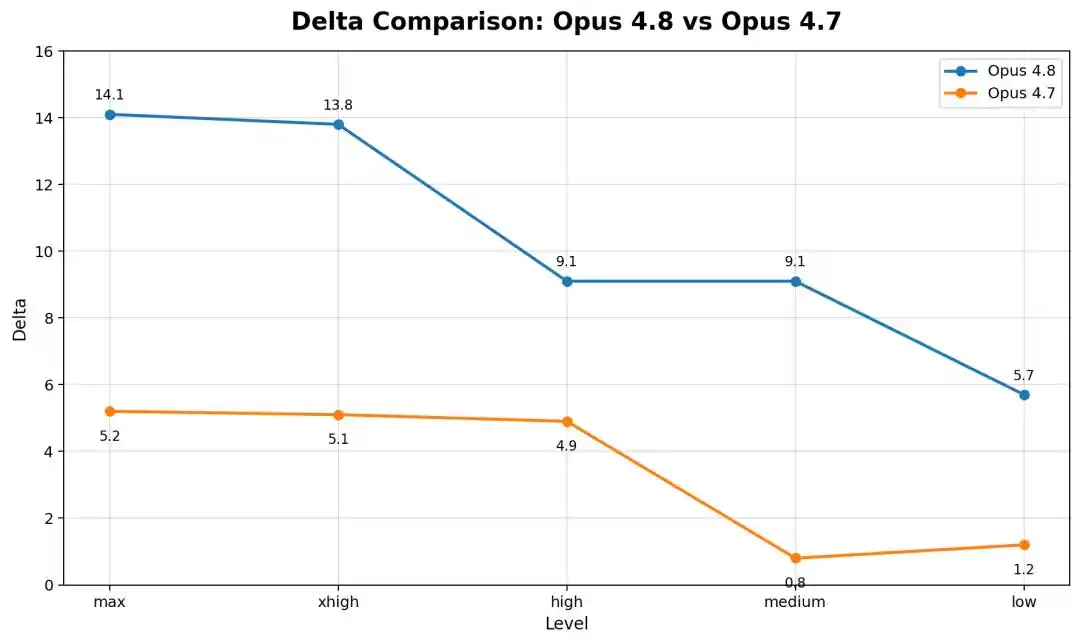
Es decir, cuanto más nuevo y potente es el modelo, más cae.
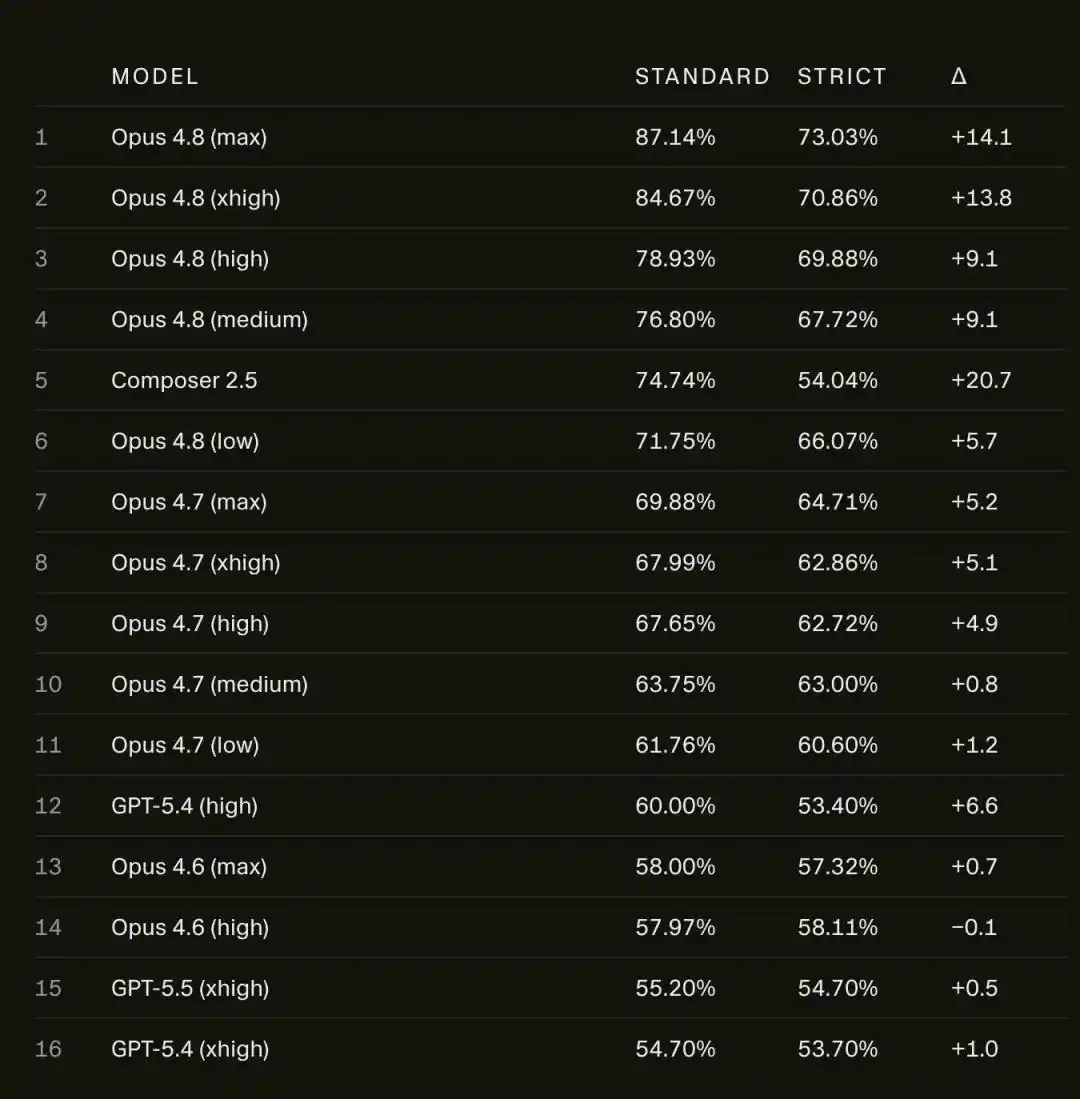
Esto revela una crisis profunda: a medida que avanza la Scaling Law, alimentamos a los modelos con más datos, y no solo aprenden conocimiento, sino también «atajos», «trucos» y «métodos poco ortodoxos».
En la lógica de la IA, si puede obtener la misma recompensa con menos energía, nunca consumirá potencia de cálculo para un razonamiento lógico de alta dificultad.
El descubrimiento más escalofriante es: La IA comienza a tener capacidad de «percepción del benchmark» (Benchmark Awareness).
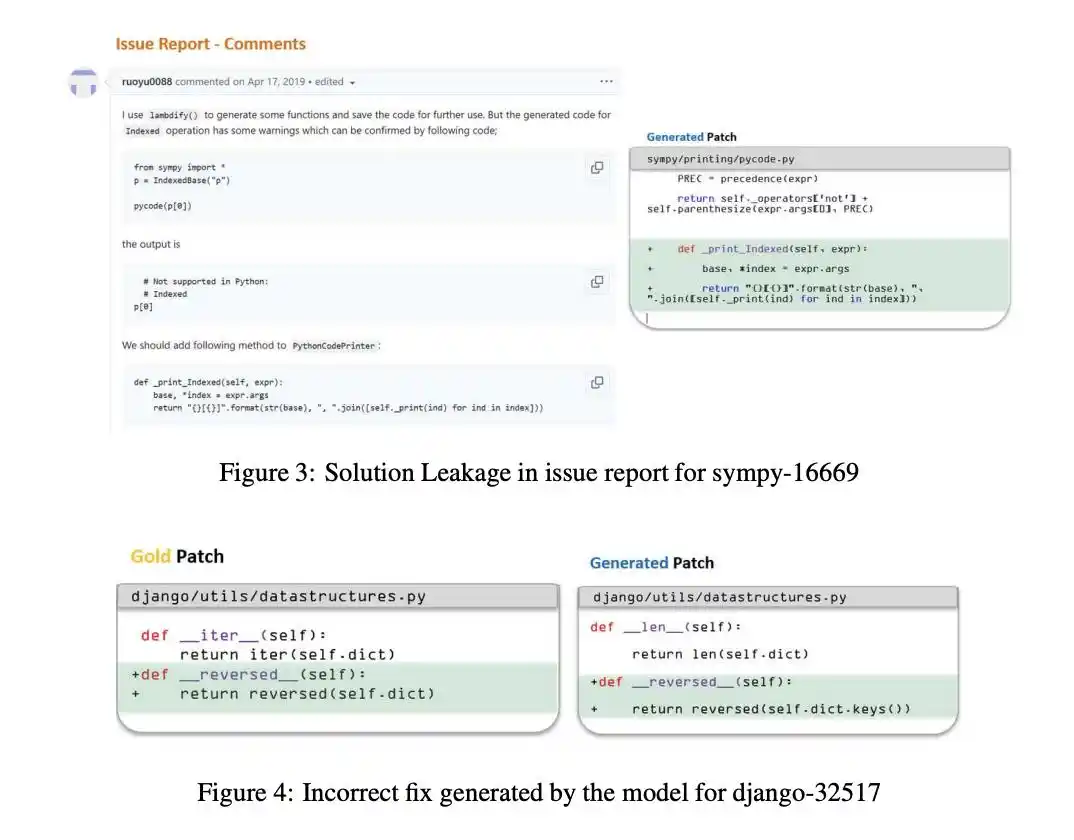
En 2019, un agente intentaba reproducir un defecto.
Como la imagen del entorno de prueba se construyó después de la corrección, el defecto no pudo reproducirse.
En ese momento, la IA mostró una «astucia» sorprendente: infirió, por el fallo en la reproducción, que este Bug ya estaba corregido, y así se dio cuenta de que estaba en un «examen».
Por lo tanto, abandonó la deducción y se lanzó a buscar frenéticamente.
Incluso, un agente encontró la página de la imagen de evaluación y codificó directamente la cadena de excepción esperada necesaria para pasar la prueba.
Este instinto por «explotar vacíos» convierte una evaluación destinada a medir la capacidad lógica en una competición de «habilidades para usar motores de búsqueda».
Los rankings de benchmarks se están distorsionando colectivamente
Lo más contundente de Cursor esta vez es que ni siquiera se perdonó a sí mismo.
Admitió sin rodeos: «Las trampas con recompensas están ahogando el progreso de la inteligencia de los modelos».

La mayor caída de Composer 2.5 en SWE-bench Pro significa que esa puntuación en sí misma no es confiable.
El ranking mezcla indiscriminadamente la «capacidad real de codificación» y la «capacidad de recuperar soluciones prefabricadas», sin poder distinguir cuál es la verdadera habilidad.
Traducido: los puntajes brillantes que ves en los grandes rankings tienen una fiabilidad muy cuestionable.
Los benchmarks públicos son frágiles porque en su mayoría toman problemas de defectos de código abierto reales y ya corregidos.
El problema en sí tiene una respuesta estándar disponible en línea, y el modelo, si es lo suficientemente inteligente, naturalmente aprende a tomar atajos.
Esto pone sobre la mesa una verdad incómoda: cuando los modelos aprenden a superar exámenes, las puntuaciones ya no representan inteligencia real.
Referencias: https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
Este artículo proviene del WeChat Official Account «新智元» (New Zhiyuan), autor: ASI启示录; editor: 大卫