没有永远赚钱的赌徒,但有永远赚钱的赌场,那么在链上,可不可以也靠「投资赌场」来赚钱呢?在推出 JLP 后,Jupiter 似乎给出了一个答案。
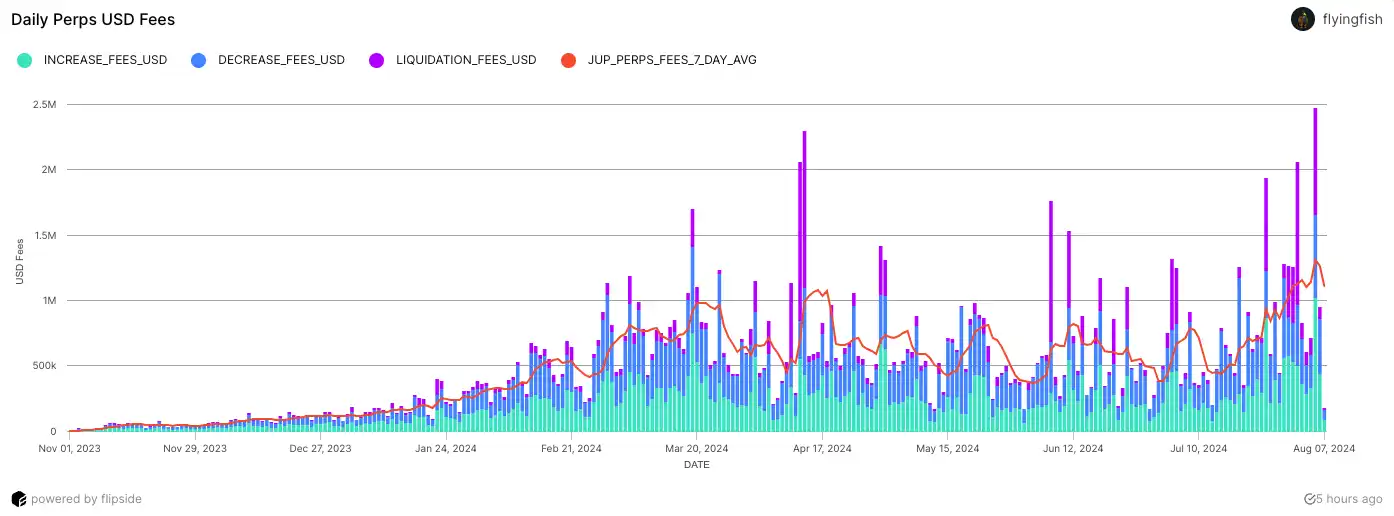
今年以来,Jupiter 的永续合约平台 JLP(Jupiter liquidity provider)成为了表现最好、收益最高的赌场之一。据Dune 数据,仅 8 月 5 日一天开仓费就达 247.5 万美元,而每笔开仓费仅 0.0006 美元。但据flyingfish 数据,从今年年初至今,在 Jupiter 上玩合约的玩家,总共只赚了 370 万美元,而他们给 JLP 贡献了 1.368 亿美元的手续费。
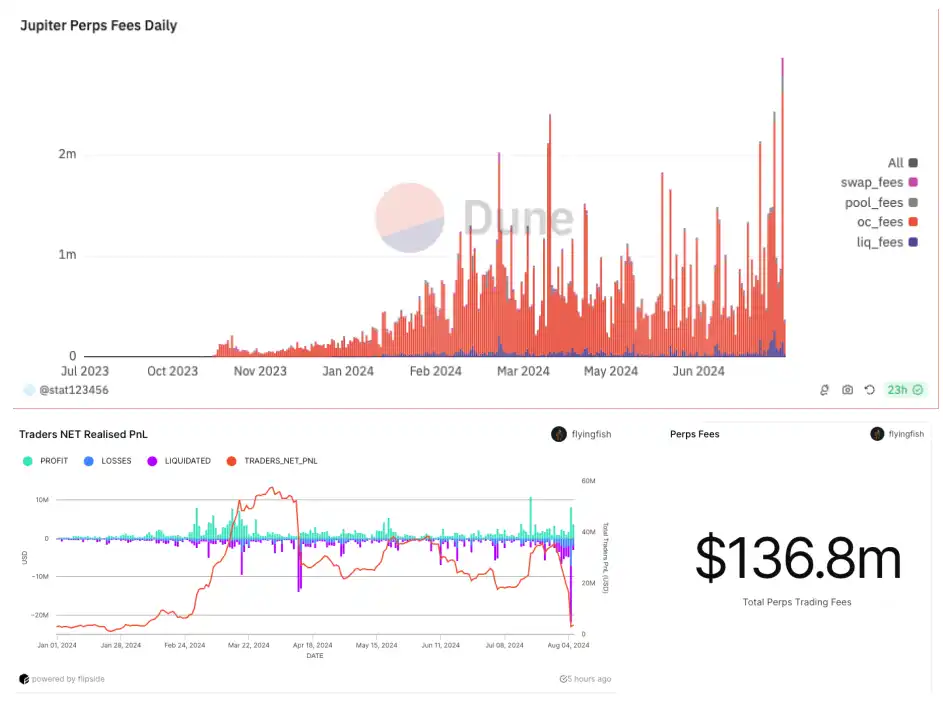
8 月 5 日大盘暴跌,加密资产全面崩盘,以太坊抹平年内涨幅,SOL 也一路下跌触及 110 美元。然而,在底层资产都是比特币、以太坊和 SOL 的情况下,JLP 跌幅却较底层资产小,不少人开始好奇,为什么 JLP 这么抗跌?
合约玩家:开仓那一刻起就在欠债
在 JLP 上,用户的交易对手方是平台本身,当交易者寻求开杠杆头寸时,他们从池中借入代币,由预言机直接喂价。这种模式也被称为「合伙开赌场」,即用户赚钱,平台亏钱。
JLP 池支持五种资产:SOL、ETH、WBTC、USDC、USDT,合约支持 1.1 x-10 0x 的杠杆倍数,从 JLP 池中借出相关流动性,在平仓后,交易者获取收益或了结亏损,并将剩余代币返还给 JLP 池。
以做多 SOL 为例,假设 SOL 价格 150 美元,开设 5 倍杠杆,即向池子中借出 5 枚 SOL,价值 750 美元。若 SOL 价格上涨至 160 美元,仓位升至 800 美元,交易者获利平仓。平仓后,交易者需归还最初的 750 美元本金,总盈利 50 美元。但对于平台来说,由于此时 SOL 上涨,本金价不足 5 枚 SOL,因此平台 U 本位资金不变,而币本位处于亏损状态。
若 SOL 价格下跌至 140 美元,仓位仅剩 700 美元,交易者止损平仓,因此交易者需将剩余 700 美元的资产还给平台,并补交 50 美元。由于 SOL 下跌, 50 美元对应的 SOL 数量增加,平台币本位处于盈利状态,U 本位资金依旧不变。同理,做空 SOL 则需借出稳定币。
JLP 与一般永续合约最大的不同点可能就在于,后者可能会出现负费率的情况,为了让永续合约的价格贴近现货价格,平台会补贴利率,但是在 JLP 的情况下,并不存在平台补贴。
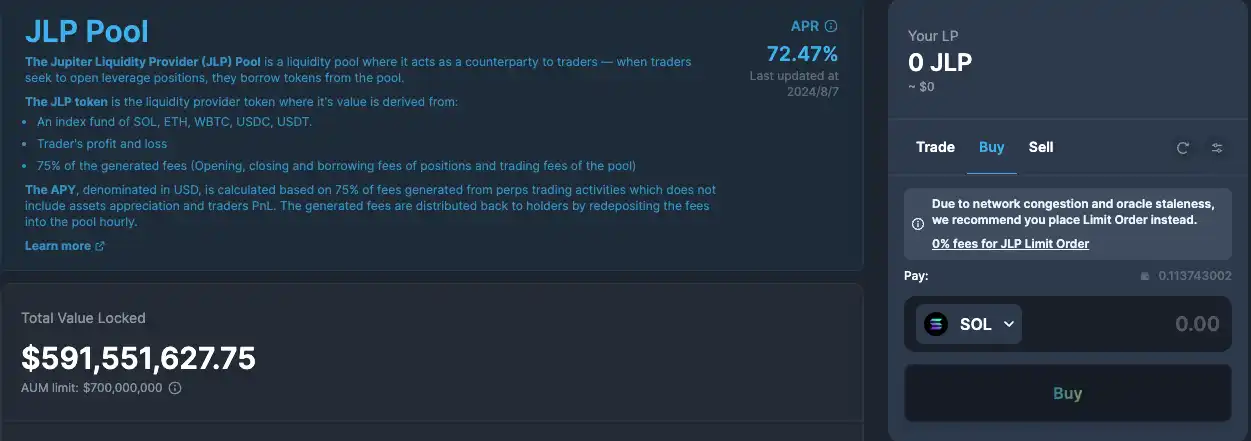
无论盈利还是亏损,开仓本金都来自 JLP 平台,因此,无论做多还是做空,从开仓那一刻起,交易者就在欠平台的债。据JLP Pool页面显示,目前 JLP 的 APR 为 72.47% ,但该数据每周更新一次,与实际收益有所差距。
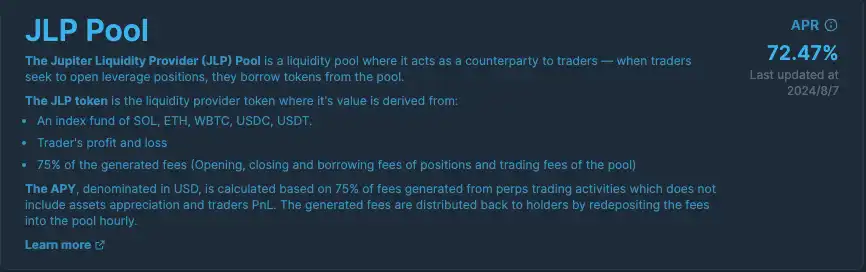
可直接在合约交易页面手动计算,不同池子的利率不同,即下图中的借款费率(Borrow rate)。若以 SOL 的利率来算,每小时 0.0028%(x24 小时 x365 天),年化达 24.53%,同理,以太坊年化 16.64%,比特币年化 44.68%,即总年化为 85.58%。

从左至右分别是 SOL、ETH、wBTC 的合约相关费用
JLP 投资者:收益与亏损都小于底层资产
交易产生的费用会反映到平台代币 JLP 上。据官方介绍,JLP 的价值来自三个方面。
一是建仓、平仓、借贷费用以及资金池交易费用的 75% 。由于能拿到平台手续费分成,因此这部分的 JLP 净值基本处于上涨状态。
二是来自 5 种底层资产,理论上(下图中的 Target Welghtage),一枚 JLP 价格由 44% 的 SOL、 10% 的 ETH、 11% 的 WBTC、 26% 的 USDC 和 9% 的 USDT 组成。在官方平台页面上也会根据这些因素计算出 JLP 的净值,目前为 3.18 美元。
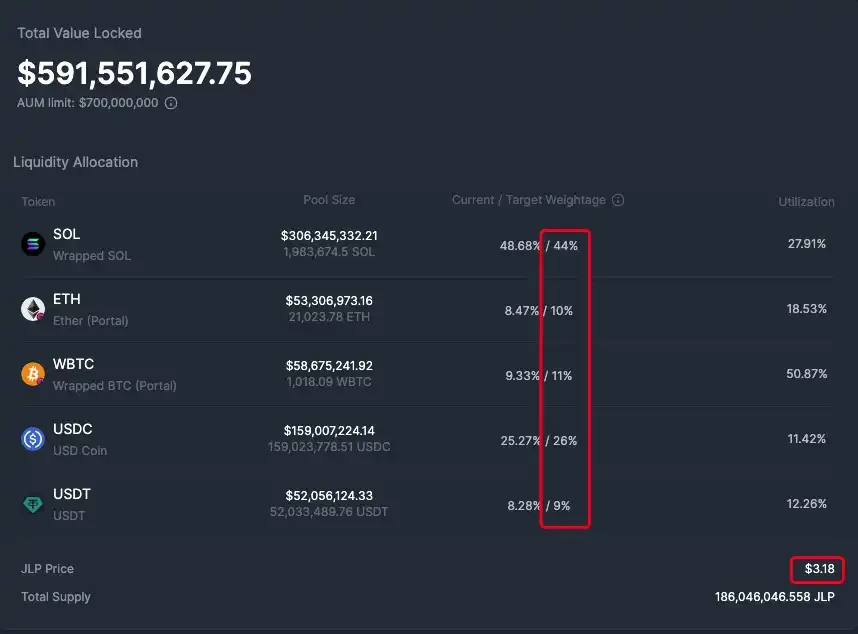
SOL、以太坊和比特币的上涨与下降也会让 JLP 随之变化。因此有社区成员认为,逢低抄底 JLP 是个不错的选择,不仅可以吃到底层资产的涨幅,又能吃到平台手续费。
然而仔细对比 JLP 和其余资产的涨跌幅可发现,JLP 的波动都要更小。最主要的原因就是 JLP 的价值组成中, 35% 来自稳定币(USDT 和 USDC),而稳定币的价格并不会出现剧烈波动。
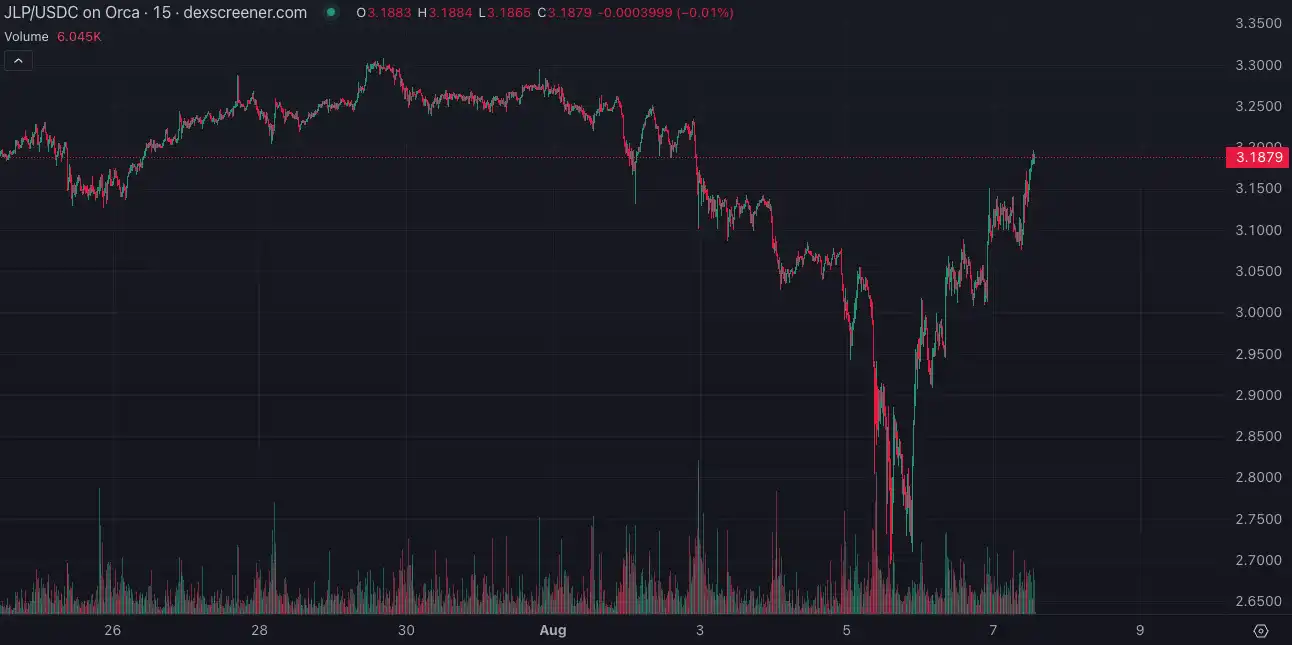
为了更具体比较 JLP 涨幅,DeFi 研究员 @22333D计算了 5 月 7 日至 5 月 19 日,JLP 与等份额的 SOL、以太坊和比特币的价格变化,发现 JLP 涨幅是最小的,其中 JLP 涨幅 5.3% ,而对应的 SOL、以太坊和比特币涨幅总计 6.8% 。
@ 2233 3D 解释,不足的部分可能来自 JLP 平台的币本位亏损。这也是 JLP 价值的第三部分来源,即交易者盈亏,其与 JLP 价格成负相关。假如一个交易员赚了非常多钱,那 JLP 的净值就会下降,相当于 JLP 的资产组成被合约玩家赚走了,反之亦然。
虽然短期来看,平台也会处于亏损状态,但据flyingfish 数据,自今年以来,JLP 的盈利总体上大于亏损。
把 JLP 当理财?
目前,可以直接在 JLP 官网通过 Jupiter 现价单购买 JLP,实现 0 手续费。购买的一部分 JLP 来自 LP 提供,一部分是新铸造的 JLP。当 JLP 达到 TVL 限制(7 亿美元)时将停止铸造,目前 TVL 达 5.91 亿美元。
@ 2233 3D 指出,如果用 SOL 购买 JLP,那可以等同于把 56% 的 SOL 换成了稳定币、以太坊和比特币。再用占 JLP 总仓位 35% 的资金量做多 SOL,就可以用对冲的方式实现 SOL 的理财。
如果用 USDT 或 USDC 购买 JLP,可以用占 JLP 总仓位 44% 的资金量做空 SOL, 10% 做空以太坊、 11% 做空比特币,这样其实就把 JLP 变成了一个稳定币本位的理财产品。
除此之外,JLP 也有别的套利玩法,比如在 Solana 借贷平台 Kamino 存入 JLP,借出稳定币后再买入 JLP,实现杠杆挖矿。但正因为 JLP 的赌场因素使其价格存在不可控风险,无论是作为合约玩家或是代币投资者,均需谨慎处理,DYOR。





