一张图能压多小?
2025 年 2 月,国际图像专家组(JPEG)宣布了一件被行业低调庆祝的事:JPEG AI,这项历时多年、被寄予厚望的第一个端到端学习型图像编码国际标准,正式发布。

消息传开,不少研究者在社交媒体上转发,配上「AI 终于进了标准」的评论。
JPEG 标准诞生于 1992 年,三十多年来一直是人类数字图像的一门基础语言。而现在,人工智能开始接手重写这门语言的语法。
然而,庆祝背后有一个微妙的现实:即便是 JPEG AI,距离真正的「感知压缩」,仍有相当距离。
工程师们知道,传统衡量压缩质量的指标峰值信噪比(PSNR)其实和人眼看到的「好不好看」关系并不大。一张图在 PSNR 上得了高分,人看了却可能觉得平平无奇;而另一张 PSNR 偏低的图,人却觉得细节丰富、质感真实。优化数学指标,和优化人眼感知,是两件完全不同的事。
几十年来,从 JPEG 到 VVC,再到 JPEG AI,几乎所有编解码器的设计逻辑,都还是在数学指标的框架里兜圈子。感知压缩(直接针对人眼体验来优化)一直像是学术论文里的远景目标,而非可以装进手机的工程现实。
就在这个节骨眼上,苹果的一支工程师团队悄悄发了一篇论文,给出了他们的答案,代号:PICO。

论文标题:What Matters in Practical Learned Image Compression
论文地址:https://arxiv.org/pdf/2605.05148
为什么「看起来更好」比「数字更高」难得多?
理解 PICO 之前,先要理解图像压缩到底在做什么。
把一张照片存成文件,本质上是一道「忘记什么、记住什么」的取舍题。存储空间有限,就必须扔掉一部分信息,同时让看的人尽量察觉不到。不同的编解码器,遵循不同的「扔法」。
JPEG、AV1、VVC 等传统编解码器都是工程师手工设计的规则系统。它们把图像切块、变换、量化、熵编码,每一步都是数十年积累的人工经验。这类系统可以在 PSNR 这样的数学指标上表现极好,但它们的设计本质上是面向「减少像素误差」,而非「减少人眼不适感」。
问题在于,人眼并不是像素误差计。人眼对纹理、对文字、对细节的敏感程度,远比数学公式复杂。当你把一张街景照片压缩得很小,PSNR 可能依然体面,但你会看到建筑边缘模糊、路牌文字变形 —— 而这些,恰恰是人眼最先察觉的东西。
学习型编解码器的出现,理论上打开了一扇新门:神经网络可以直接针对人的感知进行端到端训练,而不是针对数学公式。但在 PICO 之前,已有的感知型学习编解码器,要么速度慢得无法实用,要么缺乏跨设备兼容性,要么无法灵活控制码率,根本装不进一款消费级产品。
三个核心问题,三种解法
PICO 的全称是 Perceptual Image Codec(感知图像编解码器)。这个名字直接点明了它的目标:让人眼满意。
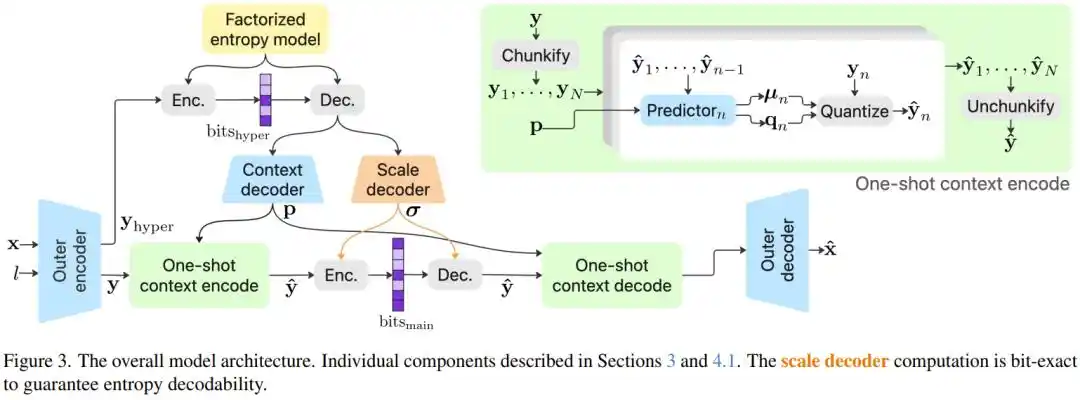
研究团队系统探索了数百万种模型配置,并引入了几项关键技术创新。
第一个问题:熵编码慢,怎么办?
图像压缩里有一个难题:为了压得更小,编解码器需要用「熵模型」来精确估计每个像素的信息量。最精确的方法叫自回归编码:每压缩一个像素,都要先看看周围已压缩的像素,依次预测。这就像厨师每放一块食材,都要回头看看锅里的状态,才能决定下一步。精确,但极慢。
PICO 的解法是「一次性上下文模型」(One-shot Context Model):把熵编码里最关键的「尺度参数」单独拆出来,在一次前向传播中全部算完,不再需要来回等待;而其余参数可以并行计算,保留了自回归的精度,却绕开了它的速度瓶颈。结果是:去掉这个模块,模型性能下降 10.28%;加上它,速度几乎不受影响。
第二个问题:感知训练会产生幻觉,怎么办?
用 GAN(对抗神经网络)训练出来的图像往往「看起来很真实」,但可能是编造出来的真实 —— 头发丝变成了不存在的花纹,平滑表面多出了虚假纹理。更麻烦的是,人眼对文字极度敏感,哪怕一个字母变形一点点,就会立刻察觉。
PICO 针对文字专门设计了 TextFidelityLoss:用一个现成的文字检测器自动找出图中的文字区域,在这些区域强制施加严格的像素保真约束,同时压制 GAN 在文字区域的「发挥空间」。实验显示,加上这项损失函数后,文字区域的绝对误差降低了整整一半。
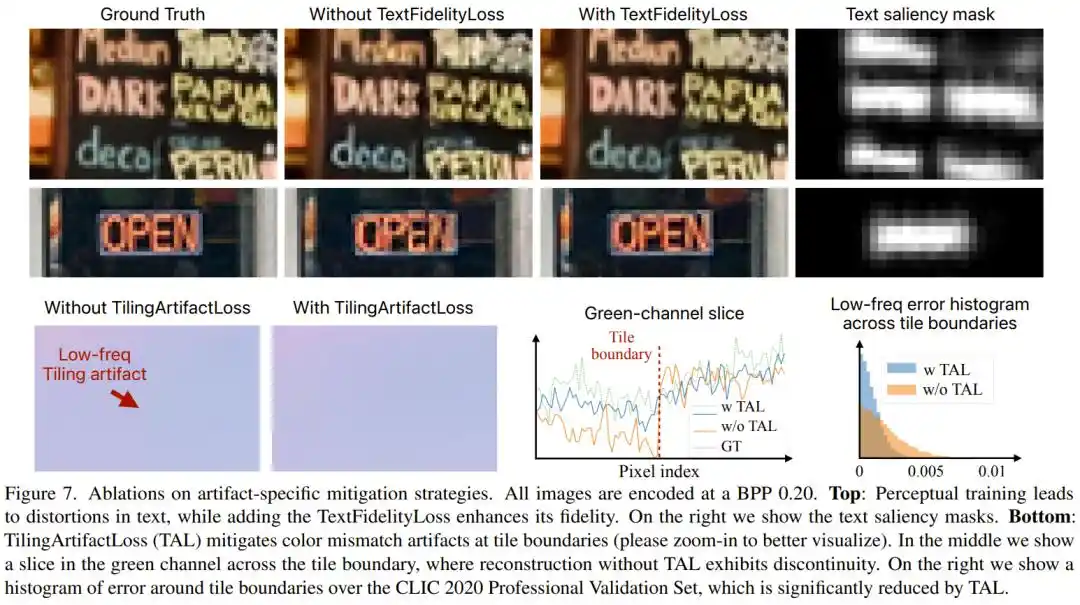
第三个问题:图像分块处理会留下色块边界,怎么办?
为了在手机芯片上快速运行,PICO 把图像切成一块块 504×504 像素的瓦片,分别处理再拼回去。但 GAN 在训练时倾向于忽略低频色彩,导致相邻瓦片之间常出现可见的色差,类似于修图时「没有拼好」的感觉。研究团队专门引入了 TilingArtifactLoss,一种多分辨率的 L1 损失,强制模型在多个空间频率上保持色彩一致。这项措施让瓦片边界的误差也下降了一半以上。
实验结果
苹果团队没有只靠基准评测指标说话。他们委托第三方平台 Mabyduck,组织了一次大规模的人类主观评测。
评测采用盲测两两对比的方式:610 位经过筛选的评测者(需通过色盲检测和压缩伪影辨别测试),对同一张图在不同编解码器下的重建结果进行配对比较,最终汇总为 Bayesian ELO 分数。共收集了 74,925 次配对比较结果。

最终数字说明了一切:在相同视觉质量下,PICO 的文件体积只有 AV1、AV2、VVC、ECM 和 JPEG AI 的三分之一到二分之一 —— 换言之,存同样的图,它需要的比特数只有这些标准的 30%-43%。对比目前最强的学习型感知编解码器(HiFiC、MRIC 等),PICO 也节省了 20%-40% 的文件大小。
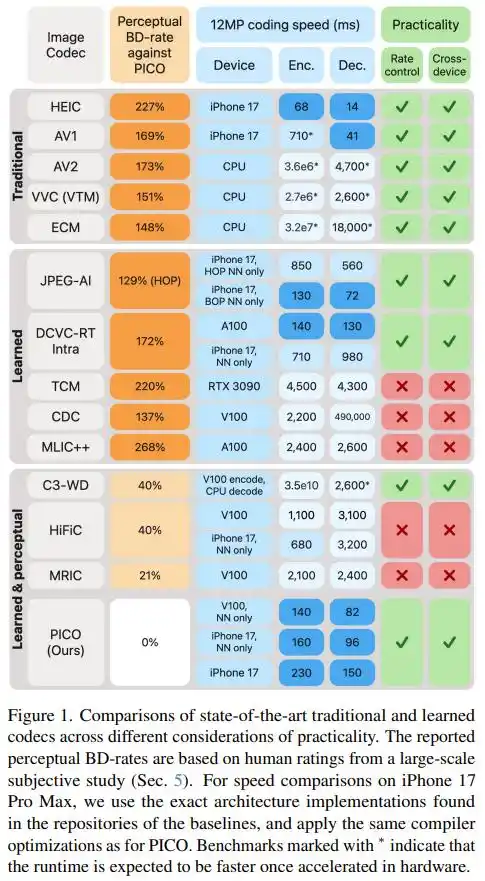
速度方面,在 iPhone 17 Pro Max 上,PICO 编码一张 12MP 的照片仅需 230 毫秒,解码只需 150 毫秒。而大多数顶级 ML 编解码器在 NVIDIA V100 服务器显卡上运行,都比这个慢。
值得注意的是,论文还专门记录了一个「反例」:在 PSNR 这个传统指标上,PICO 表现平平,甚至不如 DCVC-RT 和 VVC。这恰好印证了团队的基本判断:优化感知质量和优化数学指标,本质上是两个方向,鱼与熊掌不可兼得。
一个时代节点,而非终点
PICO 当然也有局限性。论文坦承,对于卡通、示意图等高度规则化的合成图像,PICO 的压缩效率不如传统编解码器,因为这类内容天然适合规则驱动的自回归建模,而非感知生成。
但这些局限并不掩盖这项工作的意义所在。
过去三十年,图像压缩的技术进步,几乎都发生在「让数字更好看」的赛道上。从 JPEG 到 HEVC,再到 VVC,工程师一代代优化的是 PSNR、SSIM 这类指标。而人眼的感知,始终是个被绕开的「难题」。
PICO 是第一次有人系统地把这道难题正面拆解:从架构搜索、损失函数设计,到大规模人类主观评测,并最终装进了一款可以在手机上实时运行的编解码器。
当你下一次用苹果设备分享一张照片,也许不会感受到任何不同。但或许在那个安静的压缩过程里,一套针对人眼感知量身打造的算法,正在决定哪些信息值得留下,哪些可以悄悄遗忘。
团队:从 WaveOne 到苹果
这篇论文的通讯作者是 Oren Rippel,苹果研究员,压缩领域的老面孔。
他的名字最早大规模出现,是在 2017 年。彼时他还在初创公司 WaveOne,发表了一篇名为「实时自适应图像压缩」的论文,用神经网络打败了当时所有主流编解码器,同时维持实时运行速度。那篇论文在学界引发了不小的波澜,也奠定了 Rippel 在学习型压缩领域的地位。

之后,同一批核心人员在 WaveOne 继续深耕,推出了面向视频压缩的 ELF-VC,在 UVG 视频测试集上相比 H.264 实现了 44% 的码率节省,同时运行速度比同类 ML 编解码器快五倍以上。
WaveOne 的这支团队后来整体加入苹果。而这次的 PICO,是他们带着苹果的算力和平台资源,在图像感知压缩上交出的第一份系统性答卷。
本文来自微信公众号 “机器之心”(ID:almosthuman2014),作者:压缩即智能








