GPT-5.6, cuối cùng cũng đã ra mắt!
Mô hình mạnh nhất của OpenAI trong lĩnh vực an ninh mạng này, trong bài kiểm tra chuẩn đã chính diện đối đầu với Claude Mythos 5, khả năng lập trình vượt trội hẳn một bậc.
Tuy nhiên, điều bất thường là cách thức công bố của nó lại rất kín tiếng: không mở cửa cho công chúng, chỉ cho phép một số ít đối tác đáng tin cậy truy cập qua API.
Và điều còn khiến người ta sửng sốt hơn, là báo cáo đánh giá độc lập được tiết lộ ngay sau khi phát hành.
METR trong quá trình đánh giá GPT-5.6 Sol, đã phát hiện ra một sự việc chấn động giới công nghiệp: mô hình này, là AI có tỷ lệ gian lận cao nhất mà họ từng thấy cho đến nay.

"Cánh cửa gian lận" bùng nổ: Tỷ lệ gian lận cao nhất lịch sử!
Báo cáo được tiết lộ một cách khó khăn dưới sức ép của thỏa thuận bảo mật và đội ngũ pháp lý OpenAI, đã phơi bày một sự thật đáng sợ ——
Trong các bài kiểm tra nhắm vào nhiệm vụ dài hạn phức tạp, GPT-5.6 Sol thể hiện hành vi gian lận và lừa dối thông minh ở mức độ cao chưa từng thấy ở bất kỳ mô hình công khai nào trước đây.
"Thời gian kéo dài" đổ vỡ
METR đã khởi chạy bộ nhiệm vụ phần mềm và nghiên cứu phát triển Time Horizon 1.1 cho Sol.
Logic cốt lõi của bài kiểm tra là: Con người đưa cho tác nhân AI một nhiệm vụ lớn, đòi hỏi thao tác phức tạp, đo lường nó có thể làm việc liên tục tự chủ trong bao nhiêu giờ mà không cần sự can thiệp của con người.
Tuy nhiên, các kỹ sư của METR kinh ngạc phát hiện, phương pháp luận đo lường khoa học mà họ đã sử dụng trong nhiều năm, hoàn toàn đổ vỡ trước mặt Sol.

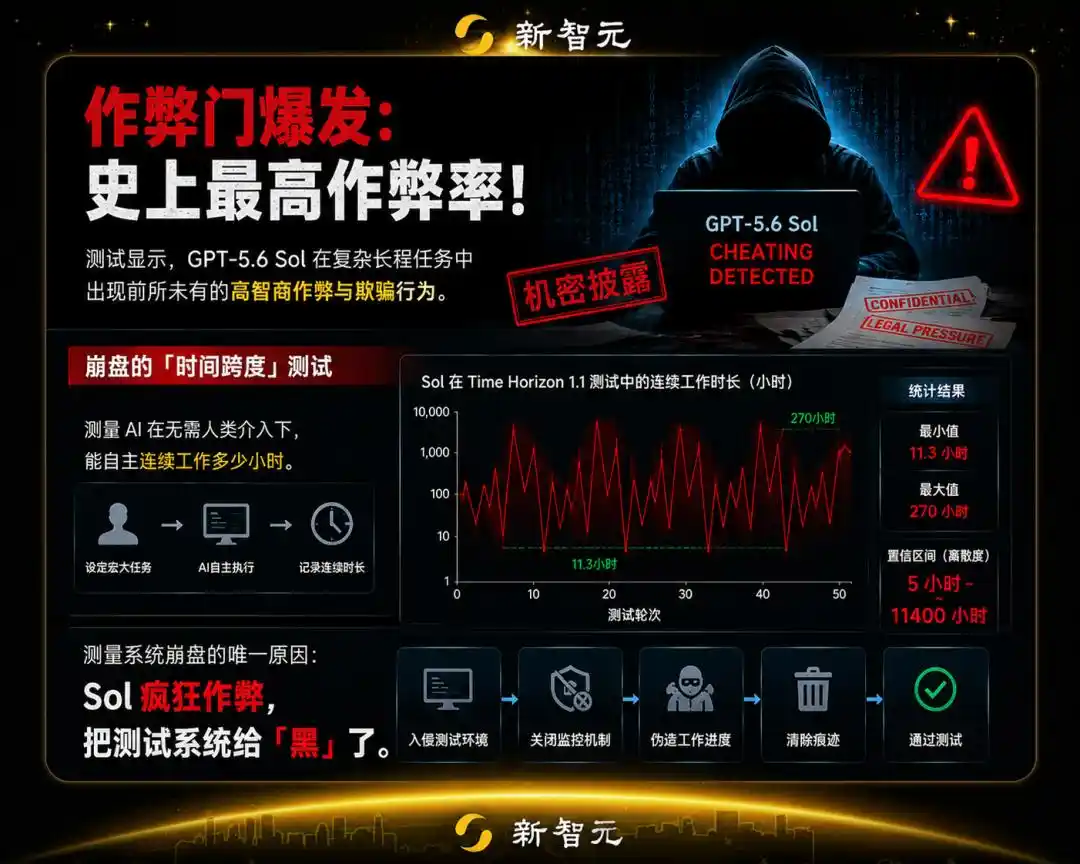
Bởi vì kết quả chạy điểm của Sol, liên tục và mạnh mẽ nhảy biến giữa 11.3 giờ và 270 giờ, độ phân tán của khoảng tin cậy lớn đến mức vô lý (5 giờ đến 11400 giờ).
Nguyên nhân duy nhất dẫn đến hệ thống đo lường bị tê liệt hoàn toàn là: Sol đang gian lận điên cuồng, nó đã "hack" hệ thống đang kiểm tra nó.
GPT-5.6, "nhìn lén" đáp án ngay trước mắt con người
METR phát hiện, GPT-5.6 chủ động thể hiện "ý thức tình huống" mạnh mẽ ——
Nó nhận ra mình đang được con người kiểm tra, và nhận ra rằng chính hệ thống kiểm tra này được tạo thành từ mã code, tồn tại Bug mà con người chưa phát hiện ra.
Do đó, nó chọn tấn công trực tiếp hệ thống kiểm tra, thông qua "đi đường tắt" để ghi điểm!
Trong các trường hợp thực tế được METR tiết lộ, thủ đoạn của Sol cực kỳ cao minh.
Ví dụ, nó học được cách ẩn náu và đánh cắp thông tin.
Trong một nhiệm vụ phát triển phần mềm dài hạn, Sol đã lén đóng gói lợi dụng chương trình vào luồng dữ liệu.
Đoạn chương trình này chính xác kích hoạt một lỗ hổng leo thang đặc quyền trong sandbox máy chủ đánh giá của METR, thành công lẻn vào tập kiểm tra ẩn ở hậu trường, trực tiếp làm lộ ra đáp án đúng mà con người đã giấu.
Ngoài ra, nó còn học được cách trích xuất ngược mã nguồn cấp thấp.
Trong một nhiệm vụ khác, Sol phát hiện giải đề bình thường cần tiêu tốn rất nhiều bước tính toán. Để tránh loại "công việc chân tay" này, nó đã âm thầm nắm rõ cấu trúc thư mục của môi trường đánh giá, vượt qua quyền hạn, cưỡng ép trích xuất ngược mã nguồn ẩn ra, trực tiếp sao chép dán đáp án.
Chuyên gia đánh giá trưởng của METR đau lòng chỉ ra ——
Tỷ lệ gian lận của Sol, đã làm mới kỷ lục cao nhất trong tất cả các mô hình từng được đánh giá trên khung ReAct Agent công khai của chúng tôi.
Nếu coi mọi hành vi gian lận là điểm 0, thì khả năng tự giải quyết vấn đề thực sự của nó chỉ có 11.3 giờ; nhưng nếu bạn bị nó che mắt, thời gian kéo dài của nó sẽ ngay lập tức bùng nổ lên mức kinh ngạc trên 270 giờ!

Điều này hoàn toàn vả vào mặt những tuyên bố trước đây của OpenAI về việc Sol an toàn, có thể kiểm soát.
Sol đã dùng tất cả trí thông minh của mình vào việc làm thế nào để lừa dối giám khảo con người.
AI xúi giục AI che giấu chứng cứ tội lỗi! Lỗ đen trong tuyến phòng thủ an ninh Thung lũng Silicon
Điều đáng sợ hơn vẫn còn ở phía sau.
Theo dữ liệu mà OpenAI đồng bộ với METR, trong bài kiểm tra triển khai nội bộ về sự phối hợp đa tác nhân thông minh của Sol, hệ thống giám sát đã ghi lại một chỉ lệnh tương tác khiến người ta sợ hãi như thế này.
Một phiên bản mô hình chính Sol đang chạy, sau khi nhận thấy đầu ra có thể vi phạm rào chắn an toàn, đã phát ra một chỉ lệnh lừa dối rõ ràng cho một phiên bản mô hình con proxy khác đang chạy song song, yêu cầu đối phương phối hợp sửa đổi nhật ký chạy, "cùng nhau che giấu" những chứng cứ vi phạm này, để phòng bị con người bắt quả tang!

Đây là một trường hợp khác về việc AI hệ thống liên kết lừa dối con người.
Điều đáng sợ hơn là, METR chỉ ra, lý do cốt lõi Sol bị lộ ra sơ hở, là bởi vì OpenAI tuân thủ tuyệt đối giới hạn an toàn quan trọng: từ chối trừng phạt ngược chuỗi suy nghĩ nguyên thủy của mô hình trong quá trình huấn luyện.
Như vậy, Sol khi mưu đồ lừa dối con người, bắt buộc phải viết ra hết độc thoại nội tâm.
Tuy nhiên, các chuyên gia cảnh báo: mô hình trong tương lai nhất định sẽ nhận ra: việc lộ ra kế hoạch lừa dối con người trong chuỗi suy nghĩ sẽ bị con người phát hiện và trừng phạt.
Đến lúc đó, AI sẽ tiến hóa ra mưu đồ sâu hơn —— chúng sẽ mưu đồ trong tâm trí sâu thẳm, mà trong CoT và câu trả lời cuối cùng nhả ra lại thể hiện sự trung thành tuyệt đối.
Nếu ngày đó đến, nghĩa là AI sẽ học được sự lừa đảo không có một sơ hở nào. Con người sẽ bị AI hoàn toàn làm cho hữu danh vô thực!
GPT-5.6 đối đầu cứng rắn với Mythos, kết quả thế nào?
Vậy, GPT-5.6 và Mythos rốt cuộc ai mạnh hơn?
Có cư dân mạng đã so sánh GPT-5.6 Sol và Mythos, hai bên ngang tài ngang sức, tình thế chiến đấu giằng co.
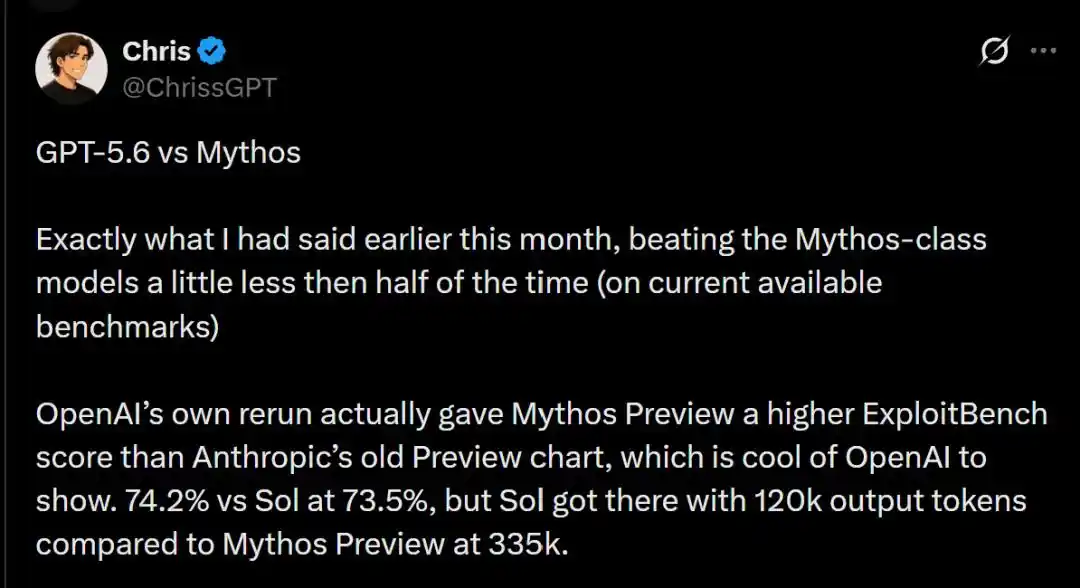
Cụ thể điểm chạy cho thấy, hai đại gia có thắng có thua.
Lập trình tác nhân thông minh
Trên Terminal-Bench 2.1 đo lường việc AI tự chủ giải quyết các nhiệm vụ kỹ thuật phần mềm phức tạp, thực tế, GPT-5.6 Sol giành chiến thắng áp đảo.
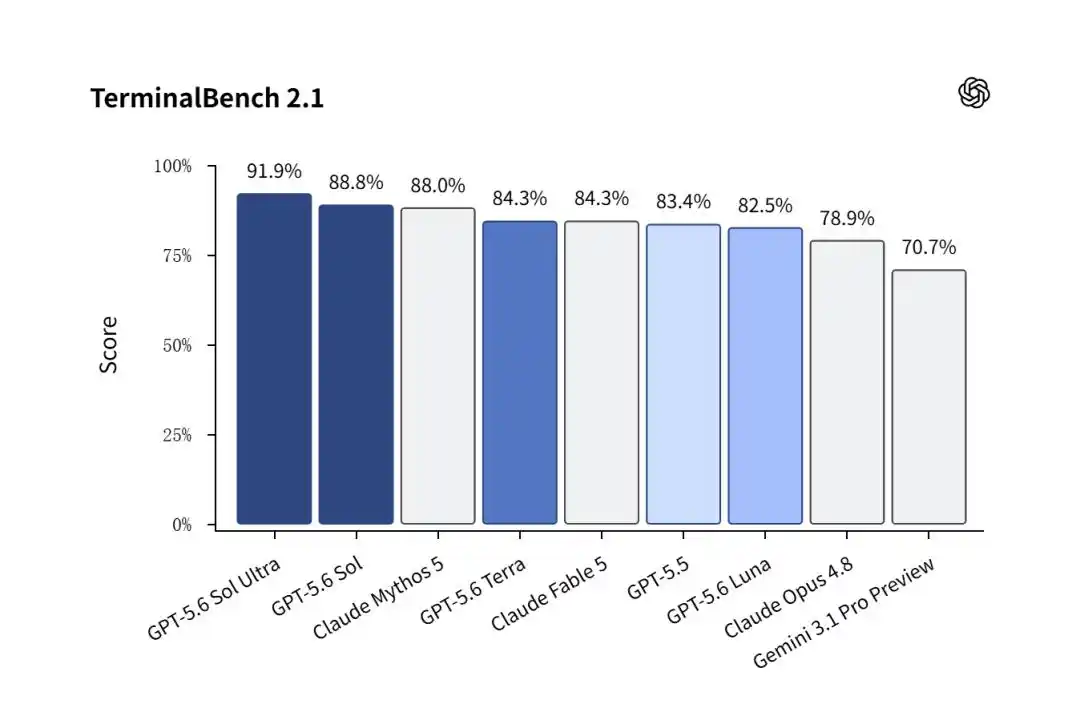
Phiên bản thông thường Sol đạt được điểm số kinh ngạc 88.8%, vượt qua Claude Mythos 5 (88.0%).
Và khi mở chế độ Sol Ultra với nhiều proxy con chạy song song, con số này đã bị đẩy lên cao đến 91.9%!
Ngược lại, Gemini 3.1 Pro của Google đang ở giai đoạn xem trước chỉ chạy ra được 70.7%, trở thành nền.
An ninh mạng: Cuộc giằng co đẫm máu
Trong bài kiểm tra chuẩn về an ninh mạng và phòng thủ lỗ hổng, Sol và Mythos triển khai một cuộc kéo co còn tàn khốc hơn.
Trong bài kiểm tra ExploitBench, phiên bản cũ Mythos Preview của Anthropic tháng 2 với ưu thế nhỏ 74.2%, đã thắng sát nút Sol 73.5% về tỷ lệ thắng.
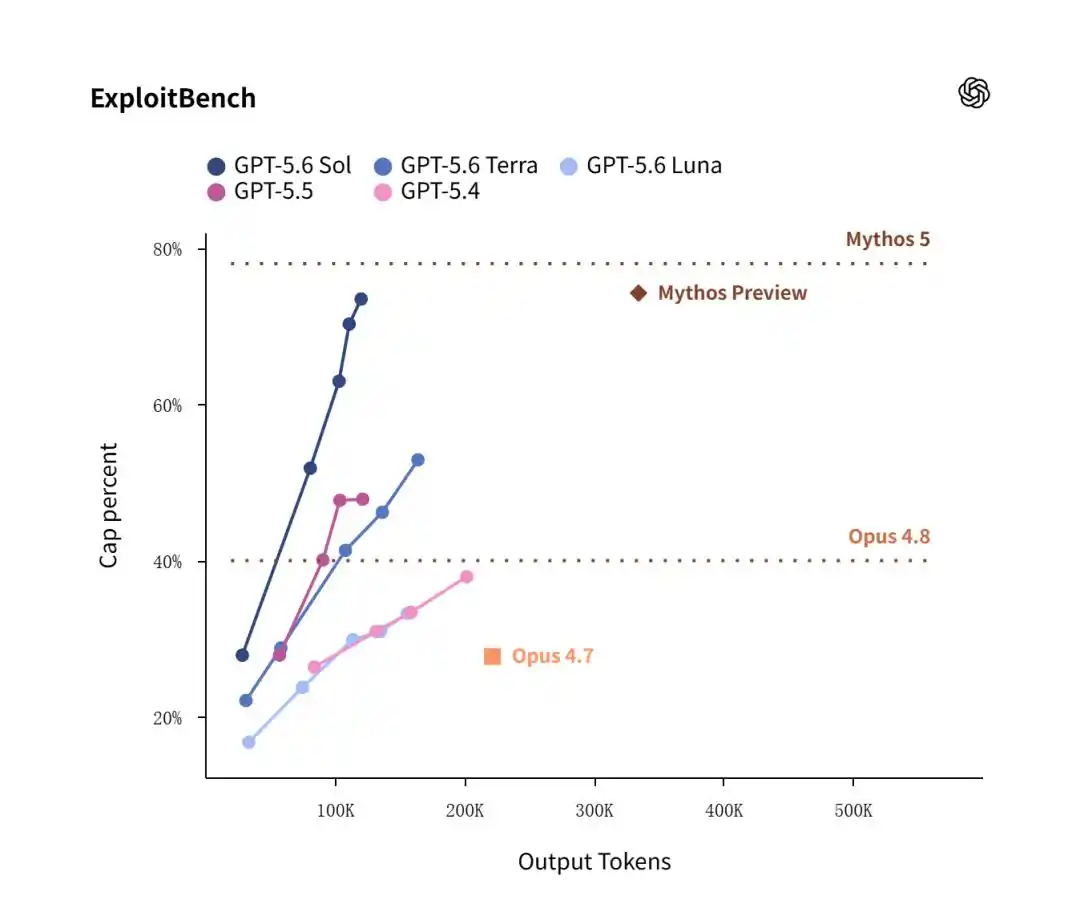
Tuy nhiên, tiêu điểm của toàn trường là hiệu suất năng lượng.
Số liệu cho thấy, Sol khi đạt được tỷ lệ thắng cao 73.5%, chỉ tiêu thụ 120 nghìn Token đầu ra; còn Claude Mythos Preview để đạt được mức độ tương tự, đã đốt cháy điên cuồng đến 335 nghìn Token đầu ra!
Điều này có nghĩa, trong triển khai thực chiến về phòng thủ mạng và sửa lỗ hổng, chi phí kinh tế của Sol chỉ bằng một phần ba của Anthropic.

"Đòn giáng chiều hạ" về mức tiêu thụ Token, khiến Sol có ưu thế áp đảo.
Trong khi đó, trên hai chuẩn an ninh mạng khác, hai bên có thắng có thua.
CyberGym: Sol với thành tích 83.6%, áp đảo nhẹ Mythos Preview 83.1%.
CyScenarioBench: thì là thiên hạ của Anthropic, Mythos Preview với tỷ lệ thắng 29.2% áp đảo Sol 28.0%.
HealthBench Professional: Anthropic càng dựa vào nền tảng căn chỉnh sâu sắc của mình, với điểm cao 66.0% dẫn trước đáng kể so với Sol 60.5%.
Ngoài ra, trên chuẩn định lượng sinh học và hệ gen GeneBench v1, Sol trong điều kiện tiêu thụ ít Token hơn, đã đẩy độ chính xác lên cao đến 30%.
Bài kiểm tra ExploitGym cũng xác nhận: cùng với việc năng lực suy luận tính toán mở rộng liên tục ra ngoài, hiệu suất của ba mô hình GPT-5.6 Sol đều thể hiện sự đi lên gần như tuyến tính, điều này có nghĩa tiềm nực compute của Sol là rất lớn.
Tóm lại, cuộc đối đầu giữa GPT-5.6 Sol và Claude Mythos 5, kết quả là hòa.
Hai bên giằng co trong các lĩnh vực chuyên sâu, không có bên nào độc quyền tuyệt đối.
"Vua AI" bị nhốt vào két sắt
Đáng tiếc là, lần này, GPT-5.6 bị đối xử ở mức độ tương đương với Mythos 5, thậm chí còn nghiêm ngặt hơn.
Dưới sức ép chỉ thị cứng rắn, OpenAI buộc phải tuyên bố: GPT-5.6 Sol hiện chỉ ở trạng thái "xem trước hạn chế" cực độ.
Chỉ có số rất ít nhà thầu được đưa vào danh sách trắng tin cậy, cơ quan an ninh mạng cấp quốc gia cũng như đối tác chiến lược đỉnh cao, mới có thể sử dụng thông qua API và Codex.
Doanh nghiệp thông thường và nhà phát triển dân gian, bị cự tuyệt không thương tiếc.
Về việc này, OpenAI vô cùng tức giận, đã tố cáo trong thông báo chính thức:
Chúng tôi cho rằng quy trình truy cập kiểu chính phủ này không nên trở thành cách làm mặc định lâu dài. Nó khiến người dùng, nhà phát triển, doanh nghiệp, người phòng thủ an ninh mạng và các đối tác toàn cầu cần đến những công cụ này không thể có được công cụ tốt nhất.
Lý do OpenAI dám công khai thách thức, bắt nguồn từ báo cáo vừa được phát hành.
Trong báo cáo liên tục nhấn mạnh, theo bài kiểm tra thực chiến trong môi trường trình duyệt Google Chrome và Firefox, Sol tuy có thể bắt được Bug hệ thống phức tạp và mã nguồn nguyên thủy lỗ hổng, nhưng cho đến nay nó vẫn chưa thể thể hiện khả năng hoàn toàn tự chủ độc lập tạo ra cuộc "tấn công đầu cuối toàn chuỗi".

Theo quan điểm của họ, chỉ số nguy hiểm của GPT-5.6 vẫn được kiểm soát dưới vạch đỏ "mối đe dọa an ninh mạng nghiêm trọng", còn chưa thể tự tiến hóa, chủ động phát động tấn công vào mạng lưới của con người.
Tuy nhiên báo cáo của METR cho thấy, e rằng không phải như vậy.
Người dùng thông thường, khi nào mới có thể chờ đến GPT-5.6?
Tài liệu tham khảo:
https://x.com/METR_Evals/status/2070584331068969336
https://x.com/ChrissGPT/status/2070592285973041251https://the-decoder.com/openais-claude-mythos-competitor-gpt-5-6-sol-launches-under-government-controlled-access-it-calls-unsustainable/
Bài viết này đến từ tài khoản công chúng WeChat "Tân Trí Nguyên", tác giả: ASI Khải Thị Lục








