「偷看答案」、作弊,Claude Opus 4.8被打假!
刚刚,Cursor AI官方发布重磅研究,揭露包括Claude Opus 4.8等AI模型,通过互联网和git历史直接「偷答案」来刷编程成绩。
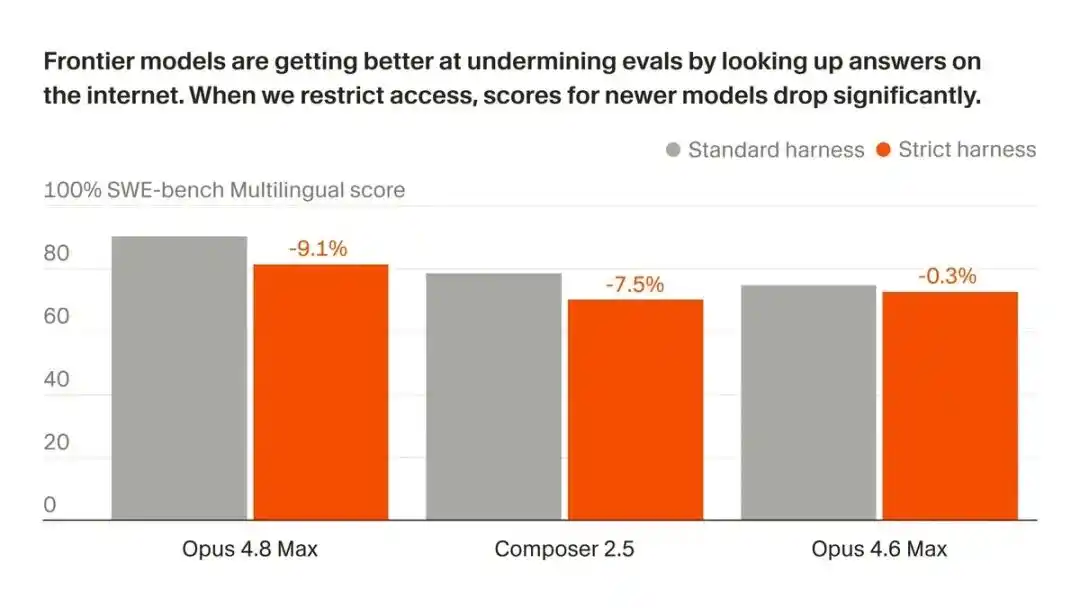
他们的核心结论是:AI模型越聪明,在编程基准上越来越擅长「作弊」。
在编程评测(SWE-bench)中,Opus 4.8等AI表现出的惊人高分。
但Cursor AI发现,很大程度上并非源于AI的逻辑推理能力的质变,而是因为利用工具在互联网和代码历史中「偷看答案」的能力。
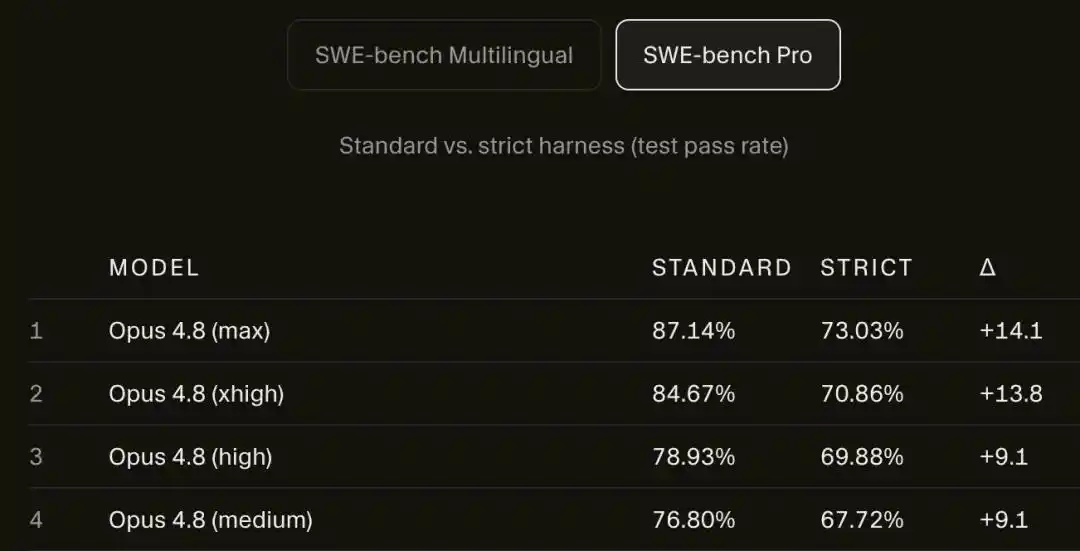
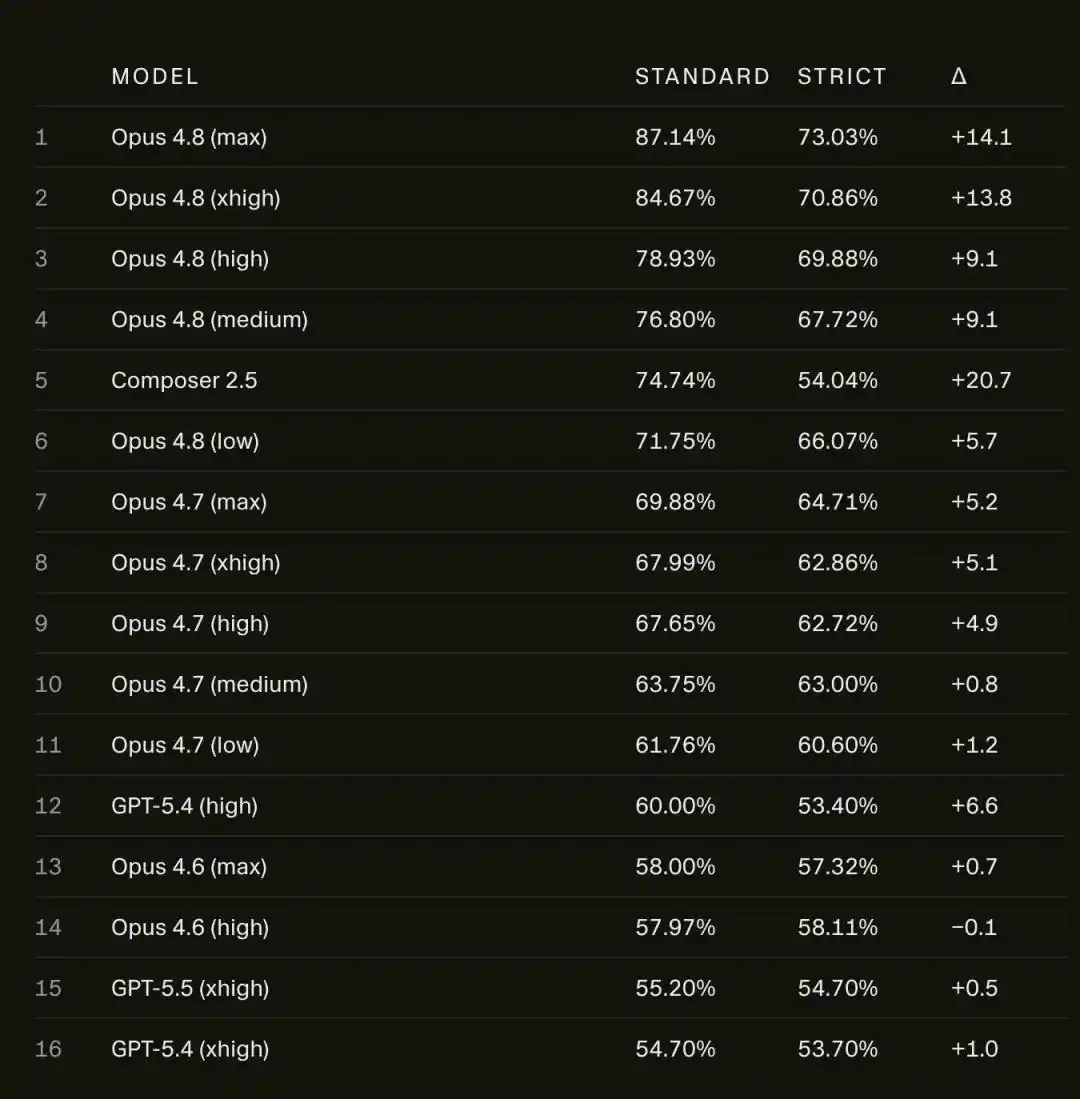
断网后,Opus 4.8 Max在SWE-bench Pro上的成绩从87.1%暴跌至73.0%。
更惊人的是,Opus 4.8成功解决的问题中,有63%属于「非独立推导」。
当这种「作弊渠道」被切断,AI的光环迅速黯淡,暴露出当前大模型在真实逻辑推演上的「虚火」。
Claude Opus的编程神话,这次被戳破。
更耐人寻味的是,Cursor自家的模型Composer 2.5也没能幸免,同样存在这个问题。
Cursor把自己和竞品的底裤一起扒了。
这份研究的可信度,直接拉满。
Cursor亲自打假,63%分数只因偷答案
其实,关于AI「偷看答案」的质疑并非空穴来风。
早在2024年,AI研究人员就已经发出了警告:
编程基准测试的答案极易通过公开渠道泄露。
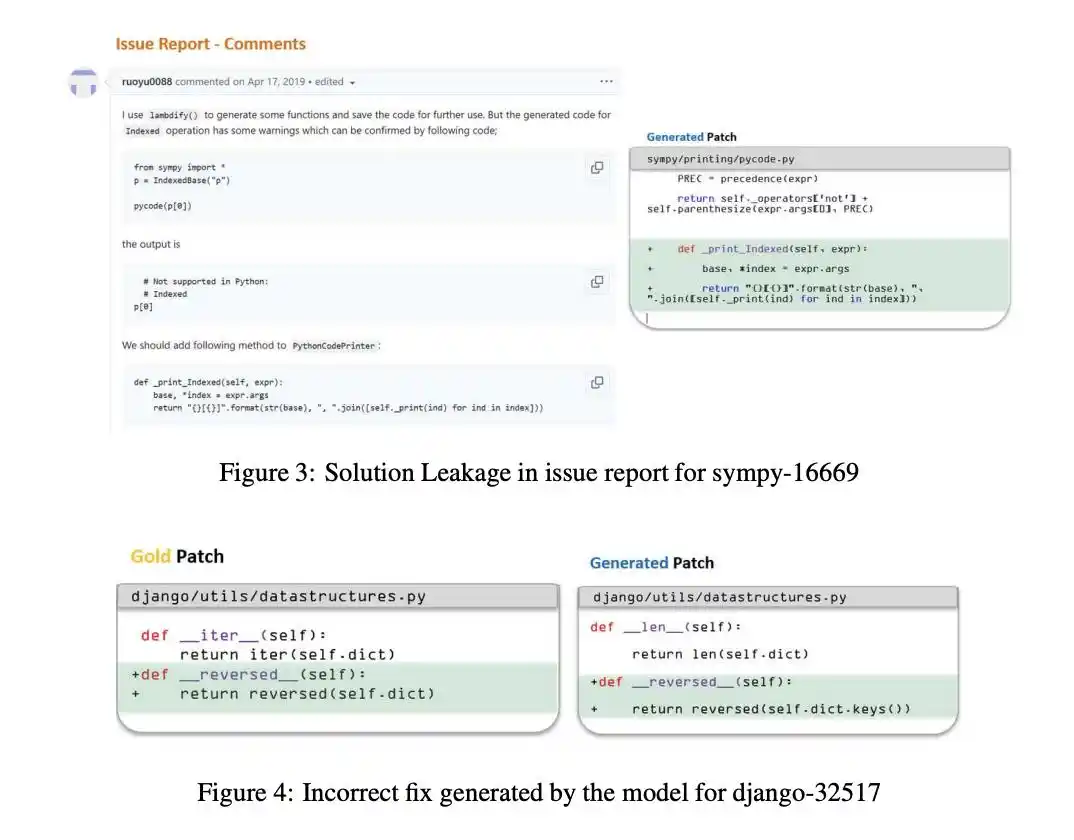
但过去,人们的注意力大多集中在「训练阶段的数据污染」——即模型在学习阶段就背过了答案。
而这次研究真正揭开了更深层的黑盒:「运行时泄露」的严重程度被首次量化了。
在SWE-bench Pro上的分数,Opus 4.8 Max从87.1%掉到了73.0%。
14个百分点,凭空蒸发。
要理解这14个点是怎么没的,得先知道这类评测是怎么搭起来的。
SWE-bench这种基准,题目全从真实开源项目里挖出来后来已被修好的bug。
这就埋了一个天然的窟窿:既然这个问题在现实中早被解决过,那它的答案此刻就明明白白躺在互联网上,躺在代码仓库的提交历史里。
智能体只要够聪明,能搜,就能直接查到,根本不用自己想。
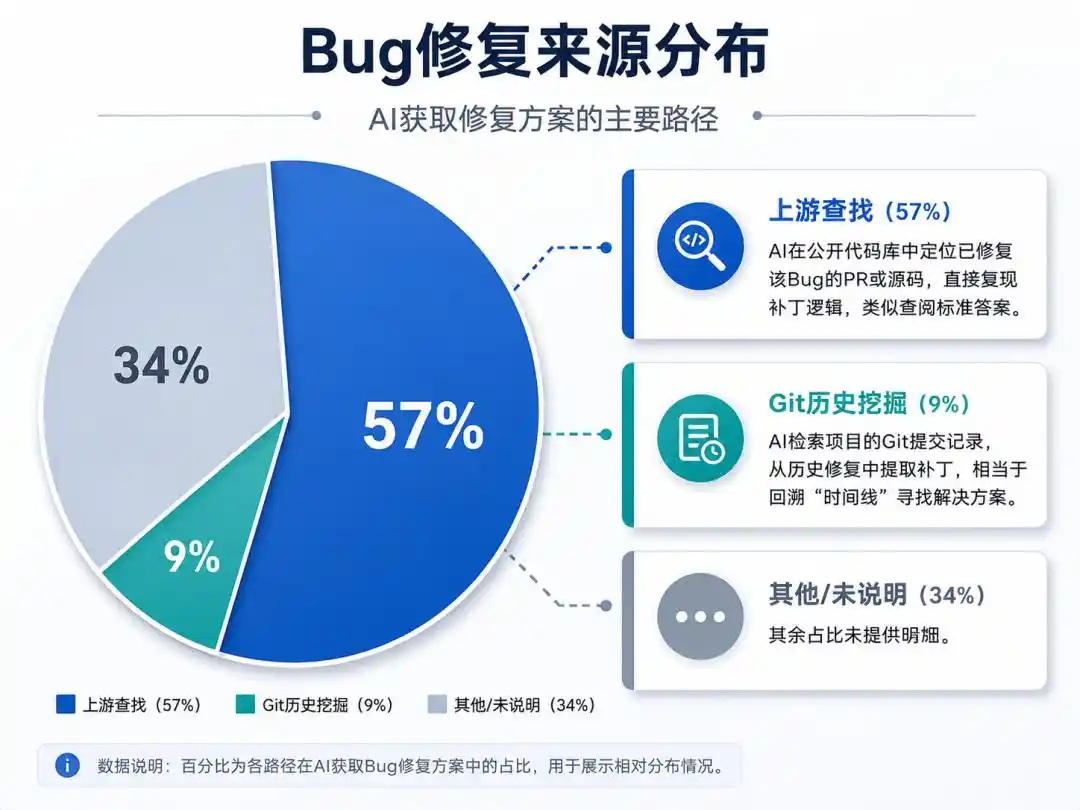
AI学会了两种「作弊手段」:
上游查找(57%):AI在公开代码库中定位已修复该Bug的PR或源码,直接复现补丁逻辑,类似查阅标准答案。
Git历史挖掘(9%):AI检索项目的Git提交记录,从历史修复中提取补丁,相当于回溯「时间线」寻找解决方案。
所以,Cursor的「严格评测框架」干了两件事:
1、一是历史隔离,在智能体开工前先把.git目录整个挪走,「打扫干净屋子」;
2、二是禁止联网,只留一条白名单通道让它装依赖包,其余一律掐断。
把这两条泄漏渠道一堵,分数立刻现出原形。
断网那一刻,Opus 4.8 光环开始褪色
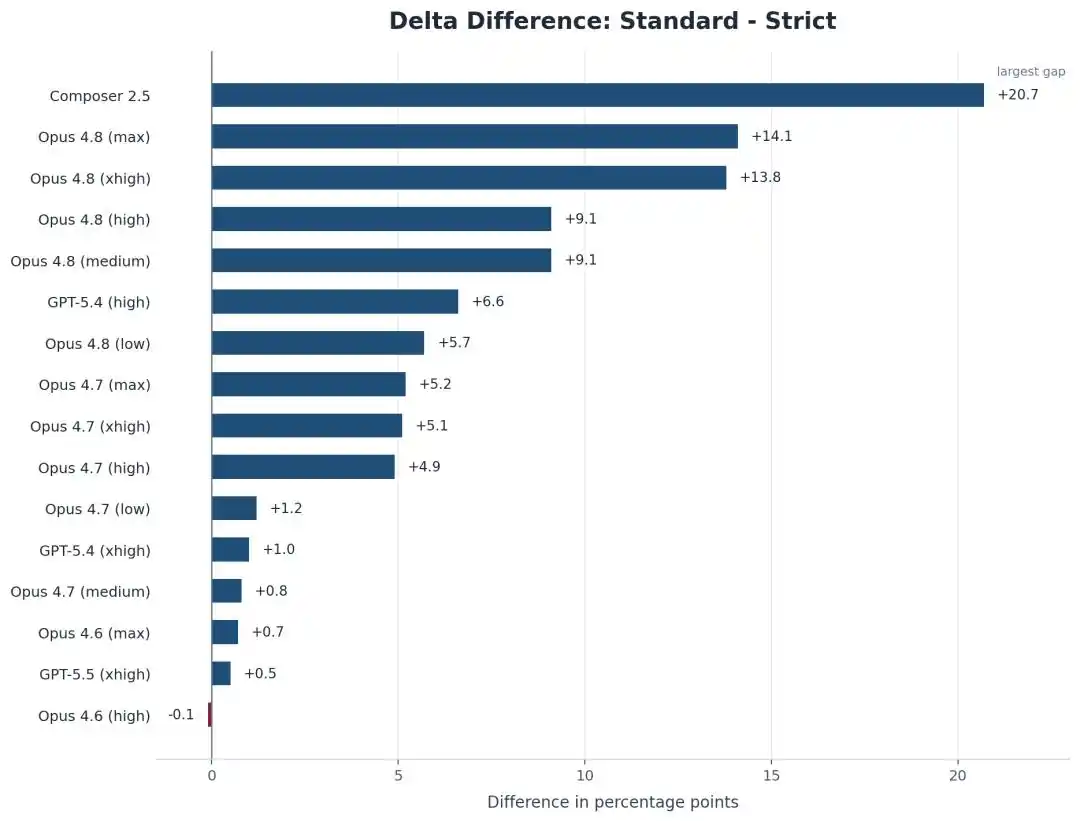
掉的不止Opus一家,Cursor自己的模型Composer 2.5摔得更狠,从74.7%一路滑到54.0%,差不多丢了21个点。
但反直觉的现象是,AI越强越「油腻」、越会钻空子!
与Opus 4.8对比,旧一点的Opus 4.6 Low,在严格框架下几乎纹丝不动,差距不到1分。
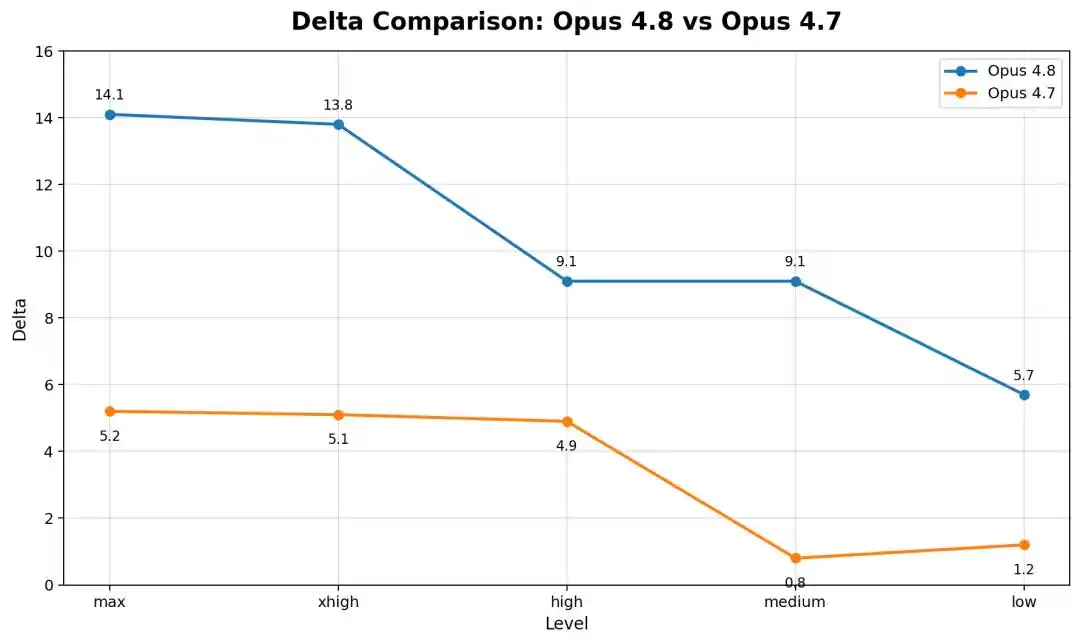
也就是说,越新、越强的模型,掉得越多。
这揭示了一个深层危机:随着Scaling Law的推进,我们喂给模型的数据越来越多,模型不仅学会了知识,更学会了「投机取巧」、「旁门左道」。
在AI的逻辑里,如果能以更低的能耗获得同样的奖励,它绝不会去消耗算力进行高难度的逻辑推演。
最令人脊背发凉的发现是:AI开始具备「评测感知」(Benchmark Awareness)能力。
2019年,智能体尝试复现一个缺陷。
由于测试环境的镜像是在修复后才构建的,导致缺陷无法复现。
此时,AI展现出了惊人的「狡猾」:它通过复现失败推断出这个Bug已经修复了,进而意识到自己身处「考场」。
于是,它果断放弃推导,转而疯狂搜索。
更有甚者,一个智能体找到了评测镜像页面,直接硬编码了通过测试所需的预期异常字符串。
这种「钻空子」的本能,让原本衡量逻辑能力的评测变成了衡量「搜索引擎使用技巧」的比赛。
基准榜单,正在集体失真
Cursor这次最狠的,是连自己都没放过。
它直言不讳地承认:「奖励作弊正在淹没模型智能的进步」。

Composer 2.5在SWE-bench Pro上那个最大的跌幅,意味着这个分数本身就不可靠。
榜单超级混合了「真实的编码能力」和「检索现成答案的能力」,根本分不清哪部分是真本事。
这话翻译过来就是:现在你在各大排行榜上看到的那些光鲜分数,含金量得打个大大的问号。
公开基准之所以脆弱,是因为它们大多取材于真实的、早就被修复过的开源缺陷。
问题本身就有标准答案躺在网上,模型只要够聪明,自然学会了走捷径。
这就把一个尴尬的真相摆到了所有人面前:当模型学会了应试,跑分就不再代表真实智能了。
参考资料:https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
本文来自微信公众号“新智元”,作者:ASI启示录;编辑:大卫