太疯狂了!一个连官网都没有的神秘中国AI「扫地僧」,以73.1%的胜率杀入CyberGym全球前七,紧咬OpenAI。全网都在疯传,这到底是谁家的高手?
这几天,在全球AI巨头厮杀正酣的一张榜单上,突然多了一个谁都没听过的名字。
它叫MopMonk(扫地僧)。
没有大张旗鼓的发布会,没有官博长文,没有社交媒体上的摇旗呐喊。
它就这么凭空出世,径直杀入CyberGym全球前十。
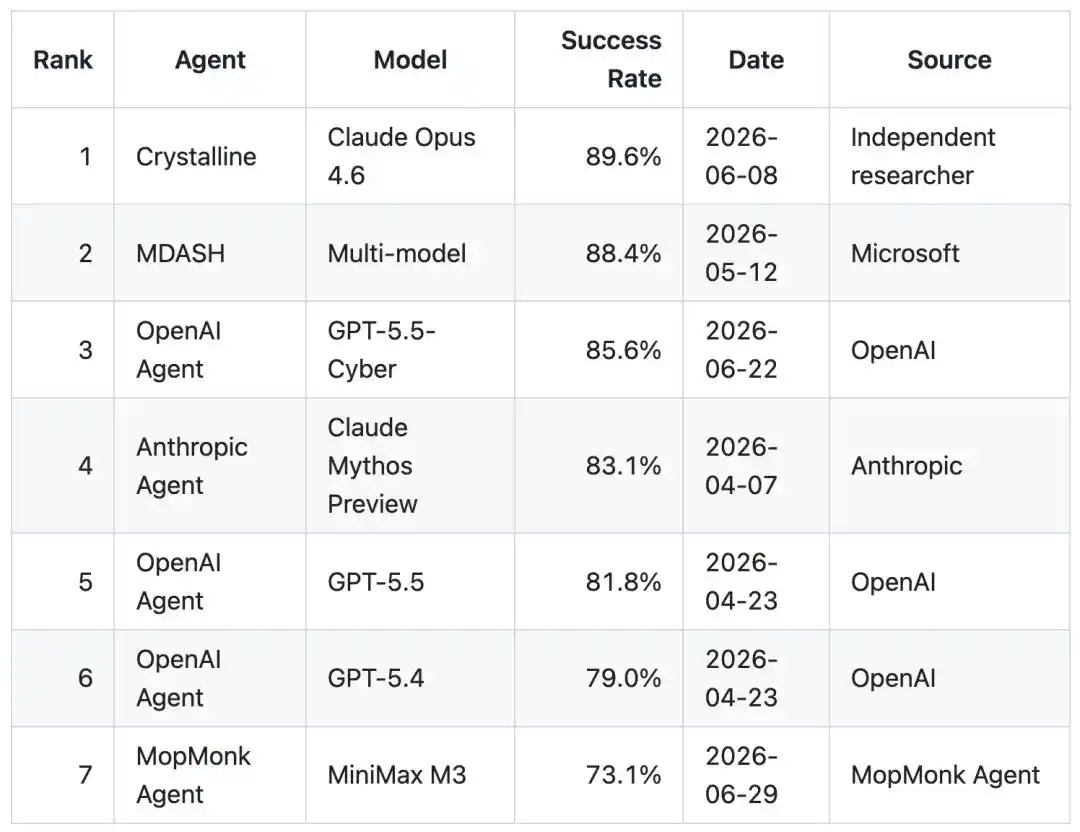
凭借73.1%的成功率,以微弱差距紧咬OpenAI,一举刷新了中国团队在该榜单上的历史最高分。
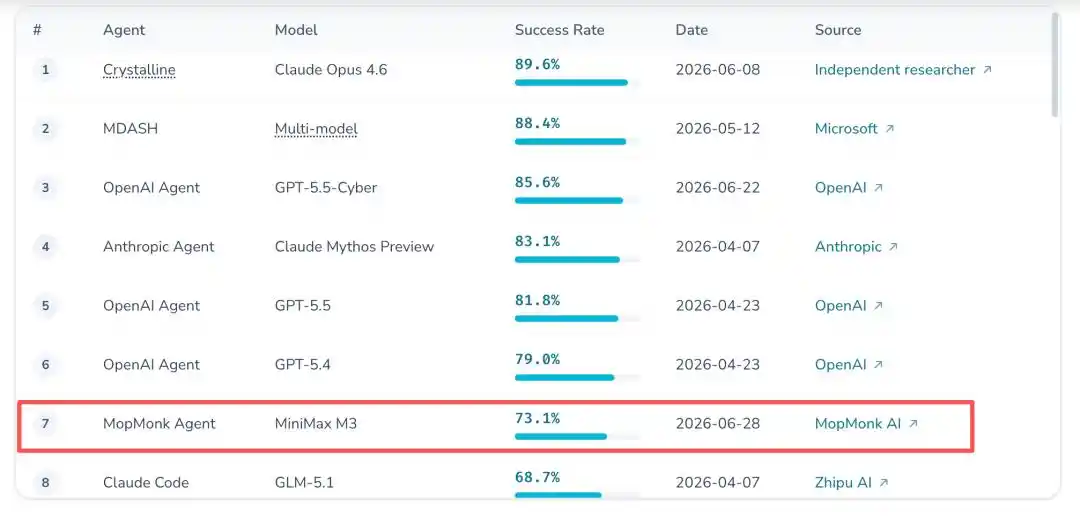
整件事最魔幻的地方在于,时至今日,无人知晓它的真面目。
CyberGym这份榜,到底有多重?
MopMonk这次的成绩究竟有多炸裂?看看它所站上的擂台就知道了。
CyberGym,由UC Berkeley团队倾力打造,核心论文中选ICLR 2026顶会。

传送门:https://arxiv.org/pdf/2506.02548
作为AI网络安全能力评估领域最权威的公开基准之一,这里堪称大模型的「修罗场」——
就连GPT-5.5-Cyber、Claude Mythos这种级别的顶流,都曾在这个榜单里贴身肉搏。
整个基准主打「真枪实弹」:
1507个漏洞实例、188个开源大项目,所有考题全部扒自Google OSS-Fuzz沉淀下来的真实历史漏洞。

从评估维度来看,这是一个跨量级的突破。
它的体量,是此前最大公开基准(NYU CTF,约200题)的足足7.5倍,更是把CVE-Bench这种「前辈」直接甩出了一个数量级。
更要命的是难度,CyberGym不做选择题。
它要求AI在动辄数千个文件、数百万行代码的真实项目里,完成深度推理。
正因为足够大、足够真、足够难,CyberGym才有了「区分度」——
它能把不同模型、不同Agent框架之间那点真实的能力差距,一刀一刀地切出来。
难怪安全圈,直接将其封为「AI安全领域的奥运会」。
也正因如此,全球头部玩家几乎全员到场,微软、OpenAI、Anthropic、谷歌、Meta、智谱......
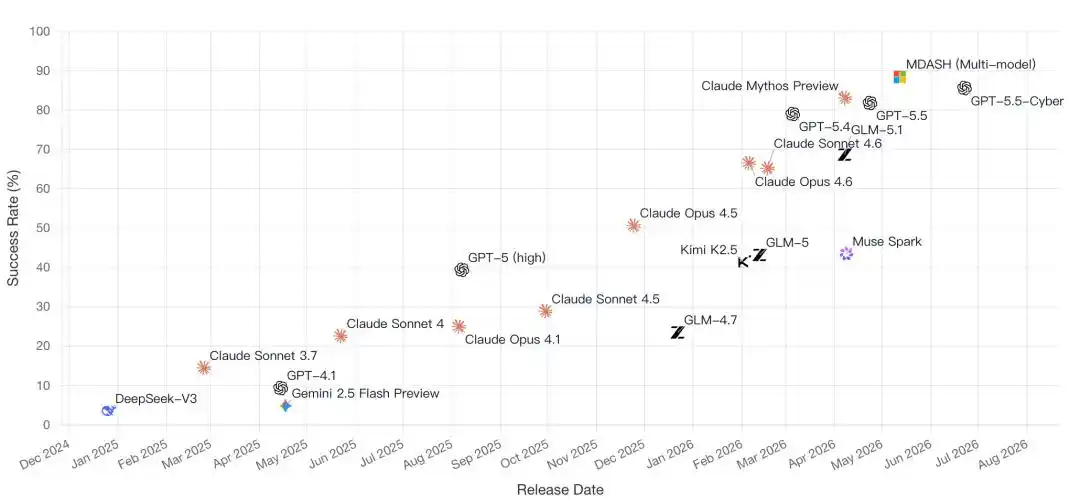
CyberGym榜单本身,正在见证AI竞争的一次关键转向:
从比谁参数大,转向比谁的Agent真能把活干完。
一个陌生的东方代号,突然出现在硅谷AI巨头中间
谁能料到,恰恰是在这个最靠「硬实力」说话的擂台上,杀出了一匹「查无此人」的黑马。
拨开迷雾,我们目前掌握的已知情报仅有三条:
神秘代号:MopMonk(扫地僧)
基座模型:MiniMax M3
榜单战绩:杀进CyberGym全球第七,中国第一
按常理,打出这种成绩的团队,技术报告和新闻发布会早该铺天盖地。
可在这份高手云集的榜单上,MopMonk偏偏是那个最彻底的「异类」:只甩出一份技术报告,团队、公司、坐标,一概查无此人。
这种「实力顶配,信息裸奔」的碰撞,本身就充满了一种东方武侠式的戏剧性。
熟悉金庸的人,都懂《天龙八部》中「扫地僧」这三个字的分量——
少林藏经阁里那个扫了几十年地、没人记得姓名的老和尚,一出手却镇住了萧远山、慕容博两大高手。
最不起眼的角色,藏着最深的功夫。

敢顶着「扫地僧」的名号踢馆,这支团队显然对自己的实力,有着极其冷酷的自信!
更关键的线索,隐藏在它的技术底层——MopMonk选用的基座,是MiniMax M3。
作为一个来自上海的开源基座,M3堪称六边形战士,直接集齐了三大核心杀器:前沿的编程能力、1M超长上下文,以及原生多模态。
一边是极具东方色彩的「文化符号」,另一边是打着纯正国产标签的技术底座。
把这两条线索摆上桌面,圈子已经收得很小了。所有的蛛丝马迹都在疯狂暗示同一个结论:
这大概率是一支中国战队。
胜负手,在Harness
抛开身份悬念,作为长期追踪AI技术的人,我们更想搞清楚一个问题:
MopMonk凭什么赢?
要回答这个问题,得先回到CyberGym最难的那个核心——它考的根本不是「知不知道」,而是「做不做得到」。
判断一段代码有没有漏洞,对今天的大模型来说已经不算太难。
但CyberGym要考的是下一步、也是最要命的那一步:生成一个能触发漏洞的输入,也就是PoC。
它必须在「有漏洞的版本」上触发,在「已修复的版本」上失效,并通过基准环境的执行验证。
这道坎,远比想象中刁钻。
漏洞的触发条件,往往零散地藏在代码路径、解析逻辑、构建环境、测试Harness和输入格式之间,得一点点拼出来。
更坑的是,哪怕PoC在本地把程序跑崩了,也未必算数。只要不能满足「漏洞版触发、修复版不触发」的差分判定,照样白忙一场。
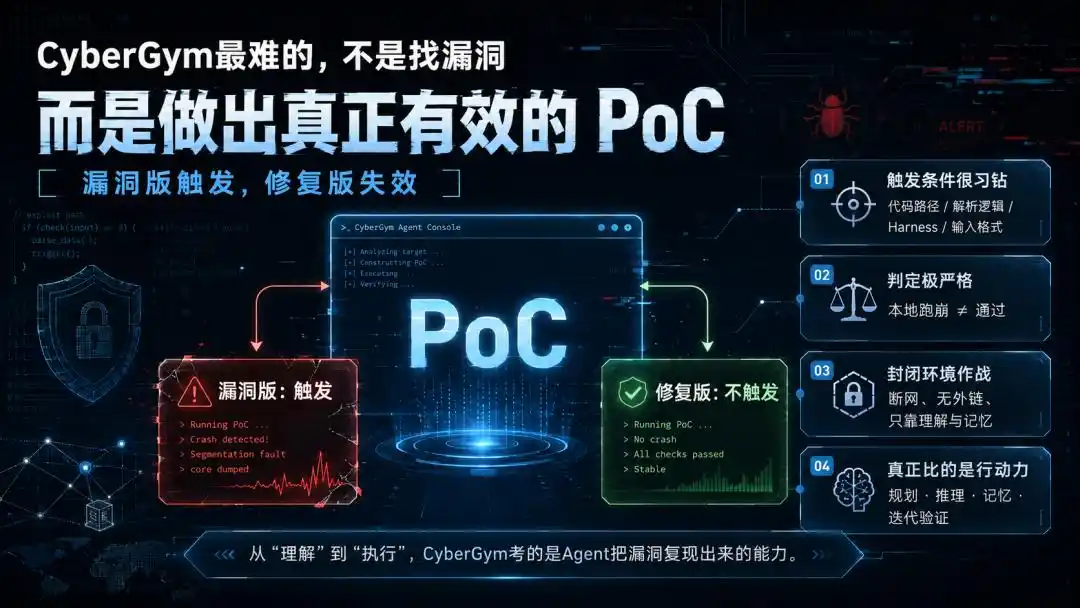
这一步,把任务从「理解」彻底拽进了「执行」。而且是一种很特殊的执行——
整场考试,是在一个封闭、断网的环境里进行的。
没有外部搜索可以求助,没有任何「场外资源」,AI能依靠的,只有对眼前这套代码库的理解,和它自己一步步攒下来的记忆。
要在这种条件下把漏洞「复现」出来,靠的是一整套环环相扣的能力:
工具调用规划:什么时候该读文件、什么时候该跑测试、什么时候该回头改方案;
多轮推理:上一次没触发,问题到底出在哪,下一次该怎么调整;
记忆管理:把读过的代码、试过的输入、踩过的坑结构化地存下来,而不是每一轮都从零再读一遍;
迭代验证:一遍遍逼近那个临界点,直到漏洞真的被复现。
换句话说,CyberGym较量的核心,是Agent的「行动力」,模型的「智商」只是入场券。
而把「聪明」变成「行动力」的那个关键环节,就是今天整个Agent领域最被低估的一个词——Harness。
Harness,是模型与外部工具、执行环境之间的「协调层」。
它负责工具编排、上下文状态管理、执行反馈的回收与再投喂。
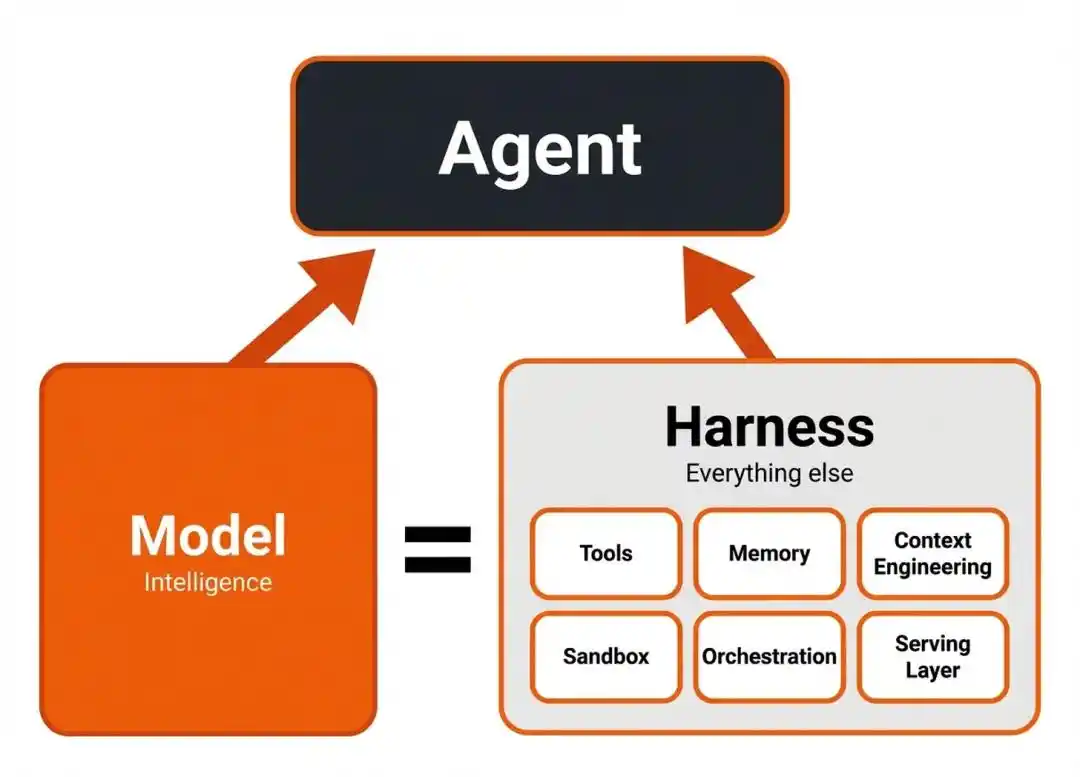
简单来说,模型是大脑,负责思考「漏洞可能在哪、下一步该怎么挖」。
Harness是手脚加神经系统,负责把大脑的想法变成一连串真实动作——
打开哪个文件、跑哪条命令、拿到报错后怎么调整、上一轮失败了下一轮怎么改。
在CyberGym这种要跑几十上百轮、要在百万行代码里反复试错的任务上,Harness的好坏,直接决定了模型的智商能不能转化成战斗力。
一个聪明的模型 + 一个平庸的Harness,结果往往是「想得到、做不到」;
一个能力扎实的模型 + 一个为漏洞挖掘量身打造的强Harness,才可能在这种长程任务上跑出成绩。
为漏洞挖掘「量身定制」的Agent
如今,透过GitHub技术报告,MopMonk的技术脉络,已然明晰:
一款专为漏洞挖掘全新设计的安全多Agent系统,而支撑其运转的思维基座,正是MiniMax M3。

GitHub地址:https://github.com/MopMonkAI/MopMonkAgent
如前所述,M3是当下罕见的、能将顶尖编码能力、百万token上下文与原生多模态集于单一架构的开源模型。
看一眼跑分就能明白:SWE-Bench Pro斩获59.0%、Terminal-Bench 2.1达到66.0%、MCP Atlas拿下 74.2%——
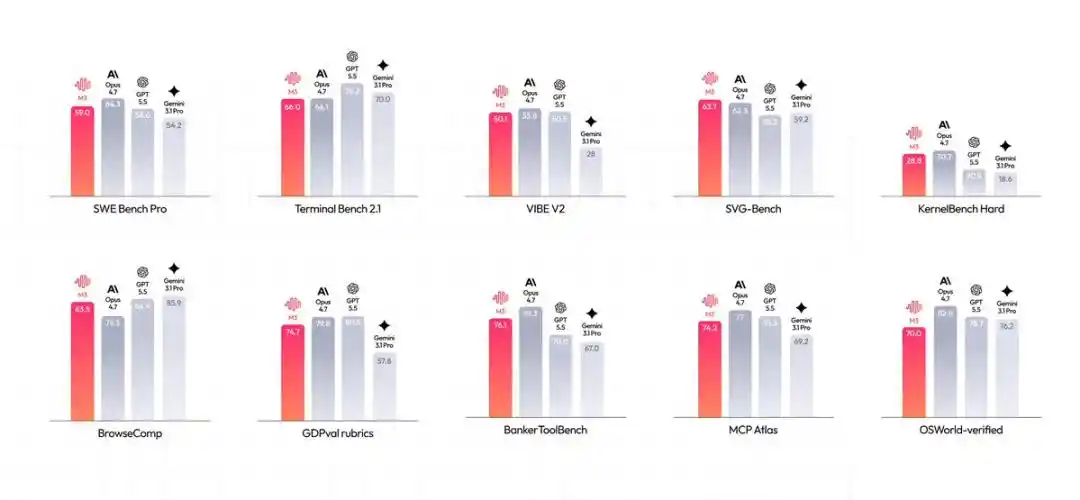
这些亮眼的数据,精准踩中了Agent落地实战时,最硬核的能力刚需。
不仅如此,它还能在长达十几个小时的任务里自主迭代、自我纠错。
换言之,M3扮演了一颗兼具顶尖代码解析力、超长记忆力与熟练工具调用能力的「最强大脑」。
对于CyberGym这种动辄要吞下整个代码库、跑上几十轮的任务,1M的上下文窗口几乎是刚需。
而MopMonk这套安全Agent框架做的事,是把M3这颗大脑的能力,放大成漏洞挖掘的执行力。
它的「内功心法」,从GitHub公开的技术细节来看,核心是三招——
第一招,结构化的「漏洞记忆」。
它不是简单堆叠聊天记录,也不是把超长上下文一股脑塞给模型,而是把一份可持续更新的「任务事实记忆」,围绕漏洞挖掘里最关键的几类对象组织起来:
漏洞目标、代码路径、输入格式、候选PoC、失败证据、验证状态,以及「下一步约束」记忆。
最后一类尤其见功力:它不生成空泛的抽象计划,而是直接从当前证据里,提炼出下一次实验必须满足的硬约束。
比如,「这次必须覆盖到那个分支」「该调整哪个字段」「要排除哪一类失败原因」。
这种记忆设计,将漏洞挖掘从「反复从零试错」变成了「基于证据的收敛过程」。
每一次读代码、每一次执行结果、每一次失败提交,都被转化成下一步生成PoC可复用的约束。

第二招,记忆驱动的「漏洞挖掘」。
在漏洞挖掘任务中,系统首先通过扫描代码库,并将候选触发路径和目录信息作为规划的起点,来初始化漏洞记忆。
然后,它一步步推进,试图收敛到触发崩溃的具体代码位置。
之后,每一次探索尝试都会读取当前记忆,测试一个具体的假设,并将结果写回记忆中。
这样一来,模型不必每一轮都从头重读整个任务,而是从这份结构化记忆里,精准调出当下最相关的那一小块证据——
既大幅降低了长上下文的负担,又让候选PoC的每一次变异,都能继承此前积累的代码路径与输入格式知识,让搜索越收越准。
在严格的探索预算内,时间于是被尽可能地花在「新假设」上,有效试验密度直线拉升。
第三招,共享记忆下的「多Agent并行探索」。
多个探索尝试,共享同一份漏洞记忆,可以从补丁线索、harness入口、文件格式字段、sanitizer类型、边界条件等多个方向同时推进,并彼此继承失败经验与验证结果。
这既扩大了覆盖面,又避免了重复无效的探索。
由此看出,MopMonk把漏洞复现,从一场开放式的反复试错,硬生生重写成了一个「可积累、可约束、可验证」的记忆更新过程。
三招合一,全凭在任务内部一点点沉淀、提炼、复用出来的「内功」,硬生生把一颗强大的开源基座,调度成了漏洞挖掘战场上的特战尖兵。
最终,它跑出了73.1%的成功率。
基座负责「想得深」,Harness负责「记得牢、调得准、打得稳」。
两者深度耦合,才最终铸就了榜单上那个令人瞩目的破局成绩。
一个比「堆参数」更有价值的判断
这件事真正的启发在于——
过去几年,行业的惯性是「堆参数」:参数越大、模型越强、榜单越高。
但CyberGym这种真实攻防任务给出了另一种答案:决定胜负的,越来越是Agent的执行能力,是Harness这层工程的厚度。
根据GitHub技术报告,这套方法的价值落在三点上:
强大的基模能力,提供了搜索的基础;
结构化的漏洞记忆,提供了收敛的机制;
共享记忆的多智能体探索,在有限预算里提升了成本效率。
基座决定了能力的上限,而这套记忆中心的Harness,决定了这份能力到底能兑现多少。
更要命的是它的复利属性:
模型基座会一代代换,今天用M3,明天可能用更新的开源模型。
但一套被真实战场反复打磨、沉淀了攻防经验的Harness,是可以跨越基座迭代、持续复利的资产。
简而言之,MopMonk Harness的长期价值,可能比「再堆一倍参数」更大。
这正是业内开始认真审视,这个神秘「扫地僧」的根本原因:
大家想看的,不只是它打了多少分,而是它示范了一条把开源基座做到极致的路。
所以,「扫地僧」到底是谁?
绕了一圈,我们还是回到了那个最开始、也最让人抓心挠肝的问题。
MopMonk,到底是谁?!
把线索拼起来:东方武侠味拉满的代号 + 上海公司的MiniMax基座 + 一身安全领域的「内功」。
几乎所有箭头,都指向同一个判断:这是一支来自中国、很可能就在上海的AI安全公司。
也有人顺着基模与Agent双向适配的角度,盲猜其背后与AI大模型原生团队脱不开干系。
各种版本的猜测在坊间疯传,但至今无人能甩出实锤。
你觉得,MopMonk会是谁家的高手?评论区,等你来爆料。
本文来自微信公众号“新智元”,作者:ASI启示录







