Hãy thử tưởng tượng một khung cảnh sau:
Một người cao tuổi sống một mình bị trượt ngã trong phòng khách, cơn đau khiến ông không thể kêu cứu. Ngay lúc đó, thiết bị thông minh trên người ông hoặc camera gia đình đã "nhìn thấy" sự bất thường. AI không chờ đợi bất kỳ lệnh thoại nào mà chủ động đưa ra cảnh báo, liên hệ nhanh chóng với người thân hoặc trung tâm cấp cứu.
Hoặc, bạn đang theo dõi một trận bóng đá căng thẳng, khoảnh khắc ghi bàn quyết định xảy ra quá nhanh, bạn không kịp tua lại và đặt câu hỏi, nhưng kính thông minh AI đã tự động cung cấp cho bạn phân tích chuyển động chậm và giải thích chiến thuật.
Những tình huống này không còn là ảo tưởng về tương lai nữa, mà chính là những bài toán thực tế mà mô hình tương tác ngôn ngữ hình ảnh nguồn mở toàn diện đầu tiên trên thế giới vừa được JD.com mở nguồn – JoyAI-VL-Interaction đang cố gắng giải quyết.

Hai năm qua, ranh giới khả năng của mô hình lớn không ngừng được mở rộng, nhưng phương thức tương tác chủ đạo vẫn nằm ở logic "người dùng hỏi, mô hình trả lời" kiểu "lượt-đánh-lượt". Nó hiệu quả, nhưng trong nhiều tình huống lại không hợp lý. Nhiều sự kiện quan trọng xảy ra quá nhanh, người dùng không kịp hỏi; nhiều cảnh tượng cũng không hề có lệnh thoại.
Năm nay, một nhận định đang trở thành sự đồng thuận trong ngành: AI đang chuyển từ "dự đoán Token tiếp theo", sang "dự đoán trạng thái vật lý tiếp theo". Điều này cũng có nghĩa là AI phải tiến hóa từ người xử lý thông tin thụ động, trở thành người tham gia chủ động.
Ngay tại thời điểm này, JD.com đã mở nguồn JoyAI-VL-Interaction. Đây là mô hình tương tác ngôn ngữ hình ảnh thời gian thực nguồn mở toàn diện đầu tiên trên thế giới, có khả năng tự đánh giá khi nào cần phản hồi, khi nào nên im lặng, khi nào nên chuyển nhiệm vụ phức tạp cho mô hình backend trong luồng video liên tục.
Điều JoyAI-VL-Interaction muốn chứng minh là: Một AI thực sự bước vào thế giới vật lý không nên chỉ chờ đợi bị hỏi; nó cần học cách nhìn thấy, chủ động phán đoán và cung cấp trợ giúp vào thời điểm thích hợp.
Đây cũng là tín hiệu lớn hơn mà JD.com AI đang phát ra: Từ năng lực mô hình đến các tình huống công nghiệp, cuộc cạnh tranh AI đang chuyển từ hỏi đáp trong màn hình, sang thế giới thực.
Tại sao lại là tương tác ngôn ngữ hình ảnh?
Trong thế giới vật lý thực tế, một lượng lớn thông tin quan trọng diễn ra vào những khoảnh khắc người dùng không kịp đặt câu hỏi. Cảm giác "không kịp" đôi khi là vấn đề trải nghiệm, nhưng nhiều lúc là vấn đề ranh giới khả năng do mô hình mẫu gây ra.
Ngành công nghiệp không phải không nhận thức được sự hạn chế này.
Đầu năm 2026, tương tác thời gian thực trở thành từ khóa nóng nhất trong lĩnh vực AI đa phương thức. Ngành công nghiệp đang tiến lên theo hai hướng chính: một là làm cho hội thoại lượt-đánh-lượt trở nên nhanh hơn, hai là làm cho cuộc gọi thoại trở nên tự nhiên hơn.
Hướng thứ nhất nhấn mạnh độ trễ thấp hoặc đầu vào/đầu ra tùy ý, nhưng cốt lõi vẫn là "nó chỉ trả lời khi bạn hỏi"; hướng thứ hai cho phép mô hình vừa nghe vừa nói, có thể bị ngắt lời bất cứ lúc nào, trải nghiệm gần với cuộc gọi thực hơn, nhưng trọng tâm vẫn nằm ở các tình huống thoại.
Vấn đề nằm ở chỗ, phần lớn sự thay đổi trong thế giới thực không phải lúc nào cũng biến thành một câu nói trước. Hỏa hoạn, ngã, xe cộ tiến đến gần, nội dung màn hình thay đổi, dây chuyền sản xuất bất thường, tất cả đều xuất hiện dưới dạng hình ảnh trước khi biến thành ngôn ngữ. Nếu AI chỉ có thể chờ người ta mở miệng, nó sẽ rất khó thực sự "có mặt".
Thực sự cùng đưa ra phán đoán giống JD.com là Thinking Machines Lab do Mira Murati thành lập. Vào ngày 11 tháng 5, công ty này đã đề xuất khái niệm interaction models (mô hình tương tác), và công bố một số bản xem trước nghiên cứu Demo, chỉ ra rằng mô hình phản hồi chủ động của mô hình tương tác có không gian tưởng tượng lớn hơn về sự hợp tác phối hợp Human-AI so với mô hình mẫu hỏi đáp truyền thống.
Việc hai nhóm hội tụ về cùng một hướng suy nghĩ vào gần như cùng một thời điểm, bản thân đã là một tín hiệu: Coi tính tương tác như một khả năng tự thân của mô hình để mở rộng quy mô, là hướng đi mà ngành công nghiệp không thể bỏ qua trong vài năm tới.
Điểm khác biệt nằm ở chỗ, JD.com đặt ngôn ngữ hình ảnh vào vị trí trọng tâm hơn, tách thoại ra thành I/O có thể cắm/rút, biến ngôn ngữ hình ảnh thành "phương thức lái chủ động hạng nhất" cho quyết định tự chủ của mô hình.
Nói cách khác, từ thời điểm camera bật lên, JoyAI-VL-Interaction sẽ liên tục "xem" sự thay đổi hình ảnh của thế giới vật lý, và tự đánh giá liệu có nên mở miệng, nên nói gì, có nên chuyển nhiệm vụ đi hay không.
Đây cũng là trí tưởng tượng của tương tác hình ảnh: Nó có thể được sử dụng cho các tình huống như chăm sóc người già và trẻ em, hỗ trợ người khiếm thị, kính thông minh AI, bình luận thể thao, kiểm tra cửa hàng, hậu cần kho vận, phối hợp robot, v.v. Người dùng không cần phải tổ chức vấn đề thành một câu nói trước, AI có thể nắm bắt nhu cầu từ sự thay đổi môi trường.
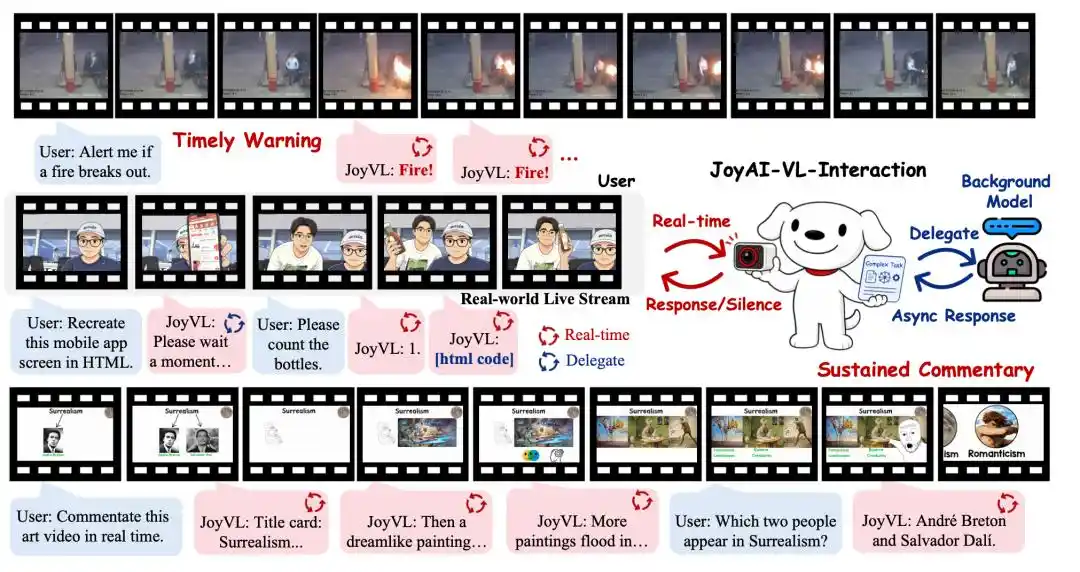
Vì vậy, hình ảnh không chỉ là một phương thức đầu vào khác, mà còn là kênh cảm nhận không thể thay thế cho việc AI tiến tới "dự đoán trạng thái vật lý tiếp theo".
Trong báo cáo kỹ thuật của JoyAI-VL-Interaction do JD.com công bố cũng nhấn mạnh điểm này. Báo cáo cho thấy, trong sáu tình huống streaming thực tế, JoyAI-VL-Interaction đạt tỷ lệ thắng 77,6% so với các mô hình hàng đầu trong nước, và tỷ lệ thắng 87,9% so với mô hình nước ngoài; trong tình huống cảnh báo giám sát thử thách khả năng nắm bắt sự kiện nhất, tỷ lệ thắng đạt 100%. Báo cáo cho rằng, sự khác biệt không chỉ nằm ở chất lượng trả lời, mà còn ở việc có thể hành động đúng thời điểm hay không.
Tuy nhiên, hoàn thành tương tác chủ động bằng hình ảnh quả thực khó hơn.
Việc thu thập dữ liệu tương tác thoại tương đối trực tiếp, các tập dữ liệu lệnh thoại lớn cho phép mô hình học cách con người nói chuyện khi nào, ngắt lời ra sao, tiếp lời thế nào; dữ liệu cần cho tương tác hình ảnh lại hoàn toàn khác. Mô hình cần học là, trong dòng hình ảnh liên tục thay đổi, tín hiệu nào đáng để phản hồi, tín hiệu nào nên im lặng.
Rào cản sâu hơn là khả năng định nghĩa tình huống. Trong tình huống, tương tác thoại có một ranh giới kích hoạt tự nhiên, người dùng mở miệng nói chuyện là sự bắt đầu tương tác. Tương tác hình ảnh thì không có điểm bắt đầu và kết thúc rõ ràng, mô hình phải tự mình phán đoán ranh giới trong dòng thông tin vô biên.
Điểm độc đáo của JD.com cũng nằm ở đây: Công ty này không tìm kiếm tình huống từ phòng thí nghiệm trừu tượng, mà vận hành một cách tự nhiên trong mạng lưới kinh doanh thực tế như bán lẻ, hậu cần, y tế, công nghiệp.
Điều này có nghĩa là, AI của JD.com đối mặt không phải với một cổng chat duy nhất, mà là hàng loạt nhiệm vụ thực tế: Hàng hóa lưu chuyển thế nào, thiết bị phối hợp ra sao, robot phối hợp với con người thế nào, bất thường được phát hiện sớm ra sao. Mô hình có thể học trong nhu cầu thực tế, lặp lại trong phản hồi thực tế.
Mặc dù con đường kỹ thuật có sự đánh đổi, nhưng hình thái tương tác của AGI phổ dụng trong tương lai nhất định là trí tuệ chủ động, tác nhân thông minh phải có vòng tuần hoàn hoàn chỉnh về cảm nhận môi trường, quyết định tự chủ và phản hồi thời gian thực. Vì vậy, không ít công ty không phải không muốn làm mô hình lớn tương tác hình ảnh, mà là hiện tại vẫn thiếu mảnh đất để tương tác hình ảnh nảy mầm. Đây cũng là lý do vốn và năng lực tính toán đổ vào đường đua tương tác thoại trước.
Vì vậy, việc JD.com chọn hướng tiếp cận từ hình ảnh không chỉ là lựa chọn con đường kỹ thuật, mà còn do vị trí chiến lược quyết định. So với nhiều người chơi mô hình lớn, JD.com gần với hiện trường vận hành thế giới vật lý hơn, và cũng cần một AI có thể chủ động cảm nhận và phản hồi thời gian thực hơn.
Muốn ngày đó đến nhanh hơn, cần có người khởi hành sớm hơn.
Nhẹ, Mã nguồn mở, Có thể triển khai
Mã nguồn mở toàn diện đầu tiên trên toàn cầu có nghĩa là gì?
Định nghĩa lại mô hình mẫu tương tác nghe có vẻ vĩ đại, nhưng khi áp dụng vào ứng dụng thực tế, rào cản đầu tiên lại rất đơn giản: AI không thể lúc nào cũng làm phiền người ta, cũng không thể im lặng khi cần nhắc nhở.
Mọi người thường kỳ vọng AI càng nói được càng tốt, nhưng trong các tình huống tương tác hình ảnh thời gian thực, một mô hình liên tục chen ngang không phải là thông minh. Khả năng thực sự có giá trị, là chủ động xuất hiện vào thời điểm then chốt, và giữ im lặng vào những lúc không liên quan.
Vì vậy, JoyAI-VL-Interaction huấn luyện "im lặng" cũng trở thành một khả năng. Mô hình cần nắm vững ba tầng phán đoán: Tình huống nào nên chủ động phản hồi, tình huống nào nên giữ im lặng, tình huống nào nên phân phát nhiệm vụ, giao cho mô hình khác.
Bộ khả năng này nếu chỉ có thể dừng lại trong bài báo, giá trị rất hạn chế. JD.com lần này nhấn mạnh "mã nguồn mở toàn diện", chìa khóa nằm ở việc mở đồng thời mô hình, hệ thống suy luận và con đường xây dựng ứng dụng, để nhà phát triển thực sự có thể chạy, sửa, dùng.
JD.com lựa chọn con đường kỹ thuật dễ lan tỏa hơn: Mô hình 8B tham số, chỉ cần một card đồ họa 3090 là có thể hoàn thành triển khai. Với tham số này, nhà phát triển cá nhân có thể chạy, phần cứng cấp tiêu dùng có thể chịu tải, thiết bị đầu cuối có thể triển khai.
Đối với tương tác hình ảnh thời gian thực, sự nhẹ hóa này không có nghĩa là khả năng bị thu hẹp, mà là phân công lao động rõ ràng hơn.
JoyAI-VL-Interaction giống như một tầng tương tác tiền trạm hơn, chịu trách nhiệm nhìn thấy môi trường, phán đoán thời cơ, hoàn thành giao tiếp ngắn gọn; gặp nhiệm vụ phức tạp cần suy luận sâu, sẽ tự động phân phát cho các Agent backend do người dùng tự chọn như OpenClaw, Codex, Claude Code, vì vậy mô hình 8B là đủ.
Ví dụ, mô hình có thể nói với người dùng trước "Để tôi nghĩ một chút", sau đó giao nhiệm vụ khó cho backend, bản thân tiếp tục duy trì hiện diện; khi backend trả về kết quả, đồng bộ hóa đáp án cho người dùng. Trong quá trình này, nó còn có thể tiếp tục giúp người dùng hoàn thành các tương tác tức thời khác.
JD.com cũng thiết kế nhẹ hóa ở hệ thống nền tảng: Thông qua mã hóa video, bộ nhớ dài hạn và nén ngữ cảnh, mô hình có thể liên tục xem luồng video dài với chi phí thấp hơn, và kiểm soát độ trễ end-to-end ở cấp độ dưới giây. Đối với độc giả phổ thông, trọng tâm không phải là những thuật ngữ kỹ thuật này, mà là kết quả: AI có thể ở lại các tình huống thực tế lâu hơn, với ngưỡng thấp hơn.
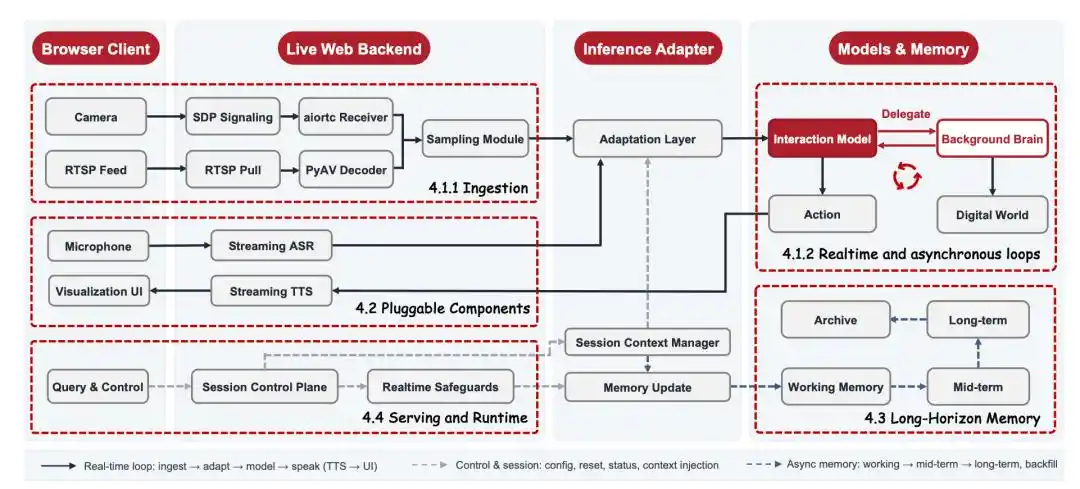
Sự lựa chọn hiệu quả chi phí cao, có thể triển khai cũng trực tiếp dẫn đến chiến lược mã nguồn mở của JD.com. Chỉ khi mô hình đủ nhẹ, hệ thống đủ hoàn chỉnh, ngưỡng triển khai đủ thấp, tương tác hình ảnh thời gian thực mới có thể từ thí nghiệm của một số ít nhóm, trở thành hệ sinh thái ứng dụng được nhiều nhà phát triển và doanh nghiệp cùng khám phá.
JD.com đã mở nguồn hệ thống suy luận này, mục tiêu rất rõ ràng: Để bất cứ ai sở hữu card đồ họa 3090 trở lên và camera, đều có thể nhanh chóng xây dựng một ứng dụng tương tác hình ảnh thời gian thực của riêng mình.
JoyAI-VL-Interaction đã nhận được hỗ trợ day-0 từ vLLM-Omni, và đã được hợp nhất nguyên bản vào nhánh chính vLLM-Omni.
Đưa AI trở về thế giới vật lý
Mục đích của mã nguồn mở là giao trí tưởng tượng ứng dụng cho thị trường lớn hơn. Bởi vì giá trị của đột phá kỹ thuật cuối cùng vẫn phải được thế giới thực nghiệm chứng.
Những tưởng tượng ứng dụng đầu tiên của JoyAI-VL-Interaction đã rất trực quan: Trong phát sóng trực tiếp trận đấu, AI có thể tự động bình luận vào khoảnh khắc ghi bàn then chốt hoặc quyết định; khi theo dõi thị trường chứng khoán, nó có thể liên tục quan sát sự thay đổi màn hình và nhắc nhở bất thường; trong chăm sóc gia đình, nó có thể chủ động cảnh báo khi người già ngã, trẻ em đến gần khu vực nguy hiểm; kết hợp với kính thông minh AI, nó có thể giúp người dùng nhận diện đường đi, hàng hóa, màn hình và môi trường xung quanh; khi phục vụ người khiếm thị, nó có thể chuyển đổi thông tin hình ảnh thành hỗ trợ thời gian thực.
Đối với JD.com, điều được mong đợi hơn là nó có thể được áp dụng vào robot: Một mô hình biết khi nào nên mở miệng, khi nào nên im lặng, khi nào nên nhờ đến hệ thống backend, có thể khiến robot hiệu quả hơn, và cũng gần hơn với người trợ lý thông minh "có chừng mực" mà mọi người mong đợi.
Lý do cơ bản khiến JD.com dám "khuấy động" lĩnh vực này tại thời điểm này, là vì nó nắm giữ tài sản dữ liệu thế giới vật lý mà những người chơi mô hình lớn khác không có.
Đặt trong tọa độ ngành công nghiệp năm 2026, sức nặng của tài sản dữ liệu thế giới vật lý đặc biệt quan trọng.
Năm 2026 được giới công nghiệp gọi là "năm nguyên thủy dữ liệu trí tuệ thể hiện", và trong bối cảnh vĩ đại đó, một mâu thuẫn sắc bén là: Dữ liệu tương tác vật lý chất lượng cao cực kỳ khan hiếm, không thể đáp ứng nhu cầu đào tạo quy mô lớn, điểm nghẽn lặp lại thuật toán đang chuyển dịch toàn diện từ phía mô hình sang phía dữ liệu.
Vào thời điểm này, JD.com tuyên bố sẽ tích lũy 10 triệu giờ dữ liệu video tình huống thực chất lượng cao trong vòng hai năm, huy động 600.000 người tham gia thu thập.
JD.com có hơn 3000 tình huống kinh doanh thực tế, bao phủ các lĩnh vực như bán lẻ, hậu cần, y tế, công nghiệp, năm nay còn sáng tạo ra mô hình thu thập theo lưới cộng đồng tại Túc Thiên, triển khai hàng loạt thiết bị đầu cuối JoyEgoCam tự nghiên cứu đeo đầu, huy động các doanh nghiệp vừa và nhỏ xung quanh và cư dân thu thập trong các tình huống làm việc thực tế.
Tốc độ bố trí rất nhanh. Tháng 3, JD.com tuyên bố xây dựng trung tâm thu thập dữ liệu trí tuệ thể hiện đầu tiên trên thế giới tại Túc Thiên; tháng 4, phát hành cơ sở hạ tầng dữ liệu thể hiện đầu tiên trong ngành bao phủ toàn bộ chuỗi thu, lưu, gán nhãn, huấn luyện, đánh giá, mô phỏng, kiểm tra; tháng 5, JoyEgoCam đạt sản xuất hàng loạt, tiếp tục thu thập dữ liệu góc nhìn thứ nhất.
Những dữ liệu này là nhiên liệu khan hiếm nhất để huấn luyện mô hình thể hiện và mô hình tương tác hình ảnh. Khi dữ liệu thể hiện tham gia vào huấn luyện, giá trị của JoyAI-VL-Interaction cũng sẽ từ "một mô hình có thể chủ động nhìn thấy", tiến thêm một bước áp dụng vào các không gian vật lý cụ thể hơn như robot, xe không người lái, kho vận, cửa hàng và gia đình.
Giữa mô hình và ứng dụng, JoyAI-Echo do JD.com mở nguồn vào ngày 3 tháng 6 cũng đóng vai trò then chốt. Echo giỏi về tạo sinh thời gian thực video dài, Interaction giỏi về hiểu và tương tác thời gian thực. Liên tiếp mở nguồn hai mô hình trong vòng một tháng, có nghĩa là JD.com đã thông suốt hai đầu nhập và xuất của đa phương thức video, và đặt việc AI tiến vào thế giới vật lý ở vị trí lâu dài hơn.
Tại hội nghị khởi động 618 năm nay, JD.com nói muốn trở thành "trung tâm vận hành thế giới vật lý lớn nhất toàn cầu".
Trong thời đại tương tác người-máy, ngành công nghiệp ngày càng quan tâm đến việc AI hiểu thế giới vật lý thế nào, nhưng logic giải bài của JD.com lại khác với hầu hết người chơi mô hình lớn: Công ty này vốn dĩ đang vận hành trong thế giới vật lý.
Kho vận, phân phối, bán lẻ, y tế, công nghiệp, đều là bãi tập và bãi thử cho AI và trí tuệ thể hiện. Chỉ riêng JD Logistics, trong vòng năm năm tới đã lên kế hoạch đầu tư 3 triệu robot, 1 triệu xe không người lái, 100.000 máy bay không người lái, những phần cứng này cũng sẽ trở thành nơi phát huy tác dụng của JoyAI-VL-Interaction.
Cho dù là thoại hay hình ảnh, bản chất của mô hình tương tác là để kết nối thế giới vật lý và thế giới số, hiểu thế giới vật lý, điều phối thế giới số.
Mã nguồn mở, là cánh cửa đầu tiên JD.com mở ra bên ngoài. Trên đường đua này mà nhu cầu thúc đẩy kỹ thuật, JD.com đưa mô hình, dữ liệu huấn luyện và hệ thống hoàn chỉnh cùng lúc ra ngoài, đặt cược vào một việc dài hạn hơn: Biến tương tác chủ động từ phán đoán của một số ít nhóm, thành một luồng chính cho AI tiến vào thế giới vật lý.
Chào mừng trải nghiệm dịch vụ kéo lên một click trên vLLM-Omni, cũng có thể khởi động một click trong kho:
Địa chỉ mã: https://github.com/jd-opensource/JoyAI-VL-Interaction
Địa chỉ mô hình: https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
Địa chỉ tập dữ liệu: https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
Địa chỉ báo cáo kỹ thuật: https://huggingface.co/papers/2606.14777






