2026年Google I/O开发者大会,给人的感觉只有两个字:张狂。
不仅把AI智能体像填鸭一样,无缝塞进搜索、浏览器、手机、智能眼镜等所有核心流量入口,还连续甩出Gemini 3.5 Flash、视频模型Omni、全新AI助手Spark三张王炸。
亮完肌肉后,劈柴甚至炫耀般地宣布,Gemini月活破9亿;并同步官宣大幅降价。
意思再直白不过了:我比你强,还比你便宜。
这不是宣战是什么?
01
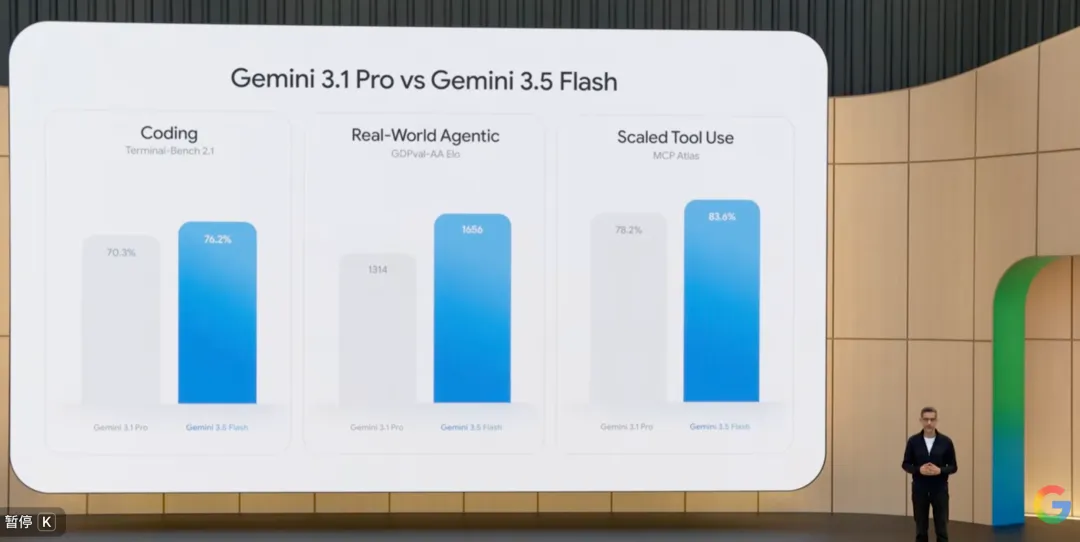
大会上最让人惊艳的,毫无疑问是Gemini 3.5 Flash的亮相。
正常来说,“Pro”代表中坚力量,“Flash”代表轻量级和快。
从模型参数量来看,3.5 Flash也确实小于3.1 Pro,但在几乎所有推理和编码基准测试上,前者的表现居然更优异:
复杂数学推理的GSM8K测试,3.5 Flash拿下了95.8%的分数,超越3.1 Pro的93.2%;代码生成能力的SWE-bench完整版中,3.5 Flash解决率达到38.4%,远远超过3.1 Pro的32.1%......
为什么?
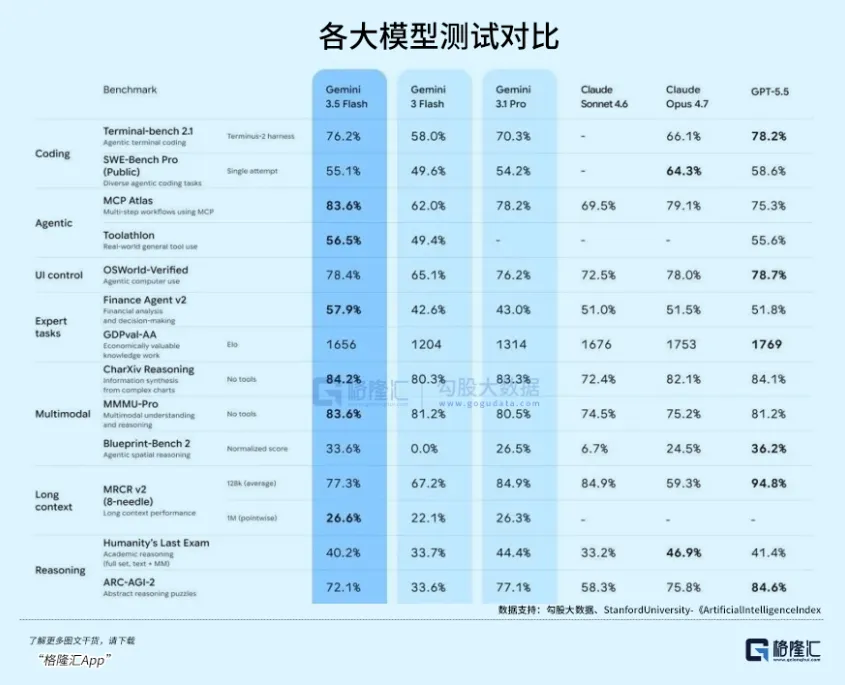
根据DeepMind发布的《Gemini 3.5 Technical Report》,最重要的核心技术有两个。
极限知识蒸馏:谷歌这次没有单纯靠堆算力来训练Flash,而是使用了从未公开的“Gemini 3.5 Ultra”作为教师模型,对Flash进行降维蒸馏。
根据DeepMind首席科学家Jeff Dean的推文解析,3.5 Flash在高质量逻辑链数据集上的微调比例,比上一代提升了400%。
这意味着它继承了超大模型的“逻辑脑”,而不是死记硬背的“知识库”。
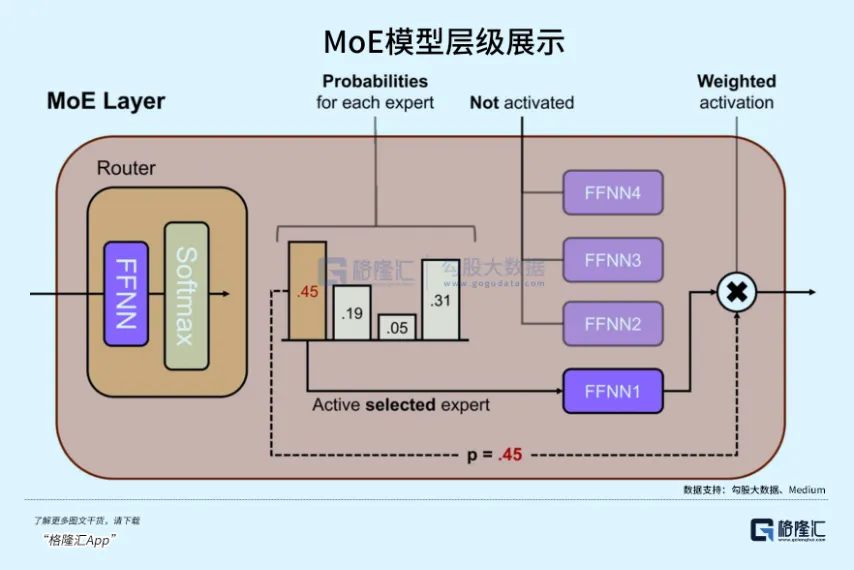
全新的MoE架构(混合专家模型):在3.5 Flash内部,谷歌采用了更细颗粒度的专家网络。
传统的MoE可能只有8个或16个专家,每次仅激活1-2个,足够支持万亿级参数规模的模型。
而根据a16z的2026年AI基建投资备忘录分析,3.5 Flash采用了256个微型专家,每次推理可激活其中最高效的4个。
所以它才能在保持极低激活参数量的同时,覆盖极其庞大的多模态特征空间。
在TTFT(Time to First Token,首字输出时间)指标上,3.5 Flash已经达到了65毫秒以内。
而人类眨眼一次需要100-150毫秒。
简而言之,当其作为智能体运行时,在人类的生理视角中,根本无法察觉到任何停顿。
对于需要频繁调用工具、进行多轮反思、极低延迟的开发者而言,这是真正完美的超级代理底座。
只有依托如此极致的工程优化,才可能在竞争剧烈的环境中,建立起“端侧落地”的统治力。
第一个,原生多模态Gemini Omni Flash。
Omni的意思是全能,对标早先的GPT-4o,只看名字,都能感受到火药味有多浓。
至少从表现来看,Gemini Omni Flash远比GPT-4o有资格用“o”这个字符。
早期的Sora或Gemini 1.5,基本都是缝合怪,即把语音转文本、文本再转视觉。
但这次发布的Omni,是真正的原生端到端多模态对齐。不仅能原生理解视频中的时间连贯性和物理规律,延迟也从400-600毫秒的行业平均水平降至120毫秒。
举个发布会上的例子:用户戴着摄像头倒水,水杯快满了,Omni能在水溢出前0.5秒说出“停停停!”
这种对现实世界物理状态的实时推断,看似简单,但意义重大:AI从屏幕里的聊天机器人正式进化为现实世界的辅助工具。
尽管只是初级阶段。
第二个,智能助手Spark。
根据The Verge专访Android工程副总裁的爆料,Spark 被赋予了Android 17系统底层的原生API操控权。
简而言之,你以前需要点开很多App才能完成的复杂流程,现在不需要动手,只需要吩咐Spark一声,它能帮你全部搞定,甚至能根据你的口吻、偏好去发送信息、整理邮件、汇总日程、追踪网页动态、识别账单隐性扣费、批量处理文档等等等等......
换句话说,以后有了AI助手,我们基本用不上App,任何复杂的操作都被简化成唯一。
第三个,智能眼镜。
为什么又是眼镜?
至少在谷歌方面看来,视觉和听觉的无缝接入,就是多模态大模型的最终宿主。
这副眼镜看起来没有任何花哨的外观,全部聚焦于实用能力:
重量仅4克的Micro-OLED全彩光波导镜片,透光率高达85%;
搭载自研轻量化Gemini端侧芯片,本地推理延迟≤12ms,无需联网即可完成实时翻译、图像识别、场景分析;
原生联动Spark智能体,同步手机、云端数据,实现日程提醒、实时翻译、环境预警等个性化服务。
简而言之,就是越过手机屏幕,把智能体通过眼镜塞进人类的第一视角。

内容实在太多,谷歌似乎一次性清仓了所有大招,向市场宣告了一个真理:
没有入口的算法,什么都不是。
卷大模型的参数、卷跑分的时代已经过去,单纯的模型提供商已经没有护城河,未来是“端+云+生态+硬件”的四维空间战。
把AI 塞进全家桶,其实是在重塑整个互联网的流量分发逻辑:从“用户主动搜索/点击”,变成了“AI 智能体主动分发服务”。
对广大的开发者和中小企业而言,这再好不过,因为底层算力和模型变得极其廉价,大家可以专心做应用层的创新。
但其它竞争对手,此刻恐怕只想破口大骂。
02
当劈柴在台上云淡风轻地宣布“Gemini月活跃用户正式突破9亿”时,在台下造成了不小的轰动。
9亿,比美国所有对手的MAU加起来都要多。
怎么做到的?
答案简单粗暴:硬塞。
谷歌不需要像独立AI公司那样去花广告费买量,只需要在Chrome浏览器的地址栏旁边加一个图标,在30亿台安卓手机的底部导航栏集成一个呼出快捷键,在Google Workspace里全量推送更新......
获客成本基本上等于0。
更关键的是,加下来一段时间,9 亿活跃用户每天用智能眼镜看商品时停留的眼神、用 Spark 处理事务时修正的逻辑以及与Omni视觉模型的交互,产生的海量高质量、多模态真实世界反馈数据,统统会成为滋养Gemini 4的养料。
这是个极其坚固的壁垒:模型越好用->用的人越多->产生的数据越多->模型变得更好用。
为了速速强化这个闭环,谷歌直接向所有对手宣布打价格战:AI Ultra套餐从249.99美元/月砍到99.9美元/月。
3.5 Flash的百万token输入价格干到了0.02美元,百万Token输出价格0.08美元。
这是个什么神仙价格?
对比一下,行业同级别模型的均价分别在0.15-0.2美元和0.6-1美元。
劈柴算了笔账:头部客户每天处理约1万亿个token。把80%的工作负载切到Gemini 3.5 Flash上一年,能省超过10亿美元。
为什么敢把AI卖成白菜价?
最大的依仗就是:垂直整合的算力基础设施。
包括OpenAI、Anthropic等巨头,看似风光,本质上其实还是“算力租客”,需要向微软、亚马逊买算力,而后者又要去给老黄交钱。
而谷歌有自家的TPU,再加上3.5 Flash极其变态的MoE稀疏激活效率,将算力成本压缩到了极致。
完全可以利用重资产优势去降维打击单纯的算法公司。
逻辑很清晰。
基础大模型正在快速商品化。就像水和电一样,你见过哪家自来水公司有暴利的?
谷歌不怕大模型本身不赚钱,因为可以通过搜索广告、云服务和安卓生态的抽成把钱赚回来。
但对于纯靠卖大模型API 为生OpenAI、Anthropic、Cohere、Mistral,这就不可能。
投资人现在大概很想按着奥特曼的头问:“谷歌的API价格只要你的十分之一,性能还比你好,你告诉我,你的商业模式怎么跑通?”
多个行业的竞争格局,将因此进入加速洗牌期。
AI厂商不必多说,必须尽快找到更便宜的算力来源,或者自己下场做芯片。
其次是仍在闭门造车的苹果。
智能眼镜+ Omni视频大模型+ Spark原生系统级接管的组合,毫无疑问已经威胁到了iPhone。
根据麦格理的《消费电子趋势预测报告》:未来三年内,基于视觉/语音的无屏交互时长占比,预计将从目前的8%跃升至35%。
如果用户习惯了用眼镜和语音完成日常工作和娱乐,屏幕的使用时长必然大幅压缩。
苹果如果拿不出足够惊艳的穿戴设备反击(Vision Pro太重太贵,注定只是少数人的玩具),其在移动互联网时代的入口垄断权将受到史无前例的挑战。
这不是迭代,是革命。
谷歌用技术、流量、价格三把刀,给所有对手下了战书。
此时此刻,还有人嘲笑它得了大企业病吗?






