文 | 象先志
罗福莉发了一条X,要给小米MiMo的降价风波划上一个句号。
5 月 26 日,小米 MiMo 官方账号在 X 上甩出一条公告:MiMo-V2.5 系列 API 永久降价,最高降幅 99%。所有 context 长度统一定价,Token 套餐升级 5-8 倍。
这条公告在国内 AI 圈刷了一整周。业界第一反应分成几派。最大那派说这是"又一轮价格战"——这两年从智谱、DeepSeek、字节豆包到阿里通义,国产大模型轮着降价,谁不在卷。
另一派往悲观处看:小米刚公告今年利润腰斩,这时候还往 AI 烧 600 亿、API 直接砍九成——典型的"亏本抢市场"。还有人觉得这是 DeepSeek 效应继续——后者把整个行业的定价基准拽到了地板上,谁不跟谁出局。
所以作为MiMo的负责人,罗福莉在昨晚直接拿出了一份 5000 字的技术博客,把降价的工程账目公开给了所有人。
“看,这是真实的工程能力,不是营销手段”。
要听懂罗福莉在说什么,先得明白这个 99% 到底降了什么。
它不是全模型降价。99% 的折扣专门针对一档叫 Input (Cache Hit) 的定价——也就是"用户在长对话里重复读历史上下文"那部分。普通的新输入(No Cache Hit)降幅小很多,模型输出(Output)降幅最小。
如果你把模型当成一家咖啡店,这件事就好理解了。
你点一杯半糖拿铁,咖啡店有两种做法:每次从头磨豆子量糖浆倒奶,原料人工都付一次;但是模型知道这周你每天都要喝同样的半糖拿铁,干脆做一大壶存进冰柜,下次按一杯舀一份。MiMo 这次做的是后者——把用户重复读的部分从"现算"改成了"现取",所以这部分的真实成本接近 0,自然能给 99% 折扣。
要做到"现取",技术博客里讲了六个工程,每一个都不能缺。下面一个一个拆开看。
工程一:把模型"记忆"压到 1/7
模型在和你对话时,每个 token 都要算一份"中间状态",存起来供下一步用。这个东西叫 KVCache——可以理解成模型的"短期记忆笔记本"。每说一句话,模型在笔记本上记下这句话的摘要,下次直接翻笔记,不用从头听一遍你说过的所有内容。
传统模型每一层都做"Full Attention"——也就是每个 token 都要看完整段对话所有 token,笔记本越翻越厚。MiMo-V2.5-Pro 改了架构:70 层里 60 层只看最近 128 个 token(SWA,Sliding Window Attention),只有 10 层"档案管理员"看全部。
结果是 KVCache 体积直接压到 Full Attention 的 1/7,计算量同样是 1/7。
这是降本的第一块地基。打个比方,原本公司每个员工都被要求记住所有的会议记录,结果每个人的脑子都不够用、效率也低。新规定把 60 个员工的脑负担降到 1/7,只留 10 个档案管理员管全部历史——公司整体记忆能力没下降,但效率提升 7 倍。
工程二:让 SWA 省下的空间真的能用
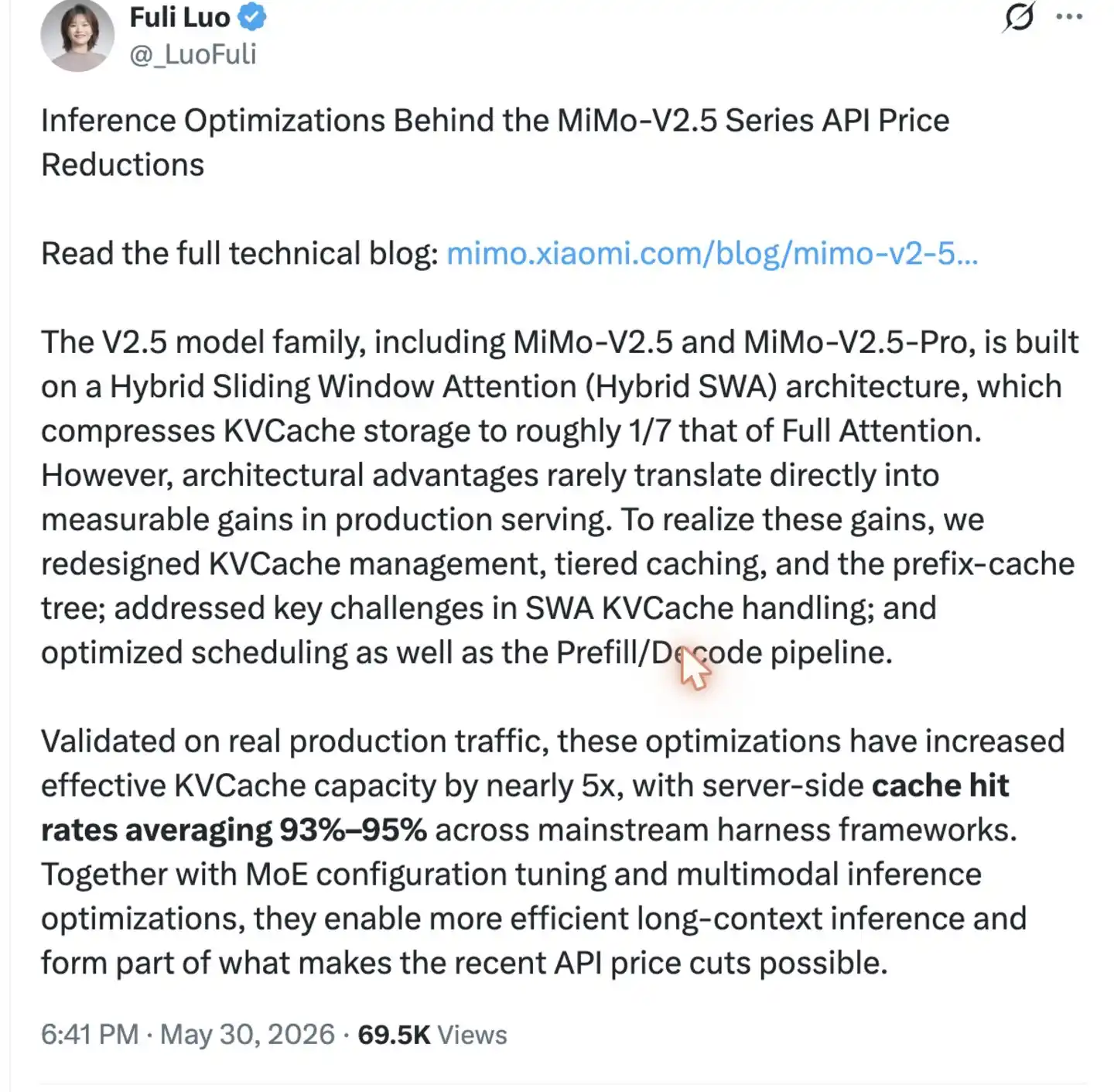
架构上把笔记本压到 1/7 是第一步,但要把"理论上的 1/7"真的兑现成"实际的 1/7",还有一道坎。
传统的 KVCache 系统是按"最大可能用量"给所有层统一分配显存的。意思是:哪怕 60 层 SWA 只需要小本子,系统也按"档案管理员的大本子"给所有层都分配——SWA 省下来的空间被白白预留了,等于没省。
罗福莉团队的做法是把 KVCache 拆成两个独立的池子。Full Attention 那 10 层走"大池子",按全长分配;SWA 那 60 层走"小池子",只按 128 个 token 的窗口分配。
打个比方,原本公司给每个员工都发了"能装 100 年文件的档案柜"——但 60 个员工其实只需要"装一周文件的小柜子",那些大柜子里 99% 的空间是空的。新做法是按实际需要分柜子。结果整个办公室能多装 5 倍以上的同事进来工作——同样一台 GPU 能服务的并发用户数翻了 5 倍。
这一步看上去简单,但没有它,前面 SWA 架构的优势等于白设计。
工程三:让"老用户重复读"真能命中缓存
笔记本压到 1/7 + 空间真用得起,下一步要解决一个老问题:前缀缓存的命中率。
很多用户的对话有相同开头——同一段 system prompt、同一段代码库、同一份长文档。系统会把这些算过的结果存起来,下一次匹配上就直接复用。这个机制叫前缀缓存。
但 SWA 模式下出现一个坑:两条请求 token 一样,不等于 KV 还在。可能前缀算过,但 SWA 窗口外的部分早就被淘汰了。如果系统还按"token 一样就命中"的旧规则给你复用,会读到无效或被覆盖的数据,模型效果会直接崩。
罗福莉团队升级了规则到"窗口安全长度"——只承诺"你能完整借到的那部分"。
打个比方,图书馆有 100 万本书,你想借全套共计三本的《三体》。原来的架构会告诉你"这本书在",你跑过去发现书架上只剩封面和第一部,后面两部都被借走了。这种"伪命中"让你白跑一趟还要重借。新系统的规则改成只承诺你能完整借到的那部分——先给你第一本,然后把后面两本再给你调过来。
听起来好像更严格、命中率会下降。但实际相反:因为 SWA 让 KVCache 体积压到 1/7,同样存储空间能装的内容多了好几倍,真实命中率反而大幅度提升。
罗福莉博客里给了线上实测数字:主流 harness 框架下服务端 cache 命中率平均 93%,高频长周期用户可达 95% 以上。
翻译一下这个数字的含义:95% 的"重复读"请求根本不用 GPU 算,直接从缓存里取。这就是 99% 折扣的物理基础。
工程四:把“缓存”装进GPU自带的SSD
命中率上去了,下一个问题是:这些缓存装在哪里。
显存(GPU 上的 HBM 内存)很贵也很有限——一台 H100 八卡机才 640GB 显存,但 MiMo 要存的 KVCache 可能是几十 TB 量级。所以必须分层:最近用的放显存(L1),稍微旧的放 CPU 内存(L2),冷数据存到分布式缓存(L3)。
跟你管钱一个道理。钱包里的现金是显存——随用随取但放不了多少。银行卡余额是 CPU 内存——取一次要 30 秒但能放很多。定期存款是 L3 分布式缓存——取一次要 2 分钟但便宜很多。
行业的常规做法是为 L3 单独建一套存储集群,专用机型、专用机房,月月付租金。
小米存储团队的做法不一样。他们自研了一套叫 GCache 的分布式缓存,直接部署在 GPU 机器自带的 SSD 上——跟训练任务、推理任务混布在同一台机器里。
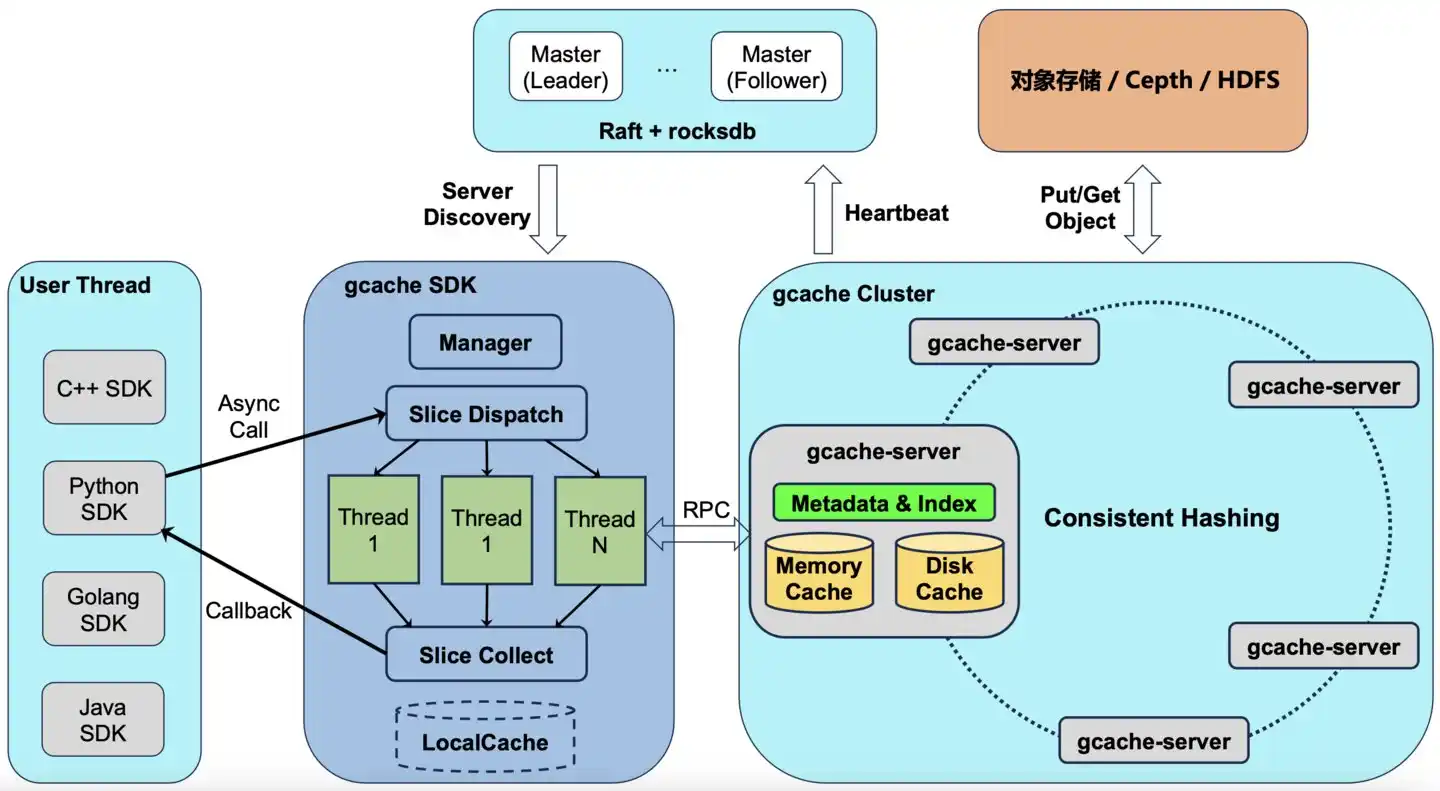
普通话翻译:别人为了存大量数据,专门租了一个仓库;小米发现 GPU 机器的车库其实空着,直接把数据存进去了。月租金省了。
技术博客的原话是:"额外的存储成本为 0。"
这件事的杀伤力比看上去大。常规的"AI 公司算力账"里,存储成本是一个固定支出项——你的模型越大、用户越多,存储账单越长。GCache 这套做法把这一项直接打掉。结合 SWA 的小体积 + 命中率 93-95%,KVCache 在 L3 的存活时间(TTL)从几分钟延长到几小时甚至几天——TTL 越长,历史 context 的可命中窗口越宽,缓存命中率越高,99% 那个折扣就越站得住。
工程五:让命中缓存的请求走最短的路
缓存能装、能查、还便宜,最后一步是:怎么让正确的请求被路由到正确的机器上。
小米开发了一套自己的调度系统叫 LLM-Router,干了三件事:
一是亲和调度。前缀相同的请求路由到同一台机器,让缓存复用最大化。
二是长度分桶。把短请求(0-64K)、中请求(64K-256K)、长请求(256K-1M)分到不同的处理通道,避免短请求被长请求拖累。
三是TTFT 优化。在排队等推理的队列里,优先调度真实计算量小的请求(也就是大量命中缓存的请求)——避免它们被"全新输入"那种重计算请求阻塞。
比如,在常规的机场调度中,所有飞同一个目的地的乘客集中到同一个候机厅,共享行李提取流程——这是亲和调度。带登机箱的和带 3 大箱托运的分两条安检通道走,快的不被慢的拖——这是长度分桶。登机时优先放只带登机箱的人,他们登机快,让飞机能早起飞——这是 TTFT 优化。
这套调度策略实测把 L2 缓存命中率提升了 25%,单机输入吞吐提升 30%,长请求 P90 延迟降低 30%。
翻译过来就是:同一台 GPU 能服务更多用户。降价的另一半逻辑就在这里——单位算力的有效产出更高,单位用户成本更低。
工程六:让模型"打字"也变快
前面五件事都在优化"读"那一侧——让用户重复读历史 context 的成本压到接近 0。第六件事是优化"写"那一侧——也就是模型生成下一个 token 的过程。
传统模型一次只能生成 1 个 token。MiMo 原生支持 3 层 MTP(Multi-Token Prediction)——一次预测接下来的 3 个 token,如果中间预测对了,直接跳过中间的计算。
打个比方,传统打字是一个字一个字打——你想打"今天天气",要按 4 次键。MTP 像有个自动补全在猜你下一个 1-2 个字是什么——如果它猜对了,你就不用再按那两次。
MiMo 的 MTP 在 agentic 场景下实测:decode 前 128 个 token 加速 2.3 倍,128-256 个 token 加速 1.5 倍。
这件事的意义在于,99% 折扣专门指向 Input (Cache Hit),但模型实际服务用户时,input 和 output 是同一次请求里发生的——如果 output 没省,整体请求成本就只省了一半。MTP 让 output 那一半也降下来,整套降价的盈利模型才闭环。
把六件事串成一条降本链:
SWA 架构 → KVCache 1/7 → 双池真正释放容量 → 同一台 GPU 能装 5+ 倍并发 → 前缀缓存命中率 93-95% → 95% 请求几乎不用算 → GCache 让存储成本归零 → 调度把命中请求优先调走 → MTP 让生成也省 → 单位请求 GPU 时间下降一个数量级 → 单位成本下降 95%+ → 定价降 99%,毛利率仍为正。
任何一个环节缺失,这条链都断在某一节。99% 降价不是营销数字,是六个工程支柱叠加 + 真实线上验证后的累积效应。
回头看业界一开始的几种解读,每种都有部分道理。这两年中国大模型公司之间的价格战是真的;小米利润腰斩还要砸 AI 是真的;DeepSeek 把行业定价拽到地板上也是真的。
但罗福莉这次公开技术博客并且详细的技术细节公开拆解,无疑是希望回击对于价格战的说法,让“技术的问题归技术、营销的问题归营销。”
她在博客中写道,MiMo-V2.5 系列模型的推理效率并非来自某一环节的单点突破,而是多维度协同优化的结果。Hybrid SWA 让 prefill 与 decode 同时受益,但未经充分优化的 KVCache 实现反而会在各环节抬高成本。围绕这一目标,MiMo团队系统性重构了 KVCache 管理、分级缓存、前缀缓存树,攻克 SWA KVCache 核心问题,优化了调度策略及 Prefill / Decode 链路,并经线上真实场景检验,最终将其理论效率优势真正兑现到生产环境。至此,Hybrid SWA 才发挥出在长文推理上兼具强度与效率的架构优势。再组合 MoE 配置和多模态推理的各种优化,极大程度提高了线上推理服务的性能。
这是一套AI工程的系统性打法,也是值得行业共同参考借鉴的降本手段。
价格战不需要写博客,工程兑现才需要。





