Noam Shazeer, the legendary AI figure whom Google brought back two years ago with a $2.7 billion deal, announced his departure from Google to join OpenAI.
Just now, Noam Shazeer confirmed this news on X. He stated that he is joining OpenAI and looks forward to working with the excellent team there. He also expressed that leaving Google was not an easy decision; he is immensely proud of the Google team and everything they have built together, and it has been an honor and a pleasure to work alongside these colleagues.
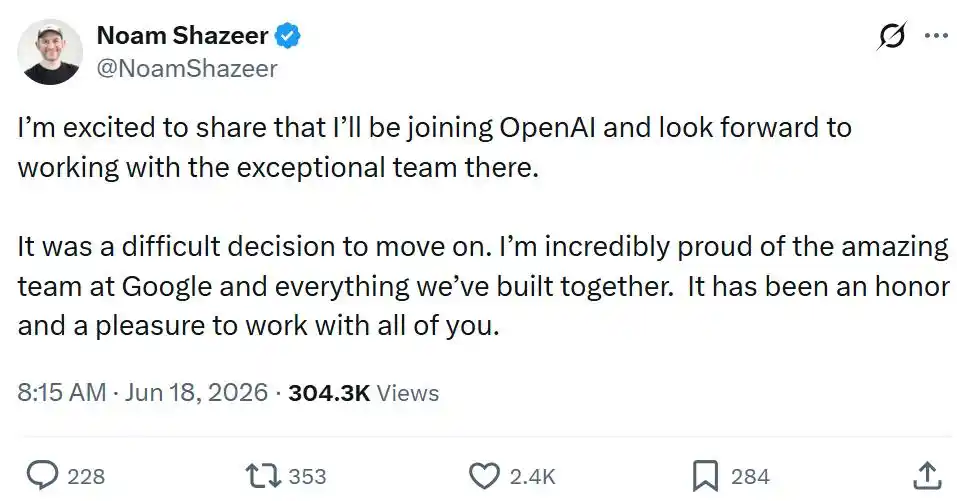
Subsequently, Sam Altman said, "From the very beginning of OpenAI's founding, Noam has been one of the people I most wanted to work with. It just took 10 years to finally get the chance. I believe the wait will be worth it!"
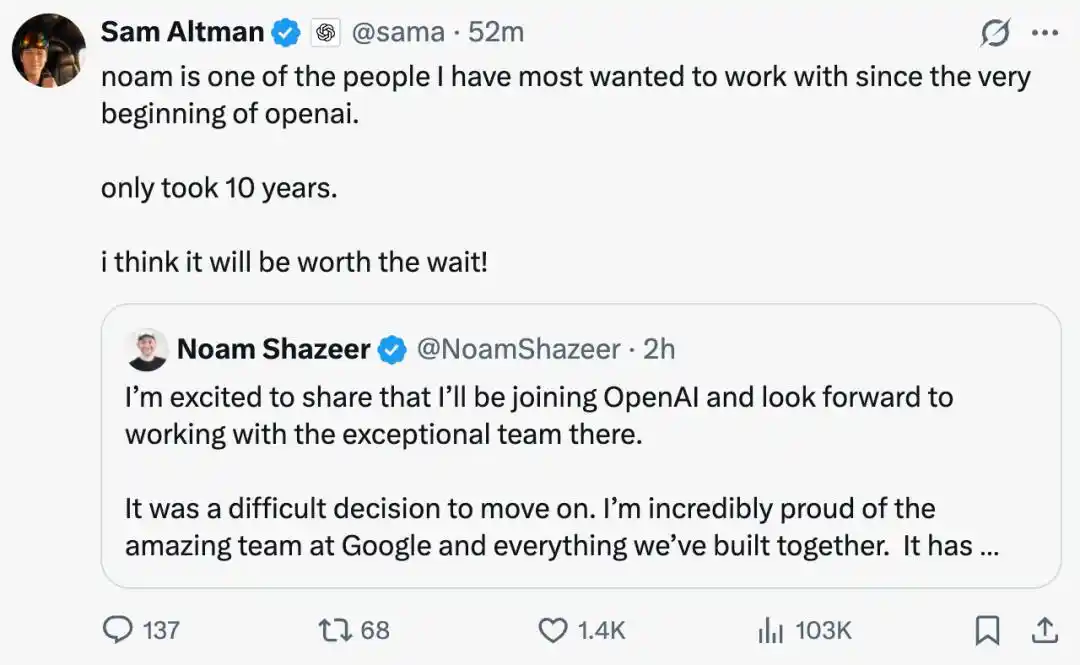
OpenAI research lead Mark Chen and others also responded on X: "A huge welcome to Noam Shazeer joining OpenAI as Head of Architecture Research! His research contributions in Transformer, MoE (Mixture of Experts), and efficient decoding have profoundly shaped the development of modern AI.
He not only holds a strong belief in achieving AGI but also has deeply considered insights on how to ensure its smooth development. Welcome, Noam!"
Noam Shazeer
Noam Shazeer is one of Google's most important early employees. He joined Google at the end of 2000, serving as a Principal Software Engineer responsible for early advertising systems.
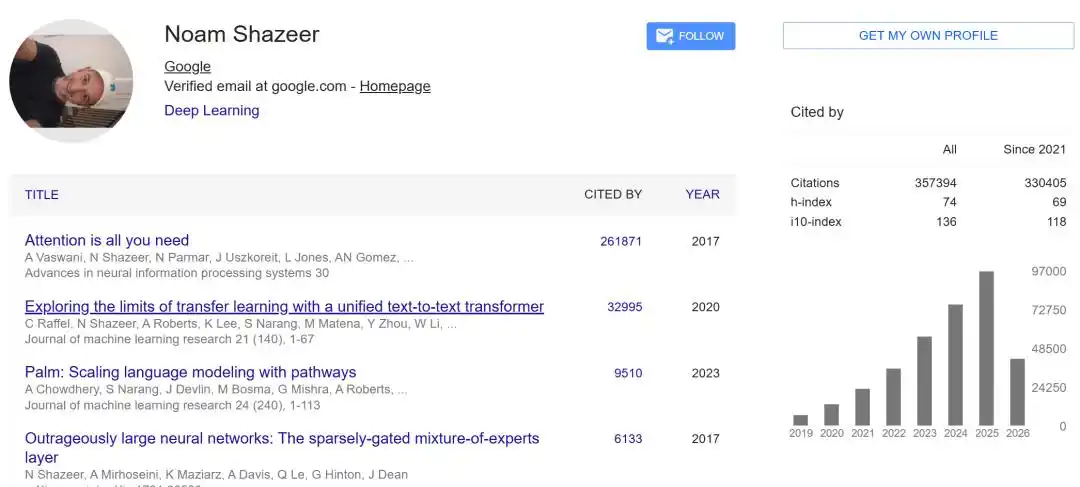
Noam Shazeer is no ordinary researcher. He is one of the co-authors of the seminal 2017 paper "Attention Is All You Need." The Transformer architecture proposed in this paper later became the most crucial technical foundation of the large language model era. From GPT and Gemini to Claude, and nearly all mainstream large models today, they all rely on the Transformer technical lineage.
More importantly, Shazeer's contributions extend beyond Transformer itself.
Long before large models truly entered the phase of scale competition, he had been focused on model scaling, sparse computation, and training of massive models. He co-proposed Sparsely-Gated Mixture-of-Experts, an important early foundation for the later MoE approach; Switch Transformer further pushed sparse expert models to the trillion-parameter scale. Today, MoE has become one of the key approaches for frontier models to increase parameter scale while controlling inference costs.
In 2021, Noam Shazeer left Google, disappointed by the bureaucracy at the search giant, and co-founded Character.AI with Daniel De Freitas. That company once became one of the most watched AI startups.
In 2024, Google reached a technology licensing deal with Character.AI and brought Shazeer and others back to Google DeepMind. Subsequently, he was appointed as co-head of Gemini technology, involved in Google's core large model project.

Now, in less than two years, he has turned to join OpenAI. This is truly harsh news for Gemini's development.
Many netizens believe that during the critical stage where Gemini still needs to continuously strengthen model capabilities and engineering systems, losing a figure like Shazeer will be a significant talent drain.

Others were more blunt in their jokes: Gemini wasn't that great to begin with; now with a core figure leaving, it's completely finished.
Another netizen joked: Google paid $2.7 billion for Shazeer's intellectual property. And OpenAI got these patents for free. This is the most favorable acquisition price in tech history.

In this AI talent war, Shazeer's addition is undoubtedly a significant victory for OpenAI.
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Focus on AI Big Shots.








