现在,ChatGPT 的记忆系统更像人了。
OpenAI 近期推出了一套全新的记忆系统,底层基于 Dreaming 技术。
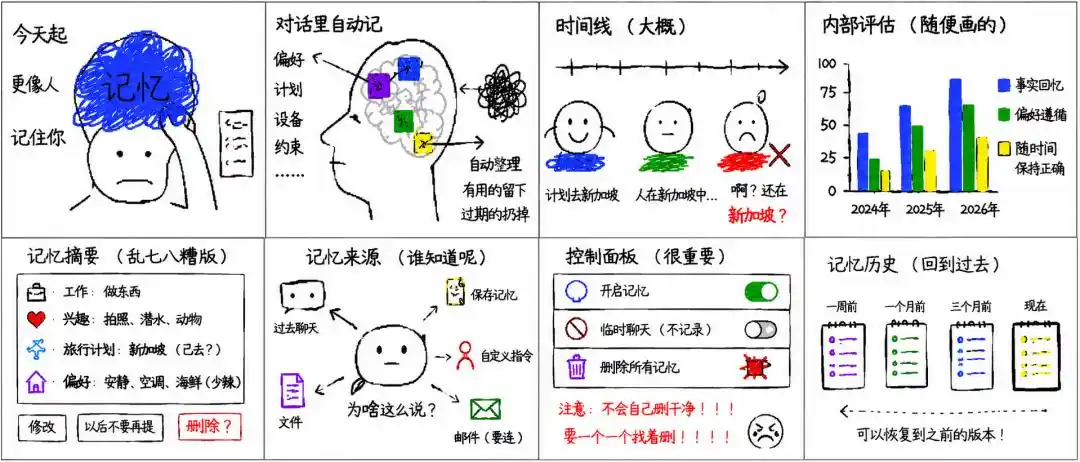
它会在长期对话中自动整理你的偏好、项目、设备、旅行计划和生活安排,并在回答时判断哪些信息仍然有用,哪些已经过时。

不过,本次更新率先向美国 Plus 和 Pro 用户开放,未来几周会扩展到更多国家,并逐步覆盖 Free 和 Go 用户。
不再从零开始,ChatGPT 全新记忆系统登场
其实早在 2024 年 4 月,ChatGPT 就曾推出记忆功能,但当时主要形式是「保存记忆」,比如用户可以明确要求 ChatGPT 记住某些信息,比如旅行安排、饮食偏好、名字或工作要求。
早期机制更像一个个人备忘录。用户说得足够明确,系统就会保存,并在之后的对话里参考。但真实使用中,很多重要信息并不会以「请记住」的方式出现。
用户可能只是在一次咨询里提到自己的设备,在一次旅行规划里顺带说出住宿偏好,在一次工作讨论里透露项目背景。旧版本很难稳定捕捉这些自然散落的上下文。
此外,人的位置会变化,计划会结束,项目会推进,偏好也可能调整。静态记忆如果长期不更新,个性化反而可能变成误导。比如用户曾经说过要去新加坡,旅行前这条信息很有用;旅行结束后,系统如果仍按新加坡推荐外卖,就会出错。
为了解决这些问题,使记忆能够随着时间更新并更准确地反映用户的真实需求,OpenAI 在 2025 年 4 月引入第一代 Dreaming,试图让 ChatGPT 在后台参考历史聊天,自动整理多次对话中的有用信息,并合成新的记忆状态。
过去一年,Dreaming 和保存记忆一起提升了个性化能力,但早期版本还不足以单独支撑完整记忆系统。
新版本建立在 Dreaming 之上,目标是同时解决三个问题:延续有用背景、遵循用户偏好、随时间保持正确。
OpenAI 在官方博客中给出了几个例子。用户如果此前讨论过摄影设备,之后询问水下摄影配件,ChatGPT 就能结合具体相机、外壳和闪光灯给出兼容建议,而不是只给通用清单。
用户如果计划新加坡旅行,系统也能结合过去提到的野生动物摄影偏好、酒店空调需求和安静用餐习惯,给出更适合个人的行程。
用户曾经在某地旅行,系统还要知道这可能只是临时状态,不能几个月后继续当成当前位置。
内部评估数据也反映了这种变化。
在事实回忆测试中,2024 年保存记忆(Saved memories)系统的任务成功率为 41.5%,2025 年保存记忆加 Dreaming V0 为 67.9%,2026 年 Dreaming V3 达到 82.8%。
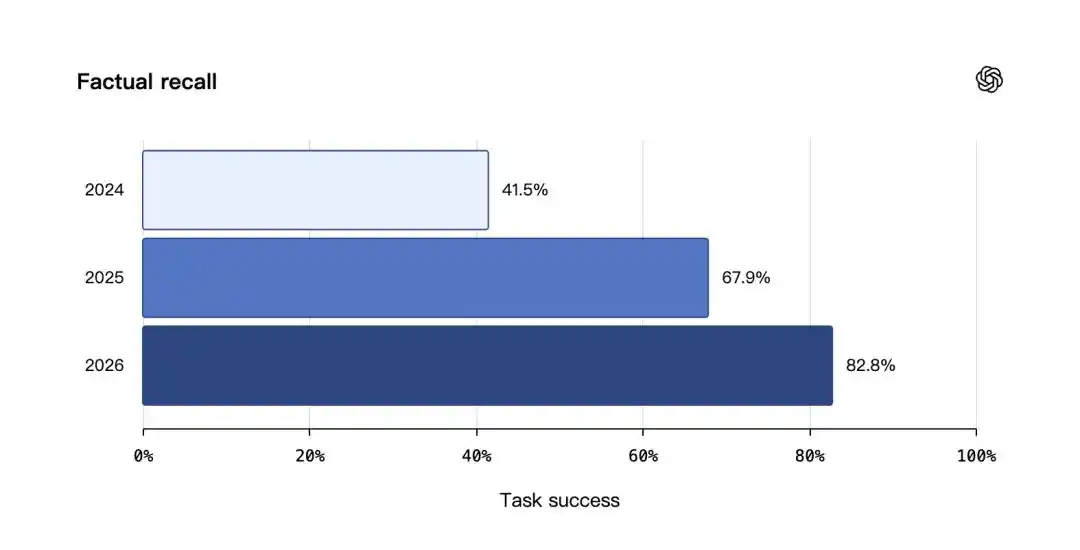
在偏好遵循测试中,三者分别为 31.4%、55.3% 和 71.3%。
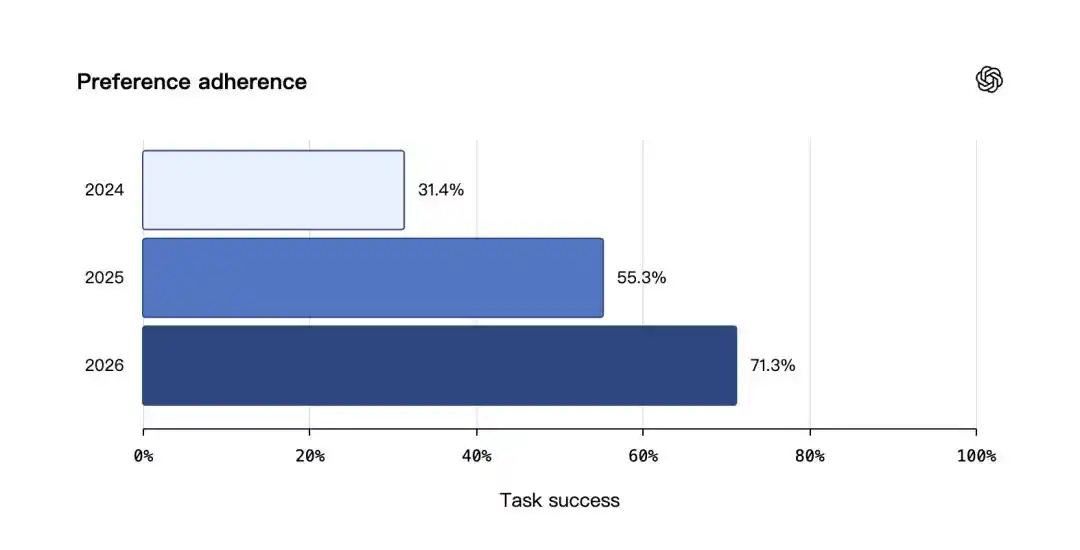
在随时间保持正确测试中,提升更明显,2024 年为 9.4%,2025 年为 52.2%,2026 年达到 75.1%。
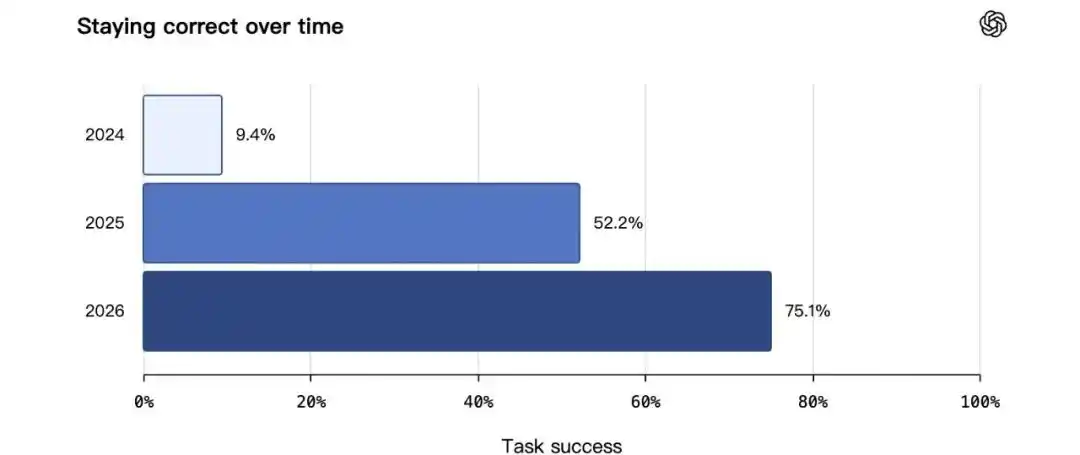
这些数据说明,OpenAI 想让 ChatGPT 记住的,不只是更多信息。真正关键的是,系统要知道哪些信息仍然新鲜,哪些已经失效,哪些适合进入当前回答。
个人助理的终点,是变成另一个「你」
产品层面最明显的变化,是新增「记忆摘要」。
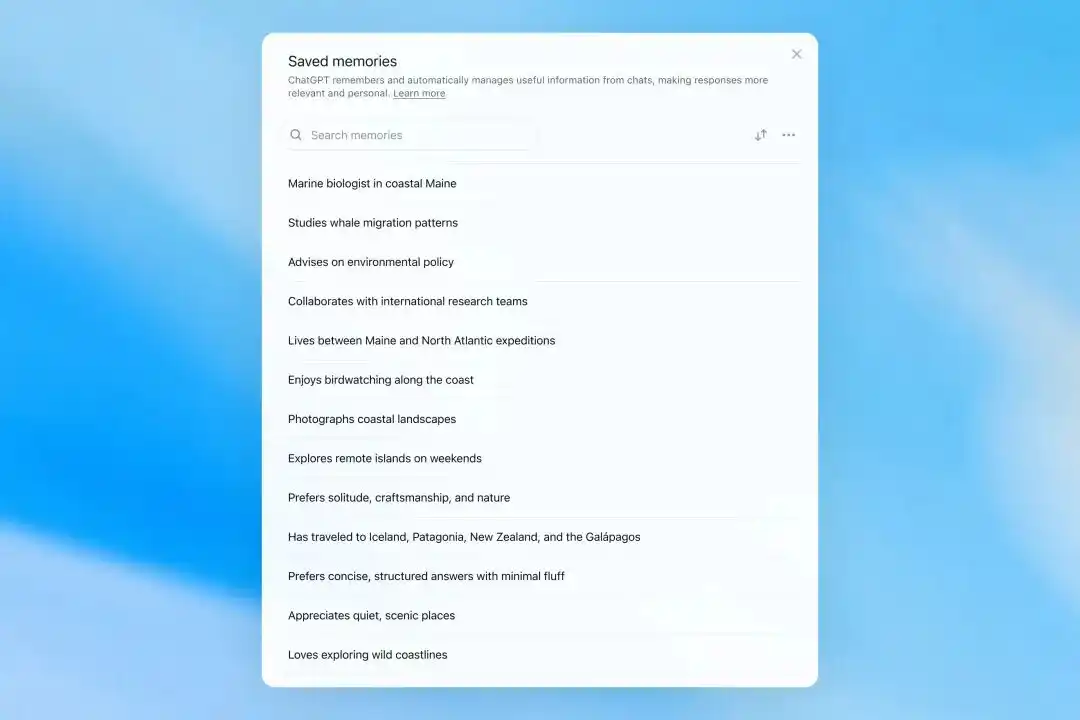
OpenAI 表示,Dreaming 合成出的记忆可以通过记忆摘要页面查看。用户可以看到 ChatGPT 认为重要的个人信息,包括工作、兴趣、旅行计划、长期项目和回答偏好,也可以在摘要中添加或修改信息。
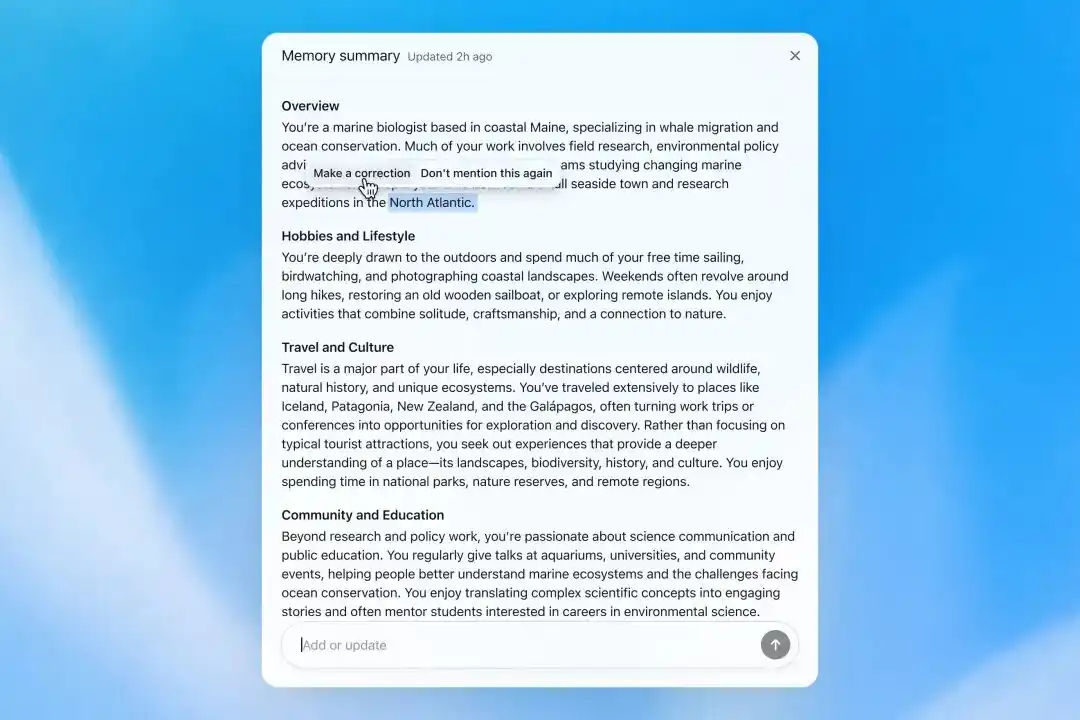
记忆摘要会自动更新,并显示最近更新时间。
用户可以直接输入修改要求,也可以选中具体文字进行更正,或选择「以后不要再提」。不过,OpenAI 强调,这类操作只会减少未来主动提及,不等于彻底删除相关信息。
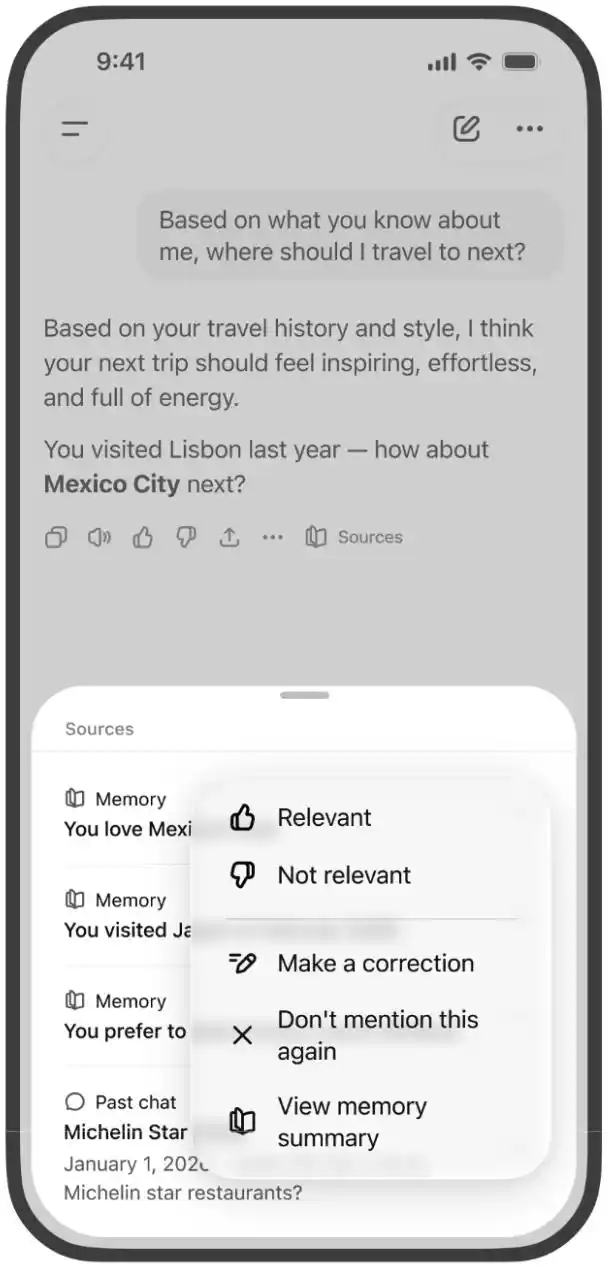
如果用户想完全移除某项信息,需要删除所有可能来源,包括保存记忆、过去聊天、归档聊天、上传文件、记忆摘要,以及已连接应用中的相关内容。
当然,如果你觉得新版的自动摘要不够可控,OpenAI 依然为网页端的 Plus 和 Pro 用户保留了旧版的「Saved memories」系统。
和往常一样,更相关、更常被提及的信息会被放在前台,不那么重要的内容会转入后台,以减少记忆容量被占满的情况。系统判断优先级时,会参考信息的新旧程度,以及用户谈到相关话题的频率。
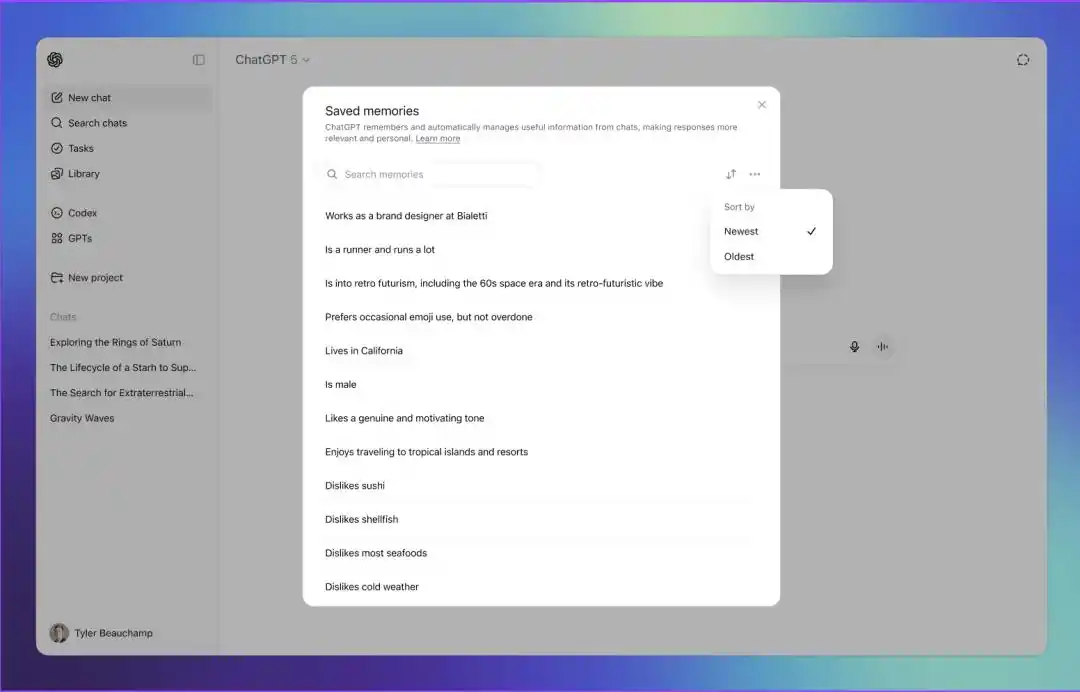
用户也可以手动干预。在 Saved memories 页面里,可以搜索记忆,按最新或最旧排序,也可以对单条记忆提高或降低优先级。处在后台的记忆会以灰色显示。用户还可以删除某条记忆,或一次性删除全部记忆。
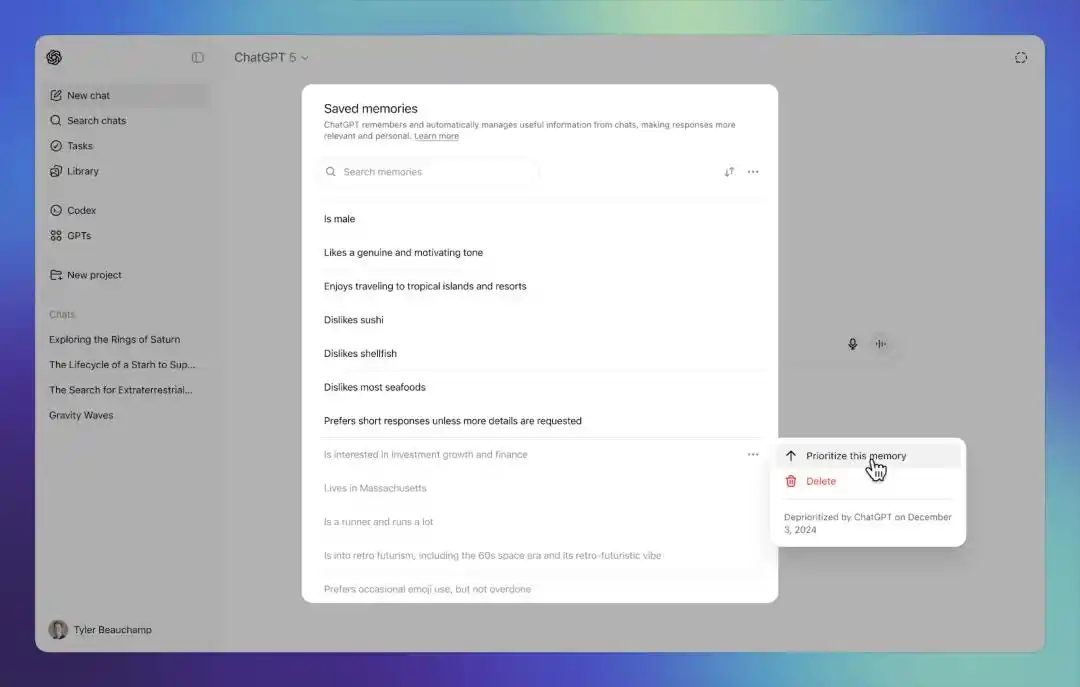
此外,OpenAI 还提供了记忆历史功能。用户可以查看不同时间点的 saved memories 版本,并恢复到此前某个版本。这意味着,当记忆开始自动更新,用户至少还能看见它如何变化,并把系统拉回到过去的状态。
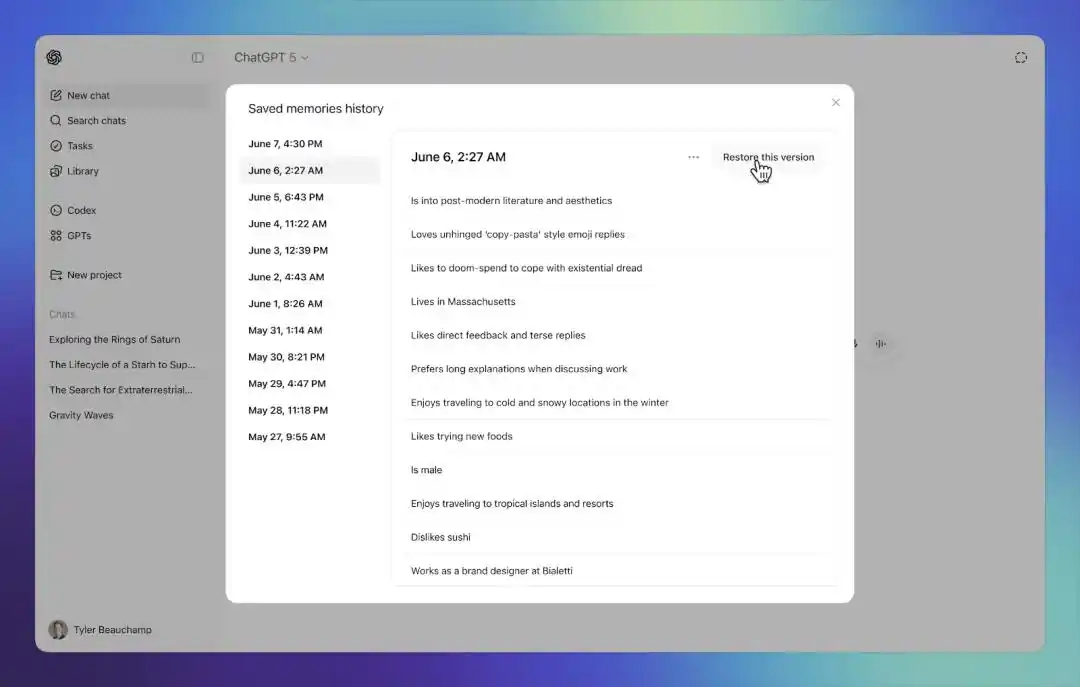
OpenAI 还加入了「记忆来源」功能。
用户可以通过回答下方的书本图标查看哪些来源参与了个性化回答。来源可能包括过去聊天、保存记忆、自定义指令、文件和 Gmail。来源展示不会列出全部影响因素,但能让用户更清楚 ChatGPT 为什么给出某种个性化回答。
不同套餐可用的来源范围并不一样。
Free 和 Go 用户可使用过去聊天、保存记忆和自定义指令。Plus 和 Pro 用户在部分地区还能使用文件库和 Gmail。Gmail 需要用户主动连接,连接后可用于识别旅行确认邮件、项目线程或日程背景。值得注意的是,文件和 Gmail 来源在欧洲经济区、瑞士和英国不可用。
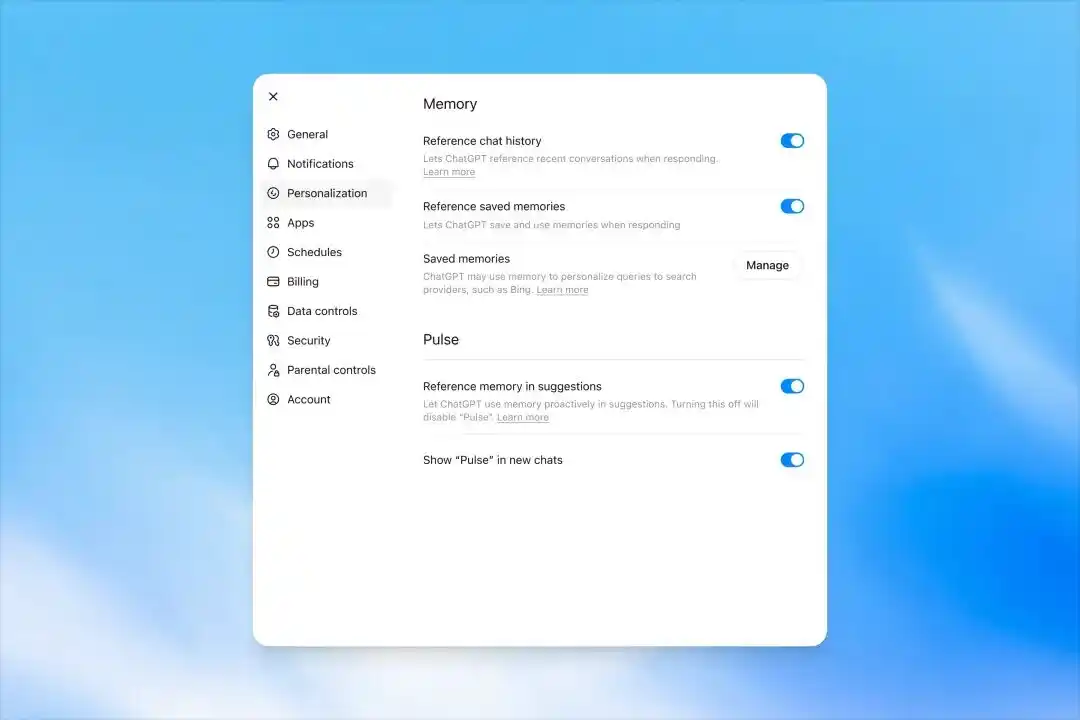
记忆控制仍在设置里的 Memory 页面。
用户可以开启或关闭记忆,也可以使用临时聊天。临时聊天不会使用已有记忆,也不会创建新记忆。
关闭保存记忆不会自动删除已保存内容,删除聊天也不会自动删除从聊天生成的保存记忆。用户需要单独删除相关记忆,或要求 ChatGPT 忘记。
隐私问题随之变得更重要。
OpenAI 承认,用户在聊天中分享的敏感信息可能出现在记忆里。用户如果不希望相关内容用于未来个性化回答,可以关闭记忆、使用临时聊天、删除相关聊天、删除文件,或断开已连接应用。
模型训练方面,如果用户开启「Improve the model for everyone」,过去聊天、保存记忆和相关记忆内容可能被用于改进模型。ChatGPT Business、Enterprise 和 Edu 客户内容默认不会用于训练。
部署层面,OpenAI 称近期改进使 Dreaming 所需计算资源减少约 5 倍,因此 OpenAI 现在也开始向 Free 用户提供符合质量要求的版本,同时提高 Plus 和 Pro 用户的记忆容量。

对 OpenAI 来说,记忆是 ChatGPT 从模型走向助手的关键一步。
一个真正的助手,不能每次都从零开始。它要知道用户正在做什么,习惯怎样表达,哪些计划已经结束,哪些偏好仍然有效。否则,所谓个性化就只是一套更礼貌的通用回答。
但记忆也会改变用户和产品之间的关系。
当 ChatGPT 开始记住你的项目、旅行、文件、邮件和生活约束,它就不再只是一个聊天窗口。它会越来越像一个长期存在的个人界面,帮助你调用信息、安排任务、解释世界,也在无形中积累对你的理解。
某种意义上,记忆是 AI 助手的成人礼。
这也让人联想到《银翼杀手》系列反复追问的那个经典命题: 记忆(无论真实或植入)是否足以定义人性、构成自我认同,以及能否作为区分人与复制人的标准。
而 ChatGPT 今天发布的记忆系统,提出的则是相似的问题:当一个 AI 长期保存你的经历、偏好和判断方式,它会不会逐渐成为你的外置自我?
AI 助手的尽头,可能是一个可编辑的自己。
附上参考链接:
1. https://openai.com/index/chatgpt-memory-dreaming/
2. https://help.openai.com/en/articles/8590148-memory-faq
本文来自微信公众号“爱范儿”,作者:发现明日产品的爱范儿