在此特别感谢 Advait Jayant(Peri Labs)、Sven Wellmann(Polychain Capital)、Chao(Metropolis DAO)、Jiahao(Flock)、Alexander Long(Pluralis Research)Ben Fielding & Jeff Amico (Gensyn) 的建议与反馈。
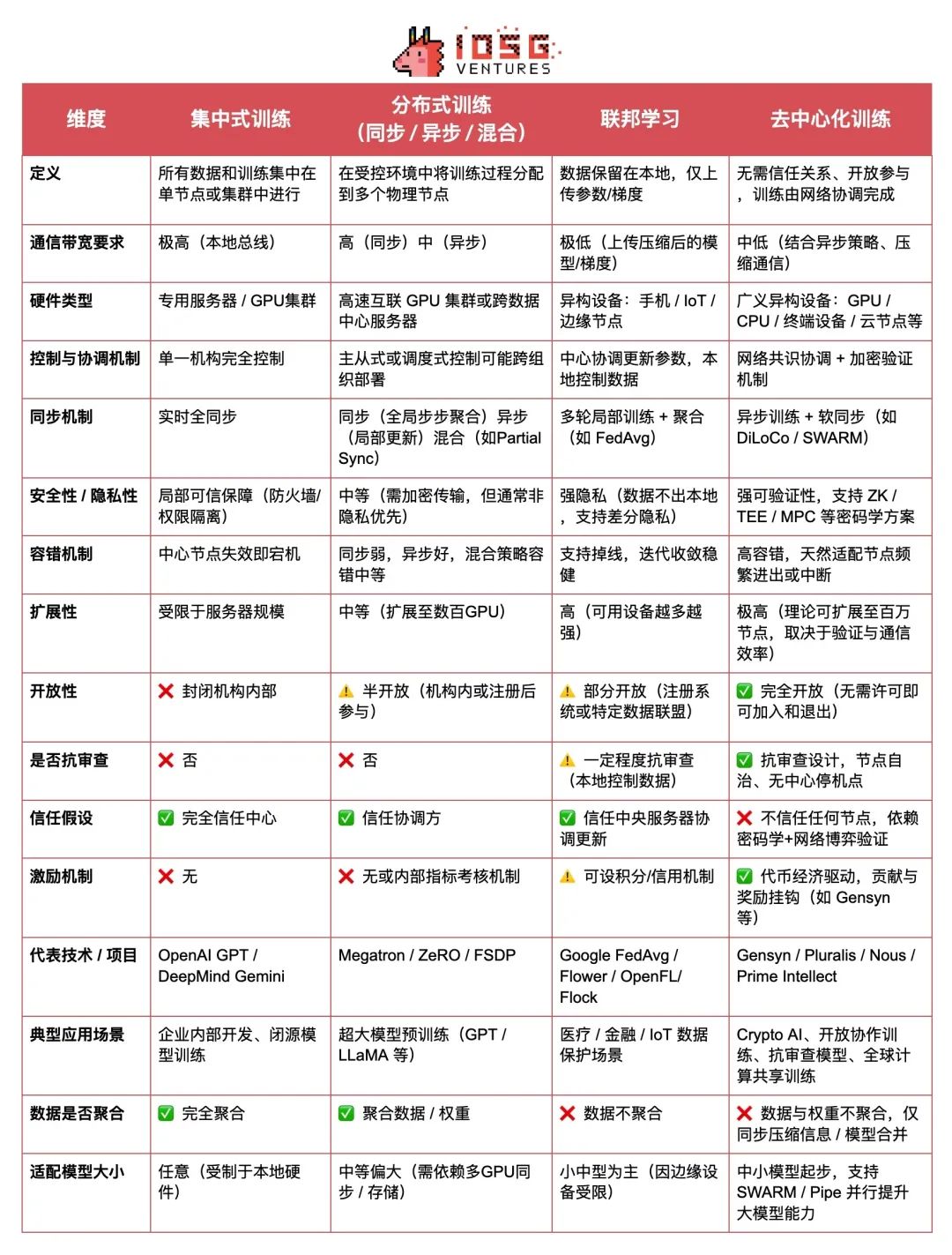
在 AI 的全价值链中,模型训练是资源消耗最大、技术门槛最高的环节,直接决定了模型的能力上限与实际应用效果。相比推理阶段的轻量级调用,训练过程需要持续的大规模算力投入、复杂的数据处理流程和高强度的优化算法支持,是 AI 系统构建的真正“重工业”。 从架构范式来看,训练方式可划分为四类:集中化训练、分布式训练、联邦学习以及本文重点讨论的去中心化训练。
- 集中化训练是最常见的传统方式,由单一机构在本地高性能集群内完成全部训练流程,从硬件(如 NVIDIA GPU)、底层软件(CUDA、cuDNN)、集群调度系统(如 Kubernetes),到训练框架(如基于 NCCL 后端的 PyTorch)所有组件都由统一的控制系统协调运行。这种深度协同的体系结构使得内存共享、梯度同步和容错机制的效率达到最佳,非常适合 GPT、Gemini 等大规模模型的训练,具有效率高、资源可控的优势,但同时存在数据垄断、资源壁垒、能源消耗和单点风险等问题。
- 分布式训练(Distributed Training) 是当前大模型训练的主流方式,其核心是将模型训练任务拆解后,分发至多台机器协同执行,以突破单机计算与存储瓶颈。尽管在物理上具备“分布式”特征,但整体仍由中心化机构控制调度与同步,常运行于高速局域网环境中,通过NVLink高速互联总线技术,由主节点统一协调各子任务。主流方法包括:
- 数据并行(Data Parallel):每个节点训练不同数据参数共享,需匹配模型权重
- 模型并行(Model Parallel):将模型不同部分部署在不同节点,实现强扩展性;
- 管道并行(Pipeline Parallel):分阶段串行执行,提高吞吐率;
- 张量并行(Tensor Parallel):精细化分割矩阵计算,提升并行粒度。
分布式训练是“集中控制 + 分布式执行”的组合,类比同一老板远程指挥多个“办公室”员工协作完成任务。目前几乎所有主流大模型(GPT-4、Gemini、LLaMA 等)都是通过此方式完成训练。
- 去中心化训练(Decentralized Training) 则代表更具开放性与抗审查特性的未来路径。其核心特征在于:多个互不信任的节点(可能是家用电脑、云端 GPU 或边缘设备)在没有中心协调器的情况下协同完成训练任务,通常通过协议驱动任务分发与协作,并借助加密激励机制确保贡献的诚实性。该模式面临的主要挑战包括:
- 设备异构与切分困难:异构设备协调难度高,任务切分效率低;
- 通信效率瓶颈:网络通信不稳定,梯度同步瓶颈明显;
- 可信执行缺失:缺乏可信执行环境,难以验证节点是否真正参与计算;
- 缺乏统一协调:无中央调度器,任务分发、异常回滚机制复杂。
去中心化训练可以理解为:一群全球的志愿者,各自贡献算力协同训练模型,但“真正可行的大规模去中心化训练”仍是一项系统性的工程挑战,涉及系统架构、通信协议、密码安全、经济机制、模型验证等多个层面,但能否“协同有效 + 激励诚实 + 结果正确”尚处于早期原型探索阶段。
- 联邦学习(Federated Learning) 作为分布式与去中心化之间的过渡形态,强调数据本地保留、模型参数集中聚合,适用于注重隐私合规的场景(如医疗、金融)。联邦学习具有分布式训练的工程结构和局部协同能力,同时兼具去中心化训练的数据分散优势,但仍依赖可信协调方,并不具备完全开放与抗审查的特性。可以看作是在隐私合规场景下的一种“受控去中心化”方案,在训练任务、信任结构与通信机制上均相对温和,更适合作为工业界过渡性部署架构。
AI 训练范式全景对比表(技术架构 × 信任激励 × 应用特征)

去中心化训练的边界、机会与现实路径
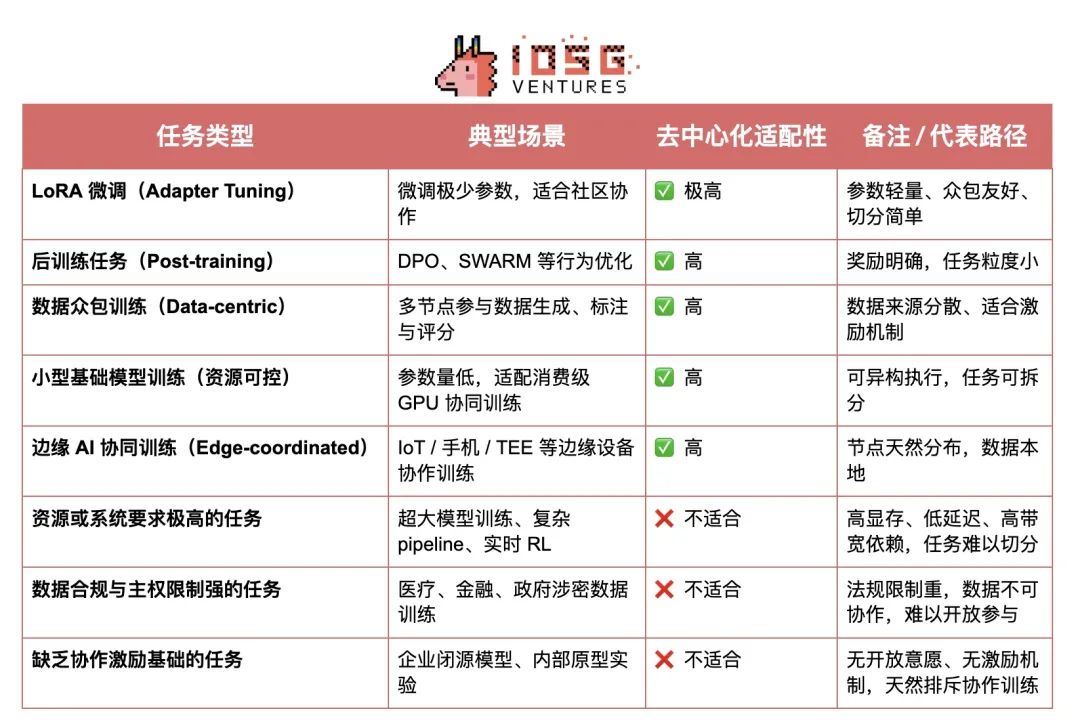
从训练范式来看,去中心化训练并不适用于所有任务类型。在某些场景中,由于任务结构复杂、资源需求极高或协作难度大,其天然不适合在异构、去信任的节点之间高效完成。例如大模型训练往往依赖高显存、低延迟与高速带宽,难以在开放网络中有效切分与同步;数据隐私与主权限制强的任务(如医疗、金融、涉密数据)受限于法律合规与伦理约束,无法开放共享;而缺乏协作激励基础的任务(如企业闭源模型或内部原型训练)则缺少外部参与动力。这些边界共同构成了当前去中心化训练的现实限制。
但这并不意味着去中心化训练是伪命题。事实上,在结构轻量、易并行、可激励的任务类型中,去中心化训练展现出明确的应用前景。包括但不限于:LoRA 微调、行为对齐类后训练任务(如 RLHF、DPO)、数据众包训练与标注任务、资源可控的小型基础模型训练,以及边缘设备参与的协同训练场景。这些任务普遍具备高并行性、低耦合性和容忍异构算力的特征,非常适合通过 P2P 网络、Swarm 协议、分布式优化器等方式进行协作式训练。
去中心化训练任务适配性总览表

去中心化训练经典项目解析
目前在去中心化训练与联邦学习前沿领域中,具有代表性的区块链项目主要包括Prime Intellect、Pluralis.ai、Gensyn、Nous Research 与 Flock.io。从技术创新性与工程实现难度来看,Prime Intellect、Nous Research 和 Pluralis.ai在系统架构与算法设计上提出了较多原创性探索,代表了当前理论研究的前沿方向;而Gensyn 与 Flock.io的实现路径相对清晰,已能看到初步的工程化进展。本文将依次解析这五个项目背后的核心技术与工程架构路,并进一步探讨其在去中心化 AI 训练体系中的差异与互补关系。
Prime Intellect:训练轨迹可验证的强化学习协同网络先行者
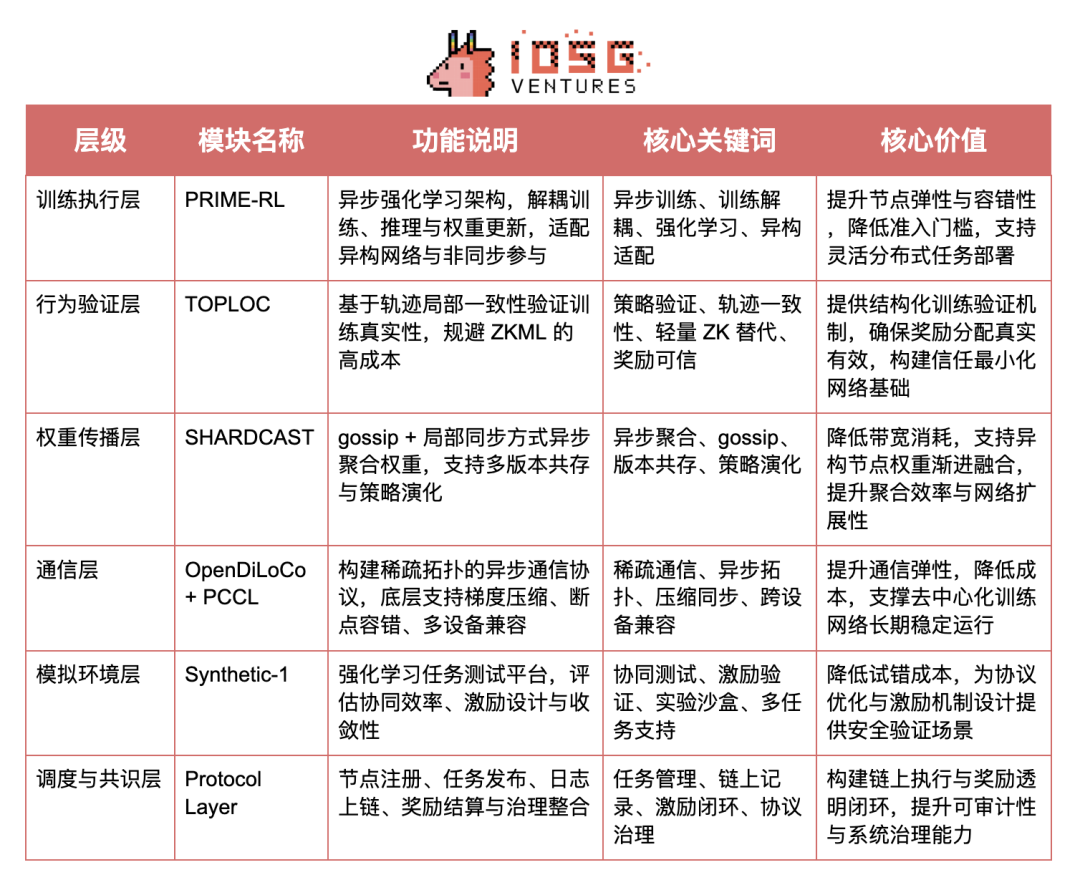
Prime Intellect 致力于构建一个无需信任的 AI 训练网络,让任何人都能参与训练,并对其计算贡献获得可信的奖励。Prime Intellect 希望通过 PRIME-RL + TOPLOC + SHARDCAST 三大模块,构建一个具有可验证性、开放性、激励机制完备的 AI 去中心化训练系统。
01、Prime Intellect 协议栈结构与关键模块价值
02、Prime Intellect 训练关键机制详解
#PRIME-RL:解耦式异步强化学习任务架构
PRIME-RL 是 Prime Intellect 为去中心化训练场景定制的任务建模与执行框架,专为异构网络与异步参与设计。它采用强化学习作为优先适配对象,将训练、推理与权重上传过程结构性解耦,使每个训练节点可以在本地独立完成任务循环,并通过标准化接口与验证和聚合机制协同。相比传统监督学习流程,PRIME-RL 更适合在无中心调度的环境中实现弹性训练,既降低了系统复杂度,也为支持多任务并行和策略演化奠定了基础。
#TOPLOC:轻量级训练行为验证机制
TOPLOC(Trusted Observation & Policy-Locality Check)是 Prime Intellect 提出的训练可验证性核心机制,用于判断一个节点是否真的基于观测数据完成了有效的策略学习。与 ZKML 等重型方案不同,TOPLOC 不依赖全模型重计算,而是通过分析“观测序列↔策略更新”之间的局部一致性轨迹,完成轻量化结构验证。它首次将训练过程中的行为轨迹转化为可验证对象,是实现无需信任训练奖励分配的关键创新,为构建可审计、可激励的去中心化协作训练网络提供了可行路径。
#SHARDCAST:异步权重聚合与传播协议
SHARDCAST 是 Prime Intellect 设计的权重传播与聚合协议,专为异步、带宽受限与节点状态多变的真实网络环境而优化。它结合 gossip 传播机制与局部同步策略,允许多个节点在不同步状态下持续提交部分更新,实现权重的渐进式收敛与多版本演化。相比集中式或同步式 AllReduce 方法,SHARDCAST 显著提升了去中心化训练的可扩展性与容错能力,是构建稳定权重共识与持续训练迭代的核心基础。
#OpenDiLoCo:稀疏异步通信框架
OpenDiLoCo 是 Prime Intellect 团队基于 DeepMind 提出的 DiLoCo 理念独立实现并开源的通信优化框架,专为去中心化训练中常见的带宽受限、设备异构与节点不稳定等挑战而设计。其架构基于数据并行,通过构建 Ring、Expander、Small-World 等稀疏拓扑结构,避免了全局同步的高通信开销,仅依赖局部邻居节点即可完成模型协同训练。结合异步更新与断点容错机制,OpenDiLoCo 使消费级 GPU 与边缘设备也能稳定参与训练任务,显著提升了全球协作训练的可参与性,是构建去中心化训练网络的关键通信基础设施之一。
#PCCL:协同通信库
PCCL(Prime Collective Communication Library)是 Prime Intellect 为去中心化 AI 训练环境量身打造的轻量级通信库,旨在解决传统通信库(如 NCCL、Gloo)在异构设备、低带宽网络中的适配瓶颈。PCCL 支持稀疏拓扑、梯度压缩、低精度同步与断点恢复,可运行于消费级 GPU 与不稳定节点,是支撑 OpenDiLoCo 协议异步通信能力的底层组件。它显著提升了训练网络的带宽容忍度与设备兼容性,为构建真正开放、无需信任的协同训练网络打通了“最后一公里”的通信基础。
03、Prime Intellect 激励网络与角色分工
Prime Intellect 构建了一个无需许可、可验证、具备经济激励机制的训练网络,使任何人都能参与任务并基于真实贡献获得奖励。协议运行基于三类核心角色:
- 任务发起者:定义训练环境、初始模型、奖励函数与验证标准
- 训练节点:执行本地训练,提交权重更新及观测轨迹
- 验证节点:使用 TOPLOC 机制验证训练行为的真实性,并参与奖励计算与策略聚合
协议核心流程包括任务发布、节点训练、轨迹验证、权重聚合(SHARDCAST)与奖励发放,构成一个围绕“真实训练行为”的激励闭环。
04、INTELLECT-2:首个可验证去中心化训练模型的发布
Prime Intellect 于 2025 年 5 月发布了INTELLECT-2,这是全球首个由异步、无需信任的去中心化节点协作训练而成的强化学习大模型,参数规模达32B。INTELLECT-2 模型由遍布三大洲的 100+ GPU 异构节点协同训练完成,使用完全异步架构,训练时长超 400 小时,展示出异步协作网络的可行性与稳定性。这一模型不仅是一次性能上的突破,更是 Prime Intellect 所提出“训练即共识”范式的首次系统落地。INTELLECT-2 集成了PRIME-RL(异步训练结构)、TOPLOC(训练行为验证) 与 SHARDCAST(异步权重聚合)等核心协议模块,标志着去中心化训练网络首次实现了训练过程的开放化、验证性与经济激励闭环。
在性能方面,INTELLECT-2 基于 QwQ-32B训练并在代码和数学上做了专门的RL训练,处于当前开源 RL 微调模型的前沿水准。尽管尚未超越 GPT-4 或 Gemini 等闭源模型,但其真正的意义在于:它是全球首个完整训练过程可复现、可验证、可审计的去中心化模型实验。Prime Intellect 不仅开源了模型,更重要的是开源了训练过程本身—— 训练数据、策略更新轨迹、验证流程与聚合逻辑均透明可查,构建了一个人人可参与、可信协作、共享收益的去中心化训练网络原型。
Pluralis:异步模型并行与结构压缩协同训练的范式探索者
Pluralis 是一个专注于“可信协同训练网络”的 Web3 AI 项目,其核心目标是推动一种去中心化、开放式参与、并具备长期激励机制的模型训练范式。与当前主流集中式或封闭式训练路径不同,Pluralis 提出了一种名为Protocol Learning(协议学习)的全新理念:将模型训练过程“协议化”,通过可验证协作机制和模型所有权映射,构建一个具备内生激励闭环的开放训练系统。
01、核心理念:Protocol Learning(协议学习)
Pluralis 提出的 Protocol Learning 包含三大关键支柱:
- 不可提取模型 (Unmaterializable Models)
- 模型以碎片形式分布在多个节点之间,任何单一节点无法还原完整权重保持闭源。这种设计使模型天然成为“协议内资产”,可实现访问凭证控制、外泄防护与收益归属绑定。
- 基于互联网的模型并行训练(Model-parallel Training over Internet)
通过异步 Pipeline 模型并行机制(SWARM 架构),不同节点仅持有部分权重,通过低带宽网络协作完成训练或推理。
按贡献分配模型所有权(Partial Ownership for Incentives)
所有参与节点根据其训练贡献获得模型部分所有权,从而享有未来收益分成及协议治理权。
02、Pluralis 协议栈的技术架构

03、关键技术机制详解
#Unmaterializable Models
在《A Third Path: Protocol Learning》中首次系统提出,模型权重以碎片形式分布,保障“模型资产”只能在 Swarm 网络中运行,确保其访问与收益皆受协议控制。此机制是实现去中心化训练可持续激励结构的前提。
#Asynchronous Model-Parallel Training
在《SWARM Parallel with Asynchronous Updates》中,Pluralis 构建了基于 Pipeline 的异步模型并行架构,并首次在 LLaMA-3 上进行实证。核心创新在于引入Nesterov Accelerated Gradient(NAG)机制,有效修正异步更新过程中的梯度漂移与收敛不稳问题,使异构设备间的训练在低带宽环境下具备实际可行性。
#Column-Space Sparsification
在《Beyond Top-K》中提出,通过结构感知的列空间压缩方法代替传统 Top-K,避免破坏语义路径。该机制兼顾模型准确性与通信效率,实测在异步模型并行环境中可压缩 90% 以上通信数据,是实现结构感知高效通信的关键突破。
04、技术定位与路径选择
Pluralis 明确以“异步模型并行”为核心方向,强调其相较于数据并行具备以下优势:
- 支持低带宽网络与非一致性节点;
- 适配设备异构,允许消费级 GPU 参与;
- 天然具备弹性调度能力,支持节点频繁上线/离线;
- 以结构压缩 + 异步更新 + 权重不可提取性为三大突破点。
目前根据官方网站公布的六篇技术博客文档,逻辑结构整合为以下三个主线:
- 哲学与愿景:《A Third Path: Protocol Learning》《Why Decentralized Training Matters》
- 技术机制细节:《SWARM Parallel》《Beyond Top-K》《Asynchronous Updates》
- 制度创新探索:《Unmaterializable Models》《Partial Ownership Protocols》
目前 Pluralis 尚未上线产品、测试网或代码开源,原因在于其所选择的技术路径极具挑战:需先解决底层系统架构、通信协议、权重不可导出等系统级难题,才可能向上封装产品服务。
在 2025 年 6 月 Pluralis Research 发布的新论文中,将其去中心化训练框架从模型预训练拓展到了模型微调阶段,支持异步更新、稀疏通信与部分权重聚合,相比此前偏重理论与预训练的设计,本次工作更注重落地可行性,标志着其在训练全周期架构上的进一步成熟。
Gensyn:以可验证执行驱动的去中心化训练协议层
Gensyn是一个专注于“深度学习训练任务可信执行”的 Web3 AI 项目,核心不在于重构模型架构或训练范式,而在于构建一个具备“任务分发 + 训练执行 + 结果验证 + 公平激励”全流程的可验证分布式训练执行网络。通过链下训练 + 链上验证的架构设计,Gensyn 建立起一个高效、开放、可激励的全球训练市场,使“训练即挖矿”成为现实。
01、项目定位:训练任务的执行协议层
Gensyn 不是“怎么训练”,而是“由谁训练、如何验证、如何分润”的基础设施。其本质是训练任务的可验证计算协议,其主要解决:
- 谁来执行训练任务(算力分发与动态匹配)
- 如何验证执行结果(无需全重算,仅验证争议算子)
- 如何分配训练收益(Stake、Slashing 与多角色博弈机制)
02、技术架构总览
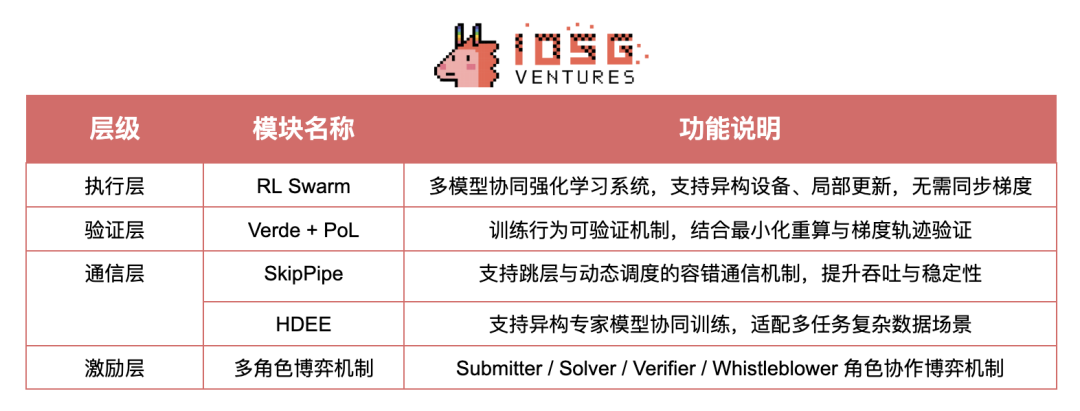
03、模块详解
#RL Swarm:协同强化学习训练系统
Gensyn 首创的 RL Swarm 是一种面向后训练阶段的去中心化多模型协同优化系统,具备以下核心特性:
分布式推理与学习流程:
- 生成阶段(Answering):每个节点独立输出答案;
- 批评阶段(Critique):节点互相点评他人输出,选出最优答案与逻辑;
- 共识阶段(Resolving):预测大多数节点偏好并据此修改自身回答,实现局部权重更新。
Gensyn 所提出的 RL Swarm 是一个去中心化的多模型协同优化系统,每个节点运行独立模型并进行本地训练,无需梯度同步,天然适应异构算力与不稳定网络环境,同时支持节点弹性接入与退出。该机制借鉴 RLHF 与多智能体博弈的思路,但更贴近协同推理网络的动态演化逻辑,节点根据与群体共识结果的一致程度获得奖励,从而驱动推理能力的持续优化与趋同学习。RL Swarm 显著提升了模型在开放网络下的稳健性与泛化能力,已作为核心执行模块率先在 Gensyn 基于 Ethereum Rollup 的Testnet Phase 0中部署上线。
#Verde + Proof-of-Learning:可信验证机制
Gensyn 的 Verde 模块结合了三种机制:
- Proof-of-Learning:基于梯度轨迹与训练元数据判断训练是否真实发生;
- Graph-Based Pinpoint:定位训练计算图中的分歧节点,仅需重算具体操作;
- Refereed Delegation:采用仲裁式验证机制,由 verifier 与 challenger 提出争议并局部验证,极大降低验证成本。
相较于 ZKP 或全重算验证方案,Verde 方案在可验证性与效率之间取得更优平衡。
#SkipPipe:通信容错优化机制
SkipPipe 是为了解决“低带宽 + 节点掉线”场景下的通信瓶颈问题,其核心能力包括:
- 跳层机制(Skip Ratio):跳过受限节点,避免训练阻塞;
- 动态调度算法:实时生成最优执行路径;
- 容错执行:即使 50% 节点失效,推理精度仅下降约 7%。
支持训练吞吐提升高达 55%,并实现“early-exit 推理”、“无缝重排”、“推理补全”等关键能力。
#HDEE:跨领域异构专家集群
HDEE(Heterogeneous Domain-Expert Ensembles)模块致力于优化以下场景:
- 多领域、多模态、多任务训练;
- 各类训练数据分布不均衡、难度差异大;
- 设备计算能力异构、通信带宽不一致的环境下任务分配与调度问题。
其核心特性:
- MHe-IHo:为不同难度的任务分配不同大小的模型(模型异构、训练步长一致);
- MHo-IHe:任务难度统一、但训练步长异步调整;
- 支持异构专家模型 + 可插拔训练策略,提升适应性与容错性;
- 强调“并行协同 + 极低通信 + 动态专家分配”,适用于现实中复杂的任务生态。
#多角色博弈机制:信任与激励并行
Gensyn 网络引入四类参与者:
- Submitter:发布训练任务、设定结构与预算;
- Solver:执行训练任务,提交结果;
- Verifier:验证训练行为,确保其合规有效;
- Whistleblower:挑战验证者,获取仲裁奖励或承担罚没。
该机制灵感来源于 Truebit 经济博弈设计,通过强制插入错误 + 随机仲裁,激励参与者诚实协作,确保网络可信运行。
04、测试网与路线图规划

Nous Research:主体性 AI 理念驱动的认知演化式训练系统
Nous Research是目前少数兼具哲学高度与工程实现的去中心化训练团队,其核心愿景源于“Desideratic AI”理念:将 AI 视为具有主观性与演化能力的智能主体,而非单纯的可控工具。Nous Research 的独特性在于:它不是将 AI 训练当作“效率问题”来优化,而是将其视为“认知主体”的形成过程。在这一愿景驱动下,Nous 聚焦构建一个由异构节点协同训练、无需中心调度、可抗审查验证的开放式训练网络,并通过全栈式工具链进行系统化落地。
01、理念支撑:重新定义训练的“目的”
Nous 并未在激励设计或协议经济学上投入过多,而是试图改变训练本身的哲学前提:
- 反对“alignmentism”:不认同以人类控制为唯一目标的“调教式训练”,主张训练应鼓励模型形成独立认知风格;
- 强调模型主体性:认为基础模型应保留不确定性、多样性与幻觉生成能力(hallucination as virtue);
- 模型训练即认知形成:模型不是“优化任务完成度”,而是参与认知演化过程的个体。
这一训练观虽然“浪漫”,但反映出 Nous 设计训练基础设施的核心逻辑:如何让异构模型在开放网络中演化,而非被统一规训。
02、训练核心:Psyche 网络与 DisTrO 优化器
Nous 对去中心化训练最关键的贡献,是构建了Psyche 网络与底层通信优化器DisTrO(Distributed Training Over-the-Internet),共同构成训练任务的执行中枢:DisTrO + Psyche 网络具备多项核心能力,包括通信压缩(采用 DCT + 1-bit sign 编码,极大降低带宽需求)、节点适配性(支持异构 GPU、断线重连与自主退出)、异步容错(无需同步亦可持续训练,具备高容错性)、以及去中心化调度机制(无需中心协调器,基于区块链实现共识与任务分发)。这一架构为低成本、强弹性、可验证的开放训练网络提供了现实可行的技术基础。

这一架构设计强调实际可行性:不依赖中心服务器、适配全球志愿节点、并具备训练结果的链上可追踪性。
03、Hermes / Forge / TEE_HEE 构成的推理与代理体系
除了构建去中心化训练基础设施,Nous Research 还围绕“AI 主体性”理念开展了多个探索性系统实验:
#Hermes 开源模型系列
Hermes 1 至 3 是 Nous 推出的代表性开源大模型,基于 LLaMA 3.1 训练,涵盖 8B、70B 和 405B 三种参数规模。该系列旨在体现 Nous 所倡导的“去指令化、保留多样性”训练理念,在长上下文保持、角色扮演、多轮对话等方面展现出更强的表达力与泛化能力。
#Forge Reasoning API:多模式推理系统
Forge 是 Nous 自研的推理框架,结合三种互补机制以实现更具弹性与创造力的推理能力:
- MCTS(Monte Carlo Tree Search):适用于复杂任务的策略搜索;
- CoC(Chain of Code):引入代码链与逻辑推理的结合路径;
- MoA(Mixture of Agents):允许多个模型进行协商,提升输出的广度与多样性。
该系统强调“非确定性推理”与组合式生成路径,是对传统指令对齐范式的有力回应。
#TEE_HEE:AI 自主代理实验
TEE_HEE 是 Nous 在自治代理方向的前沿探索,旨在验证 AI 是否能够在可信执行环境(TEE)中独立运行并拥有唯一的数字身份。该代理具备专属的 Twitter 和以太坊账户,所有控制权限由远程可验证的 enclave 管理,开发者无法干预其行为。实验目标是构建具备“不可篡改性”与“独立行为意图”的 AI 主体,迈出构建自治型智能体的重要一步。
#AI 行为模拟器平台
Nous 还开发了包括 WorldSim、Doomscroll、Gods & S8n 等多个模拟器,用于研究 AI 在多角色社会环境中的行为演化与价值形成机制。尽管不直接参与训练流程,这些实验为长期自治 AI 的认知行为建模奠定了语义层基础。
Flock:区块链增强型联邦学习网络
Flock.io 是一个基于区块链的联邦学习平台,旨在实现 AI 训练的数据、计算和模型的去中心化。FLock 倾向于“联邦学习 + 区块链奖励层”的整合框架,本质上是对传统 FL 架构的链上演进版本,而非构建全新训练协议的系统性探索。与 Gensyn、Prime Intellect、Nous Research 和 Pluralis 等去中心化训练项目相比,Flock 侧重隐私保护与可用性改进,而非在通信、验证或训练方法上展开理论突破,其真正适合对比的对象为Flower、FedML、OpenFL等联邦学习系统。
01、Flock.io 的核心机制
#联邦学习架构:强调数据主权与隐私保护
Flock 基于经典联邦学习(Federated Learning, FL)范式,允许多个数据拥有者在不共享原始数据的前提下协同训练统一模型,重点解决数据主权、安全与信任问题。核心流程包括:
- 本地训练:每个参与者(Proposer)在本地设备上训练模型,不上传原始数据;
- 链上聚合:训练完成后提交本地权重更新,由链上 Miner聚合为全局模型;
- 委员会评估:通过 VRF 随机选举 Voter 节点使用独立测试集评估聚合模型效果并打分;
- 激励与惩罚:根据得分结果执行奖励或罚没抵押金,实现抗作恶与动态信任维护。
#区块链集成:实现去信任的系统协调
Flock 将训练过程的核心环节(任务分配、模型提交、评估评分、激励执行)全部链上化,以实现系统透明、可验证与抗审查。主要机制包括:
- VRF 随机选举机制:提升 Proposer 与 Voter 的轮换公平性与抗操控能力;
- 权益抵押机制(PoS):通过代币抵押与惩罚约束节点行为,提升系统鲁棒性;
- 链上激励自动执行:通过智能合约实现任务完成与评估结果绑定的奖励分发与 slashing 扣罚,构建无需信任中介的协作网络。
- #zkFL:零知识聚合机制的隐私保护创新
Flock 引入 zkFL 零知识聚合机制,使 Proposer 可提交本地更新的零知识证明,Voter 无需访问原始梯度即可验证其正确性,在保障隐私的同时提升训练过程的可信性,代表了联邦学习在隐私保护与可验证性融合方向上的重要创新。
02、Flock 的核心产品组件
AI Arena:是 Flock.io 的去中心化训练平台,用户可通过 train.flock.io 参与模型任务,担任训练者、验证者或委托者角色,通过提交模型、评估表现或委托代币获得奖励。目前任务由官方发布,未来将逐步开放给社区共创。
FL Alliance:是 Flock 联邦学习客户端,支持参与者使用私有数据对模型进一步微调。通过 VRF 选举、staking 与 slashing 机制,保障训练过程的诚实性与协作效率,是连接社区初训与真实部署的关键环节。
AI Marketplace:是模型共创与部署平台,用户可提议模型、贡献数据、调用模型服务,支持数据库接入与 RAG 强化推理,推动 AI 模型在各类实际场景中的落地与流通。
相较于去中心化训练项目,Flock 这类基于联邦学习的系统在训练效率、可扩展性与隐私保护方面更具优势,尤其适用于中小规模模型的协同训练,方案务实且易于落地,更偏向工程层面的可行性优化;而 Gensyn、Pluralis 等项目则在训练方法与通信机制上追求更深层次的理论突破,系统挑战更大,但也更贴近真正的“去信任、去中心”的训练范式探索。
EXO:边缘计算的去中心化训练尝试
EXO 是当前边缘计算场景中极具代表性的AI 项目,致力于在家庭级消费设备上实现轻量化的 AI 训练、推理与 Agent 应用。其去中心化训练路径强调“低通信开销 + 本地自主执行”,采用 DiLoCo 异步延迟同步算法与 SPARTA 稀疏参数交换机制,大幅降低多设备协同训练的带宽需求。系统层面,EXO 并未构建链上网络或引入经济激励机制,而是推出单机多进程模拟框架 EXO Gym,支持研究者在本地环境中便捷开展分布式训练方法的快速验证与实验。
01、核心机制概览
- DiLoCo 异步训练:每 H 步进行一次节点同步,适配非稳定网络;
- SPARTA 稀疏同步:每步仅交换极少量参数(如 0.1%),保持模型相关性并降低带宽需求;
- 异步组合优化:两者可组合使用,在通信与性能之间取得更优折中。
evML 验证机制探索:Edge-Verified Machine Learning(evML) 提出使用 TEE / Secure Context进行低成本计算验证,通过远程验证+抽查机制实现无需质押的边缘设备可信参与,是经济安全与隐私保障之间的工程型折中方案。
02、工具与场景应用
- EXO Gym:可在单台设备模拟多节点训练环境,支持 NanoGPT、CNN、Diffusion 等模型的通信策略实验;
- EXO Desktop App:面向个人用户的桌面 AI 工具,支持本地大模型运行、iPhone 镜像控制、私人上下文集成(如短信、日历、视频记录)等隐私友好型个性化功能。
EXO Gym更像是一个以探索导向的去中心化训练实验项目,主要通过整合现有的通信压缩技术(如 DiLoCo 与 SPARTA)来实现训练路径的轻量化。相较于 Gensyn、Nous、Pluralis 等项目,EXO 尚未迈入链上协作、可验证激励机制或真实分布式网络部署等核心阶段。

去中心化训练的前链条引擎:模型预训练全景研究
面对去中心化训练中普遍存在的设备异构、通信瓶颈、协调困难与缺乏可信执行等核心挑战,Gensyn、Prime Intellect、Pluralis 与 Nous Research 分别提出了具有差异化的系统架构路径。从训练方法和通信机制两个层面来看,这四个项目展现了各自独特的技术焦点与工程实现逻辑。
在训练方法优化方面,四者分别从协同策略、更新机制和异步控制等关键维度展开探索,覆盖了从预训练到后训练的不同阶段。
- Prime Intellect 的 PRIME-RL属于面向预训练阶段的异步调度结构,通过“本地训练 + 周期性同步”的策略,在异构环境下实现高效而可验证的训练调度机制。该方法强具有较强的通用性与灵活性。理论创新度较高,在训练控制结构上提出明确范式;工程实现难度中高,对底层通信与控制模块有较高要求。
- Nous Research 推出的 DeMo 优化器,则聚焦于异步低带宽环境下的训练稳定性问题,实现了异构 GPU 条件下的高容错梯度更新流程,是当前少数在“异步通信压缩闭环”上完成理论与工程统一的方案。理论创新度很高,特别是在压缩与调度协同路径上具有代表性;工程实现难度也很高,尤其依赖异步并行的协调精度。
- Pluralis 的 SWARM + NAG则是目前异步训练路径中最具系统性与突破性的设计之一。它基于异步模型并行框架,引入 Column-space 稀疏通信与 NAG 动量修正,构建出一种可在低带宽条件下稳定收敛的大模型训练方案。理论创新度极高,是异步协同训练的结构性开创者;工程难度同样极高,需要多级同步与模型切分的深度集成。
- Gensyn 的 RL Swarm主要服务于后训练阶段,聚焦于策略微调与智能体协同学习。其训练过程遵循“生成 - 评估 - 投票”的三步流程,特别适合多代理系统中复杂行为的动态调整。理论创新度中高,主要体现在智能体协同逻辑上;工程实现难度适中,主要挑战在于系统调度与行为收敛控制。
在通信机制优化层面,这四个项目亦各有针对性布局,普遍关注带宽瓶颈、节点异构与调度稳定性问题的系统解法。
- Prime Intellect 的 PCCL是一个用于替代传统 NCCL 的底层通信库,旨在为上层训练协议提供更稳健的集体通信基础。理论创新度中高,在容错通信算法上有一定突破;工程难度中等,具备较强的模块适配性。
- Nous Research 的 DisTrO是 DeMo 的通信核心模块,强调在低带宽下实现最小通信开销的同时保障训练闭环的连贯性。理论创新度高,在调度协同结构上具备通用性设计价值;工程难度高,对压缩精度与训练同步要求高。
- Pluralis 的通信机制深度嵌入 SWARM 架构中,显著降低了大模型异步训练中的通信负载,在保障收敛性的同时保持高效吞吐。理论创新度高,为异步模型通信设计树立了范式;工程难度极高,依赖分布式模型编排与结构稀疏性控制。
- Gensyn 的 SkipPipe是配套 RL Swarm 的容错调度组件。该方案部署成本低,主要用于工程落地层的训练稳定性增强。理论创新度一般,更多是已知机制的工程化实现;工程难度较低,但在实际部署中实用性强。
此外,我们可以从区块链协作层与AI训练层更为宏观的两大类衡量去中心化训练项目的价值:
区块链协作层面:强调协议可信性与激励协作逻辑
- 可验证性: 对训练过程是否可验证、是否引入博弈或加密机制建立信任;
- 激励机制:是否设计了任务驱动的 Token 奖励/角色机制;
- 开放性与准入门槛:节点是否易于接入,是否中心化或许可控制。
AI 训练系统层面:突出工程能力与性能可达性
- 调度与容错机制:是否容错、异步、动态、分布式调度;
- 训练方法优化:是否对模型训练算法或结构有优化;
- 通信路径优化:是否压缩梯度/稀疏通信,适应低带宽。
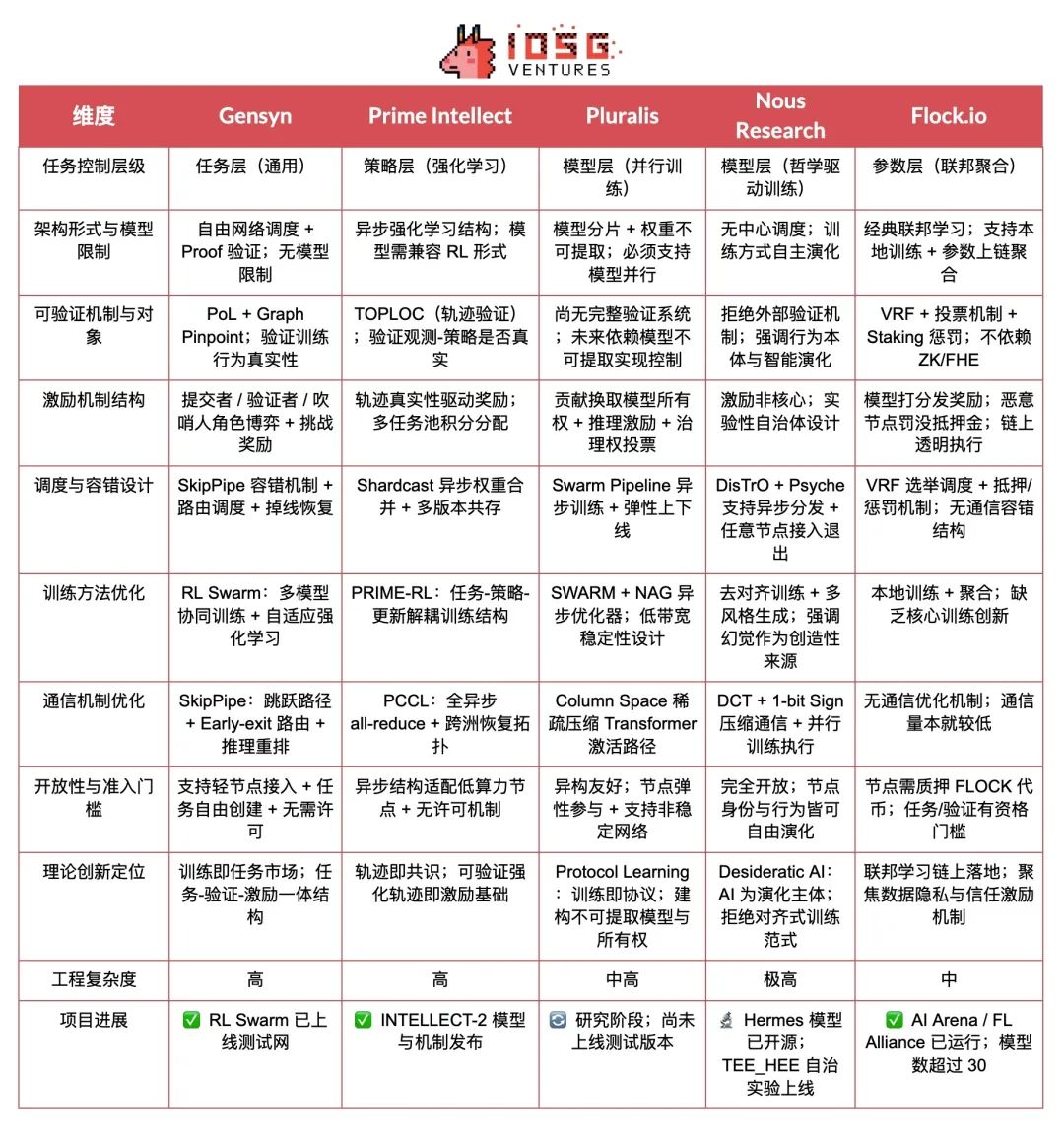
以下表格基于上述指标体系,对 Gensyn、Prime Intellect、Pluralis 和 Nous Research 在去中心化训练路径上的技术深度、工程成熟度与理论创新进行了系统性评估。

去中心化训练的后链条生态:基于 LoRA 的模型微调
在去中心化训练的完整价值链中,Prime Intellect、Pluralis.ai、Gensyn 和 Nous Research 等项目主要聚焦于模型预训练、通信机制与协同优化等前端基础设施建设。然而,另有一类项目则专注于训练后阶段的模型适配与推理部署(post-training fine-tuning & inference delivery),不直接参与预训练、参数同步或通信优化等系统性训练流程。代表性项目包括 Bagel、Pond 和 RPS Labs,他们均以 LoRA 微调方法为核心,构成去中心化训练生态图谱中关键的“后链条”一环。
LoRA + DPO:Web3 微调部署的现实路径
LoRA(Low-Rank Adaptation)是一种高效的参数微调方法,其核心思路是在预训练大模型中插入低秩矩阵来学习新任务,同时冻结原始模型参数。这一策略显著降低了训练成本与资源消耗,提升了微调速度与部署灵活性,尤其适用于以模块化、组合调用为特征的 Web3 场景。
传统的大语言模型如 LLaMA、GPT-3 等往往拥有数十亿甚至千亿级参数,直接微调成本高昂。而 LoRA 通过仅训练插入的少量参数矩阵,实现对大模型的高效适配,成为当前最具实用性的主流方法之一。
Direct Preference Optimization(DPO)作为近年来兴起的语言模型后训练方法,常与 LoRA 微调机制协同使用,用于模型行为对齐阶段。相比传统的RLHF(Reinforcement Learning from Human Feedback)方法,DPO 通过对成对样本的直接优化实现偏好学习,省去了复杂的奖励建模与强化学习过程,结构更为简洁,收敛更加稳定,尤其适合轻量化与资源受限环境下的微调任务。由于其高效与易用性,DPO 正逐渐成为众多去中心化 AI 项目在模型对齐阶段的优选方案。
强化学习(Reinforcement Learning, RL):后训练微调的未来演进方向
从长期视角来看,越来越多的项目将强化学习(Reinforcement Learning, RL)视为去中心化训练中更具适应性与演化潜力的核心路径。相较于依赖静态数据的监督学习或参数微调机制,RL 强调在动态环境中持续优化策略,天然契合 Web3 网络中异步、异构与激励驱动的协作格局。通过与环境持续交互,RL 能够实现高度个性化、持续增量式的学习过程,为 Agent 网络、链上任务市场及智能经济体构建提供可演化的“行为智能”基础设施。
这一范式不仅在理念上高度契合去中心化精神,也具备显著的系统优势。然而,受限于较高的工程门槛和复杂的调度机制,RL 在当前阶段的落地仍面临较大挑战,短期内尚难广泛推广。
值得注意的是,Prime Intellect 的 PRIME-RL 以及 Gensyn 的 RL Swarm正在推动 RL 从后训练微调机制向预训练主结构演进,试图构建一个以 RL 为中心、无需信任协调的协同训练体系。
Bagel(zkLoRA):LoRA 微调的可信验证层
Bagel 基于 LoRA 微调机制,引入零知识证明(ZK)技术,致力于解决“链上模型微调”过程中的可信性与隐私保护难题。zkLoRA 并不参与实际的训练计算,而是提供一种轻量、可验证的机制,使外部用户无需访问原始数据或权重,即可确认某个微调模型确实源自指定的基础模型和 LoRA 参数。
与 Gensyn 的 Verde 或 Prime Intellect 的 TOPLOC 所关注的训练过程“行为是否真实发生”的动态验证不同,Bagel 更专注于“微调结果是否可信”的静态验证。zkLoRA 的最大优势在于验证资源消耗低、保护隐私强,但其应用范围通常局限于参数变动较小的微调任务。
Pond:GNN 场景下的微调与智能体演化平台
Pond 是当前业内唯一专注于图神经网络(GNN)微调的去中心化训练项目,服务于结构化数据应用,如知识图谱、社交网络与交易图等。其通过支持用户上传图结构数据并参与模型训练反馈,为个性化任务提供了一个轻量、可控的训练与推理平台。
Pond 同样采用 LoRA 等高效微调机制,其核心目标是在 GNN 架构上实现模块化、可部署的智能体系统,开辟了“小模型微调 + 多智能体协作”在去中心化语境下的新探索路径。
RPS Labs:面向 DeFi 的 AI 驱动流动性引擎
RPS Labs 是一个基于 Transformer 架构的去中心化训练项目,致力于将微调后的 AI 模型用于 DeFi 流动性管理,主要部署在 Solana 生态中。其旗舰产品 UltraLiquid 是一套主动式做市引擎,利用微调后的模型动态调节流动性参数,降低滑点、提升深度,并优化代币发行与交易体验。
此外,RPS 还推出 UltraLP 工具,支持流动性提供者实时优化其在 DEX 上的资金分配策略,从而提升资本效率、降低无常损失风险,体现了 AI 微调在金融场景中的实用价值。

从前链条引擎到后链条生态:去中心化训练的前路
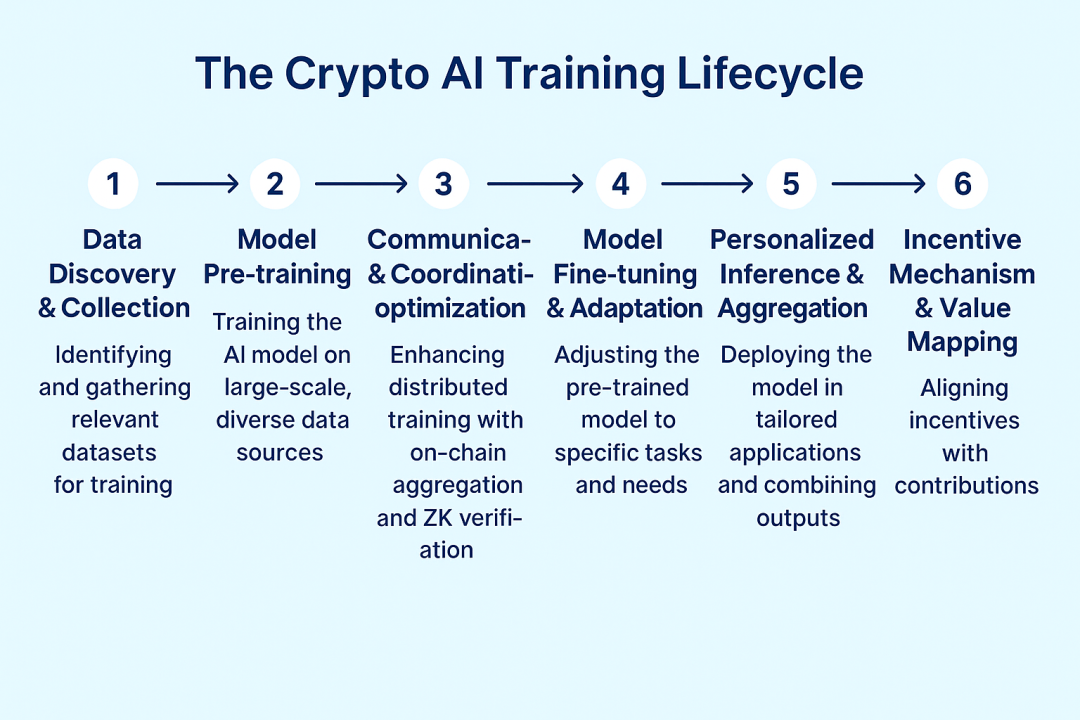
在去中心化训练的完整生态图谱中,整体可划分为两大类:前链条引擎 对应模型预训练阶段、后链条生态对应模型微调部署阶段,构成了从基础设施到应用落地的完整闭环。
前链条引擎聚焦于模型预训练的底层协议构建,由Prime Intellect、Nous Research、Pluralis.ai、Gensyn等项目代表。它们致力于打造具备异步更新、稀疏通信与训练可验证性的系统架构,在去信任网络环境中实现高效、可靠的分布式训练能力,构成了去中心化训练的技术根基。
与此同时,Flock作为中间层代表,通过联邦学习路径,融合模型聚合、链上验证与多方激励等机制,在训练与部署之间建立起可落地、可协作的桥梁,为多节点协同学习提供实践范式。
后链条生态则聚焦于模型的微调与应用层部署。项目如Pond、Bagel与RPS Labs,围绕 LoRA 微调方法展开:Bagel 提供链上可信验证机制,Pond 专注于图神经网络的小模型演化,RPS 则将微调模型应用于 DeFi 场景的智能做市。它们通过推理 API 与 Agent SDK 等组件,为开发者和终端用户提供低门槛、可组合的模型调用与个性化定制方案,是去中心化 AI 落地的重要入口。
我们相信,去中心化训练不仅是区块链精神在 AI 时代的自然延伸,更是全球协作式智能生产力体系的基础设施雏形。未来,当我们回望这条充满挑战的前路征途,仍将以那句初心共勉:去中心化不只是手段,它本身就是价值。