如果有一天,你在撤稿名单里看到了马克斯·普朗克的名字,大概率会以为自己点进了某个学术恶搞网站。
毕竟,这不是普通作者。普朗克是量子论奠基人,1918 年诺贝尔物理学奖得主,也是 20 世纪科学史上最重要的名字之一。
但一篇新论文指出,普朗克发表于 1940 年和 1942 年的两篇文章,竟然在 Springer 的数字平台上被标记为「retracted」(撤回)。


论文标题:The Curious Case of Max Planck retracted papers. When past scientific practices meet contemporary publishing norms论文地址:https://arxiv.org/abs/2605.17534
搞笑的是,从论文作者的调查看,这两篇文章并不是因为造假、错误或学术不端被撤,而是被算法误伤。
01
事情的开端,是 Retraction Watch(学术出版问题记录网站)的一个「诺奖得主撤稿名单」。
作者作为物理学史研究者,在名单中看到马克斯·普朗克时感到意外,因为这两篇文章出自德国科学期刊《Die Naturwissenschaften》。当时的普朗克已经是享誉世界的物理学家,论文作者也很难相信这些文章真的在他生前被撤,或者后来存在足够充分的撤回理由。

链接:https://retractionwatch.com/retractions-by-nobel-prize-winners/
Springer 平台上给出的解释相当含混。页面标题把它标成「RETRACTED ARTICLE」(撤稿文章),但 PDF 里的说法是「This article has been withdrawn due to article violation」;网页上的表述则更明确一些,称文章因「copyright violation」(版权违规)被撤回。
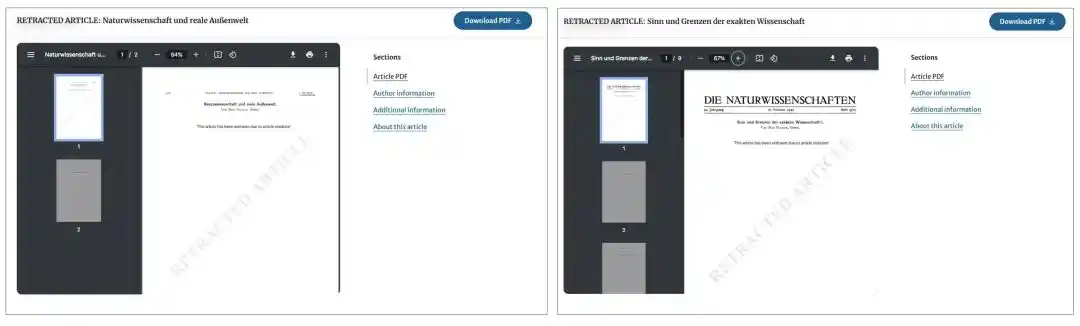
也就是说,这可能是版权、数字化归档和平台元数据管理共同制造出来的事故——这两篇老文章在现代数据库里被系统/出版商当成了版权或重复发表问题处理。
让我们先回到 20 世纪上半叶的科学出版生态。《Die Naturwissenschaften》创刊于 1913 年,由 Julius Springer Verlag 出版,定位有点像德语世界的《Nature》:它是面向自然科学、医学和技术进展的综合性科学周刊。它既发表技术论文,也发表演讲、会议报告,以及关于科学哲学和文化意义的讨论。
普朗克这两篇文章本身也不是报告新实验或新理论的研究论文,而是关于科学知识性质的哲学性反思。
1942 年那篇《精确科学的意义与界限》尤其典型。它原本是普朗克 1941 年在柏林 Kaiser-Wilhelm-Gesellschaft 的一次演讲,后来以多种形式流通:1942 年作为小册子出版,也发表在《Europäische Revue》和《Die Naturwissenschaften》上,1943 年又被收入普朗克的演讲和论文集中。
放在今天,这种路径很容易被平台或版权系统识别为「重复发表」。但在当时,从演讲到期刊、从小册子到文集的多渠道流通,本来就是科学思想传播的一部分。
1940 年的《自然科学与真实外部世界》则更离奇。论文作者没有发现它在其他地方重复发表的证据。作者提出的一种可能解释是:同一期刊几个月前,另一位作者 Aloys Müller 曾发表过一篇同名文章,讨论普朗克的哲学立场;普朗克随后用同样标题写了一篇回应,参与这场思想辩论。
在当年的编辑文化里,这显然不是问题,甚至是一种明确的对话姿态。但到了后来的数字索引、版权管理和元数据系统里,两个相同标题就可能被识别成一组可疑的重复。
论文还指出,这两篇「被撤稿」的文章在 Springer 的平台上甚至变成了空白页。通常情况下,即便一篇论文被撤稿,原文也会保留,只是加上撤稿说明,以维护科学记录的完整性。但在这里,1940 年那篇两页文章、1942 年那篇九页文章,在数字平台上都被抹掉了。今天想看原文,去原始出版方 Springer 是看不到的,得去非营利的 Internet Archive。

02
事情到这里,已经不只是「普朗克被误撤稿」这么好笑了,而是一次现代学术出版基础设施的翻车:当历史文献进入现代数字出版平台,谁有权决定什么算「重复发表」、什么算「版权违规」、什么又该继续被看见?
论文作者认为,「重复发表」「自我剽窃」这类概念并不是永恒不变的学术伦理标准,而是和 20 世纪后期以来的文献计量、科研评价、版权转让、商业出版平台绑定在一起的现代范畴。论文明确指出,「自我剽窃」是一个相对晚近的概念,随着 1990 年代以来以论文数量衡量学术生产力的评价系统而兴起。
这也是今天的学术系统格外熟悉的一点:问题不只是「内容是什么」,而是「内容被系统如何表示」。
一篇历史文章进入数据库后,会被拆成 DOI、标题、作者、版权状态、撤稿标签、PDF 文件、引用记录等结构化对象。一旦平台按照当代规则自动或半自动地处理旧文献,就可能把过去正常的出版实践,改写成今天的违规事件。
这种错位在 AI 时代尤其值得警惕。
我们今天谈训练数据、数据清洗、文献数据库、知识图谱和 RAG,常常默认数字化知识是稳定、可检索、可调用的。但这件事提醒我们:数字档案不是中性的「过去之镜」,而是一套带有商业逻辑、法律假设和平台规则的过滤器。数据会被平台重新命名、重新分类,甚至被空白页替代。
一个现代版权和计量系统,把前数字时代正常的科学传播行为,反向判定为可疑操作。更严重的是,这种判定并没有停留在标签层面,而是直接影响了历史文献的可访问性。
对正在进入 AI 时代的知识生产系统来说,一个错误标签、一段缺失的 PDF、一次不透明的版权处理,都可能在模型、搜索引擎和学术工具中被继续放大。未来的 AI 助手未必知道普朗克的文章是「误撤」的,它可能只会看到数据库里那个冷冰冰的 retracted 标记。
当科学记忆越来越多地被数据库、出版商、平台规则和商业基础设施托管,我们还能不能准确地看见科学的过去?
参考链接:https://www.science.org/content/article/why-have-papers-one-history-s-most-famous-physicists-been-retracted
本文来自微信公众号 “机器之心”(ID:almosthuman2014),作者:关注学术的






