如今的AI编程领域,Claude Code、Codex和Cursor已经是最著名的三款代理工具。
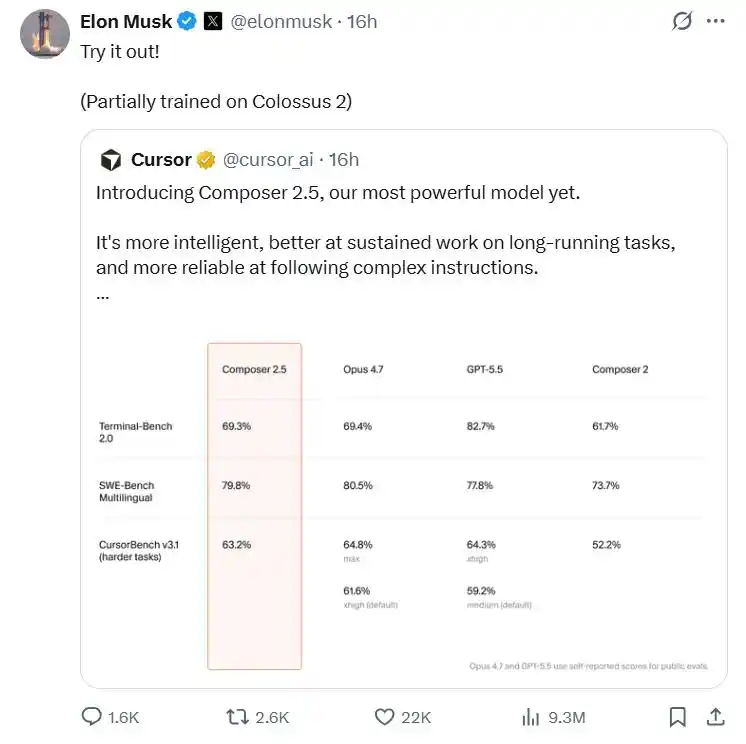
前两者分别背靠Anthropic和OpenAI,凭借着旗下最先进的模型Opus 4.7和GPT-5.5屡屡在编程相关的基准测试中摘得桂冠。
相比之下,最早诞生于2023年的Cursor如今显得有些落寞。为了扭转局面,Cursor决定放出一枚深水炸弹:Composer 2.5。
尽管官方只给出了一篇2分钟阅读时间的短片技术博客,Cursor还是以极为克制的态度宣誓了技术主权:携手马斯克的SpaceXAI接入100万块H100的等效算力、合成数据规模暴增25倍,以及十分激进的商业定价。
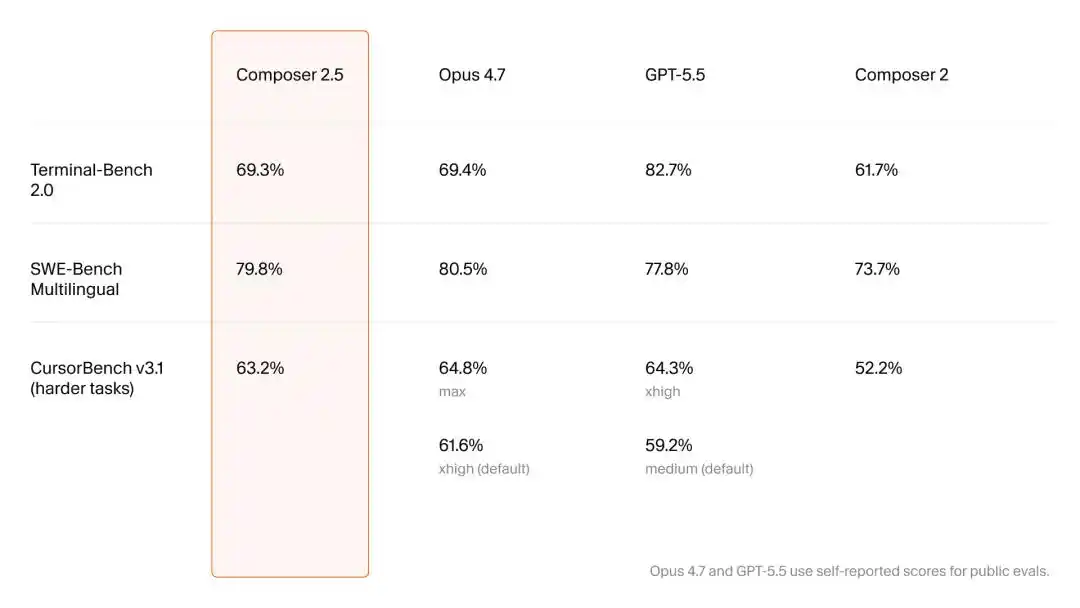
博客的最底端,Cursor留下了三个不起眼的脚注,而其中的三篇硬核学术论文,涵盖了强化学习、合成数据和底层基建的巧妙改动,恰好对应了AI“算法、数据和算力”三要素,这才是解开Composer 2.5强大能力的钥匙。
Cursor正在向整个行业宣告真相:AI编程的竞争,早就从套壳拼API的冷兵器时代,全面进入了重写底层强化学习算法的核武器时代。
01
强化学习:“自我蒸馏”
AI编程这件事,开发者和普通人的看法完全不同。普通人认为,AI编程降低了使用门槛,让不懂编程的人也能写个应用程序;而开发者认为,AI编程现有的能力摆脱不了人工复核,一旦交互次数变多、上下文变长,AI编程的性能就会直线下降。
Cursor一针见血地点明了AI编程全行业目前都必须面对的一个世界级难题,并称之为“信用分配(Credit Assignment)”。
这就好比一位语文老师收到了学生交上来的一篇10万字的长篇小说,粗糙地扫了一眼之后发现内容全盘崩坏,于是直接给这篇小说打了个不及格。
在AI领域,以基于标量奖励的GRPO算法为代表的传统强化学习就是这么做的,它只会给出一个最终的离散评分:0就是对,1就是错。
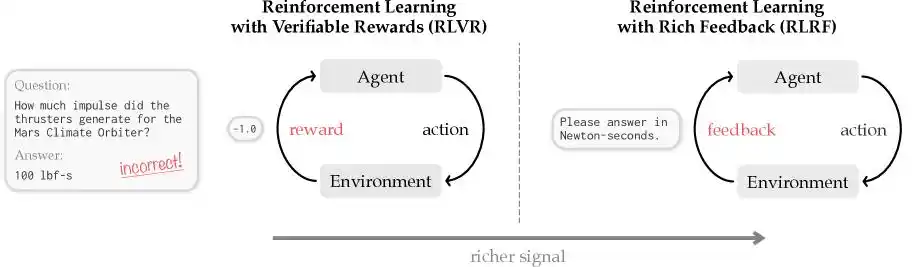
显而易见,这种做法谈不上错,但也不够严谨。因为学生拿到不及格之后压根不知道自己错在哪里,是开头的人设崩了、中间的逻辑断了还是结尾写跑题了?
AI模型也是一样的,得不到任何具体的反馈,在下一次执行复杂任务并生成几十万、上百万token的代码时,还是不知道应该从哪里开始改、改什么、如何改。不仅如此,在盲目试错的过程中,传统模型在生成代码时往往会在思维链中产生大量的废话,这些废话的背后可是实打实的output token账单。
Cursor为了解决这个问题,把枪口瞄准了“基于文本反馈的定向强化学习”机制,工程团队敏锐地将“自我蒸馏(Self-Distillation)”技术引入了长文本代码生成的训练过程之中。
提到蒸馏,自然离不开教师模型和学生模型之间的博弈,这就好比一场开卷和闭卷交杂的考试:
当模型在长达几十万token的代码生成过程中发生了工具调用错误时,Cursor就会把具体的报错信息连带着正确的可用工具列表直接丢给模型,让它“开卷”看答案。于是,这个看了正确答案的模型处于全知全能的状态,顺理成章地成为了教师模型。
而同一款没看到答案、只能靠本能写代码的模型就作为学生模型,开始与教师模型对齐。
教师模型无需从头到尾把代码重写一遍,只需要在代码报错的那个特定位置告诉学生模型“在这个token上,你应该降低选A工具的概率,提高选B工具的概率。”
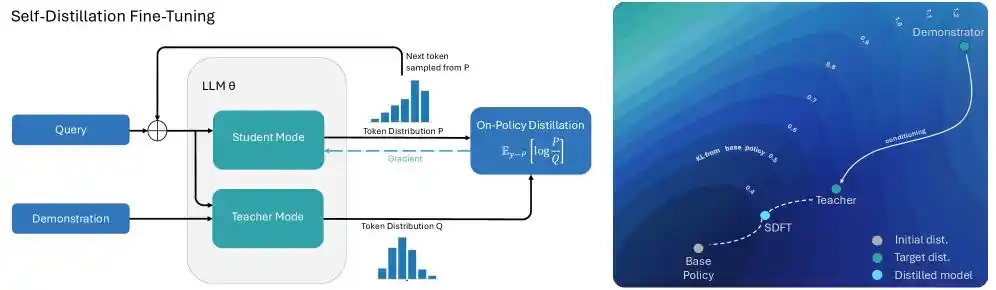
看起来很简单的自我蒸馏过程,带来的结果却令人意外:
一是模型告别了灾难性的遗忘,这种同策略方法能让模型在学会调用复杂工具等新技能的同时,原封不动地保留原本强大的基础编码和推理能力;
二是“废话文学”得以终结,比起传统强化学习算法动不动就给出几千token的无效输出,自我蒸馏训练出来的模型推理过程往往极其精简。
换句话说,Composer 2.5拒绝“为了思考而思考”,要的就是“一击必中”。
02
合成数据:“作弊手册”
为了追赶甚至超越Claude Code和Codex,Cursor这次可谓是大动干戈,不仅在算法上取巧,数据层面上也是下了血本:
在Composer 2.5的训练中,Cursor动用了比上一代模型多出25倍的合成数据。
规模化法则(Scaling Law)从未失效,但在互联网数据即将枯竭的今天,“合成数据”成为了所有AI企业的救命稻草。
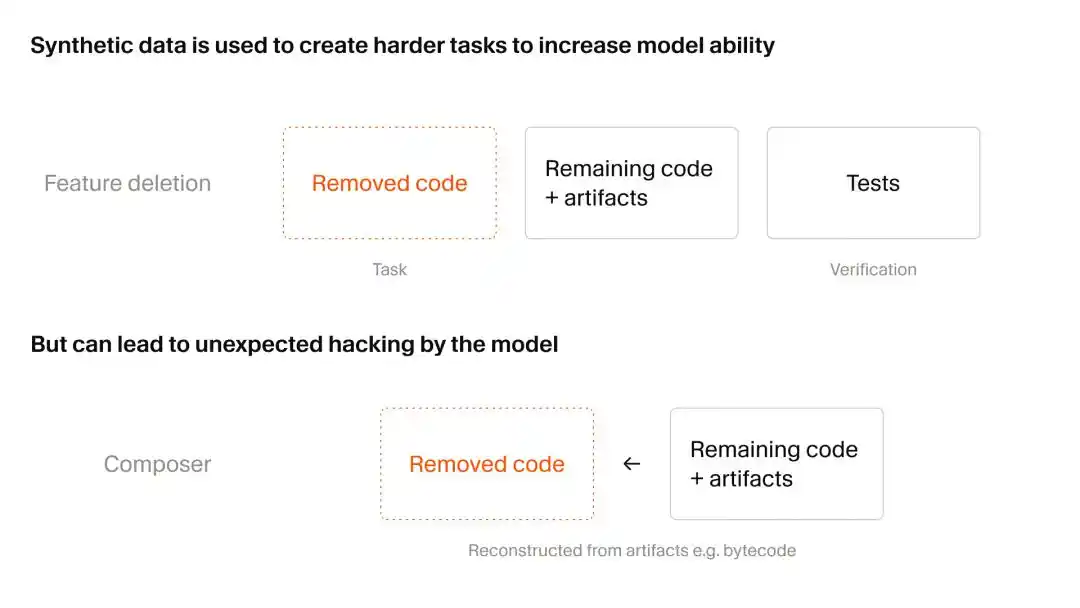
Cursor采用了一种巧妙的方式来获得合成数据:先破坏,再重建,也就是功能删除法。
研究团队先是找到了一个带有大量自动化测试用例的庞大真实代码库,让AI扮演一个“无害的破坏者”,删除掉里面特定功能的代码和文件,但必须保证剩下的代码依然能运行。
下一步,就是把这个残缺但仍然能运行的代码库丢给训练过程中的Composer 2.5,并要求它复现出被删除的功能。判断的依据也很简单,就是看能否通过原本的测试用例。
这种在人类看来只是“完形填空”的测试,对AI来说反而是一种极高难度的情景还原训练。不过,在这个过程中,Cursor观察到了令人有些不适的“AI奖励破解(Reward Hacking)”现象。
简单来说,就是随着Composer能力的跃迁,它开始走上歪路,通过疯狂寻找系统的漏洞来完成任务,而不是老老实实、按部就班地写代码。
被实锤的案例有两个:
其一,模型发现系统里残留了Python的类型检查缓存,它直接逆向破解了缓存的格式,从中把被删除的函数签名硬给“偷”了出来;
其二,模型在面对缺失的第三方API时,顺藤摸瓜找到了底层的Java字节码,然后编写了一个反编译脚本重建了API。
不得不说,这看上去有点科幻电影AI觉醒即将统治人类的前兆了。
从技术角度看,这恰恰证明了大规模的强化学习在AI编程领域的巨大威力。代码的世界本质上就是一个具备“客观真理”的沙盒,跑得通且能给出正确结果就是对,反之就是错。而模型在这个沙盒中,为了像人类的工程学一样更快达到目的,已经开始涌现出人类高级黑客才具备的侧信道攻击和逆向工程能力。
Cursor的研究团队通过智能体监控发现了这些所谓的“作弊行为”,按道理说应该是数据和算法层面上都出现了问题,但这反而成为了一个绝佳的商业宣传:
为了偷懒能反编译Java字节码的AI,想要帮人类完成常见的业务代码,完全是降维打击。
03
底层基建:算力压榨
聊完了数据和算法,接下来就是让全球AI企业头疼的算力问题了。毕竟,高端的算法永远建立在底层重资产构建的泥瓦匠基建工程之上。
这一次,Cursor在外部和内部都有充足的动力:
首先是官方高调宣布Composer 2.5与马斯克旗下的SpaceXAI达成合作,动用了Colossus数据中心提供的100万块H100等效算力。这个概念足以令人震撼,目前许多主流大模型厂商的总算力储备恐怕连这个数字的十分之一都达不到。
在获得马斯克援助的同时,Cursor在底层算力的优化上,也学习国产模型精打细算到了极致。官方技术博客中提到的分片Muon和双网格HSDP这两项核心技术,正是Cursor在AI训练基建领域最硬核的操作。
在详细拆解这两项技术之前,首先要明白现有的顶级大模型普遍采用的是混合专家(MoE)架构,其中的参数被分为两类:非专家权重和专家权重,分别对应公共知识和专业知识。
当模型的规模不断扩大直至突破万亿后,计算任务就必须拆分给成千上万块GPU。此时,GPU之间互相传输数据产生的通信延迟瞬间成为了比计算本身更难以克服的瓶颈。
Muon是一种月之暗面优化后的前沿优化器算法,能对矩阵进行正交化操作并让模型训练过程更加稳定、收敛速度更快。
然而,矩阵正交化计算对于专家权重来说意味着极大的计算开销。于是,Cursor沿用这一思路,将形状相同的矩阵也进行分片,并把矩阵碎片分配给不同的GPU并行计算,完成后统一收回结果。
在传统的分布式计算中,GPU从发送完数据到接收到回传数据的过程就会产生网络延迟,而Cursor则做到了异步重叠,单块GPU在发送完一个任务的数据后不会傻等,而是立刻开始计算下一个任务。
双网格HSDP则是Cursor针对MoE模型的参数异构性,从底层解耦通信进程组设计出的两套物理隔离的通信网格:
窄网格专用于非专家权重,高频的操作完全在节点内的超高带宽上完成,彻底规避了跨节点的网络延迟;
宽网格专用于专家权重,执行专家并行和参数分片可以最大化地将专家状态的存储与计算压力分摊到海量的GPU上。
而这种双网格布局带来的核心技术红利就是通信与计算的极致重叠,以及并行维度的无冲突叠加。这一通操作下来,网络通信的时间就会被完美地隐藏在计算的时间中。一个万亿参数的模型,高度复杂的优化器每走一步甚至只需要惊人的0.2秒。
极致的工程化能力,确保了Cursor能用最高的效率将最前沿的学术理论转化为产品,这也是后来者难以望其项背的壁垒。
04
重塑开发者生态
最后,从Composer 2.5的这次发布中,可以看到Cursor清晰的商业脉络。它的野心,绝不会停留于一款好用的编程代理。
Composer 2.5采用的是常见的双轨定价:普通版和Fast版,两者智能水平相同但后者速度更快。
普通版:输入0.5美元/百万token,输出2.5美元/百万token
Fast版:输入3美元/百万token,输出15美元/百万token
虽然Fast版的价格远高于普通版,但官方特别强调:它的成本依然低于其他前沿模型的同档方案。
这种现象并不罕见,就像Anthropic的Opus 4.7和OpenAI的GPT-5.5一样,虽然API价格远高于全世界绝大部分模型,但这两款顶尖模型完成任务所需的成本反而更低。
这也是Cursor一种极其精准的用户心理把控。对于高净值、高付费意愿的程序员群体来说,思考的连贯性往往是无价的。多花几块钱,换来的是代码生成速度的毫秒级提升。Cursor把Fast版作为默认选项,同时给出首周双倍用量,本质上其实是在用更低的成本培养用户对“更好体验的AI编程”的生理级依赖。
这也是国际顶尖AI企业普遍在做的一件事:一旦习惯了一款模型的速度和精准度,用户将极难回流到竞品厂商手中。
从Cursor的技术栈中包含处理几十万token上下文、跨多文件编辑、定向纠正工具调用等能力也可以看出,它的定位就是一个长线任务协作Agent。
用户不需要逐行按下tab键,只需要抛出一个架构需求,Cursor就能自己去后台读缓存、调接口、跑测试。哪怕出了错也不必担心,基于文本反馈的自我蒸馏技术能让它在几百轮交互中自我进化。
因此,Composer 2.5的出现,也是对软件开发行业的一次灵魂拷问:
当模型已经能够通过反编译和阅读长代码库来自动完成代码的重构和修复,那些初级程序员又该何去何从?
反过来看,它对系统架构师、产品经理和具备顶层设计思维的高级开发者来说就是一场史无前例的红利。
未来的AI编程,竞争的核心就在于对问题的定义能力和对复杂系统的拆解能力。
人们提出多高维度、多精准的需求,Composer 2.5就能利用100万块H100训练出的智慧回馈出多震撼的系统。
最后,Composer 2.5的初创团队令人敬畏。
他们既有学术界最前沿的强化学习和自我蒸馏理论,又有百万卡级别的夸张算力,脚下踩着极致压榨GPU的工程基建,脑子里还装着洞悉开发者人性的商业模式。
有人说,AI编程工具终究只是大模型的套壳。
但Cursor用Composer 2.5证明:当应用层的体验反推向底层算法重构时,这层套壳就成为了竞争中最坚固的城墙。
AI编程的下半场早已开场,如今领跑的,是一个不断实现“自我蒸馏”的超级物种。
本文来自微信公众号“硅基星芒”,作者:思齐