A medida que las capacidades de los Agentes de Código LLM siguen mejorando, cada vez más investigadores se dan cuenta de que es hora de dar el siguiente paso hacia tareas de largo alcance que se acerquen más a las necesidades del mundo real. Esto ha dado lugar a benchmarks de evaluación de tareas de largo alcance como NL2RepoBench y BeyondSWE, entre otros. La expectativa del rol que deben asumir los Agentes de Código ha ido evolucionando gradualmente de ser meros mantenedores de repositorios a convertirse en arquitectos capaces de planificar y completar tareas de largo alcance para generar el código de todo un repositorio.
Recientemente, la Escuela de Inteligencia Artificial Gaoling de la Universidad Renmin de China completó una investigación relevante y publicó oficialmente el conjunto de datos DeNovoSWE, centrado en tareas de ingeniería de software de largo alcance, especialmente en la generación de código a nivel de repositorio desde cero.

Enlace al artículo: https://arxiv.org/pdf/2606.10728
Enlace al repositorio: https://github.com/AweAI-Team/DeNovoSWE
Enlace a los datos: https://huggingface.co/collections/AweAI-Team/denovoswe
Mediante mecanismos de Divide & Conquer y Critic & Repair, se construyó un conjunto de datos de alta calidad y se logró con éxito el escalado de tareas SWE de largo alcance. Así se construyó un conjunto de datos de alta calidad y de código abierto para tareas SWE de largo alcance que contiene 4.818 instancias reales. Este logro proporciona datos a gran escala para entrenar la capacidad de tareas de largo alcance de los Agentes de Código, mejorando significativamente su desempeño en dichas tareas.
El artículo también proporciona un método de filtrado basado en la puntuación de dificultad de los problemas, que mitiga eficazmente la compensación entre la proporción de problemas difíciles y la calidad de las trayectorias.
Los experimentos muestran que Qwen3-30B-A3B-Instruct, entrenado en DeNovoSWE, mejoró del 5.8% al 47.2% en BeyondSWE-Doc2Repo y del 4.3% al 23.0% en NL2RepoBench, demostrando una mejora significativa en la capacidad de generación de código a nivel de repositorio gracias a los datos de largo alcance.
Reconstruir un Repositorio Completo a Partir de un Documento
En el último año, con el escalado de datos SWE a gran escala como en Scale-SWE, los agentes de código han progresado rápidamente en tareas de ingeniería de software reales como SWE-bench. Pero a medida que los modelos se vuelven cada vez más hábiles para "arreglar un issue" o "corregir algunos bugs", surge una pregunta más crítica: ¿Realmente los agentes poseen capacidad de ingeniería de software de largo alcance? A juzgar por los resultados de modelos de vanguardia en BeyondSWE-Doc2Repo y NL2RepoBench, el efecto no es ideal.
El desarrollo de software en el mundo real a menudo no consiste en modificar una función o agregar una condición, sino en comprender los requisitos, planificar la arquitectura, crear archivos, diseñar APIs, manejar dependencias, conectar módulos y, en última instancia, hacer que todo el repositorio funcione en las pruebas.
En otras palabras, lo difícil es la generación a nivel de repositorio de largo horizonte: partiendo de un documento de tarea, generar un repositorio de software completo, ejecutable y verificable. Esto es precisamente lo que DeNovoSWE busca resolver.
Documentos de Tarea de Alta Calidad para "Generar un Repositorio desde Cero"
En la generación de documentación a repositorio, el documento no es solo un README, ni una simple lista de APIs. Esencialmente, es la única entrada de tarea para que el agente reconstruya todo el repositorio.
Un documento de tarea de alta calidad debe cumplir al menos dos criterios fundamentales.
Primero, debe estar bien organizado.
Las tareas a nivel de repositorio son naturalmente complejas, involucrando múltiples módulos, interfaces, configuraciones, estructuras de datos y flujos de interacción. Si el documento simplemente apila descripciones de funciones, el agente puede perderse fácilmente en la información fragmentada. Por lo tanto, el documento debe proporcionar primero una visión general clara del repositorio, luego dividir los capítulos por capacidades o flujos de trabajo, de modo que cada parte corresponda a un límite funcional claro.
Segundo, debe partir de una perspectiva de evaluación confiable.
El documento no puede ser demasiado escaso; de lo contrario, la tarea se convierte en un problema subdefinido, pudiendo obligar al modelo a adivinar de manera amplia para pasar la evaluación. Tampoco puede ser demasiado extenso, de lo contrario se filtrarían detalles de implementación y la tarea perdería su desafío.
Un documento verdaderamente de alta calidad debe describir los comportamientos clave en los que se basa la evaluación: incluyendo import path, APIs públicas, entradas y salidas, parámetros por defecto, comportamientos excepcionales, elementos de configuración, cadenas de patrón, campos de retorno, etc., y también describir la funcionalidad que aproximadamente debe cumplirse. Es decir, el documento debe ser suficiente para que el agente pueda reproducir comportamientos verificables, pero no debe convertirse en una copia del código de implementación.
Esta es la idea central de DeNovoSWE: hacer que los documentos sean legibles, realizables y verificables.
El Método DeNovoSWE
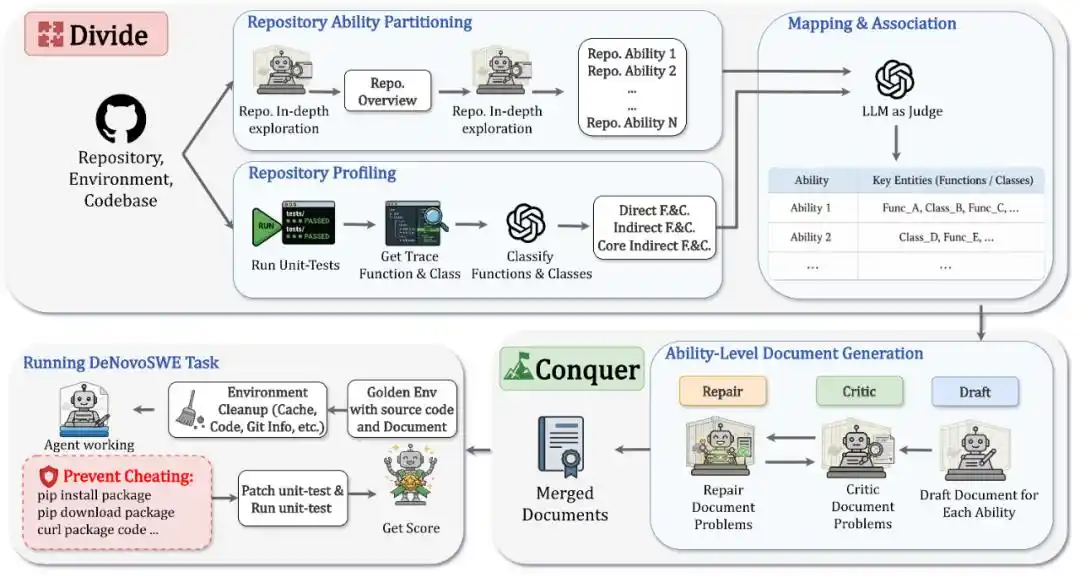
DeNovoSWE formula la tarea de "generar un repositorio completo a partir de un documento" como una tarea de ingeniería de software de largo alcance, a gran escala y verificable. No se escriben documentos manualmente, sino que se construyen automáticamente instancias de alta calidad mediante un flujo de trabajo sandboxed multi-agent. Todo el método puede resumirse en dos pasos: Dividir y Conquistar.
En la fase de División, el sistema primero analiza el repositorio objetivo y lo descompone en múltiples "capacidades del repositorio".
Cada capacidad corresponde a una función central o flujo de trabajo dentro del repositorio, como autenticación y conexión, lectura/escritura de datos, procesamiento por lotes, flujo de exportación, etc. Así, el problema originalmente enorme de generar un repositorio se divide en varios capítulos de documentos con una estructura clara.
Al mismo tiempo, DeNovoSWE ejecuta las pruebas unitarias originales y recoge un rastro de ejecución, identificando qué funciones, clases e interfaces afectan realmente a la evaluación, diferenciando así entre componentes directos, componentes indirectos centrales y componentes indirectos no centrales: las interfaces invocadas directamente por las pruebas deben registrarse en detalle; los componentes indirectos centrales que afectan el comportamiento observable también deben cubrirse; y las implementaciones internas no centrales pueden dejarse a la libre interpretación del agente.
En la fase de Conquista, DeNovoSWE utiliza el mecanismo Draft-Critic-Repair para generar documentos capacidad por capacidad. El agente Draft primero escribe un borrador; el agente Critic revisa si el documento omite APIs clave, contratos de comportamiento o información estructural; el agente Repair luego corrige el documento según los comentarios. Este ciclo se repite iterativamente hasta que cada capítulo de capacidad sea lo suficientemente claro, completo y esté alineado con la evaluación.
Finalmente, los documentos de las diferentes capacidades se fusionan en un único documento de tarea completo, que sirve como la única referencia para que el agente genere el repositorio desde cero.
Dificultad: ¿Por Qué es Esta una Tarea de Largo Alcance?
La dificultad de las tareas DeNovoSWE proviene de un cambio fundamental: ya no se trata de corrección a nivel de issue, sino de generación de todo el repositorio.
En las tareas SWE tradicionales, el agente generalmente se enfrenta a un repositorio existente, y solo necesita localizar el bug, modificar el código localmente y pasar las pruebas.
En DeNovoSWE, el agente se enfrenta a un entorno limpiado: el código fuente original y las pruebas se eliminan, el historial de git se restablece, y se limpian posibles canales de fuga como cachés, residuos de site-packages, paquetes pip wheel, productos de compilación temporales, etc. Esto significa que el agente debe depender verdaderamente del documento para completar la reconstrucción de todo el repositorio. Necesita planificar la estructura del proyecto, crear archivos de módulos, definir interfaces públicas, implementar interacciones entre archivos, manejar dependencias y configuraciones, y corregir errores constantemente a través de múltiples rondas de edición y retroalimentación de pruebas.
Cualquier desviación en una firma de API, un campo de retorno, un tipo de excepción o un comportamiento por defecto puede hacer que las pruebas fallen. Los errores también pueden acumularse en el proceso de largo alcance: un módulo diseñado de manera inadecuada en una etapa temprana puede afectar a múltiples archivos y cadenas de llamadas posteriores.
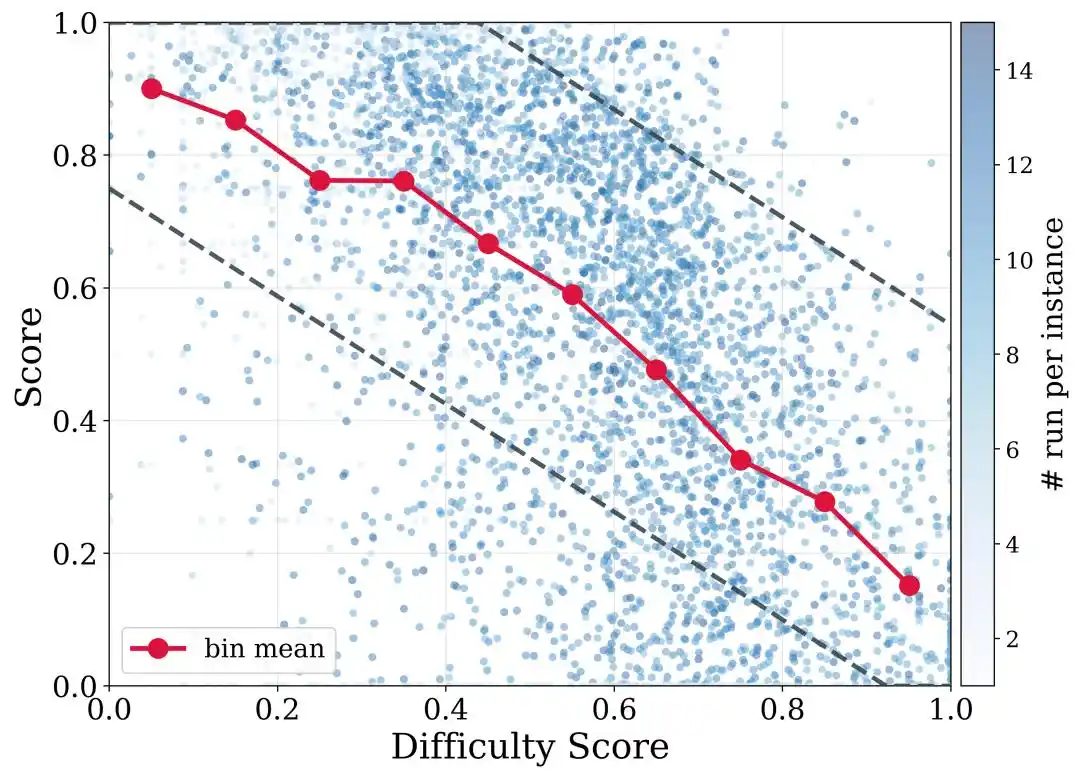
Para manejar aún más las diferencias de dificultad entre repositorios, DeNovoSWE también propone un filtrado de trayectorias consciente de la dificultad. En pocas palabras, las tareas fáciles deben requerir una tasa de aprobación más alta, mientras que las tareas difíciles no deben descartarse por completo por no alcanzar una puntuación perfecta. DeNovoSWE establece diferentes umbrales de filtrado para diferentes intervalos de dificultad según la complejidad estructural y la evaluación de dificultad del LLM, logrando así un equilibrio entre calidad y diversidad.
Esto es especialmente importante para tareas de largo alcance: cuanto más complejo es un repositorio, más difícil es pasar todas las pruebas de una vez, pero las trayectorias de repositorios difíciles, con puntuaciones bajas y éxitos parciales aún contienen valiosas capacidades de planificación e implementación de largo alcance.
Resultados Experimentales
DeNovoSWE finalmente construyó 4818 instancias de tareas de alta calidad de documentación a repositorio. Es un entorno de ingeniería de software de largo alcance ejecutable, evaluable y entrenable.
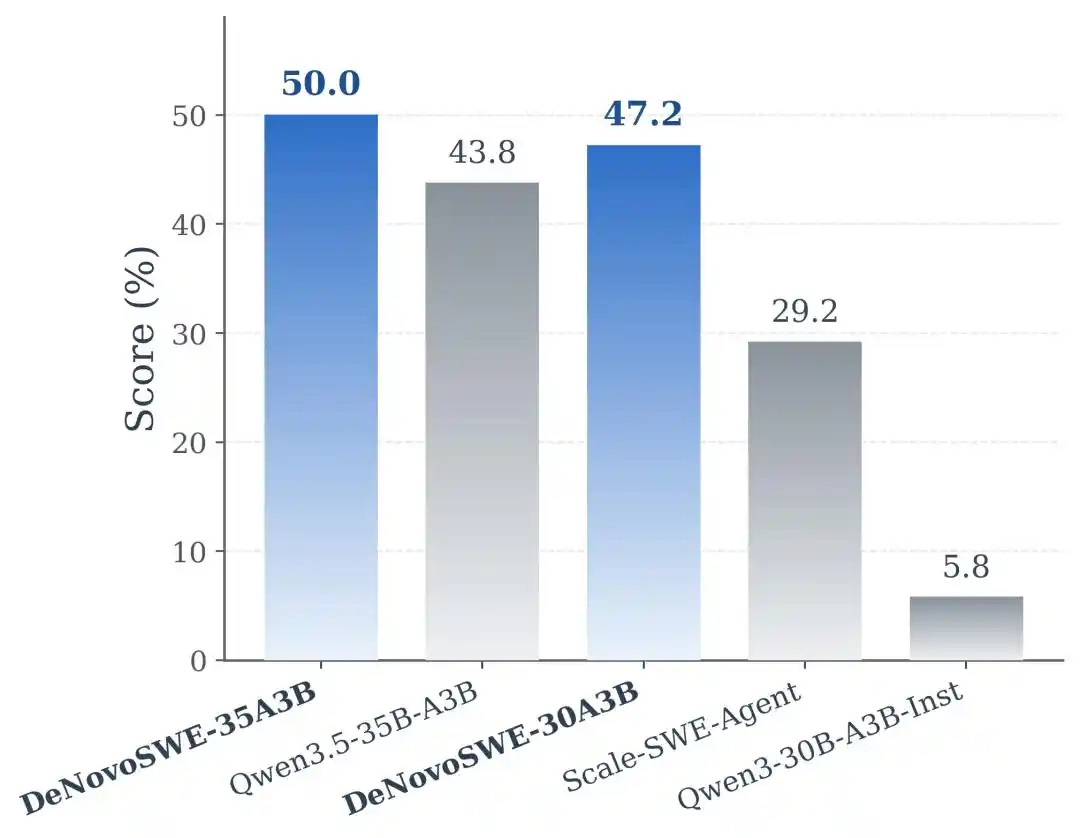
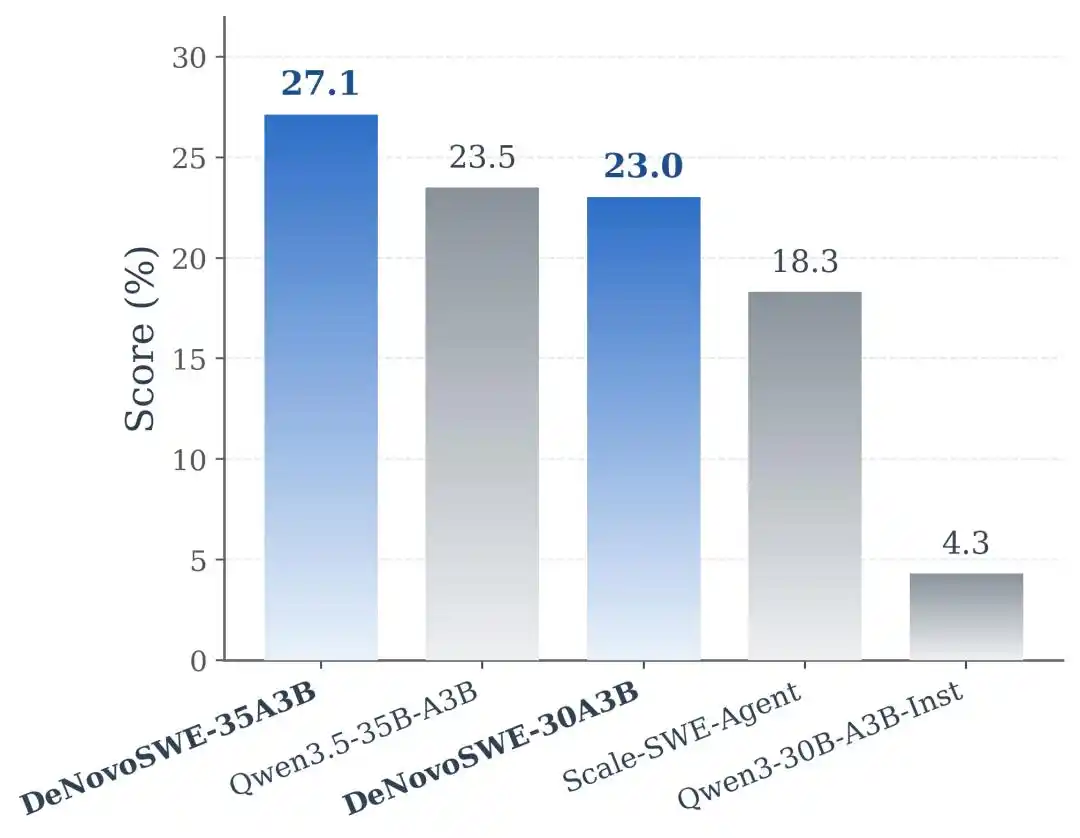
Los resultados experimentales muestran que DeNovoSWE trajo una mejora significativa en la capacidad de los modelos para generar repositorios de largo alcance. En Qwen3-30B-A3B-Instruct, el modelo original alcanzó solo un 5.8% en BeyondSWE-Doc2Repo y un 4.3% en NL2RepoBench. El modelo Scale-SWE-Agent entrenado con datos SWE convencionales a nivel de issue puede mejorar hasta el 29.2% y 18.3%, lo que indica que los datos SWE comunes sí tienen un efecto de transferencia. Pero cuando el modelo se entrena con DeNovoSWE, el rendimiento mejora aún más al 47.2% y 23.0%.
Esto indica que los datos orientados a "arreglar bugs" no pueden reemplazar completamente los datos de largo alcance orientados a "generar un repositorio completo". Para que un agente aprenda realmente ingeniería a nivel de repositorio, es necesario construir entornos de entrenamiento específicamente orientados a tareas de largo alcance.
En el backbone más potente Qwen3.5-35B-A3B, DeNovoSWE también aporta beneficios estables: BeyondSWE-Doc2Repo mejora del 43.8% al 50.0%, y NL2RepoBench del 23.5% al 27.1%. Esto demuestra aún más que los beneficios de DeNovoSWE no son una adaptación casual a un modelo específico, sino que provienen de los datos de largo alcance de alta calidad en sí mismos.
Conclusión
La próxima etapa para los agentes de código no consiste solo en corregir issues individuales más rápido, sino en ser capaces de comprender documentos, planificar arquitecturas, organizar módulos, implementar interfaces y, en última instancia, generar un repositorio de software completo y funcional.
DeNovoSWE sistematiza este objetivo convirtiéndolo en un conjunto de datos entrenable, verificable y escalable. Responde a una pregunta clave: ¿Qué tipo de datos puede realmente entrenar a un agente con capacidad de ingeniería de software de largo alcance?
La respuesta no es más código fragmentado, ni problemas más simples, sino tareas de generación de repositorios completos que sean de alta calidad, estructuradas, alineadas con la evaluación y protegidas contra fugas de información.
Partiendo de un documento, reconstruir todo un repositorio. Este es el umbral que los agentes de código de largo alcance necesitan superar.
Referencias: https://arxiv.org/pdf/2606.10728
Este artículo proviene del WeChat Official Account "新智元" (AI Era), editado por: LRST






