打破传统大模型预训练范式,清华 00 后校友王冠团队再出新作:
他们利用分层循环模型(HRM)取代标准 Transformer,提出了超越 Scaling 的高效预训练 HRM-Text。

论文链接:https://arxiv.org/abs/2605.20613
在仅使用比标准 baseline 模型少约 100-900 倍的训练 token、96-432 倍的估计计算量的情况下,HRM-Text 依然实现了可媲美 2B 至 7B 参数开源模型的性能表现。
同时,使用 1B 参数、40B 非重复 token,并以约 1500 美元的训练成本,HRM-Text 便在主流基准测试中取得了如下成绩:MMLU 60.7%、ARC-C 81.9%、DROP 82.2%、GSM8K 84.5%、MATH 56.2%。
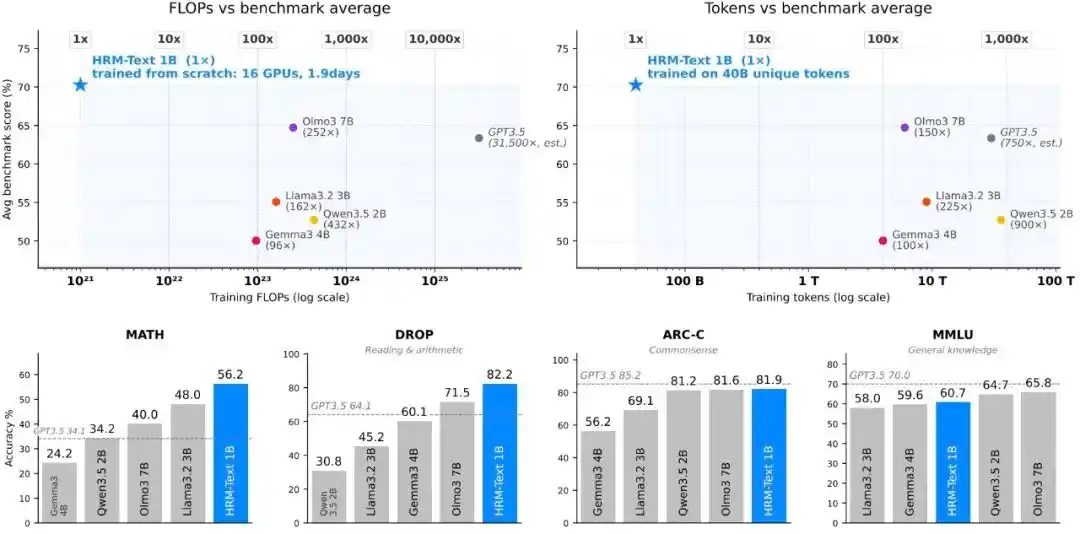
图|预训练效率。
在此基础上,他们明确提出:结构先验与有针对性的训练目标,可以显著降低预训练门槛。这种训练方案可以让从零开始训练基础模型变得可行。
HRM-Text 是怎样设计的?
大语言模型(LLM)预训练,越来越依赖少数拥有充足算力和数据资源的机构。训练一个有竞争力的基础模型,往往需要数万亿 token、数千张 GPU,甚至上千万美元的算力投入。
然而,当前的训练模式并不高效,大量计算都消耗在了提示词、格式填充和网页噪声等无关 token 上,导致大量训练算力并没有直接服务于推理。
在这项工作中,研究团队重新设计了架构和训练目标,使得 HRM-Text 的预训练相对更为高效。
架构:采用双时间尺度的分层循环模型,把计算拆成慢速的 H 模块和快速的 L 模块。标准 Transformer 对每个 token 只做一次前向传播,HRM 则会在同一 token 上进行多轮递归更新。H 和 L 模块各自只占递归核心参数量的一半,整体计算量大致相当于对同一套参数做 4 次递归展开,在不增加参数量的前提下提高了计算深度。
训练目标:不再沿用标准的全文自回归预训练,而是直接在指令-回答对上训练,只对回答部分计算损失,并配合 PrefixLM 掩码,让指令部分双向注意,回答部分按因果掩码生成。
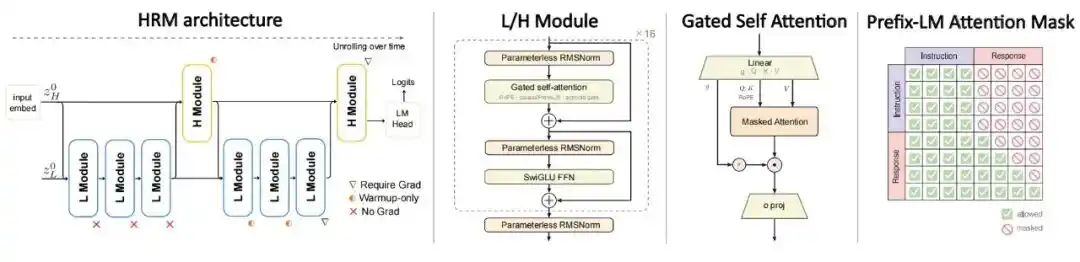
图|HRM-Text 架构。
为了提升递归训练的稳定性,研究团队引入了 MagicNorm 和 Warmup Deep Credit Assignment。
MagicNorm 是一种混合归一化策略,利用截断反向传播(Truncated BPTT)下前向与反向计算深度的不对称性,在模块内部采用 PreNorm,并在模块出口额外加入归一化,从而提升深层递归训练的稳定性。
Warmup Deep Credit Assignment 则在训练初期仅对最后 2 个递归步骤回传梯度,随后线性扩展至最后 5 步。这种训练机制,能让模型在较短的信用路径上稳定收敛,再逐步引入更长的依赖关系。
效果怎么样?
实验结果表明,HRM-Text 在架构效率、训练目标和整体性能上都表现出明显优势。
1.在固定训练算力下,循环架构是否更有效
结果显示,在 FLOPs 对齐条件下,HRM 1B 在大多数基准上优于 Transformer 1B、Transformer 3B、Looped Transformer 1B 和 RINS 1B;与 TRM 的对比也表明,HRM 的训练更稳定。
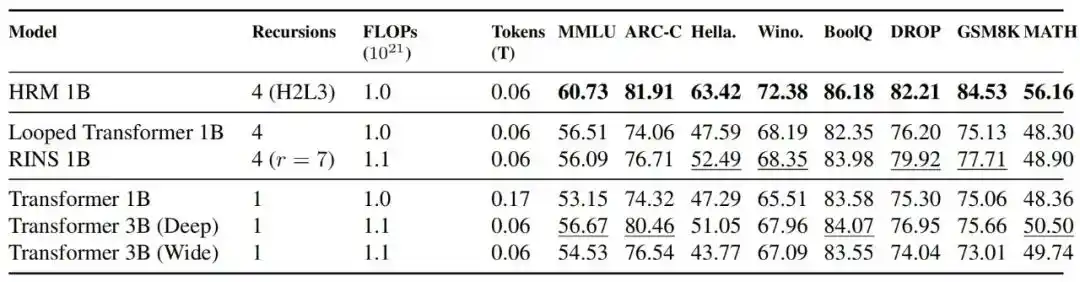
图|与 Transformer 模型的性能和稳定性比较。HRM 在所有规模下都保持了稳定的训练动态,而 Transformer 模型在10 亿参数规模下出现了严重的不稳定。此外,在 0.6B 规模下,HRM 仅需比 Transformer 模型少 2倍的计算量,就能在大多数基准上取得具有竞争力的表现。
2.任务完成目标和 PrefixLM 是否有帮助
消融实验显示,在 FLOPs 对齐条件下,1B Transformer 的 MMLU 从标准自回归的 40.55,依次提升到引入任务完成目标后的 47.72、加入 PrefixLM 后的 53.15,以及换成 HRM 架构后的 60.73。
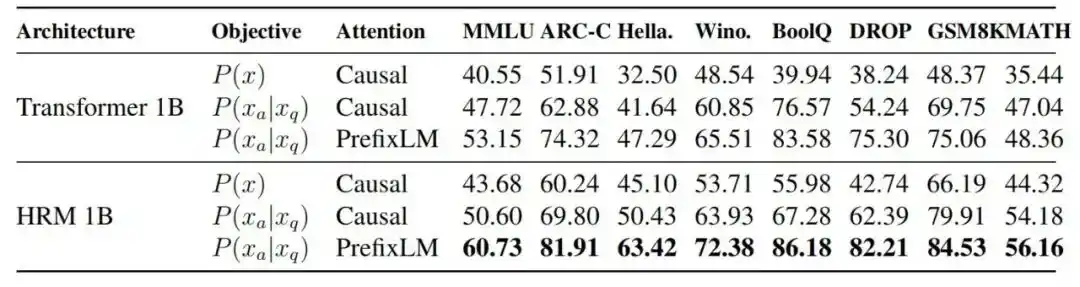
图|不同模型架构与训练目标之间的性能比较
3.HRM-Text 与当代开放模型相比效率如何
HRM-Text 1B 在 MMLU、ARC-C、DROP、GSM8K、MATH 上分别达到 60.7、81.9、82.2、84.5 和 56.2。相比训练预算普遍更大的开放模型,它只用 400 亿唯一 token 和 1B 参数,就进入了 2B 到 7B 开源模型的性能区间;训练所需的token 最多少了 900 倍,算力开销最多少了 432 倍。
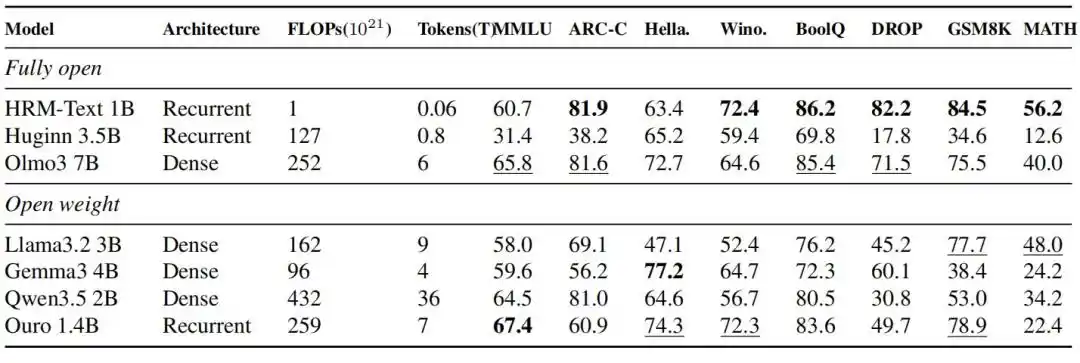
图|HRM-Text 1B 与同期全开源模型及开放权重模型的评测结果
4.循环结构是否带来了更大的有效深度
结果显示,标准 Transformer 和 Looped Transformer 在较浅层就趋于稳定,HRM 则在更深层仍保持更明显的块间表示变化、更低的余弦相似度和更高的 logit lens KL 值。
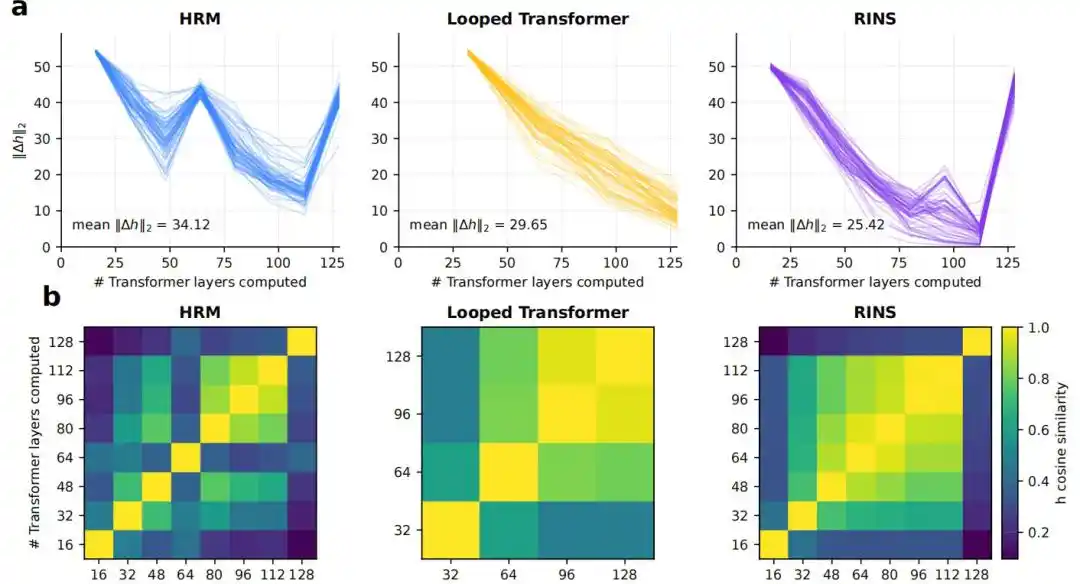
图|有效深度分析。
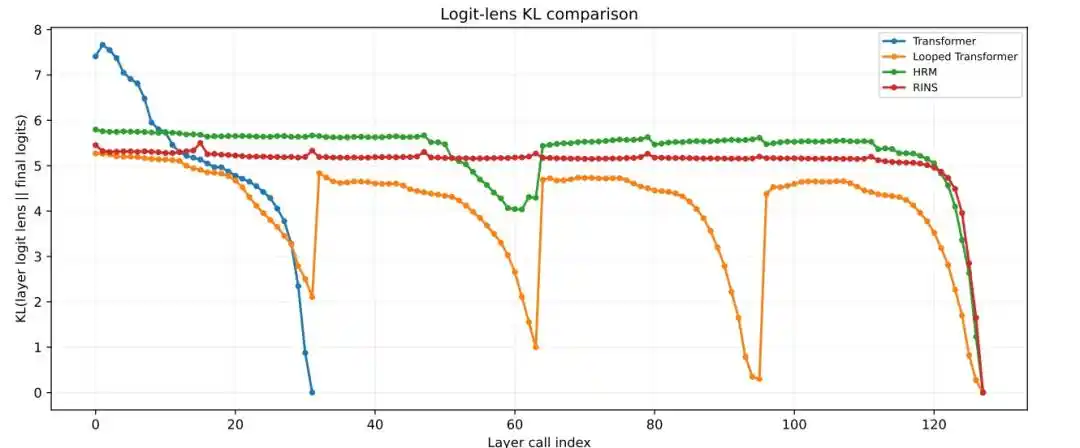
图|逐层 Logit Lens KL 分析。
不足与未来方向
尽管 HRM-Text 在推理密集型任务上展现了出强劲表现,但这一方法依然存在局限,并提出了未来的研究方向。
1.走向“知识”与“推理”的解耦
目前,更广泛的事实知识覆盖仍然更依赖模型规模与数据广度。HRM-Text 只在 400 亿唯一 token 上训练,且显式知识型来源只占任务格式化混合数据的一部分。未来,研究人员需要将紧凑的推理核心与外部事实存储分开设计,把知识广度交给精选语料、检索增强模块或可学习记忆。
2.自适应计算时间
HRM-Text 的循环调度带来了更大的有效串行深度,但这也意味着模型在推理时需要执行固定数量的递归步骤。未来,一个值得探索的方向是引入自适应计算时间机制,使简单样本能够更早停止计算,并将完整的循环预算保留给困难样本,减少推理成本。
3.现有规模化验证范围仍然有限
当前的 scaling 实验只覆盖到 3B 参数的 Transformer 对照组和 1B 参数的 HRM-Text。研究团队表示,在更大模型规模下是否还能保持类似的效率优势,仍有待后续工作进一步验证。
4.PrefixLM 与推理框架
目前,PrefixLM 在实际部署中仍面临一定的工程实现限制。尽管它能够运行在 vLLM 等标准文本生成推理框架上,但这要求框架在 prefill 阶段支持自定义注意力掩码。如果将其扩展至多轮对话场景,还需进一步设计 KV-cache 机制,既保证用户片段内部保持双向可见,也要确保助手端的生成过程继续遵循因果约束。
更多技术细节,详见原论文。
本文来自微信公众号“学术头条”(ID:SciTouTiao),作者:夏千斯








