作者:张艾拉
今天来聊聊中转站。
简单来说,模型中转站,就是把 OpenAI、Claude、Gemini、DeepSeek 等不同模型接到同一个入口后面,让开发者用一套接口、一个账号和统一账单调用多个模型,并在不同模型或供应商之间做选择、切换和备用。
当然,对于国内用户来说,用中转站更大的原因是想用海外模型,以及更便宜。
这个大家懂得都懂,国内的中转站我们就不多说,今天主要介绍 OpenRouter。

到 2026 年,OpenRouter 已经融到 1.13 亿美元 B 轮,估值已经接近 13 亿美元。
也就是说,它已经是一家独角兽公司。
我们就来分析下,一个“不造模型”的模型中转站,为什么能值这么多钱?
OpenRouter 到底是做什么?
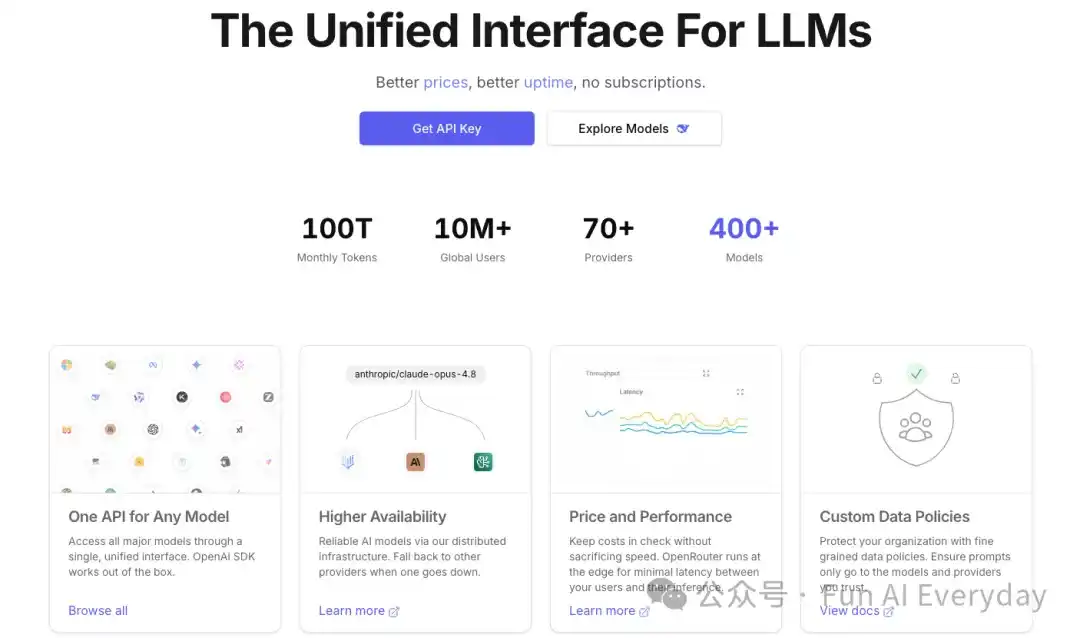
OpenRouter 官方给自己的定位是:统一的大模型接口。
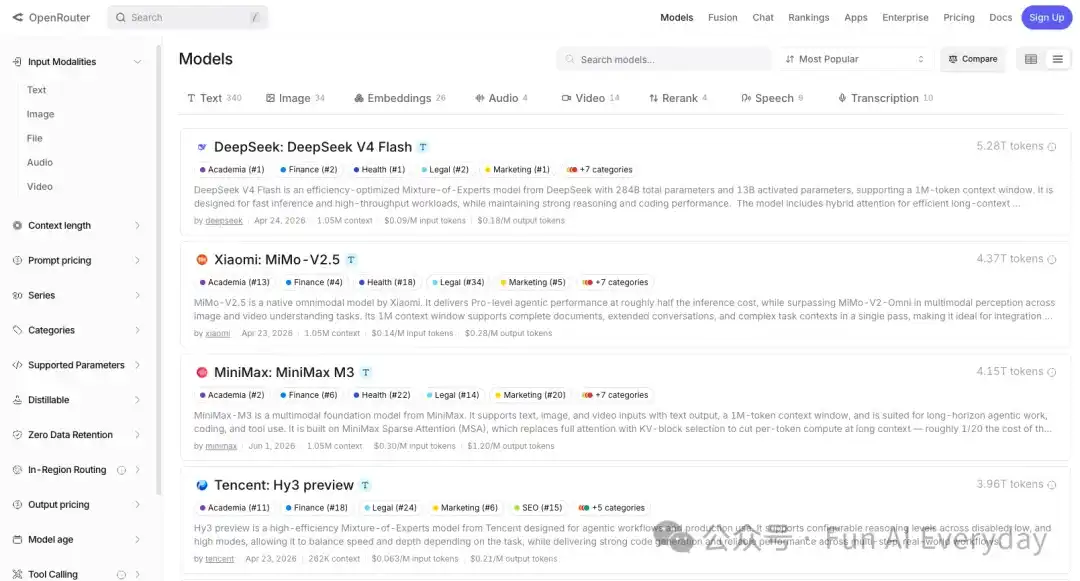
OpenRouter 现在支持 400 多个模型、70 多个模型供应商。
官网还披露,平台月处理量已经达到 100 万亿 tokens,全球用户超过 1000 万。
在 2026 年 5 月的 B 轮融资公告里也提到,过去 6 个月,OpenRouter 每周处理量从 5 万亿 tokens 增长到 25 万亿 tokens,并服务 800 多万开发者。
这些数字说明一件事:
OpenRouter 已经不是一个小众开发者工具,而是一个很大的 AI 调用入口。
开发者使用它的方式也很简单。
原来你要分别接 OpenAI、Anthropic、Google、DeepSeek、Mistral、xAI 等模型。
每接一家,都要看文档、申请 API key、绑定账单、处理接口差异、看限流规则、做异常处理。
用 OpenRouter 后,开发者可以通过同一个接口调用不同模型。
很多时候,原来使用 OpenAI 接口的代码,只需要改 base URL、换 API key,再指定模型名称,就可以通过 OpenRouter 调用别的模型。
这也是它早期增长很快的原因之一:迁移成本低。
为什么开发者不直接接模型公司?
看起来,开发者完全可以绕过 OpenRouter,直接去模型公司官网开通 API。
但在真实开发里,这件事没有那么简单。
如果一个 AI 产品只是 demo,只用一个模型就够了。但只要进入真实业务,就很难只依赖一个模型。
比如一个 AI 写作工具,可能有几类不同任务:
- 生成标题,用便宜模型就够了;
- 写长文章,需要更强的文本能力;
- 分析资料,需要长上下文模型;
- 做内容审核,需要低成本、高稳定的分类能力;
- 企业客户要求数据不被留存,就必须选择符合数据政策的供应商;
- 高峰期模型被限流,还要自动切到备用模型。
这时候,问题就不只是“接一个 API”。
团队要维护一套完整的模型调用系统:
哪个模型负责哪个任务,哪个模型更便宜,哪个供应商速度更快,哪个供应商失败率更低,出了问题怎么切换,账单怎么归因,企业客户的数据怎么隔离。
更麻烦的是,模型市场变化太快。
今天 Claude 适合写代码,明天 Gemini 的长上下文更有优势,后天 DeepSeek 或某个开源模型把价格打下来。
模型能力、价格、上下文长度、供应商政策,一直在变。
OpenRouter 的价值也就在这里。
它不是替开发者写 AI 应用,而是替开发者管理“用哪个模型、怎么调用、怎么兜底、怎么控成本”这件事。
不只是模型超市,而是模型调度层
如果只把 OpenRouter 理解成“模型超市”,就会低估了它。
模型超市解决的是“这里有很多模型,你可以挑”。
但 OpenRouter 真正重要的能力,是在模型和供应商之间做调度。
同一个模型,可能由不同供应商提供推理服务。
比如一个开源模型,可以由多家云服务商或推理服务商托管。不同供应商的价格、速度、稳定性并不一样。
OpenRouter 的文档里有一个能力叫 provider routing,也就是供应商路由。
开发者可以根据价格、延迟、吞吐、供应商顺序等条件,让请求自动走不同供应商。
它还支持 fallback,也就是某个模型或供应商失败后,系统自动切到备用选项。
对开发者来说,OpenRouter 相当于把“模型选择”和“故障处理”从业务代码里拆出来,交给一个专门的平台处理。
企业为什么会需要这层东西?
企业中上 AI,早期的问题通常是“能不能用”,但很快就会变成“怎么管”。
一个公司内部可能有很多团队都在用 AI。
市场团队用来写内容,客服团队用来回复用户,研发团队用来写代码,运营团队用来分析数据,法务团队用来处理合同。
如果每个团队都自己接模型,问题会越来越多:
- 账单分不清;模型选择不统一;
- 数据政策不透明;不同团队重复接入;
- 出了问题没人知道是哪一路调用;
- 模型供应商发生变化,系统很难统一调整。
OpenRouter 提供的工作区、预算控制、调用日志、供应商策略、零数据留存路由,都是在解决这些问题。
比如零数据留存。
对很多企业来说,不是所有请求都能随便发给任何模型供应商。客户信息、合同内容、医疗数据、金融数据,都可能有严格要求。
OpenRouter 文档里支持 Zero Data Retention,也就是零数据留存。
开发者可以设置只把请求发给不存储数据的供应商。这个策略可以按全局、模型组、安全规则或单次请求来执行。
再比如 prompt caching,也就是提示词缓存。
很多 AI 应用会反复使用很长的系统提示词、知识库内容或上下文。如果每次都重新计算,成本会很高。
OpenRouter 支持通过供应商粘性路由提高缓存命中率,尽量让后续请求走同一个供应商端点,从而降低重复上下文的成本。
这类功能听起来不性感,但非常实用,而且 AI 应用的规模越大,省下来的成本越明显。
OpenRouter 怎么赚钱?
OpenRouter 的商业模式很清楚:按使用量赚钱。
开发者先购买平台额度,然后按实际调用的模型和 tokens 付费。
OpenRouter 官方写得很清楚:
平台在购买额度时收取 5.5% 的费用,最低 0.8 美元;底层模型供应商的价格按原价转给用户,不在模型推理价格上额外加价。
这是一门很典型的“流量过路费”生意。
这个模式的好处是,收入和使用量绑定。
开发者调用越多,平台收入越高;AI 应用越多、tokens 消耗越大,OpenRouter 的生意就越大。
但它也有一个特点:单次抽成不高,所以必须靠规模。
这也是为什么 tokens 处理量对 OpenRouter 很重要。
它的核心指标不是注册用户数,而是每周、每月有多少 tokens 从它这里流过。
2025 年,OpenRouter 的年处理量从约 10 万亿 tokens 增长到 100 万亿 tokens 以上。
到了 2026 年,OpenRouter 已经达到约 1.5 千万亿 tokens 的年化处理量。
这就是这门生意的底层逻辑。
只要越来越多 AI 应用跑在多模型系统上,OpenRouter 就能从这些调用里持续抽取服务费。
为什么最近增长这么快?
OpenRouter 的增长,总结下来是吃到了三个变化。
第一个变化,是模型越来越多。
过去做 AI 应用,很多团队默认先用 OpenAI。现在不一样了。
Claude、Gemini、DeepSeek、Qwen、Mistral、Llama、Grok,还有大量开源和开放权重模型,都在不同场景里有优势。
这不是一个“谁完全替代谁”的市场。
有的模型写代码好,有的模型便宜,有的模型长文本强,有的模型速度快,有的模型适合角色扮演,有的模型适合企业文档,有的模型适合多模态。
模型越多,选择成本越高;选择成本越高,中间层就越有价值。
第二个变化,是 AI 应用开始关注成本。
很多产品早期用最强模型,因为先要把效果做出来。
但产品一旦有用户,模型成本会很快变成问题。
一个客服机器人、AI 搜索产品、代码助手、内容生成工具,如果所有请求都走最贵模型,毛利很容易被吃掉。
更成熟的做法是,把任务拆开:
- 简单任务用便宜模型;
- 复杂任务用强模型;
- 高频任务优先低延迟模型;
- 失败后切备用模型;
- 涉及敏感数据时,只走符合数据政策的供应商。
这正是 OpenRouter 的使用场景。
它不一定帮你找到“最强模型”,但它可以帮你在效果、价格、速度和稳定性之间做平衡。
第三个变化,是 AI 应用从聊天框走向智能体。
智能体会调用工具、读取文件、搜索网页、执行任务,也会连续多轮调用模型。
相比普通聊天,智能体会消耗更多 tokens,也更依赖稳定性。
这对 OpenRouter 是利好。
因为调用次数越多、链路越长,开发者越需要路由、备用、日志、成本控制和供应商管理。
这也是为什么 OpenRouter 的融资公告里强调,AI 正在从实验走向关键生产应用和智能体场景。
它的增长,本质上来自 AI 调用量的上升。
这门生意也有风险
OpenRouter 的位置很好,但并不安全。
它夹在模型公司、云厂商和应用开发者中间。这种位置既有价值,也容易被挤压。
第一个风险,是大公司可能自建。
对小团队来说,OpenRouter 很省事。
但对大企业来说,模型路由、权限、日志、成本管理,也可以自己做,或者交给云厂商做。
尤其是金融、医疗、政企客户,可能更在意数据可控和私有化部署。
OpenRouter 要进入这些客户,不能只靠“模型多”。它必须把权限、审计、数据政策、供应商管理和企业支持做得足够深。
第二个风险,是云厂商也会做模型网关。
AWS、Google Cloud、Azure 这些云平台,本来就有企业客户、账单系统、权限系统和合规能力。
它们完全可以把多模型调用、路由、监控和成本管理做成云服务的一部分。
OpenRouter 的优势是开放和中立,模型覆盖更广,接入更快。
但云厂商的优势是客户关系和企业采购流程,这是一场长期竞争。
第三个风险,是模型供应商关系。
OpenRouter 给模型公司带来流量,但也让模型公司离最终开发者远了一层。
当平台越来越大,它会掌握更多用户关系和模型使用数据。
模型供应商既希望获得分发,也会担心议价权被削弱。
这类中间层平台,早期通常被供给方欢迎;规模变大后,关系会更微妙。
第四个风险,是平台费可能被压低。
OpenRouter 收 5.5% 平台费,现在看起来不高。
但如果类似服务越来越多,开发者会比较价格、稳定性、模型覆盖和企业功能。
如果某些竞品愿意更低费率,或者云厂商把这类能力打包进已有服务里,OpenRouter 就需要证明自己不只是一个“请求转发器”。
它必须持续提供更好的路由、更强的模型覆盖、更透明的价格、更稳定的服务和更完整的企业控制。