近年来,混合专家模型(MoE)已广泛用于云端大模型。但在手机端,大语言模型(LLM)仍以稠密架构为主。过去,手机设备对内存、算力和时延的约束更严苛,子十亿活跃参数范围内的端侧 MoE 一直缺少系统研究。如今,随着移动设备 DRAM 容量提升,MoE 也开始有机会部署到智能手机上。
Meta 团队提出的 MobileMoE,首次在商用智能手机上实现了高效的 MoE 推理。结果显示,在 14 个基础测试中,MobileMoE-S/M 在内存相近的情况下,仅用稠密基线 1/2 到 1/4 的推理计算量,就做到了持平甚至更高的平均准确率。实测中,MobileMoE-S 在 iPhone 16 Pro 的 GPU/MLX 后端提速最明显,输入阶段最高可提速 3.8 倍。

论文链接:https://arxiv.org/abs/2605.27358
研究团队还提出了一套端侧 MoE 缩放规律,用于确定更适合手机部署的模型结构。MobileMoE 并为端侧大语言模型建立了新的帕累托前沿,在精度与推理计算开销的权衡上取得了更优结果。
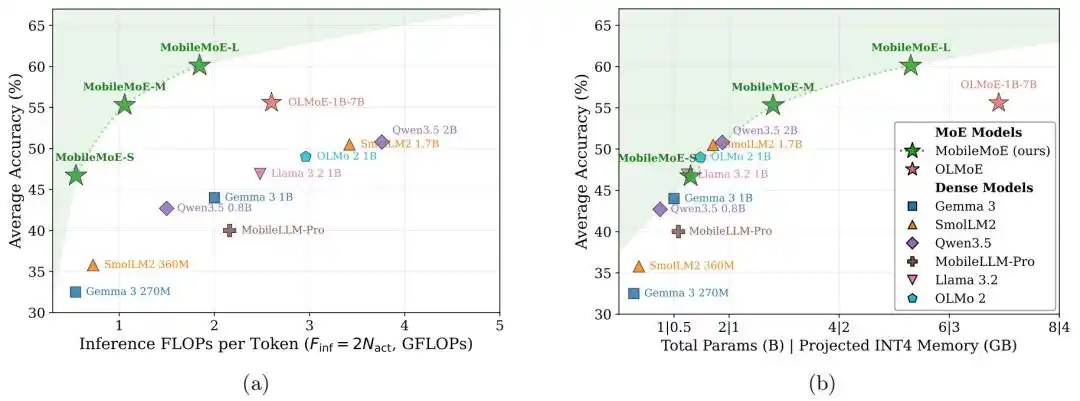
图|MobileMoE 为端侧大语言模型建立了新的帕累托前沿。
MobileMoE是如何设计的?
MobileMoE 可以这样理解:它是一类面向端侧部署设计的MoE 语言模型。整体仍是decoder-only Transformer,但把原来的稠密前馈层换成了 MoE 层。路由器会为每个 token 选出得分最高的少数专家参与计算,同时还有一个共享专家始终参与计算。整个训练流程分为四步:预训练、中期训练、监督微调和量化感知训练。
预训练:研究团队在 2048 的上下文长度下,使用约 6T token 的开放许可数据进行预训练,数据整体以 Web 为主,同时覆盖数学、代码、知识和科学等领域。
中期训练:研究团队将上下文长度扩展到 8192,并进一步提高知识、代码、数学和科学等高质量数据的占比,总规模约为 500B token。
监督微调(SFT):研究团队在超过 8000 万个样本的开放许可指令微调数据上,对 MobileMoE-Base 进行了微调。
量化感知训练:研究团队将线性层和 embedding 量化到 INT4,将激活动态量化到 INT8,router 则保留 FP32 精度。

图|MobileMoE 的四阶段训练。
实验结果
消融实验结果
研究团队先比较了三个架构变量:专家数量 E、专家粒度 g,以及是否加入共享专家。

图|专家数量 E 的缩放。
在固定内存预算下,当内存高于约 0.25GB 时,MoE 的损失开始低于对应的稠密模型。继续增加专家数量 E,损失则会进一步下降,但当 E 增加到 8 后,边际收益已经明显减弱。对专家粒度 g 的实验则表明,更细粒度的专家配置整体更优,其中 g=8 在效果和训练开销之间取得了较好的平衡;当 g 从 8 增加到 16 时,损失改善不足 0.01,但训练时长增加约 50%。在相同计算预算下,加入共享专家后模型损失进一步下降。
基于消融实验结果,研究团队最终采用了 E=8、g=8、带共享专家的配置,即 60 个细粒度路由专家、Top-4 路由和 1 个共享专家,并将这套结构用于 MobileMoE-S/M/L 三个版本。
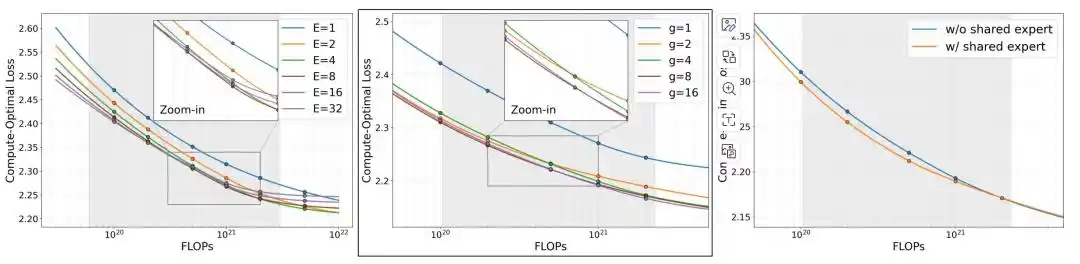
图|在计算最优条件下对 MoE 模型进行缩放。
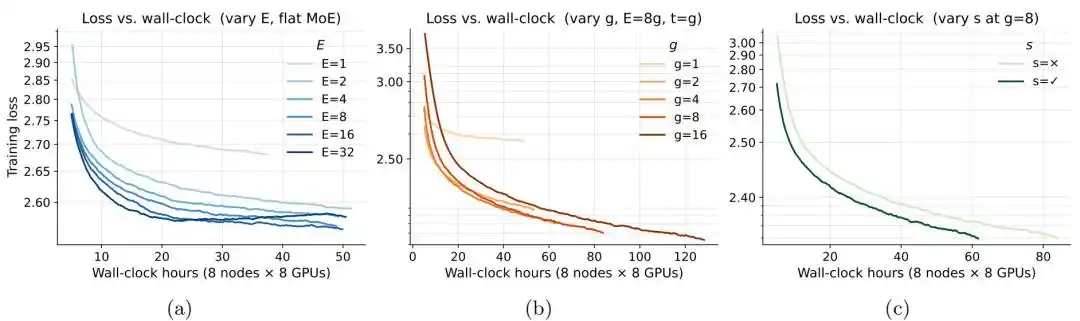
图|MoE 架构的训练效率。
14 项基础评测:建立新的端侧帕累托前沿
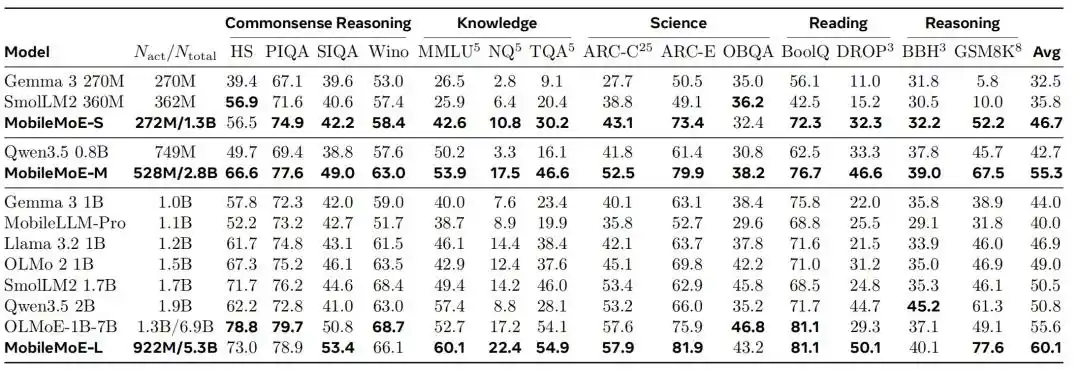
研究团队在常识推理、知识、科学、阅读和推理五类共 14 项基础评测中,将 MobileMoE 与 Gemma 3、SmolLM2、Qwen3.5、OLMo 2、OLMoE-1B-7B 等模型放在统一设置下重新评测。
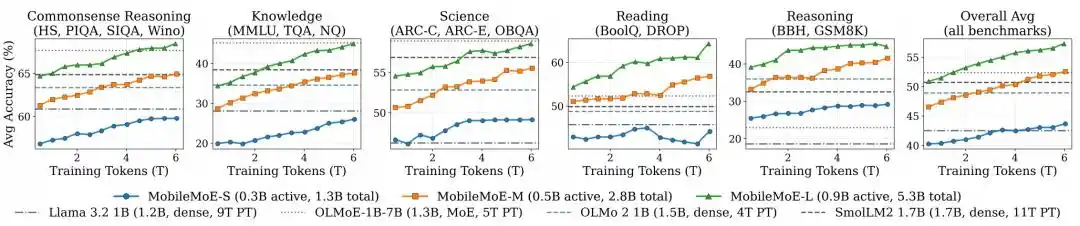
图|MobileMoE 的预训练轨迹。
Base 模型对比结果显示,MobileMoE-M 的平均分高于 Qwen3.5 2B,MobileMoE-L 的平均分高于 OLMoE-1B-7B,所需模型规模也更小;研究团队还提到,MobileMoE-L 的 Base 版本平均分已经高于 OLMoE-1B-7B 的 Instruct 版本。在训练规模上,MobileMoE 使用约 6T 预训练 token,少于 Llama 3.2 1B 的 9T 和 SmolLM2 1.7B 的 11T。在指令微调模型的整体比较中,MobileMoE-M 的平均准确率已经接近 OLMoE-1B-7B,但活跃参数和总参数都少约 60%。

图|MobileMoE-Base 模型对比。
高级评测:代码与数学任务优势更明显
在指令微调后的高级评测中,MobileMoE 在代码和数学任务上表现更突出。以 MobileMoE-L 为例,它在代码和数学两类评测中的平均分都高于 Qwen3.5 2B 和 OLMoE- 1B-7B。不过,研究团队也提到,在指令跟随和知识推理两类能力上,Qwen3.5 2B 仍然更强。
图|高级基准测试上的 Instruct 模型对比。
量化与端侧部署:INT4 后仍保持竞争力,手机端明显提速
量化后,MobileMoE-S/M/L 的整体平均分相比各自的 BF16 版本有所下降,但降幅大致在 2 到 3 分之间。即便如此,MobileMoE-L 的 INT4 版本表现仍高于 OLMoE-1B-7B Instruct 的 BF16 版本。
研究团队还将 MobileMoE 部署到 Samsung Galaxy S25 和 iPhone 16 Pro 上进行测试。结果显示,在可比的 INT4 权重内存条件下,MobileMoE-S 相比 MobileLLM-Pro,输入阶段提速 1.8-3.8 倍,逐 token 生成阶段提速 2.2-3.4 倍。
内存占用方面,在 Samsung Galaxy S25、8K 上下文和真实 prompt 条件下,MobileMoE-S 的峰值 RSS 为 1.49GB,低于 MobileLLM-Pro 的 1.91GB。

图|端侧运行时延迟。
不足与未来方向
目前,在更高阶的指令遵循以及知识与推理能力上,指令微调后的 MobileMoE 仍落后于 Qwen3.5 2B。研究团队认为,这一差距可能与更完善的后训练有关。未来,若要缩小这一差距,训练侧需要加强蒸馏、面向推理的后训练,以及多模态扩展。
此外,研究团队指出,MoE 在手机上的内存占用会随输入内容变化。与固定模板输入相比,真实输入通常会带来更高的内存占用。若仅基于模板化输入进行测试,可能会低估实际部署场景中的内存压力。未来,如果要更准确评估端侧 MoE 的真实内存表现,仍需要基于更多的真实实测数据。
与此同时,研究团队已经在 CPU 和 GPU 后端完成了系统性的真机测试,但 NPU 路线仍有待探索。同时,MoE 的运行时内存占用对输入内容比较敏感。未来,动态路由、专家剪枝、混合精度量化以及移动端 NPU 部署,都是后续继续提升端侧效率的方向。
更多技术细节,详见原论文。
本文来自微信公众号“学术头条”(ID:SciTouTiao),作者:夏千斯





