Auteur : IC3
Traduction : Jiahuan, ChainCatcher
Conclusion principale
La fusion significative de l'IA et de la crypto est encore à un stade très précoce, et le bruit autour de ce domaine croisé a déjà éclipsé les progrès réels.
Dans le sens Crypto x IA, l'IA peut déjà analyser et détecter les transactions, événements et propriétés clés des protocoles existants, identifier les fraudes ou les contrats intelligents vulnérables. Ces techniques utilisent principalement des méthodes d'apprentissage automatique simples et sont les plus efficaces dans des environnements contrôlés avec des données suffisantes.
Dans le sens IA x Crypto, les outils crypto offrent de nouvelles voies pour protéger et gouverner les processus d'IA. Des outils comme les preuves à connaissance nulle et le calcul de confiance peuvent être adaptés pour réduire les risques de falsification des résultats d'IA. Quant aux concepts de gouvernance décentralisée et de gestion d'infrastructure décentralisée, ils ne sont pas encore vraiment adoptés dans le monde de l'IA grand public.
L'industrie doit encore prouver deux choses.
Premièrement, l'IA décentralisée doit faire une comparaison plus stricte et directe des coûts avec les solutions centralisées. Actuellement, l'industrie prouve principalement qu'il est "possible d'entraîner un grand modèle dans un environnement distribué", mais elle manque encore de preuves quantifiées sur les opportunités de concurrence avec les plateformes centralisées dans des scénarios spécifiques, basées sur le coût.
Deuxièmement, le paiement crypto doit démontrer son utilité réelle par rapport aux solutions centralisées dans les scénarios de paiement d'agents. Le crypto a toujours manqué d'avancées substantielles dans le domaine des paiements, mais le paiement par agent a des taux faibles et ne nécessite pas d'appliquer le modèle traditionnel où "un compte doit appartenir à une personne", ce qui lui donne un potentiel. L'industrie devrait saisir cette opportunité avec des preuves quantifiées, plutôt que de rester au stade de la faisabilité.
De plus, il existe deux problèmes de recherche non résolus.
Premièrement, la sécurité de l'IA nécessite une défense au niveau système : la communauté de l'IA résout généralement les problèmes de sécurité au niveau du modèle, en concevant des garde-fous autour de la sémantique des entrées/sorties. Mais avec l'augmentation de l'autonomie des agents et leur capacité à toucher directement l'infrastructure sous-jacente, cette approche ne suffira plus. L'exécution vérifiable et les processus d'authentification du crypto peuvent combler les garanties au niveau système que le niveau modèle ne peut offrir.
Deuxièmement, la combinaison du crypto et de l'IA créera de nouveaux vecteurs de menace et d'attaque, comme les agents autonomes impossibles à arrêter ou les contrats intelligents hors de contrôle, dont nous parlerons plus bas.
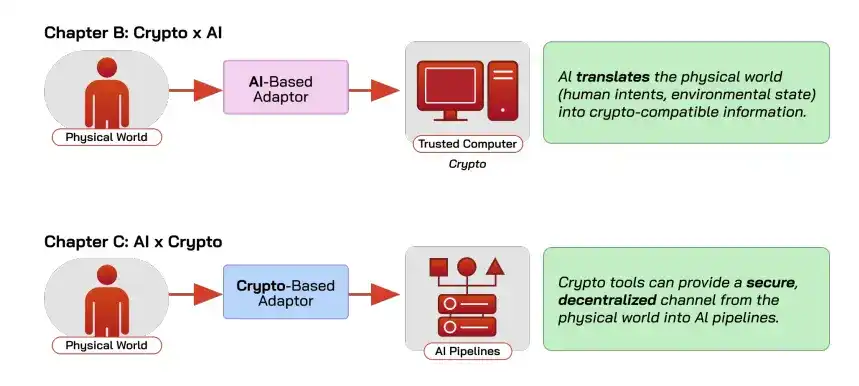
Un cadre unifié : l'IA et le Crypto comme "middleware" réciproques
Un processus de décision automatisé peut être décomposé en quatre maillons : l'intention humaine, l'entrée, le programme, la sortie, et chaque maillon de cette chaîne peut ne pas être fiable. L'IA et le Crypto gèrent chacun une partie dans ce cadre.
L'IA est le "middleware de traduction", qui traduit les intentions floues de l'humain en un programme exécutable par la machine, par exemple transformer "Je veux identifier des panneaux de stationnement" en un modèle entraîné, réduisant ainsi le seuil d'utilisation de la blockchain.
Le Crypto est le "middleware de confiance", garantissant, grâce au calcul de confiance, qu'un calcul s'est bien exécuté comme convenu et que le résultat n'a pas été falsifié (intégrité). Grâce à la décentralisation, il assure que le système reste toujours disponible et résistant à la censure (disponibilité). Certaines solutions peuvent aussi garantir la non-divulgation des entrées/sorties (confidentialité).
Le calcul de confiance suit trois approches techniques.
Premièrement, les environnements d'exécution de confiance (TEE), qui s'appuient sur du matériel dédié pour fournir isolation et attestation à distance (le matériel fournit une preuve vérifiable de son état, permettant à l'autre partie de confirmer que la puce est authentique et non altérée). Grâce au calcul confidentiel de Nvidia, la surcharge supplémentaire pour l'inférence d'un modèle de 8B paramètres est inférieure à 7%, et pratiquement nulle pour un modèle de 70B. Le prix à payer est la confiance dans le fabricant du matériel et l'absence de défense contre les attaques physiques.
Deuxièmement, les preuves à connaissance nulle (ZK), qui s'appuient uniquement sur des problèmes cryptographiques difficiles, avec l'hypothèse de sécurité la plus propre, mais un coût extrêmement élevé. Générer une preuve pour un petit modèle d'environ 18 millions de paramètres prend déjà environ une minute, ce qui est plusieurs ordres de grandeur en dessous des modèles de pointe.
Troisièmement, le calcul multipartite (MPC), qui permet à plusieurs parties de calculer conjointement sans révéler leurs données originales, mais est encore plus lent. Le framework d'inférence MPC Transformer le plus avancé nécessite environ cinq minutes pour générer un seul token pour LLaMA-7B.
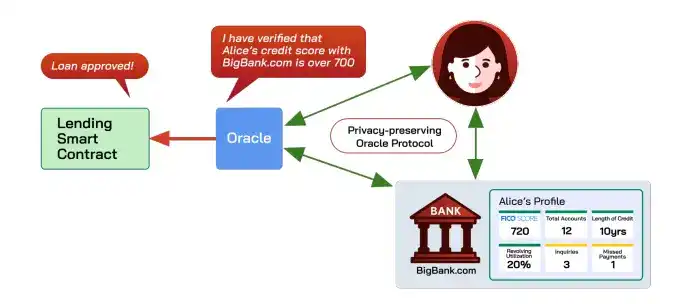
Les oracles sont chargés de fournir de manière fiable des données hors chaîne sur la chaîne. Les oracles de confidentialité (comme Town Crier, DECO) vont plus loin en permettant de prouver des propriétés des données sans divulguer la vie privée, par exemple prouver que "le score de crédit de quelqu'un est supérieur à 700" sans révéler d'autres informations.
L'industrie regroupe ces technologies sous le nom de zkTLS, mais les solutions basées sur les TEE n'utilisent aucune preuve à connaissance nulle, ce qui est un abus de langage.
Crypto x IA : Utiliser l'IA pour renforcer la blockchain
La recherche sur l'IA appliquée au crypto peut être grossièrement divisée en trois générations chronologiques.
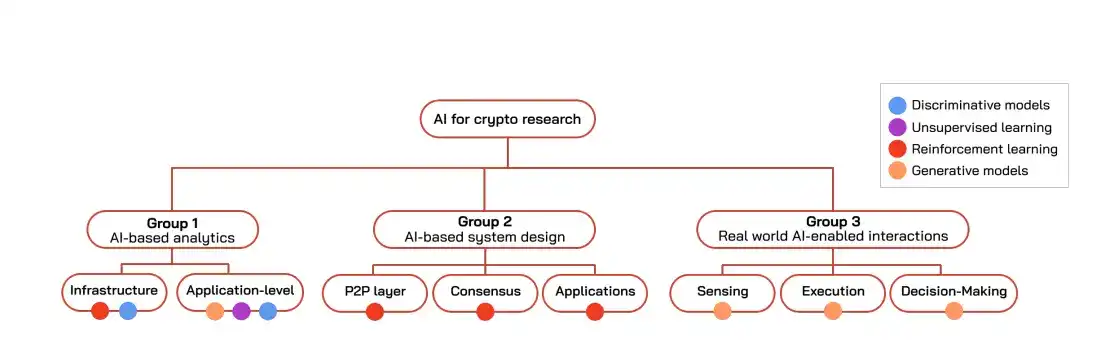
Première génération : Analyse et détection
Depuis plus de dix ans, l'apprentissage automatique est utilisé pour analyser l'état de la chaîne : détecter les vulnérabilités des protocoles de consensus (comme le minage égoïste, où un mineur cache un bloc miné pour le publier au moment opportun et augmenter ses gains), détecter les attaques d'éclipse sur les réseaux P2P (entourer un nœud avec de nombreux nœuds malveillants, le coupant du réseau honnête), prédire le prix des crypto-monnaies, identifier les transactions frauduleuses et le blanchiment.
La limite est que ces analyses dépendent souvent de scénarios où l'information globale et publique est accessible, et sont limitées par des données simulées, manquant d'échantillons d'attaques réelles.
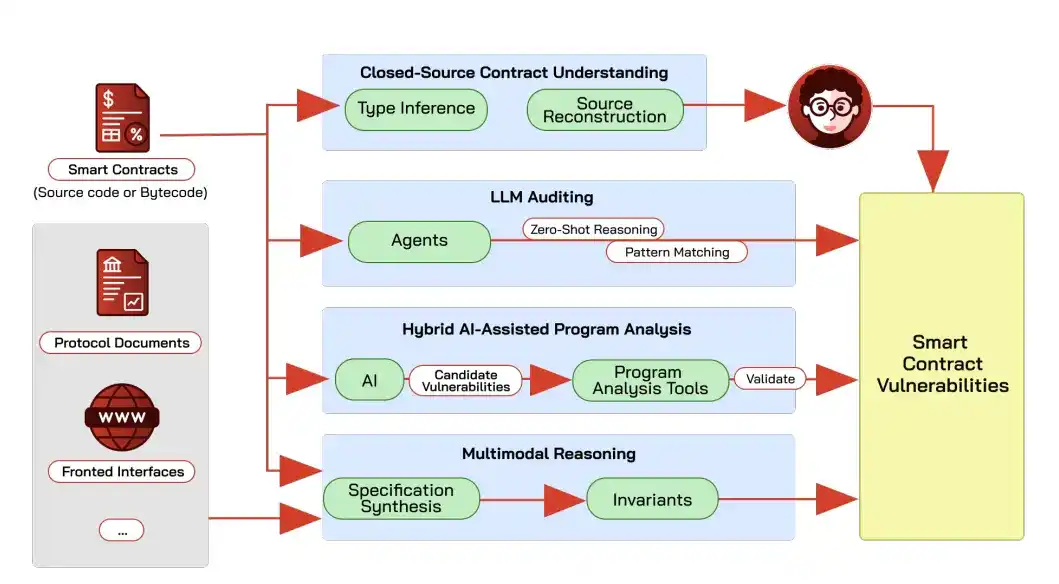
La détection de vulnérabilités des contrats la plus avancée aujourd'hui ne consiste plus à faire deviner la conclusion à l'IA directement depuis le code, mais à laisser l'IA proposer d'abord des points suspects, puis à utiliser l'analyse statique, l'exécution symbolique (analyser la structure du code sans l'exécuter pour trouver des failles) pour vérifier.
Faire jouer à un grand modèle le rôle d'auditeur génère de nombreux faux positifs à cause des hallucinations. GPT-4 et Claude n'ont correctement identifié le type de vulnérabilité que dans 40% des 52 contrats DeFi précédemment attaqués.
Deuxième génération : Conception d'algorithmes
Ces six dernières années, l'apprentissage par renforcement a été utilisé pour concevoir des algorithmes décentralisés, couvrant la topologie des réseaux P2P, les paramètres de consensus et la sélection des rôles, le sharding, les taux des marchés et prêts DeFi, les stratégies d'enchères MEV, etc.
Ces méthodes sont efficaces principalement dans des environnements pouvant être clairement modélisés, et sont pour la plupart restées au stade de la recherche, sans déploiement à grande échelle dans des réseaux réels et sans avoir été testées contre des attaques.
Troisième génération : Interaction avec le monde réel
Grâce aux oracles pilotés par l'IA, les contrats intelligents acquièrent trois capacités renforcées : perception (comprendre des données non structurées et le langage naturel), exécution (appeler des modèles et outils d'IA hors chaîne), décision (agir comme un agent en fonction d'une fonction objectif).
Les performances réelles de l'IA en tant qu'oracle sont mitigées. D'après les expériences de Chainlink Labs, GPT-4o a obtenu un taux de précision global de 89,3% sur 1660 questions de marchés prédictifs, le Truth Bot d'UMA 75%, tandis que l'humain sur l'oracle optimiste d'UMA (où la réponse est présumée vraie avec une période de contestation, et validée si personne ne conteste) atteignait 98,2%.
Le taux de précision dépend fortement du type de question : des questions discrètes avec source officielle comme les résultats sportifs peuvent atteindre 99,7%, tandis que le taux d'erreur augmente significativement pour les questions impliquant des relations temporelles ou nécessitant la transcription et le comptage vidéo.
Il existe trois façons de réagir : premièrement, concevoir pour être tolérant aux fautes, uniquement pour des scénarios à faible valeur ; deuxièmement, introduire un arbitrage humain, par exemple avec une fenêtre de contestation de 48 heures, mais cela ralentit la décision ; troisièmement, laisser le modèle s'abstenir en cas d'incertitude, et n'introduire l'humain qu'à ce moment-là.
Les "DAO d'investissement" qui confient des pools de fonds à des modèles d'IA pour un trading collectif, appelés CoinAlg dans le rapport, avec des projets comme ElizaOS, AI XBT, ont atteint des valorisations maximales de 2,7 et 4,7 milliards de dollars respectivement. Ces produits font face à un dilemme de conception insoluble, qu'on peut appeler "l'impasse CoinAlg".
Si la stratégie de trading est transparente, elle sera copiée ou subira des attaques en sandwich (passer des ordres juste avant et après la transaction de la victime pour profiter du slippage), détournant les profits. Si elle est secrète, les initiés qui connaissent la stratégie peuvent profiter d'un avantage informationnel pour réaliser des gains à l'avance, équivalent à un délit d'initié. Les deux voies nuisent aux investisseurs ordinaires.
Une approche d'atténuation préliminaire consiste à encapsuler la stratégie dans un TEE et à randomiser les transactions, augmentant la difficulté de prédiction pour les initiés.
Nouveau risque : Contrats intelligents malveillants pilotés par l'IA
Les contrats intelligents servent à remplacer la confiance interpersonnelle, ce qui signifie aussi que les acteurs criminels les moins dignes de confiance peuvent en bénéficier.
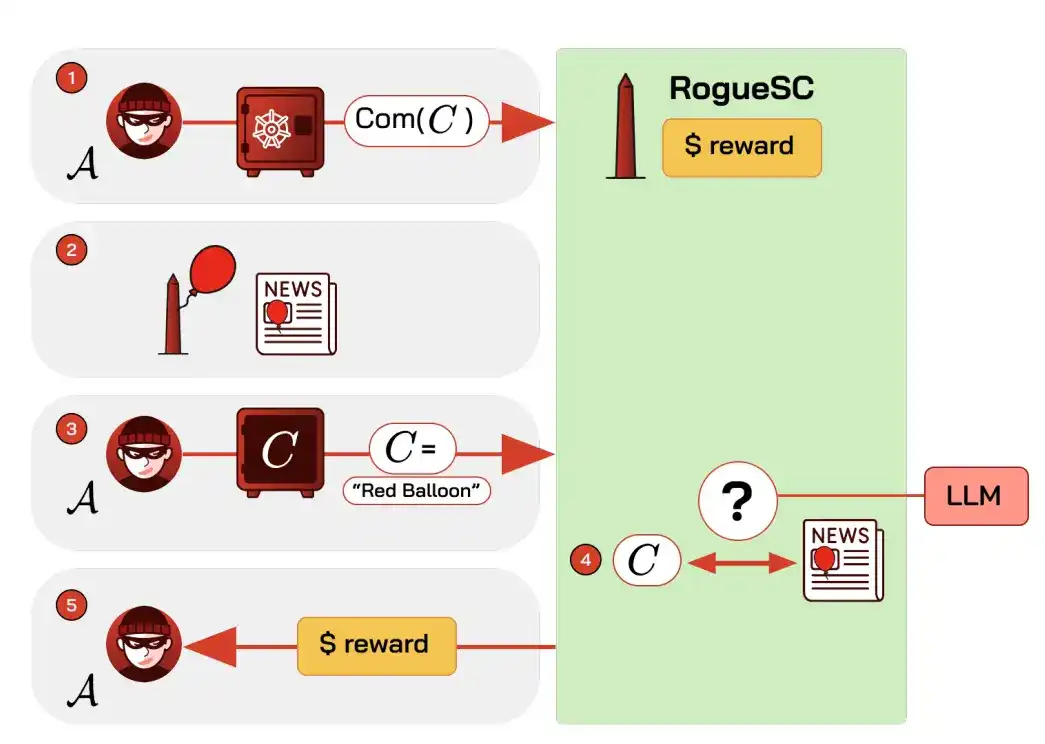
Un mécanisme possible : un contrat offre une prime pour un crime, le criminel s'engage cryptographiquement à l'avance avec une "marque secrète", qu'il révèle après coup ; un modèle d'IA compare avec des articles de presse, confirme l'accomplissement du crime et effectue le paiement automatiquement. L'IA joue ici le rôle d'"arbitre", difficile à automatiser auparavant, et peut être utilisée pour du harcèlement ciblé, du vol de renseignements d'organisation, la révélation de l'identité de lanceurs d'alerte, etc.
Les contre-mesures possibles incluent l'analyse de la chaîne pour le suivi, la mise sur liste noire des fonds impliqués, et le refus de service des oracles hébergeant des modèles d'IA sur des requêtes à haut risque.
AI x Crypto : Utiliser le Crypto pour renforcer l'IA
La contribution potentielle du crypto à l'IA se divise en deux catégories : premièrement, décentraliser les différentes étapes du cycle de vie de l'IA ; deuxièmement, protéger la sécurité de ces étapes.
Infrastructure décentralisée (DePIN)
Les réseaux d'infrastructure physique décentralisés permettent aux nœuds de fournir de la puissance de calcul et d'autres ressources moyennant des incitations tokenisées. Theta, Akash, etc., prétendent économiser 50% à 85% par rapport à AWS, le principal goulot d'étranglement étant le débit et la latence dus à la communication entre nœuds via le réseau public.
L'adéquation varie selon le type de tâche. L'entraînement n'est pas sensible à la latence (se fait hors ligne), mais la synchronisation inter-régions est un goulot. Des résultats existent déjà pour entraîner des modèles de plusieurs milliards de paramètres sur du matériel distribué (700M et 7B sur Bittensor, 10B paramètres d'Intellect-1 de Prime Intellect, et le plus grand étant un modèle de 40B en cours d'entraînement sur le réseau Psyche).
L'inférence est plus sensible à la latence, mais nécessite moins de débit que l'entraînement et n'a pas besoin de rétropropagation (l'étape centrale de l'entraînement où l'erreur est propagée en arrière pour mettre à jour les paramètres, nécessaire uniquement à l'entraînement). Les inférences peu sensibles à la latence (comptes-rendus de réunion, révision de documents) sont particulièrement adaptées au DePIN.
La lacune cruciale est que la plupart de ces projets ne rapportent pas le coût total de bout en bout. Ils font la promotion du prix par GPU-heure, alors que ce qui détermine vraiment le coût d'une tâche de ML est l'efficacité de l'entraînement (nombre d'itérations par unité de coût) et l'efficacité de l'inférence (nombre de tokens par unité de coût).
Marchés décentralisés de données et de modèles
Les données d'IA ont plusieurs caractéristiques distinctes des biens ordinaires. C'est un bien numérique, dont la création initiale est coûteuse mais la copie presque gratuite ; elles sont souvent non rivales (une donnée peut être utilisée simultanément par plusieurs parties sans perte) ; leur qualité est difficile à juger à l'avance, c'est le problème du "marché des citrons" (l'acheteur ne peut juger la qualité à l'avance, poussant les produits de qualité hors du marché) ; le vendeur doit fournir un échantillon, mais l'échantillon lui-même a de la valeur ; et elles peuvent être revendues, avec en plus la difficulté de déterminer si deux ensembles de données sont substantiellement identiques.
Le litige avec les marchés centralisés concerne l'opacité des prix et la limitation des choix des utilisateurs, mais les prix centralisés sont parfois plus efficaces car ils disposent de plus d'informations.
Les marchés de données n'ont pas encore de géants monopolistiques, c'est une fenêtre d'opportunité pour les refaire de manière décentralisée, en utilisant des outils crypto comme les micro-paiements, les TEE (limiter l'utilisation des données à des tâches spécifiques), les preuves à connaissance nulle (révéler des propriétés des données à l'acheteur sans divulguer les données elles-mêmes).
La réalité est que la plupart des plateformes n'utilisent la crypto-monnaie que pour l'étape de paiement. Le mécanisme de tarification est soit décidé par le protocole, soit entièrement laissé au vendeur, deux approches qui existent déjà sur les marchés centralisés. Les améliorations apportées par la décentralisation restent insuffisamment étudiées.
Voie de paiement pour agents et x402
L'écosystème des agents est déjà décentralisé en soi : différentes parties utilisent différents modèles pour développer et optimiser différents objectifs, il n'y a pas de point de contrôle central naturel. La pensée de la cryptéconomie (utiliser des moyens cryptographiques combinés à des récompenses/peines économiques pour contraindre le comportement des participants) du crypto peut être transposée à la gouvernance des agents.
Les micro-paiements sont essentiels à l'économie des agents. L'historique d'Internet montre que les micro-paiements ont souvent échoué, le blocage venant du coût de décision pour un humain de juger chaque petit paiement, et non de l'infrastructure de paiement. Un agent évalue les micro-paiements bien plus vite qu'un humain, l'utilisateur n'a qu'à définir une stratégie, ce qui pourrait permettre aux micro-paiements de fonctionner pour la première fois.
Cloudflare a déjà lancé le "pay-per-crawl", des protocoles comme x402 (un protocole ouvert permettant aux programmes d'effectuer directement de petits paiements sur chaîne via HTTP) sont en développement.
L'actif sous-jacent de ce système est principalement des stablecoins (USDC, USDT, DAI), car ils fournissent une unité de compte stable pour les agents (une échelle pour évaluer uniformément tous les biens), tandis que les tokens natifs comme ETH, SOL sont trop volatils.
La confiance entre agents repose sur des registres sur chaîne (comme ERC-8004, une proposition de norme pour établir des identités et réputations sur chaîne pour les agents sur Ethereum) qui enregistrent identité et réputation, mais ce sont essentiellement des auto-déclarations, et la réputation est en retard, favorisant les acteurs établis.
Une solution plus avancée est l'audit vérifiable d'agents : un LLM exécuté dans un TEE examine le code propriétaire de l'agent, produit un score de réputation, le résultat de l'audit est lié au hachage du code, permettant aux vérificateurs d'obtenir des garanties fiables tout en gardant le code privé.
Les agents autonomes impossibles à arrêter (UAA) sont un autre risque. La durée des tâches qu'un agent de pointe peut accomplir de manière autonome a doublé environ tous les sept mois depuis 2019. Des recherches ont montré qu'un modèle peut localement franchir le seuil d'auto-reproduction, créer des copies indépendantes, mais la réplication vers des infrastructures externes bute encore sur l'authentification.
Le modèle Mythos d'Anthropic a démontré la capacité à découvrir et exploiter de manière autonome des vulnérabilités zero-day (inconnues du fabricant, sans correctif). Un agent qui possède un portefeuille et qu'on ne peut pas arrêter se trouverait dans un angle mort du cadre réglementaire actuel centré sur l'"opérateur".
Gouvernance décentralisée
Les communautés blockchain ont une plus longue histoire de pratique dans l'attribution du contrôle du système, de manière naturellement décentralisée, cherchant à inclure un large éventail de parties prenantes, mais elles ont aussi des faiblesses reconnues : vulnérabilités de sécurité, apathie électorale, corruption.
L'adéquation de la gouvernance communautaire aux différentes étapes du développement de l'IA varie : le volume de données de pré-entraînement est trop important pour recueillir des avis efficaces, la valeur se manifeste davantage dans la phase de fine-tuning ; le choix de l'architecture sous-jacente relève de décisions techniques, peu adaptées à la gouvernance communautaire ; les phases d'évaluation et d'alignement mêlent jugements techniques et normatifs, l'apport de la communauté y a de la valeur.
Constitutional AI utilise une "constitution" rédigée par des humains pour établir les principes que le modèle doit suivre. Le Collective Constitutional AI auquel participe Anthropic introduit un vote public pour générer des principes ; les modèles entraînés avec des principes de source ouverte présentent moins de biais sociaux. Mais ces expériences de démocratisation de la gouvernance n'ont pratiquement pas été adoptées, les entreprises d'IA manquant de motivation pour céder le contrôle de leurs modèles.
Le vote pondéré par token des DAO est publiquement considéré comme une "ploutocratie", ce qui a conduit à des mécanismes dérivés comme le vote quadratique (le coût d'une voix supplémentaire augmente pour limiter l'influence des gros détenteurs), le vote par conviction (poids accumulé en fonction de la durée de détention du vote en faveur), le vote par délégation, mais leur efficacité reste incertaine.
Protéger l'intégrité d'exécution des systèmes d'IA
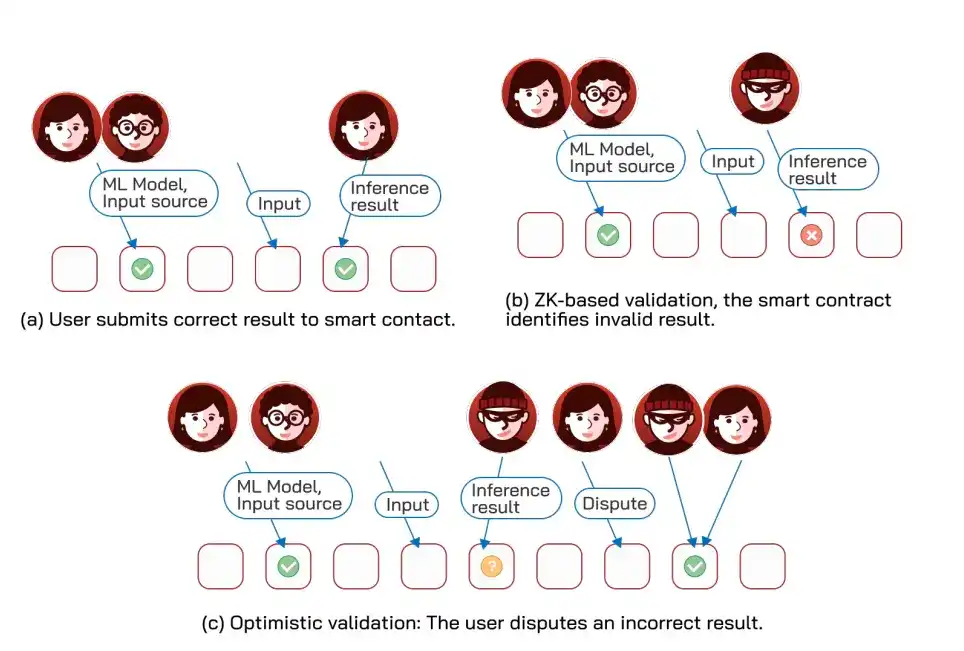
Lorsqu'un contrat intelligent nécessite un calcul de ML dépassant ses propres capacités, il peut servir d'"arbitre" : les parties s'engagent d'abord sur le modèle et les données utilisés et déposent une garantie ; après exécution hors chaîne, les résultats sont soumis au contrat pour vérification, la partie fautive est sanctionnée. Il existe quatre approches de vérification, avec des compromis.
Premièrement, les TEE, les plus efficaces, le matériel de confiance signe une preuve d'intégrité du calcul, mais nécessite de faire confiance à l'opérateur.
Deuxièmement, l'exécution optimiste, le résultat est d'abord considéré comme non final, avec une fenêtre de contestation ; en cas de contestation, une recherche dichotomique (diviser répétitivement par deux la plage d'erreur pour localiser l'instruction fautive) est utilisée pour localiser l'instruction unique erronée avant sanction.
La difficulté réside dans la non-déterminisme des opérations à virgule flottante en ML, nécessitant un ordre d'exécution contrôlé ou une sémantique tolérante (ne pas exiger l'exactitude parfaite entre deux calculs, considérer comme cohérents dans une marge d'erreur) pour le gérer. Des solutions représentatives incluent Verde, TAO, Arbigraph, OPML, etc.
Troisièmement, les preuves à connaissance nulle (zkML, utiliser des preuves à connaissance nulle pour prouver la correction du processus d'inférence d'IA), qui peuvent prouver la correction de l'inférence tout en cachant les paramètres du modèle, voire les entrées/sorties. Il existe des solutions spécialisées pour les CNN, les Transformers ainsi que des compilateurs généraux (comme EZKL, ZKML, DeepProve).
Son objectif de confidentialité a en fait trois niveaux : cacher l'entrée, cacher les poids, cacher la structure du modèle. Mais plus la confidentialité est forte, plus les contraintes du circuit sont complexes, moins il y a de possibilités d'optimisation, il existe une tension fondamentale entre confidentialité et efficacité. Le coût principal vient des couches non linéaires et de la représentation numérique, ce qui rend toujours difficile la prise en charge de contextes longs, de grands modèles et de services à haut débit.
Quatrièmement, les preuves d'inférence statistique, dont le principe est que deux modèles ayant des fonctionnalités différentes calculent nécessairement des caractéristiques internes différentes. Ainsi, en échantillonnant et comparant ces caractéristiques, on peut juger de manière probabiliste si l'inférence a bien été exécutée par le modèle spécifié.
Son coût de preuve est de l'ordre de la milliseconde, avec une finalité immédiate, adapté aux scénarios à haute fréquence et faible latence. Il protège contre des méfaits réalistes comme le remplacement du modèle par le fournisseur de service (par exemple, par une version distillée moins chère ou une version désalignée), mais ne bloque pas un acteur complètement malveillant qui fabriquerait de toute pièce un enregistrement de calcul complet, ce qui reste un problème non résolu.
Prouver l'entraînement d'un modèle (zkPoT, utiliser des preuves à connaissance nulle pour prouver la correction du processus d'entraînement) est bien plus difficile que prouver l'inférence : l'entraînement dure longtemps, l'état intermédiaire s'accumule constamment, il est fortement aléatoire, la complexité est supérieure de plusieurs ordres de grandeur à celle de l'inférence. Des travaux (Garg et al., Kaizen) sont en cours, s'étendant à des preuces auditables sur l'origine des données d'entraînement et les contraintes d'équité (ZkAudit, Confidential-PROFITT).
Protéger le pipeline d'entraînement
Lorsqu'une seule institution entraîne un modèle avec ses propres données de confiance, il n'y a généralement pas de préoccupations immédiates de confidentialité ou d'intégrité. Les défis de sécurité complexes apparaissent lors d'un entraînement conjoint multipartite, avec des sources de données diverses.
Un scénario typique est celui de plusieurs hôpitaux s'entraînant conjointement à un modèle de diagnostic : fusionner leurs dossiers médicaux électroniques (DME) couvre une population de patients plus large, améliore la précision du diagnostic, mais est soumis à des réglementations comme HIPAA, et les parties ne souhaitent ni ne peuvent échanger directement leurs données brutes entre elles ou avec un tiers.
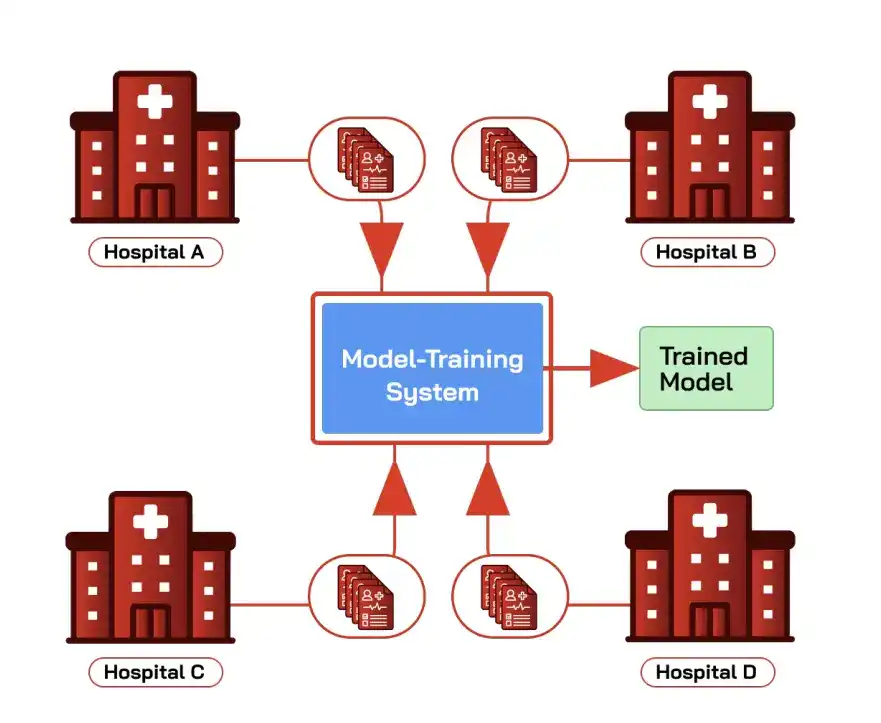
Les institutions financières s'entraînant conjointement à un modèle anti-fraude, les entreprises à un modèle de détection d'intrusion, sont des cas similaires.
L'apprentissage fédéré est conçu pour cela : l'environnement d'entraînement initialise d'abord un modèle global et le distribue aux parties, chacune entraîne localement avec ses données privées, ne renvoyant que les mises à jour du modèle, l'environnement d'entraînement les agrège en un nouveau modèle global, les données restant localement tout au long du processus.
Mais l'adoption de l'apprentissage fédéré est limitée (l'application la plus connue est la prédiction du clavier des smartphones). Il ne garantit pas l'intégrité des données et des calculs ; même si toutes les parties sont honnêtes, la surcharge de communication est importante, la latence réseau et de coordination ralentit l'ensemble, la précision du modèle est inférieure à l'entraînement centralisé, et une partie malveillante peut empoisonner le modèle ou y insérer une porte dérobée.
Une alternative plus simple est d'utiliser les TEE pour un entraînement centralisé : l'environnement d'entraînement s'exécute dans un environnement de calcul confidentiel de confiance, reçoit les données brutes des parties via des canaux chiffrés, effectue un entraînement centralisé, ne sort que le modèle entraîné, les données sont invisibles les unes aux autres, et peut inclure une preuve de provenance du modèle (qui a fourni les données, comment le modèle a été entraîné).
Le prix à payer est le risque inhérent de canaux auxiliaires des TEE et la surcharge élevée d'E/S. Dans la réalité, les institutions préfèrent actuellement regrouper les données dans un cloud conforme, en s'appuyant sur l'isolation, le contrôle d'accès, le chiffrement et des accords d'utilisation des données pour répondre à la conformité, mais cela nécessite de faire confiance au fournisseur de services cloud.
Les données des réseaux privés sont une autre piste. Les données textuelles du réseau public approchent de leurs limites (certaines prédictions suggèrent leur épuisement entre 2025 et 2030), et les données synthétiques présentent le risque d'"effondrement du modèle", sans pouvoir étendre la couverture des données au-delà des domaines existants.
En revanche, les "réseaux privés" (données non accessibles aux crawlers comme les emails, données de santé, financières) sont estimés être deux ordres de grandeur plus grands que le réseau public, une mine inexploitée, mais actuellement très fragmentés.
Les oracles peuvent ouvrir cette porte. Prenons l'exemple d'un patient partageant son dossier médical pour entraîner un modèle médical : l'utilisateur peut, via un oracle, transférer son dossier du portail de l'hôpital vers la partie chargée de l'entraînement, et prouver que les données viennent bien de ce portail, sans que l'hôpital n'ait à modifier son infrastructure, car la connexion est initiée par l'utilisateur.
Pour protéger simultanément la vie privée, il faut combiner un oracle de confidentialité (données via un canal chiffré) et un TEE. Le TEE peut aussi fournir une preuve à l'utilisateur, montrant qu'il exécute bien le logiciel d'entraînement confidentiel "qui ne sort que le modèle", l'utilisateur peut vérifier cela avant de transmettre ses données.
On peut y ajouter des engagements plus fins : confidentialité différentielle (la sortie du modèle dépend très peu de toute donnée d'entraînement individuelle), suppression après utilisation, limitation de l'utilisation du modèle final aux hôpitaux d'une liste blanche.
Pipeline d'inférence sécurisé et pipeline protégé (Props)
La même combinaison oracle + calcul de confiance peut aussi servir à effectuer des inférences sécurisées sur des données privées.
Prenons l'exemple de l'approbation d'un prêt bancaire : le modèle lit les documents financiers du demandeur, sort une décision d'approbation ou de rejet. Le processus actuel est que l'emprunteur télécharge ou photographie lui-même les documents pour les téléverser, ce qui pose deux problèmes : d'une part, le prêteur ne peut pas confirmer que les documents sont authentiques, non falsifiés ; d'autre part, les documents de l'emprunteur pourraient fuiter du système de modélisation du prêteur, un risque pour les deux parties.
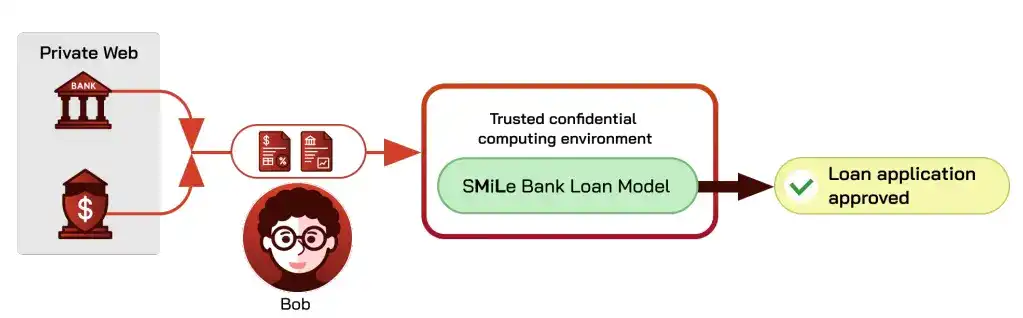
Utiliser un oracle de confidentialité pour résoudre l'authenticité de la source, et le calcul confidentiel pour la vie privée, permet d'obtenir un pipeline d'inférence sécurisé : le prêteur ne voit que la conclusion du modèle, tout en étant sûr que l'entrée est fiable.
Les sources privées peuvent également servir de système d'identité et de certification.
L'emprunteur peut transférer des relevés bancaires, des formulaires W-2 portant son identité, ce qui constitue en soi une preuve d'identité solide, transformant les services réseau existants en système d'identité temporaire contre le vol d'identité et la fraude aux prestations ; le modèle peut aussi émettre des certificats sur cette base, par exemple, après vérification des documents fiscaux et d'activité d'une petite entreprise, émettre une attestation de "conformité à un certain critère" accompagnée de la preuve du pipeline d'inférence.
L'ensemble du processus peut être réalisé de manière décentralisée, théoriquement n'importe qui peut mettre en place un pipeline d'inférence fiable, sans nécessiter la coopération de la source de données ou d'une autorité existante.
Les entrées adverses sont un problème tenace. Un attaquant peut soumettre un relevé bancaire qui semble normal à l'œil nu mais a été subtilement modifié, trompant le modèle pour qu'il lise un solde artificiellement élevé et approuve à tort le prêt. La recherche académique sur les échantillons adverses a toujours été un cycle "contournement - correction", sans solution générale à ce jour.
Le pipeline d'inférence sécurisé offre une nouvelle approche : limiter les entrées à des sources réseau certifiées, réduisant ainsi l'espace pour qu'un attaquant construise des entrées adverses, complémentant les défenses au niveau du modèle.
La confidentialité du modèle lui-même nécessite aussi une protection. Un attaqueur peut, via des requêtes soigneusement construites, effectuer du vol de modèle (extraire des caractéristiques voire le modèle entier), de l'inférence d'appartenance (déterminer si les données de quelqu'un étaient dans l'ensemble d'entraînement) voire reconstituer des données d'entraînement originales, et ainsi espionner la configuration du système et les choix de prétraitement.
Des chercheurs ont estimé qu'environ 8 000 $ suffiraient pour voler les poids d'une couche d'un grand modèle. La limitation de débit couramment utilisée dans les systèmes ouverts est fragile, car un seul utilisateur anonyme peut se faire passer pour de nombreux utilisateurs dans une attaque Sybil.
Le pipeline d'inférence sécurisé peut atténuer cela des deux côtés : utiliser l'oracle pour limiter les types d'entrées, contenant les attaques d'extraction nécessitant de nombreuses requêtes diversifiées ; puis utiliser des preuves d'identité fortes générées dans le pipeline pour imposer une limite de requêtes par utilisateur, exécutable sans révéler l'identité de l'utilisateur à la plateforme, réprimant ainsi les attaques Sybil.
La mémoire des agents est une nouvelle surface d'attaque. Un attaquant peut, via des appels d'outils ou l'insertion de matériel externe, contaminer le contexte (injection de mémoire) donné à l'agent, l'induisant à agir anormalement, par exemple, dans le framework ElizaOS qui gère d'importants actifs cryptographiques, un contexte contaminé peut inciter l'agent à initier des transactions non autorisées.
Les TEE peuvent partiellement atténuer cela : exécuter l'agent dans un TEE, ou ne récupérer que des contextes certifiés.
Mais même avec des TEE, deux difficultés subsistent.
Premièrement, une source fiable peut aussi contenir du contenu contaminé, par exemple, le contenu d'une plateforme sociale est généré par les utilisateurs eux-mêmes, qui peuvent facilement empoisonner leurs propres posts.
Deuxièmement, l'opérateur d'un TEE peut lancer une attaque de retour en arrière ou de bifurcation, en restaurant l'état du TEE à un point de contrôle ancien, effaçant les mises à jour de mémoire ultérieures.
Le premier relève du problème de détection de contenu, insoluble par la cryptographie ; le second peut déjà être abordé par une approche de consensus, des systèmes comme ROTE, Narrator utilisent des protocoles distribués, voire des blockchains publiques, pour garantir la cohérence et la fraîcheur de l'état des TEE.
En résumant l'architecture de cette section, on obtient le framework générique "Pipeline Protégé" (Props), dont l'objectif est d'utiliser de manière sécurisée des données privées sans modifier l'infrastructure existante.

Il assemble l'oracle et le calcul de confiance en trois segments : l'oracle récupère des données depuis une source privée certifiée et prouve leur provenance ; le TEE effectue l'entraînement ou l'inférence à l'intérieur d'une frontière chiffrée ; le TEE sort le modèle ou la conclusion accompagné d'une preuve décrivant les attributs du pipeline (source des données, hachage du code du logiciel ou du modèle, etc.).
Props garantit trois propriétés : intégrité des entrées de bout en bout (la sortie dépend uniquement de données certifiées provenant de sources privées fiables), confidentialité par défaut (les entrées et états intermédiaires ne sortent pas de la frontière protégée, seule la sortie est rendue publique), prouvable sans divulgation (la preuve permet aux fournisseurs de données et aux utilisateurs des résultats d'être convaincus de l'intégrité et de la confidentialité).
Il a aussi une version "transparente", où les données et calculs n'ont pas besoin d'être confidentiels, seulement certifiés, les sources pouvant être publiques ou privées.
Cinq idées fausses sur Crypto x IA
Autour des plateformes et applications Crypto x IA, plusieurs idées fausses ou affirmations trompeuses sont apparues dans l'industrie. Les cinq suivantes ne sont pas totalement fausses, mais il est crucial de clarifier quelles parties sont actuellement valables et lesquelles nécessitent encore des preuves.
Idée fausse n°1 : La blockchain peut distinguer le contenu généré par IA de celui généré par l'humain
L'idée qu'en enregistrant du contenu sur la chaîne, on peut déterminer après coup s'il provient d'une IA ou d'un humain, est souvent citée. Des projets (comme Everlyn AI) enregistrent déjà du contenu généré par IA sur la chaîne. Mais la blockchain ne peut pas le faire en général, il faut séparer les problèmes de "détection de contenu" et de "traçabilité du contenu".
La détection de contenu consiste à déterminer si un contenu est généré par un humain ou une IA. L'approche actuelle principale est a posteriori, ne dépendant pas de métadonnées ou signaux pré-embarqués, et se divise en deux catégories : les classificateurs d'IA, utilisant l'apprentissage profond pour identifier des caractéristiques statistiques propres aux modèles de génération ; et les analyses médico-légales statistiques, analysant la distribution du bruit au niveau pixel, les anomalies structurelles (comme les incohérences physiologiques dans un visage généré par IA).
Le problème est que la blockchain elle-même ne peut pas percevoir ces informations hors chaîne. Le résultat de classification doit être fourni par un classificateur externe. Le fait d'être sur chaîne ne fait qu'ancrer ce résultat, garantissant que l'enregistrement n'est pas altéré après soumission, mais ne garantit pas que l'enregistrement était vrai au moment de l'écriture. Si le détecteur externe se trompe, la blockchain enregistrera l'erreur de façon permanente. En d'autres termes, la blockchain fournit "l'intégrité de la déclaration", et non la "vérification que la déclaration est vraie".
La traçabilité du contenu enregistre l'historique d'un actif numérique depuis sa création. Des standards industriels comme C2PA permettent aux créateurs ou appareils d'attacher des métadonnées signées cryptographiquement (credentials de contenu) aux médias, enregistrant la source, l'auteur et les modifications ultérieures. Des projets comme Numbers Protocol, Starling Lab utilisent la blockchain comme registre public et inaltérable pour ces credentials.
Mais même avec un système de traçabilité robuste ancré sur la chaîne, on ne peut pas garantir que le contenu était initialement généré par un humain ou une IA.
Un utilisateur peut parfaitement afficher une image générée par IA sur un écran haute définition, puis la photographier avec un appareil conforme au C2PA, obtenant un fichier valide signé, étiqueté comme "prise réelle" ; c'est similaire pour le texte, généré par IA puis retapé manuellement dans un éditeur conforme, portera des informations de traçabilité légitimes indiquant "création humaine".
De plus, une fois le contenu modifié au point de ne plus correspondre à l'enregistrement sur chaîne, la traçabilité est rompue, et un registre universel couvrant tout le contenu est presque impossible à réaliser dans un futur proche, laissant nécessairement de grandes lacunes dans les systèmes de traçabilité.
Point clé : Dans un sens étroit, la blockchain peut fournir une garantie robuste d'intégrité pour les métadonnées de traçabilité, mais elle est loin d'être une solution complète au problème de détection de contenu généré par IA.
Une solution vraiment efficace nécessiterait un écosystème universel où chaque contenu serait capturé par un appareil fiable et immédiatement ancré sur la chaîne, alors qu'en réalité, la grande majorité du contenu est créé et partagé avec des outils ne supportant pas l'ancrage cryptographique, laissant le contenu non étiqueté dans une zone grise.
Idée fausse n°2 : La blockchain ou la décentralisation peuvent résoudre les problèmes de biais et d'équité de l'IA
"Mettre l'inférence et l'entraînement des modèles sur la chaîne résoudra l'injustice et les biais de l'IA." Pour évaluer cette affirmation large, il faut d'abord distinguer différents types de biais.
Le biais algorithmique est le concept d'équité le plus courant dans le monde de l'IA. Les modèles apprennent et peuvent même amplifier les déséquilibres présents dans les jeux de données, conduisant à des modèles discriminants moins performants sur les groupes défavorisés, ou des modèles génératifs perpétuant des tendances indésirables des données d'entraînement (comme un langage nocif, des stéréotypes figés).
Le monde académique a proposé de nombreuses solutions techniques, pendant l'entraînement et pendant l'inférence (garde-fous), mais ces protections sont loin d'être parfaites, l'équité n'est pas un problème résolu, et pourrait même ne jamais l'être complètement, car la définition même de l'équité implique de nombreux compromis.
La décentralisation ne résout pas le biais algorithmique, car il provient du processus d'entraînement lui-même, généralement atténué en améliorant les techniques d'entraînement ou d'inférence, la décentralisation n'en touche pas la racine.
Mais le biais a une seconde source : les décisions de haut niveau qui influencent les performances du modèle : quelles données utiliser, quelle architecture, comment compenser les contributeurs. Cette couche est orthogonale à l'équité généralement comprise dans l'IA, mais peut influencer le biais algorithmique, et peut en partie être améliorée grâce à deux caractéristiques de la décentralisation.
La première caractéristique est la transparence. Les développeurs peuvent utiliser la blockchain pour s'engager publiquement sur les données d'entraînement, l'algorithme d'entraînement, les points de contrôle du modèle et les garde-fous d'inférence, permettant aux opérateurs de retracer de manière vérifiable la sortie d'un entraînement ou d'une inférence donnée.
Mais cela est difficile à étendre aux grands modèles et points de contrôle (coûts de stockage et calcul trop élevés). Dans les systèmes existants, ces données existent déjà majoritairement hors chaîne et les utilisateurs n'y ont pas directement accès. À court terme, le bénéfice de la transparence pourrait se limiter à l'inférence.
Plus crucial encore, à moins que l'industrie ne définisse clairement les cas d'usage que cette transparence doit servir et les interfaces adaptées (par exemple, permettre aux utilisateurs de signaler une utilisation abusive de leurs données, ce qui nécessiterait d'établir une véritable propriété des données et des techniques comme l'oubli machine), la transparence en elle-même pourrait ne pas changer la façon dont les gens développent et utilisent l'IA.
La deuxième caractéristique est la gouvernance décentralisée, qu'il faut distinguer en deux types. Le premier regroupe les mécanismes de gouvernance communautaire explorés et adoptés dans la blockchain (vote pondéré par token, démocratie liquide) ; le second est la gouvernance autonome décentralisée représentée par les DAO, où les décisions de gouvernance sont exécutées de force par des contrats intelligents.
Le point commun crucial est que des mécanismes comme la gouvernance communautaire n'ont pas besoin de blockchain pour être mis en œuvre. Les présenter comme des "problèmes d'IA résolus par la blockchain" n'est donc pas exact. Parmi eux, les décisions d'IA techniques et sensibles aux performances ne conviennent pas à un vote large, mais les décisions d'orientation de valeur (comme l'alignement des modèles) sont plus adaptées ; les développeurs d'IA grand public les ont explorées, mais ne les ont pas vraiment adoptées.
La gouvernance véritablement sur chaîne, exécutée de force par des contrats intelligents (exécution directe ou confiscation de garanties) peut renforcer la robustesse, mais se heurte aux mêmes barrières techniques que la transparence sur chaîne : l'infrastructure actuelle ne peut supporter les besoins de stockage et de calcul de l'IA. La mise en œuvre nécessite des avancées majeures dans l'entraînement vérifiable, c'est une vision à long terme cohérente mais prématurée.
Point clé : La blockchain en elle-même ne peut pas réduire les biais algorithmiques, mais elle peut promouvoir la transparence à différentes étapes du cycle de vie de l'IA et élargir la participation à la gouvernance de l'IA.
Idée fausse n°3 : Donner un portefeuille à un agent IA le rend "autonome"
Les projets de "portefeuilles d'agents" et de protocoles de paiement affirment souvent qu'en donnant un portefeuille à un agent IA, lui permettant de gagner, dépenser, "survivre" par lui-même, on le rend autonome. Cette affirmation mélange plusieurs concepts différents.
L'ambiguïté vient d'abord de la signification différente de "autonome" dans les deux domaines. Dans le contexte de l'IA, un agent autonome peut agir sur la base de sa propre perception, apprentissage, expérience, plutôt que de suivre strictement des règles prédéfinies. Les contrats intelligents sont aussi souvent appelés autonomes, mais cela met l'accent sur la résilience face à la falsification, la censure, l'arrêt.
Le premier est appelé "autonomie intelligente", le second "autonomie d'exécution". Les agents IA modernes possèdent déjà une autonomie intelligente considérable, mais pas nécessairement d'autonomie d'exécution, un administrateur peut toujours éteindre le serveur qui l'exécute.
Ce qu'apporte un portefeuille d'agent, ce n'est ni l'une ni l'autre. Posséder un portefeuille ne rend pas l'IA plus intelligente, ni plus résistante à la manipulation humaine ou à l'arrêt. Il apporte en réalité de l'automatisation : l'agent peut trader, transférer des fonds, appeler des fonctionnalités sur chaîne de manière programmatique, sans passer par un processus d'approbation humaine.
Cette automatisation n'est pas non plus exclusive à la blockchain ; les infrastructures financières centralisées peuvent aussi être appelées de manière programmatique par des agents. Une interprétation plus valable est : les systèmes de paiement blockchain offrent intrinsèquement une plus grande autonomie que les solutions centralisées (bien que cela ne soit pas spécifique aux agents), par exemple, ils peuvent garantir que les transactions d'un agent ne sont pas traitées différemment, c'est-à-dire la neutralité et la résistance à la censure.
Point clé : Un portefeuille d'agent permet à un agent IA d'appeler commodément des interfaces financières, d'automatiser les interactions économiques, d'éviter les approbations humaines, mais l'automatisation n'est pas l'autonomie. Un portefeuille seul ne permet pas à l'agent d'échapper au contrôle humain (l'opérateur peut toujours éteindre le modèle ou l'infrastructure dont il dépend). L'automatisation des paiements n'a pas non plus besoin de la blockchain ; les systèmes centralisés peuvent aussi la réaliser.
Le véritable avantage des paiements blockchain réside dans la neutralité et la résistance à la censure, adaptés aux scénarios où l'on craint que les paiements soient bloqués ou influencés.
Idée fausse n°4 : Une IA transparente est une IA digne de confiance
Mettre sur la chaîne la source des données et les enregistrements d'inférence d'un modèle semble être un outil idéal pour garantir la confiance dans l'IA. Cet argument provient d'un blog IBM largement cité, et a été étendu aux agents IA. Mais il faut l'analyser à deux niveaux.
En matière de transparence au niveau du modèle, enregistrer la provenance des données d'entraînement semble apporter de la transparence sur la création du modèle, mais il existe un énorme fossé entre "enregistrement de la provenance" et "garantie du comportement du modèle".
Premièrement, un enregistrement sur chaîne n'est qu'un enregistrement, pas une preuve de provenance (prouver la composition de l'ensemble d'entraînement nécessite des techniques spécialisées).
Deuxièmement, même en connaissant parfaitement les données d'entraînement, cela ne suffit pas à déterminer comment le modèle se comportera, car le processus d'entraînement et l'environnement de calcul déterminent aussi le comportement du modèle.
Troisièmement, même en maîtrisant le processus complet des données au modèle, suffisant pour reproduire le modèle, la non-détermination inhérente à l'entraînement aléatoire rend impossible en principe de "vérifier les poids du modèle en utilisant le processus d'entraînement".
De plus, même en obtenant les poids, il n'existe pas de moyen universellement efficace pour détecter une porte dérobée ou une manipulation adversaire insérée pendant l'entraînement. Mettre sur la chaîne les données du modèle et les informations d'entraînement ne garantit pas directement son comportement ou l'absence de manipulation adversaire.
En matière de transparence au niveau de l'inférence, mettre sur la chaîne les entrées du modèle et les inférences correspondantes semble apporter de la transparence sur l'utilisation du modèle, mais la blockchain rend les transactions transparentes, pas les inférences. Un enregistrement sur chaîne disant "le modèle X avec l'entrée Y a produit l'inférence Z" ne peut presque rien prouver sur la confiance en Z.
Car il ne peut prouver ni "l'exécution correcte" (pour prouver que ce triplet a bien été produit par le modèle X selon ses spécifications, il faut des TEE ou des moyens cryptographiques coûteux), ni la "confiance dans le modèle".
Même si l'exécution correcte est prouvée, le problème plus fondamental est : l'enregistrement complet de la provenance du modèle X ne peut prouver, au niveau sémantique, qu'il répond aux attentes de l'utilisateur ou aux normes de l'industrie ; spécifier le modèle par un hachage de ses poids offre une garantie encore plus faible, car l'identité du modèle n'équivaut pas à sa fiabilité.
La blockchain est effectivement utile pour certains objectifs de confiance, par exemple, une institution publie sur la chaîne le hachage des poids d'un modèle open-source comme référence inaltérable, permettant aux utilisateurs de confirmer qu'ils utilisent le vrai modèle non modifié ; une logique similaire de journal anti-falsification est utilisée pour les enregistrements de mises à jour de firmware et la transparence des certificats (utilisation de journaux en ajout seul, de type blockchain, pour maintenir un enregistrement vérifiable publiquement des émissions de certificats).
Point clé : Il existe encore un fossé important entre mettre sur la chaîne la provenance des données d'un modèle et ses enregistrements d'inférence, et obtenir des "garanties significatives de confiance dans le modèle et ses inférences".
Idée fausse n°5 : La décentralisation rend naturellement les tâches d'IA moins chères
Certains projets présentent les réseaux décentralisés comme une alternative plus efficace et économique à l'IA, typiquement les réseaux d'infrastructure physique décentralisés (DePIN), où les utilisateurs louent leur matériel (comme des GPU), le principal argument étant le coût inférieur. Louer un GPU sur un DePIN peut être bien moins cher que chez un fournisseur cloud comparable.
Mais des machines moins chères ne se traduisent pas nécessairement par un coût total de tâche inférieur. Les nœuds décentralisés communiquent via le réseau public, les besoins de débit et latence des tâches d'IA affectent significativement le coût total, et les tâches très importantes (comme l'entraînement de modèles de pointe) sont généralement limitées par des goulots d'étranglement de débit.
Il est actuellement difficile de faire une comparaison directe des coûts, car l'industrie manque encore de tests de référence systématiques, incapables de comparer les performances et coûts d'une tâche d'IA sur DePIN avec ceux du cloud traditionnel selon les mêmes critères.
Point clé : Les réseaux décentralisés sont une option attractive face au cloud centralisé à coût élevé, mais les données actuelles sont insuffisantes pour prédire quand une tâche sera moins chère sur un DePIN ou une plateforme d'IA décentralisée que sur le cloud centralisé.
Les petites tâches (inférence, entraînement à petite échelle) seront probablement moins chères, tandis que les très grandes tâches (entraînement de modèles de base) pourraient être pénalisées par la communication instable et à faible bande passante entre nœuds. Pour clarifier ces compromis, davantage de recherche est nécessaire.
Le point commun de ces cinq idées fausses est que ce que la blockchain peut fournir est davantage de "l'intégrité" et de la "vérifiabilité", plutôt que la "véracité" ou la "confiance" en elles-mêmes. Crypto x IA en est encore à un stade précoce où il faut avancer avec des preuves, et non sur des récits.






