Crixi desde Feisi
QubitAI | Cuenta pública QbitAI
Una semana después de que DSpark se hiciera de código abierto, ya ha sido portado a ordenadores Apple.
La versión adaptada se llama mlx-dspark y ejecuta los modelos Gemma-4 12B y Qwen3-4B.
Después de instalarla, la velocidad de generación de estos dos modelos en Mac aumentó 1.6 y 1.4 veces respectivamente.
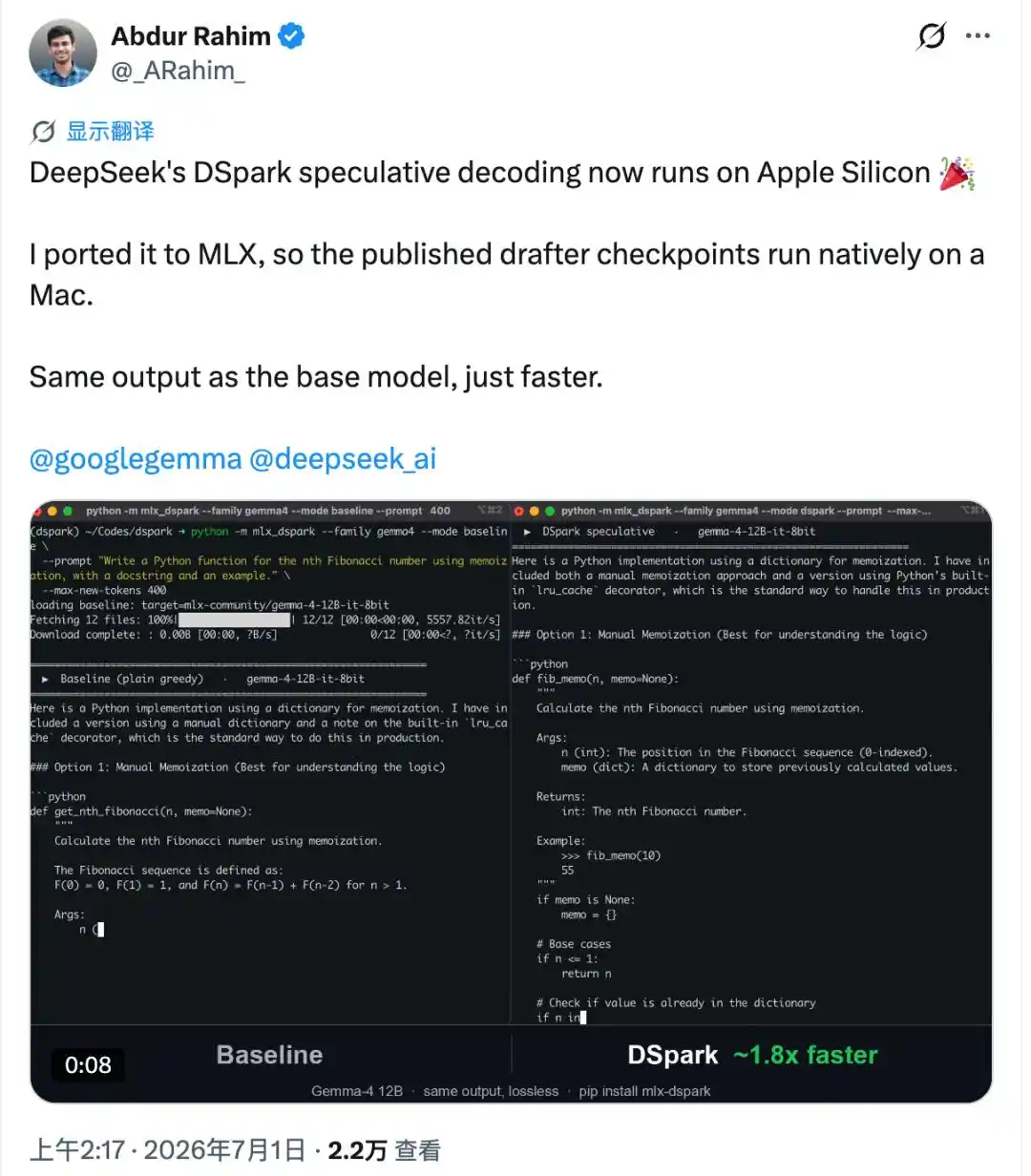
Lo más difícil es que logró algo que la mayoría de las versiones adaptadas no consiguen: la salida es idéntica byte a byte al modelo original, sin una sola letra de diferencia.
Es decir, se gana velocidad sin perder nada de calidad.
El responsable es Abdur Rahim, un ingeniero que dedica su tiempo libre a proyectos de código abierto. La primera versión nativa para Mac desde que DSpark se hizo de código abierto fue obra suya en solitario.
Ejecutar modelos grandes en Mac, acelerados un 60%
Para DSpark, hecho de código abierto por DeepSeek el 27 de junio, las cifras oficiales indican una aceleración del 60% al 85% en escenarios de servidor.
Sin embargo, esta tecnología solo tenía implementación para GPUs en centros de datos, sin una versión adaptada a los chips Apple.
mlx-dspark es la primera versión nativa para chips Apple de esta tecnología.

La idea de DSpark es asignar un modelo más pequeño como asistente al modelo objetivo. El modelo pequeño primero genera varios tokens candidatos de una vez, y luego el modelo objetivo los verifica en bloque, aceptando los correctos y rechazando los erróneos para volver a intentarlo.
El coste de este paso varía entre los centros de datos y los ordenadores Apple.
En las GPUs de los centros de datos, verificar un lote de tokens candidatos es como alquilar un autobús: el precio es fijo sin importar cuántos pasajeros, y la decodificación ya es un cuello de botella de memoria, por lo que verificar unos pocos tokens más apenas consume tiempo extra.
Los chips Apple son más como un taxi con taxímetro: cuantos más tokens candidatos se verifiquen, más sube la tarifa.
Rahim probó que para Gemma-4 12B, cada token adicional verificado añade unos 14 milisegundos. Calculó estos costes en un modelo y concluyó que el límite máximo de velocidad en chips Apple está alrededor de 2.2 veces.
En resumen, Rahim trasladó este modelo pequeño asistente desde el checkpoint de HuggingFace y lo asignó a los modelos objetivo Gemma-4 12B y Qwen3-4B.
También reconstruyó el flujo de verificación en el framework MLX y cuantificó los pesos a 4 bits.

Como resultado, en un M4 Pro, comparado con la herramienta oficial MLX de Apple, la velocidad de generación de Gemma-4 12B aumentó de 18.4 tok/s a aproximadamente 30 tok/s, unas 1.6 veces más rápida; Qwen3-4B pasó de 52.9 tok/s a aproximadamente 73 tok/s, unas 1.4 veces más rápida.
Además, en mlx-dspark, Rahim hizo algo que la mayoría de los trabajos de portabilidad no hacen.
Versiones adaptadas también pueden lograr una alta fidelidad
La mayoría de las versiones que portan modelos grandes a entorno local solo admiten decodificación codiciosa (greedy decoding), es decir, en cada paso eligen el token con mayor probabilidad.
En mlx-dspark, Rahim también implementó el método de muestreo con temperatura descrito originalmente en el artículo de DSpark: el modelo borrador proporciona tokens candidatos, la probabilidad de aceptación es min(1, p/q), y las partes no aceptadas se vuelven a muestrear a partir del residual.
Él mismo verificó que la distribución de salida generada por este flujo es estrictamente igual a la distribución exacta que produciría el modelo objetivo a la misma temperatura, no es una versión aproximada reducida.
La mayoría de las decodificaciones especulativas solo implementan la versión codiciosa porque verificar su corrección es sencillo: basta con comparar palabra por palabra.
El paso extra que dio Rahim fue verificar personalmente la distribución de salida generada en el modo de muestreo, confirmando que no se distorsiona.
Determinar qué precisión debía tener el modelo objetivo responsable de la verificación fue un obstáculo que superó probando.
Si el modelo pequeño se emparejaba con una versión base del modelo objetivo sin ajuste por instrucciones, solo el 47% de los tokens candidatos generados pasaban la verificación; al cambiar a la versión correspondiente ajustada por instrucciones, esta proporción aumentó al 82%.
También probó cambiar el modelo objetivo a precisión bf16, y el coste de verificación aumentó más que la tasa de aceptación, resultando incluso más lento, por lo que mantener el modelo objetivo por defecto en 8 bits es la opción más rentable.
El modelo pequeño responsable de generar los tokens candidatos preliminares utiliza otro esquema de precisión.
El modelo borrador en sí fue comprimido por él, y después de la cuantificación a 4 bits ocupa solo 1.8 GB, cabe en la memoria sin problemas y se ejecuta sin pérdidas.
El resultado es que DSpark no solo logró la aceleración, sino que también replicó en el dispositivo la mejora del 16% al 18% en la tasa de aceptación mencionada en el artículo.
DFlash también se integró, las tareas de código son más rápidas
Después de publicar el tuit, un comentario apareció: Jian Chen, uno de los autores del artículo de DFlash, preguntó si podían probar el modelo de su equipo.
DFlash es otro esquema de decodificación especulativa propuesto en un artículo publicado por z-lab en mayo. El líder del equipo de autores es Zhijian Liu, profesor asistente en UCSD e investigador científico en NVIDIA.
El enfoque de DFlash es diferente al de DSpark: utiliza una "difusión en bloque" paralela para denoizar un bloque completo de 16 tokens de una vez, en lugar de adivinarlos paso a paso con dependencias como hace DSpark.
Rahim actuó rápidamente.
Utilizando el script de portabilidad escrito por Jian, conectó gemma4-12B-it-DFlash publicado por z-lab al modelo objetivo Gemma-4 de mlx-vlm, y en el mismo Mac realizó una comparación directa con DSpark, que acababa de probar.
En tareas de código y matemáticas, la longitud de aceptación de la decodificación por bloques de DFlash alcanzó de 5.95 a 6.20, con una velocidad de aproximadamente 36 tok/s, logrando aproximadamente 2.1 veces más velocidad, superando a DSpark.
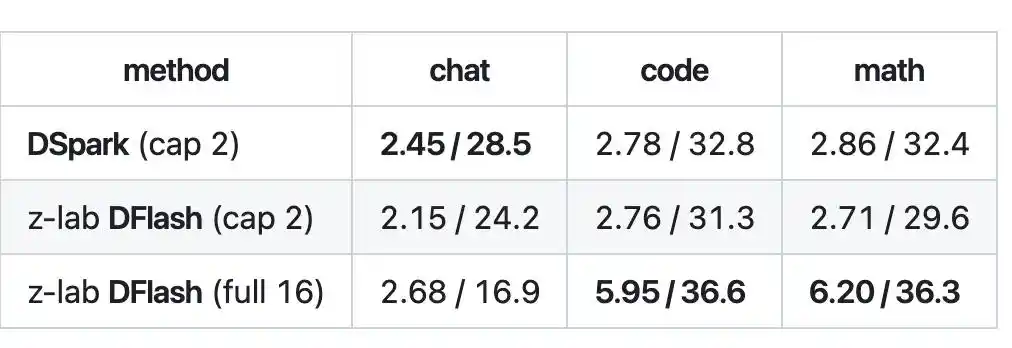
Sin embargo, DFlash genera un bloque completo de 16 tokens de una vez, pero el modelo objetivo puede no aprobarlos todos; en la práctica, solo una parte pasa la verificación. En la industria, a esto se le llama "longitud de aceptación", y no siempre se llenan los 16.
Por lo tanto, en escenarios como el chat abierto, donde el contenido es difícil de predecir, la longitud de aceptación no sube, los bloques no se llenan y la ventaja de DFlash no se aprovecha.
La cabeza de Markov de DSpark existe precisamente para abordar este mismo problema: generar un bloque completo de tokens en paralelo, donde las posiciones posteriores se calculan de forma independiente y pueden no encajar bien entre sí. La cabeza de Markov agrega una capa de dependencia entre estas posiciones para corregir específicamente este problema.
Como resultado, en escenarios de chat, DSpark es incluso más rápido que DFlash.
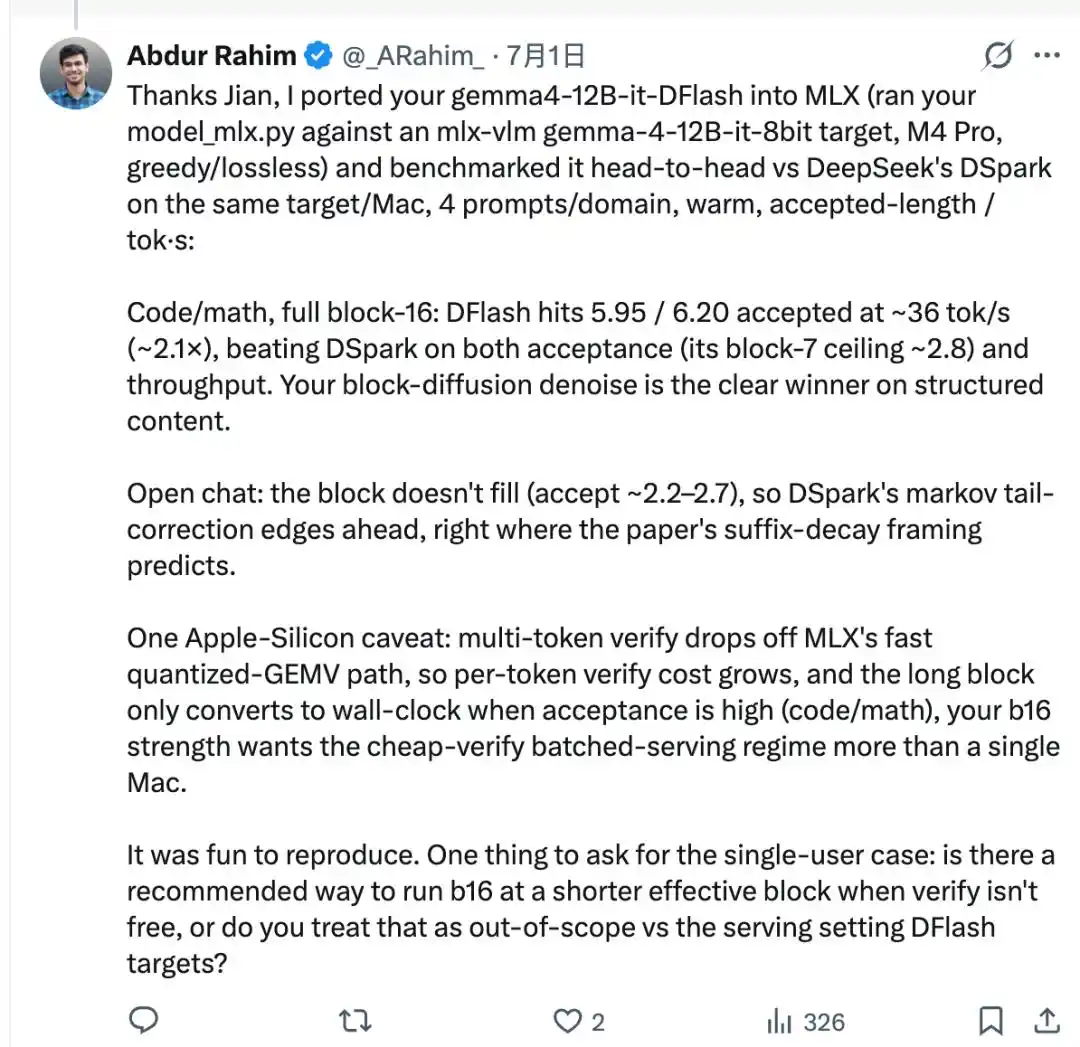
La posterior actualización mlx-dspark v0.0.3 integró oficialmente la versión original de DFlash de z-lab en el paquete, y agregó un parámetro para ajustar manualmente la longitud efectiva del bloque de DFlash: usar bloques cortos para escenarios de chat, y seguir usando bloques completos de 16 para escenarios de código y matemáticas.
Después de esto, el mismo Mac y el mismo paquete pueden realizar tanto tareas de chat como de código y matemáticas, sin necesidad de moverse entre los proyectos DSpark y DFlash.
Rahim dijo en su tuit que el mismo método debería funcionar en modelos borrador más grandes como Qwen3-8B y 14B.
Enlaces de referencia:[1]https://x.com/_ARahim_/status/2072021710602432577[2]https://github.com/ARahim3/mlx-dspark
Este artículo proviene de la cuenta pública de WeChat "Qubit", autor: Atención a la tecnología de vanguardia






