That's right, AI is still in an accelerated sprint.
In 2016, deep learning had only been exploding for a year before it almost stagnated. In 2026, after four years of explosive growth, large models still haven't hit their ceiling.
At the 2026 BAAI Conference, Guangzhui Intelligent observed that from models to software/hardware to products, everything is striving for AI to 'run' from the digital world into the physical world.
On one hand, Scaling Law continues to function steadily, propelling the ongoing development of large language models and multimodal models. The AI industry has entered a phase of pursuing World Models. However, issues like current technical routes and data remain unresolved, likely requiring at least 3-5 more years of exploration.
On the other hand, breakthroughs in Agents are accelerating the deployment of AI in real-world scenarios. As Agents have reached a usable stage, the industry is advancing their application in areas like healthcare and meetings. To transition Agents from usable to useful, software-hardware co-design has become key. At the exhibition booths of the BAAI Conference, chip manufacturers occupied 'half the room,' with nearly all leading domestic AI chip companies present.

"We are standing at a new historical inflection point. Artificial intelligence is no longer just a tool transforming a specific industry but is becoming the underlying force reconstructing the world. AI Coding, autonomous agents, and model self-evolution are opening up possibilities for creating AI. World Models, embodied intelligence, and robotics are extending intelligence from the digital world to the physical world," said Wang Zhongyuan, President of the Beijing Academy of Artificial Intelligence (BAAI).
What exactly is happening within this wave of reconstruction by this underlying force?
On the first day of the BAAI Conference, the guests present offered this answer: AI is moving from 'being able to chat' to 'being able to work.' Scaling Law persists, World Models with unconverged technical directions become the focus of the next phase, while Agents have started transitioning from usable to useful, with many optimization challenges remaining.
AI Has Not Hit Its Technical Ceiling,
And Has Learned Self-Evolution
Over the past year, as high-quality internet text data was being exhausted, a pessimistic sentiment spread throughout the industry that 'Scaling Law is about to peak.'
In multiple forums at the BAAI Conference, the question 'Has the Scaling Law dividend diminished?' was frequently raised. Several guests denied this notion.
"I still firmly believe scaling is far from over," said Wang He, Founder and CTO of Galaxy Universal. "Looking back today, Scaling Law hasn't failed; it has just become more diversified."
Scaling continues to show its effect on a series of newly released large language models. Analyzing Anthropic's recently released Fable 5, Luo Fuli from Xiaomi suggested this model itself is a product of scientifically advancing scaling. It is the result of extending large models by combining three dimensions: parameter scale, synthetic data, and reinforcement learning.
"We speculate that Fable 5's parameter scale itself is likely several times that of the current largest open-source models. Additionally, it involved significant computational investment in Test-Time Scaling or reinforcement learning. Furthermore, synthetic data generated by humans and agents brought the data scale to a new order of magnitude," said Luo Fuli.
In the multimodal field, performance improvements brought by scaling are equally significant. Zhu Jun, Founder and Chief Scientist of Shengsheng Technology, stated that data quality, model size, and large-scale training all enhance model performance. With improved foundational model capabilities, models also learn physical laws and understand 3D scenes more efficiently.
While scaling continues to be effective, alongside the maturation of AI Coding and accelerated deployment of Agents, a trend of AI self-evolution is becoming evident, upgrading from writing code to autonomously completing product iteration updates.
"The foundation of the vast human digital world is largely constructed through code. With AI Coding making substantial progress and becoming mainstream, it means AI could gradually take over everything in the digital world," said Wang Zhongyuan.
Globally, using AI for product updates has become the norm.
"If the model determines an agent's capabilities, then the Harness determines the upper limit of those capabilities," said Li Jingqiu. "Its difficulty lies in further improving problem clarification, verification, and feedback on top of the model."
For example, relying solely on the model to understand a problem inevitably has limitations. The Harness needs to elaborate and enrich the user's simple one-sentence instruction so the model can better comprehend the requirement. This requires the Harness to leverage intent understanding. After receiving the task, it must design the subsequent workflow and then orchestrate the model to execute it. This process may require human intervention and correction, followed by checks before task completion.
World Models:
The Next Key Battleground for Large Models
Pushing outward along the boundaries of the digital world, World Models have become the next key battleground for large models.
"Currently, no single world model truly feels particularly impressive or solves all kinds of problems in the real physical world," said Wang Zhongyuan.
For World Models in their early developmental stage, the industry hasn't reached full consensus on the technologies involved. With technical routes not yet converged, a series of unresolved problems remain. Using data as an example, Wang Zhongyuan illustrated that whether video data, simulation data, or real-world physical data is needed, a clear methodological path hasn't been found yet.
Taking Galaxy Universal as an example, Wang He introduced their application of synthetic data at the event.
"Before the WAM (World Action Model) paradigm emerged, we conducted extensive experiments within the VLA paradigm using synthetic data, specifically for grasping tasks," said Wang He. "We used 1 billion frames of simulation data to prove: as long as you scale the data to this extent, you can achieve complete zero-shot learning. Give me any object in the real world, and it can handle the grasp."
Regarding the development progress of World Models, the BAAI predicts that 'at least several more years' are needed. The next three to five years will likely be a phase of continuous evolution and iteration for World Models.
Over the past few years, various world models with different technical routes have emerged in the industry, each progressing distinctively.
Taking multimodal world models as an example, Zhu Jun stated that video models and world models are closely related because world models need three capabilities: understanding and interpreting states, prediction, and action. Among currently accessible training data, video data is most relevant to world models.
With various technical routes diverging and industry consensus yet to form, the BAAI classifies world models into four categories:
First, language-centric world models, mapping other modalities and abilities into language space, including LLMs, VLMs, VLAs, etc.
Second, pixel-centric world models; video generation essentially predicts the next frame, but video generation models are not equivalent to world models, though they are related. The potentially very popular World Action Model (WAM) this year is evolving from a pixel-centric perspective.
Third, 3D structure-centric world models, including 3D reconstruction which focuses purely on the three-dimensional world.
Fourth, visual representation-centric world models.

Currently, BAAI is exploring a 'fifth' path – the fusion of language-centric and visual representation-centric approaches, namely latent space representation. This involves compressing information like text and images into a vector space to represent various states of the real physical world.
"Future unified latent space modeling will not be limited to visual space but encompass full-modal latent space. This is highly likely to be the true next possible path for world models," said Wang Zhongyuan.
At the conference, BAAI introduced the world model it is developing – WuJie · Physis-v0.1. Centered on physical space modeling to predict the next physical state, it is positioned as the world's first general-purpose world foundation model, emphasizing four key capabilities: 'physically correct, causally traceable actions, long-term temporal consistency, and general-purpose generalization.'
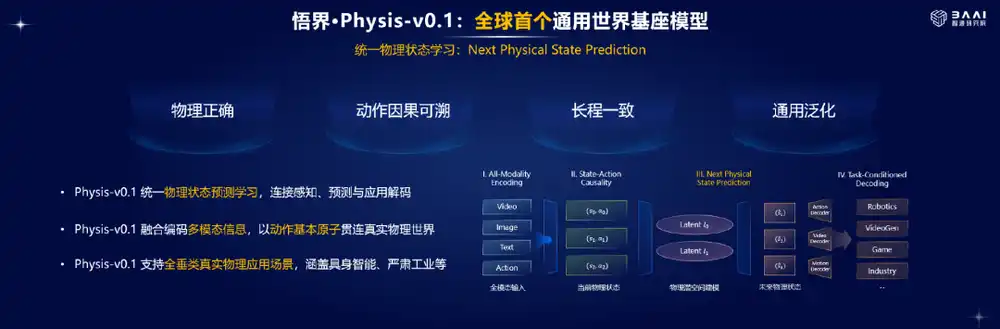
Currently, this model is still in the training phase. BAAI will continue to share progress in the second half of the year and will open-source the model upon training completion.
From 'Usable' to 'Useful':
Agents Face More Challenges
On the model side, progress in World Models drives the realization of physical AI; on the product side, Agents (Intelligent Agents) become the key products for AI to enter public life.
Since 2025, dubbed the 'Year of the Agent,' some impressive Agent products have emerged, showing signs of taking off. However, the unexpected surge in popularity of 'Lobsters' this year still came as a surprise.
Compared to last year when agents were mostly in an execution state, this year's agents have clearly become more proactive and capable, able to help users proactively execute more complex tasks.
At this year's BAAI Conference, BAAI also released four vertical-focused agents: BAAI Cardiac Agent, the world's first auxiliary diagnosis agent for cardiac magnetic resonance, aiding doctor decision-making by integrating multimodal capabilities and medical expertise; the autonomous research agent AREX for the scientific research field; SoulAgent, an agent helping users listen to meetings in real-time and capture key points; and a risk discovery agent targeting hazardous protein acquisition.
For example, regarding the meeting-listening agent, Guangzhui Intelligent tested its ability to summarize different meeting contents. SoulAgent did provide simple summaries of meeting content. While not as complete as minutes, the core viewpoints were accurate. This is particularly suitable for situations where parallel forum sessions overlap.

However, current agents still face numerous technical issues requiring further optimization. Yang An, President's Chair Professor at Nanyang Technological University, mentioned that to maintain and enhance agent capabilities, the most crucial aspects currently are related to context engineering, such as Memory, orchestration, etc.
At the agent sub-forum, Harness (literally meaning a horse's harness, referring to the entire engineering framework or environment built around an agent), which received little attention last year but gained significant popularity this year, became a high-frequency keyword mentioned on-site.
"If the model determines an agent's capabilities, then the Harness determines the upper limit of those capabilities," said Li Jingqiu. "Its difficulty lies in further improving problem clarification, verification, and feedback on top of the model."
For example, if relying solely on the model to understand a problem, limitations are inevitable. The Harness needs to elaborate and enrich the user's simple one-sentence instruction so the model can better comprehend the requirement. This requires the Harness to leverage intent understanding. After receiving the task, it must design the subsequent workflow and then orchestrate the model to execute it. This process may require human intervention and correction, followed by checks before task completion.
In short, like a real human assistant, every detailed step requires product refinement for the Harness to further improve the Agent's execution effectiveness.
Currently, Agents are still in the early stages of development. It is foreseeable that this industry has immense room for growth. Both improvements in model capabilities and solidification of engineering details will continue to enhance Agents' task-handling abilities.
This article is from WeChat Official Account: Guangzhui Intelligent , Author: Focus on Frontier Technology








