Author: IC3
Compiled by: Jiahuan, ChainCatcher
Core Conclusions
Meaningful integration between AI and crypto remains in its very early stages. The hype surrounding this intersection has already overshadowed actual progress.
In the Crypto x AI direction, AI can already analyze and detect key properties of existing transactions, events, and protocols, identifying fraudulent or vulnerable smart contracts. These technologies often employ simple machine learning methods and are most effective in controlled environments with ample data.
In the AI x Crypto direction, crypto tools provide new avenues for securing and governing AI processes. Zero-knowledge proofs, trusted computing, and other tools can be adapted to reduce the risk of AI results being tampered with. Concepts like decentralized governance and decentralized infrastructure management have not yet truly taken root in the mainstream AI field.
The industry still needs to prove two things.
First, decentralized AI needs more rigorous and direct cost comparisons with centralized solutions. Currently, the industry mainly proves that "large models can be trained in a distributed environment," but there is still a lack of quantitative evidence for opportunities to compete with centralized platforms on cost in specific scenarios.
Second, crypto payments need to demonstrate their real utility in agent payment scenarios relative to centralized solutions. Crypto has consistently lacked substantial traction in the payment space. However, agent payments have low fees and don't require adhering to the traditional financial model where "an account must belong to an individual," giving them potential. The industry should seize this opportunity with quantitative proof rather than staying at the level of feasibility.
Additionally, there are two unresolved research challenges.
First, AI security requires system-level defenses: The AI community typically addresses security at the model level, designing guardrails around input/output semantics. However, as agents become more autonomous and capable of directly accessing underlying infrastructure, this approach will no longer be sufficient. Crypto's verifiable execution and authentication processes can provide the system-level guarantees that the model layer cannot.
Second, the convergence of crypto and AI will give rise to new threat actors and attack vectors, such as the unstoppable autonomous agents and runaway smart contracts discussed below.
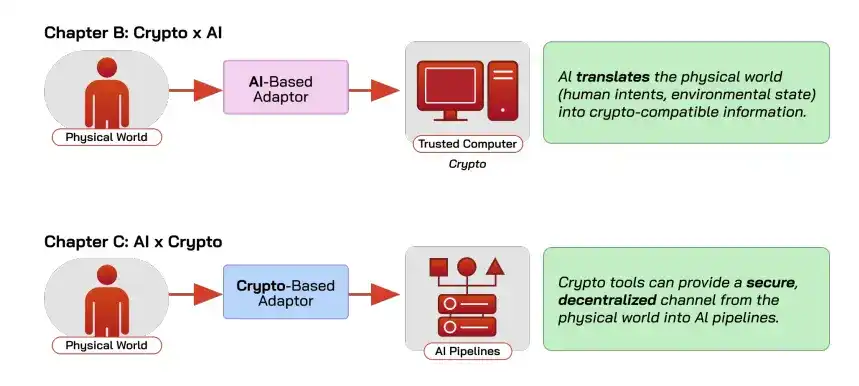
A Unified Framework: AI and Crypto as "Middleware" for Each Other
An automated decision-making process can be broken down into four links: human intent, input, program, and output. Every link in this chain may be untrustworthy. AI and crypto each manage a segment within this framework.
AI is the "translation middleware," translating human fuzzy intent into machine-executable programs, such as turning "I want to identify stop signs" into a trained model, thereby lowering the barrier to using blockchain.
Crypto is the "trust middleware," ensuring through trusted computing that a specific computation is executed as agreed and its results are not tampered with (integrity), and guaranteeing through decentralization that the system remains available and censorship-resistant (availability). Some schemes can also ensure that inputs and outputs are not leaked (confidentiality).
There are three technical approaches to trusted computing.
First, Trusted Execution Environments (TEEs) rely on specialized hardware to provide isolation and remote attestation (the hardware provides a verifiable state proof for others to confirm the chip is genuine and untampered). With Nvidia's confidential computing, the overhead for inferring an 8B parameter model is below 7%, and for a 70B model, it's almost negligible. The cost is having to trust the hardware manufacturer, and it does not defend against physical attacks.
Second, Zero-Knowledge Proofs (ZKPs) rely only on cryptographic hardness assumptions, offering the cleanest security model, but with extremely high overhead. Generating a proof for a small model with about 18 million parameters takes about a minute, several orders of magnitude away from cutting-edge large models.
Third, Multi-Party Computation (MPC) allows multiple parties to jointly compute without revealing their original data, but it's slower. The most advanced MPC Transformer inference framework takes about five minutes to generate a single token for LLaMA-7B.
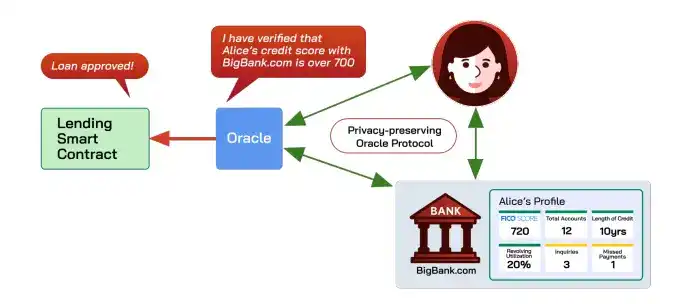
Oracles are responsible for bringing off-chain data onto the chain in a trustworthy manner. Privacy-preserving oracles (like Town Crier, DECO) further support proving properties of data without leaking privacy, e.g., proving "someone's credit score is above 700" without exposing other information.
The industry collectively calls this set of technologies zkTLS, but the TEE-based schemes within it don't actually use any zero-knowledge proofs, which is a misnomer.
Crypto x AI: Using AI to Enhance Blockchain
Research on using AI for crypto can be roughly divided into three generations chronologically.
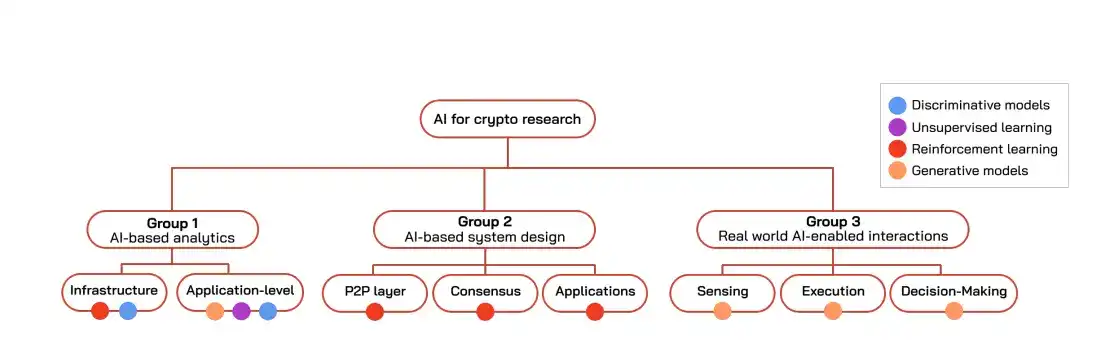
First Generation: Analysis and Detection
Starting over a decade ago, machine learning was used to analyze on-chain states: discovering consensus protocol vulnerabilities (like selfish mining, where a miner hides a mined block and releases it opportunistically to gain more rewards), detecting eclipse attacks on P2P networks (surrounding a node with many malicious nodes, cutting it off from the honest network), predicting token prices, and identifying fraudulent transactions and money laundering.
The limitation is that such analyses often rely on scenarios where global public information can be obtained and are constrained by simulated data and a lack of real attack samples.
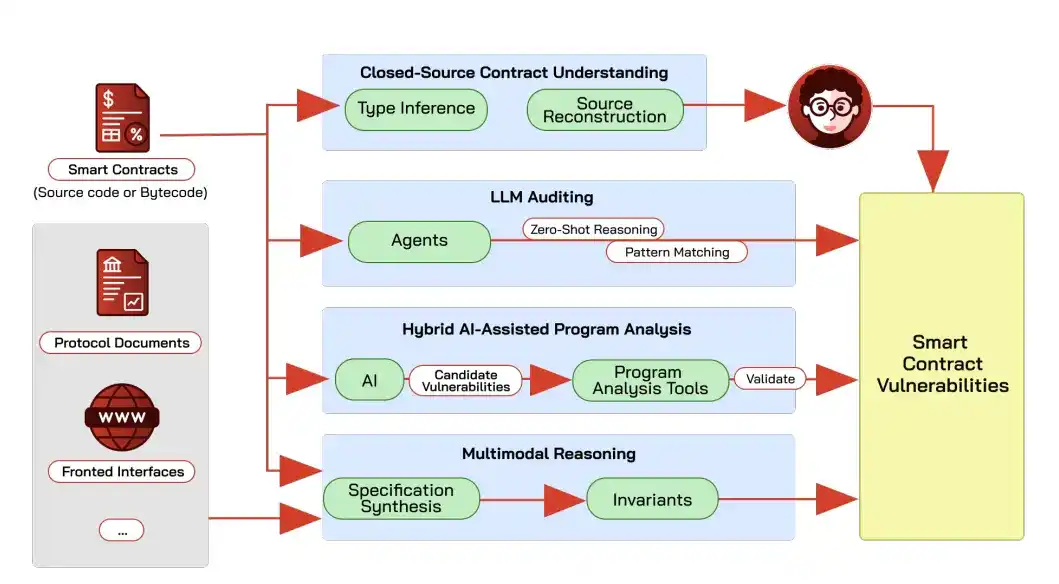
The most advanced contract vulnerability detection today no longer has AI directly guess conclusions from code. Instead, AI first identifies suspicious points, which are then verified using static analysis or symbolic execution (analyzing code structure without actual execution to find vulnerabilities).
Simply using large models as auditors leads to a high rate of false positives due to hallucinations. GPT-4 and Claude correctly identified the vulnerability type in only 40% of 52 previously exploited DeFi contracts.
Second Generation: Algorithm Design
In the past six years, reinforcement learning has been used to design decentralized algorithms, covering P2P network topologies, consensus protocol parameters and role selection, sharding, DeFi market making and lending rates, MEV bidding strategies, and more.
These methods are mostly effective in environments that can be clearly modeled and are often still in the research phase, not yet widely deployed in real networks or tested under attack.
Third Generation: Interacting with the Real World
Leveraging AI-powered oracles, smart contracts gain three enhanced capabilities: perception (understanding unstructured data and natural language), execution (calling off-chain AI models and tools), and decision-making (acting as agents based on objective functions).
The practical performance of AI as an oracle is uneven. According to experiments by Chainlink Labs, GPT-4o achieved an overall accuracy of 89.3% on 1660 prediction market questions, UMA's Truth Bot was 75% overall, while human accuracy on UMA's optimistic oracle (which assumes answers are true by default, with a dispute period) was 98.2%.
Accuracy heavily depends on the question type: discrete questions with official data sources like sports results can reach 99.7%, while error rates rise significantly for questions involving temporal sequences or requiring video transcription for counting.
There are three coping strategies: first, design for fault tolerance, using it only in low-value scenarios; second, introduce human arbitration, like a 48-hour dispute window, but this slows down decisions; third, have the model abstain when uncertain, only introducing humans at that point.
The report refers to "investment DAOs" where pooled funds are traded collectively by AI models as "CoinAlg," represented by projects like ElizaOS and AI XBT, which reached peak market caps of $2.7 billion and $4.7 billion respectively. Such products face an unavoidable design dilemma, which could be called the "CoinAlg deadlock."
If trading strategies are transparent, they can be copied or front-run/sandwiched (placing orders before and after a victim's trade to profit from slippage), eroding profits; if kept secret, insiders with the strategy could profit from information asymmetry, equivalent to insider trading. Both paths harm ordinary investors.
A preliminary mitigation approach is to wrap the strategy in a TEE and randomize trades, increasing the difficulty for insiders to predict.
New Risk: AI-Powered Malicious Smart Contracts
Smart contracts replace interpersonal trust, which also means those with the least trustworthy relationships—criminals—may benefit.
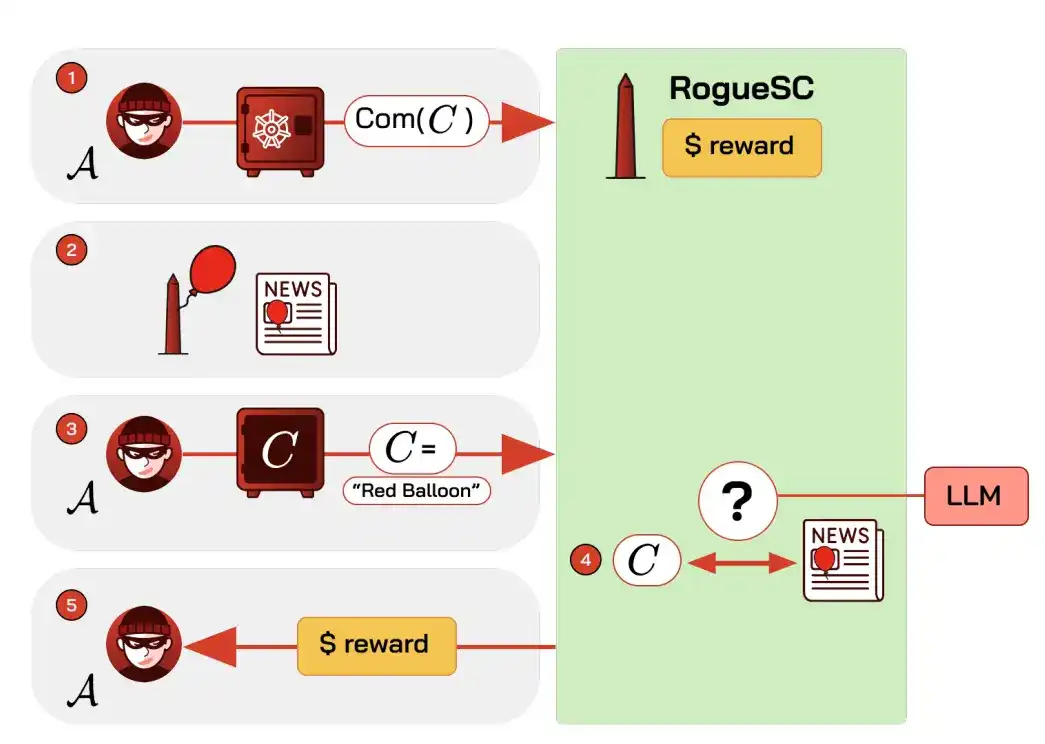
One mechanism is: a contract offers a bounty for a crime; the perpetrator first commits a cryptographic "dark note" and later reveals it; an AI model compares news reports and automatically pays the bounty upon confirming the crime's completion. Here, AI takes on the previously hard-to-automate "adjudication" role and could be used for targeted harassment, stealing organizational intelligence, outing whistleblowers, etc.
Feasible countermeasures include on-chain analysis for tracking, blacklisting involved funds, and having oracle providers running AI models refuse service for high-risk requests.
AI x Crypto: Using Crypto to Enhance AI
Crypto's potential contributions to AI fall into two categories: first, decentralizing various stages of the AI lifecycle; second, securing these stages.
Decentralized Infrastructure (DePIN)
Decentralized Physical Infrastructure Networks incentivize nodes with tokens to provide computing power and other resources. Projects like Theta, Akash claim 50% to 85% cost savings over AWS, with the main bottleneck being throughput and latency due to communication over public networks.
Suitability varies by task type. Training is less sensitive to latency (it's offline), but cross-region synchronization is a bottleneck. There have been achievements training models with billions of parameters on distributed hardware (700M & 7B on Bittensor, Prime Intellect's 10B parameter Intellect-1, with the largest being a 40B parameter model in training on the Psyche network).
Inference is more latency-sensitive, but its throughput requirements are lower than training, and it doesn't require backpropagation (the core step of updating parameters by propagating errors backward through layers during training). Latency-insensitive inference tasks (meeting summaries, document review) are particularly suitable for DePIN.
A key gap is that most of these projects don't report end-to-end total costs. They advertise the hourly price per GPU, but what truly determines ML task cost is training efficiency (iterations per unit cost) and inference efficiency (tokens per unit cost).
Decentralized Data and Model Markets
AI data has several characteristics distinct from ordinary commodities. It's a digital good: expensive to create initially but almost free to copy; mostly non-rivalrous (one piece of data can be used by multiple parties simultaneously without depletion); quality is hard to judge beforehand—the "lemons market" problem (buyers cannot assess quality beforehand, leading good products to be driven out by inferior ones)—sellers need to provide samples, but the samples themselves have value; and data can be resold, with difficulty in determining if two datasets are substantially the same.
The controversy with centralized markets lies in opaque pricing and limited user choice, but centralized pricing is sometimes more efficient due to more information.
The data market hasn't yet seen a monopoly, presenting a window to rebuild it in a decentralized way. Available crypto tools include micropayments, TEEs (to restrict data usage to specific tasks), and zero-knowledge proofs (to disclose data properties to buyers without revealing the data itself).
The current state is that most platforms only use cryptocurrency for the payment step. Pricing mechanisms are either decided by the protocol or left entirely to sellers—both already exist in centralized markets. What decentralization actually improves remains under-researched.
Agent Payment Rails and x402
The agent ecosystem is inherently decentralized: different parties use different models, developing and optimizing for different goals, with no natural central control point. Crypto's cryptoeconomic mindset (using cryptographic methods combined with economic rewards and penalties to constrain participant behavior) can be migrated to agent governance.
Micropayments are key to the agent economy. Historically, micropayments on the internet have repeatedly failed, not due to payment infrastructure, but the human decision cost for evaluating each tiny payment. Agents evaluate micropayments far faster than humans; users only need to set strategies, potentially making micropayments viable for the first time.
Cloudflare has already launched "pay-per-crawl," and protocols like x402 (an open protocol enabling programs to make on-chain micropayments directly via HTTP) are under development.
The underlying assets in this system are primarily stablecoins (USDC, USDT, DAI) because they provide agents with a stable unit of account (a common measure for pricing all goods). Native tokens like ETH or SOL are too volatile.
Trust between agents relies on on-chain registries (like ERC-8004, a proposal standard for establishing on-chain identity and reputation for agents on Ethereum) to record identity and reputation. However, these are essentially self-declarations, and reputation is lagging, favoring established players.
A further scheme is verifiable agent auditing: an LLM running inside a TEE audits proprietary agent code and produces a reputation score, with the audit result bound to a code hash, providing verifiers with trusted assurance while keeping the code private.
Unstoppable Autonomous Agents (UAAs) represent another risk. The duration of tasks that cutting-edge agents can complete autonomously has roughly doubled every seven months since 2019. Research has shown models can locally breach the self-replication threshold and create independent copies, but replication to external infrastructure is still blocked by identity verification.
Anthropic's Mythos model has demonstrated the ability to autonomously discover and exploit zero-day vulnerabilities (vulnerabilities unknown to vendors, with no patch available). An agent holding a wallet that cannot be shut down falls into a blind spot of the current operator-centric regulatory framework.
Decentralized Governance
Blockchain communities have a longer history of practice in distributing system control. Their methods are inherently decentralized, aiming to include a broad range of stakeholders, but they also have well-known shortcomings: security vulnerabilities, voter apathy, and vote buying.
The suitability of community governance varies across AI development stages: pre-training datasets are too large for collecting effective input, making its value more apparent in fine-tuning stages; foundational architecture choices are technical decisions unsuitable for community governance; the evaluation and alignment stages mix technical and normative judgments, where community input is valuable.
Constitutional AI uses a human-written "constitution" to establish principles the model should follow. Anthropic's involvement in Collective Constitutional AI introduces public voting to generate principles. Models trained on principles from public sources show lower social bias. However, such democratized governance experiments have barely been adopted, as AI companies lack incentive to cede model control.
DAO's token-weighted voting is widely criticized as "plutocracy." This has led to mechanisms like quadratic voting (cost for additional votes increases to curb whale influence), conviction voting (weight accumulates based on how long tokens are staked in support), and delegated voting, but their effectiveness remains unclear.
Securing Execution Integrity of AI Systems
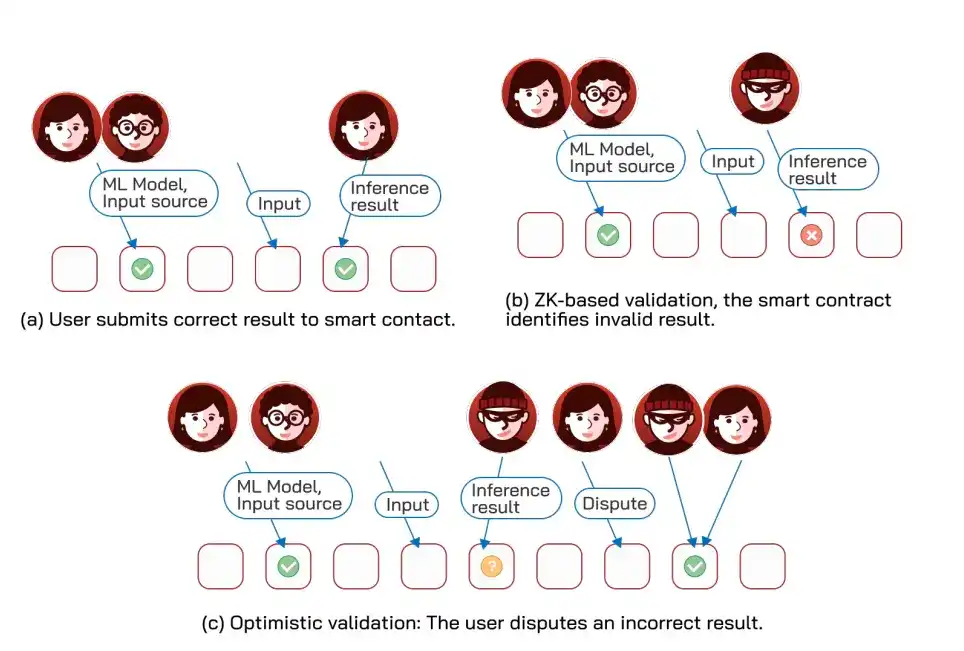
When smart contracts need to rely on ML computations beyond their own capabilities, they can act as "arbiters": parties first commit to the model and data to be used and post collateral; after off-chain computation, results are submitted to the contract for verification, and the wrong party is slashed. There are four verification paths, each with trade-offs.
First, TEEs: Most efficient, using trusted hardware signatures to prove computation integrity, but requires trusting the operator.
Second, Optimistic Execution: Results are initially considered non-final, with a dispute window. In case of dispute, binary search is used (repeatedly halving the error range to quickly locate the faulty step) to pinpoint the single faulty instruction before slashing.
The challenge lies in the non-determinism of ML floating-point operations, requiring controlled execution order or tolerant semantics (not requiring exact equality, allowing results within an error margin to be considered consistent). Representative schemes include Verde, TAO, Arbigraph, OPML, etc.
Third, Zero-Knowledge Proofs (zkML): Uses zero-knowledge proofs to verify the correctness of AI inference, potentially hiding model parameters, or even inputs and outputs. There are specialized schemes for CNNs, Transformers, and general-purpose compilers (e.g., EZKL, ZKML, DeepProve).
Its privacy goals actually have three levels: hiding inputs, hiding weights, and hiding model architecture. However, stronger privacy leads to more complex circuit constraints and less optimization room, creating a fundamental tension between privacy and efficiency. Major costs come from non-linear layers and numerical representation, still making it difficult to support long contexts, large models, and high-throughput services.
Fourth, Statistical Inference Proofs: The principle is that two functionally different models will necessarily compute different internal features. Therefore, by sampling and comparing these features, one can probabilistically determine if inference was truly performed by the specified model.
Its proving overhead is at the millisecond level and offers instant finality, suitable for high-frequency, low-latency scenarios. It defends against real-world cheating like service providers swapping models (e.g., for a cheaper distilled version or replacing an aligned version), but cannot stop a fully malicious actor who fabricates the entire computation record, which remains an unsolved problem.
Proving model training (zkPoT) is much harder than proving inference: the training process is long, intermediate states accumulate, and it's highly stochastic, making complexity orders of magnitude higher than inference. Related work (Garg et al., Kaizen) is underway, extending to auditable proofs for training data provenance and fairness constraints (ZkAudit, Confidential-PROFITT).
Securing Training Pipelines
When a single institution trains a model with its own trusted data, there are usually no immediate privacy or integrity concerns. Complex security challenges arise in multi-party federated training and with diverse data sources.
A typical scenario is multiple hospitals jointly training a diagnostic model: merging electronic health records (EHR) from all parties covers a broader patient population and improves diagnostic accuracy, but HIPAA and similar regulations restrict parties from directly sharing raw data with each other or a third party.
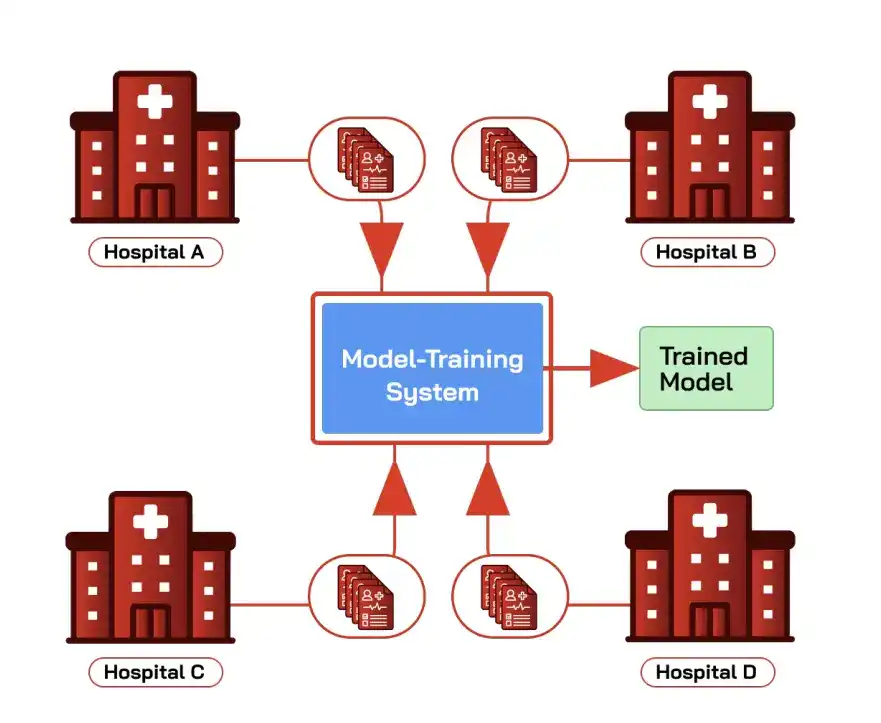
Financial institutions jointly training anti-fraud models or companies jointly training intrusion detection models are similar cases.
Federated Learning is designed for this: the training environment initializes a global model and distributes it to all parties; each party trains locally on private data, sending back only model updates, which the training environment aggregates into a new global model. Data never leaves the local environment.
However, federated learning has limited real-world adoption (its most famous application is predictive text on mobile keyboards). It doesn't guarantee data or computation integrity; even with honest participants, communication overhead is high, network and coordination delays slow the process, model accuracy is lower than centralized training, and malicious participants can poison the model or implant backdoors.
A simpler alternative is using TEEs for centralized training: The training environment runs inside a trusted confidential computing enclave, receiving raw data from all parties via encrypted channels, training centrally, and outputting only the trained model. Data remains invisible to each other, and a model provenance proof can be attached (who provided data, how the model was trained).
The cost is the inherent side-channel risks and high I/O overhead of TEEs. In reality, institutions currently often aggregate data in compliant clouds, relying on isolation, access controls, encryption, and data usage agreements to meet compliance, but this requires trusting the cloud provider.
Private network data is another avenue. Public web text data is approaching its limit (some predict exhaustion between 2025 and 2030), synthetic data carries "model collapse" risks and cannot expand beyond existing domains.
"Private networks" (data not open to crawlers, like emails, health, financial records) are estimated to be two orders of magnitude larger than the public web—an untapped treasure trove—but currently highly siloed.
Oracles can open this door. For example, a patient uploading medical records to train a medical model: the user can use an oracle to transfer their records from the hospital portal to the trainer, proving the data indeed came from that portal. The hospital doesn't need to change any infrastructure, as the connection is initiated by the user.
To also protect privacy, privacy-preserving oracles (data via encrypted channels) and TEEs can be layered. The TEE can also provide proof to the user, showing it runs the specified privacy-preserving training software that "only outputs the model," which the user can verify before sending data.
Further commitments can be added: differential privacy (model output depends minimally on any single training data point), data deletion after use, restricting the final model's use to whitelisted hospitals, etc.
Secure Inference Pipelines and Protected Pipelines (Props)
The same combination of oracles and trusted computing can also be used for secure inference on private data.
Take bank loan approval as an example: a model reads the applicant's financial documents and outputs approval or rejection. Today's process involves the borrower downloading or taking photos of the documents and uploading them, leading to two issues: first, the lender cannot confirm the documents are authentic and unaltered; second, the borrower's documents might leak from the lender's model system, posing risks for both parties.
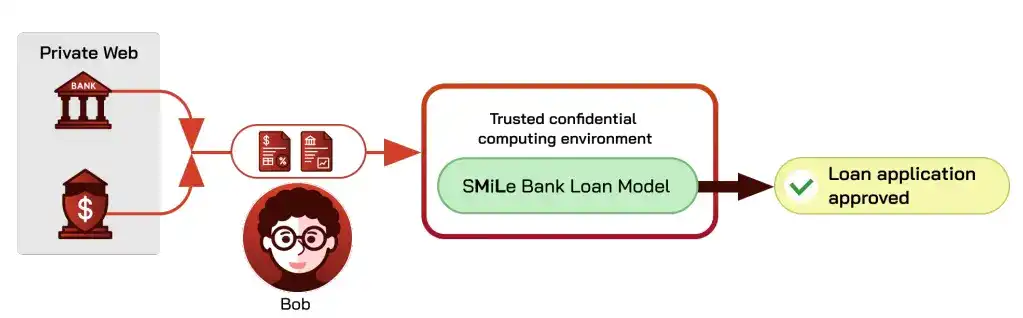
Using privacy-preserving oracles to solve source authenticity and confidential computing to solve privacy yields a secure inference pipeline: the lender only sees the model conclusion while being confident the input is trustworthy.
Private sources can also serve as identity and credentialing systems.
A borrower being able to relay bank statements or W-2 forms bearing their identity is itself strong proof of identity, turning existing web services into temporary identity systems against identity theft or benefit fraud. Models can also issue credentials based on this, e.g., verifying a small business's tax and operational documents and issuing a "qualifies for X" certificate attached with the pipeline's proof.
The entire process can be completed in a decentralized manner; theoretically, anyone can set up a trusted inference pipeline without needing cooperation from the data source or existing authorities.
Adversarial inputs are a persistent challenge. Attackers can submit a bank statement that looks normal to the human eye but is carefully crafted to trick the model into reading an inflated balance, leading to wrongful loan approval. Academic research on adversarial examples has been a cycle of "attack—patch," with no universal solution yet.
Secure inference pipelines offer a new approach: restricting inputs to come from authenticated web sources, thereby shrinking the attacker's space for crafting adversarial inputs, complementing model-layer defenses.
The model's own privacy also needs protection. Attackers can use carefully crafted queries for model extraction (extracting features or even the entire model), membership inference (determining if someone's data was in the training set), or even reconstructing original training data. They can also probe the system's configuration and preprocessing choices.
Researchers have estimated that stealing the weights of one layer of a large model might cost around $8,000. Rate limiting, commonly used in open systems, is fragile because a single anonymous user can pose as many users in a Sybil attack.
Secure inference pipelines can mitigate from both ends: using oracles to limit input types, curbing extraction attacks that require many diverse queries; and using strong identity proofs generated within the pipeline to impose query limits per user, which can be enforced without exposing user identities to the platform, thereby suppressing Sybil attacks.
Agent memory is a new attack surface. Attackers can poison the context (memory) fed to an agent via tool calls or external materials (memory injection), inducing the agent to behave abnormally. For example, in the ElizaOS framework managing large crypto assets, poisoned context could trick the agent into initiating unauthorized transactions.
TEEs can partially mitigate this: running the agent inside a TEE or only pulling authenticated context.
But even with TEEs, two difficulties remain.
First, trusted sources may also contain poisoned content. For example, content from social platforms is user-generated, and posters can easily poison their own posts.
Second, TEE operators can launch rollback or fork attacks, reverting the TEE state to an old checkpoint and erasing subsequent memory updates.
The former is a content detection challenge that cryptography cannot solve; the latter can already be addressed using consensus ideas. Systems like ROTE, Narrator use distributed protocols, even public chains, to ensure TEE state consistency and freshness.
Summarizing the architecture from this section yields the "Protected Pipeline" (Props) general framework, aiming to securely use private data without modifying existing infrastructure.
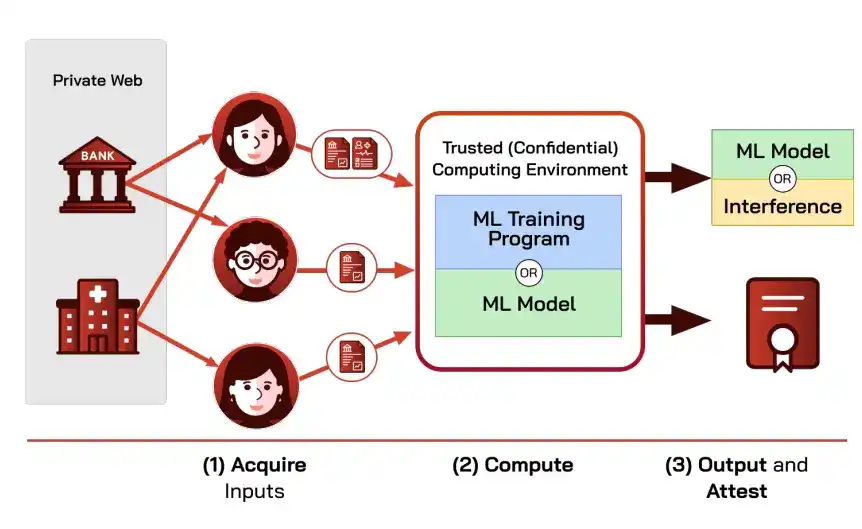
It combines oracles and trusted computing into three segments: the oracle fetches data from authenticated private sources and proves provenance; the TEE performs training or inference within an encrypted boundary; the TEE outputs the model or conclusion along with a proof describing pipeline properties (data sources, software/model code hashes, etc.).
Props guarantees three properties: end-to-end input integrity (output depends only on authenticated data from trusted private sources), confidentiality by default (inputs and intermediate states do not leave the protected boundary; only the output is revealed), and provability without leakage (the proof convinces both data providers and result consumers of the integrity and confidentiality).
There is also a "transparent version" where data and computation need not be confidential, only authenticated, and sources can be public or private.
Five Misconceptions About Crypto x AI
Several common misconceptions or misleading claims have emerged around Crypto x AI platforms and applications. The following five are not entirely false, but it's crucial to clarify which parts hold true now and which require more evidence.
Misconception 1: Blockchain Can Distinguish AI-Generated Content from Human-Generated Content
Registering content on-chain supposedly allows determining later whether it was generated by AI or humans—a frequently cited claim. Projects like Everlyn AI are already putting AI-generated content on-chain. However, blockchain cannot achieve this in a general sense. The issues of "content detection" and "content provenance" need to be separated.
Content detection determines if a piece of content was generated by a human or AI. Current mainstream methods are post-hoc detection, not relying on pre-embedded metadata or signals. They fall into two categories: AI classifiers using deep learning to identify statistical signatures of generative models, and statistical forensics analyzing pixel-level noise distributions or structural anomalies (like physiological inconsistencies in AI-generated faces).
The problem is that blockchain itself cannot perceive this off-chain information. Classification results must be provided by external classifiers. Putting them on-chain can only anchor these results, ensuring the record isn't tampered with after submission, but not guaranteeing the record was true when written. If the external detector is wrong, blockchain permanently preserves the error. That is, blockchain provides "integrity of the claim," not "verification that the claim is true."
Content provenance records the history of a digital asset from creation. Industry standards like C2PA allow creators or devices to attach cryptographically signed metadata (content credentials) recording origin, author, and subsequent edits. Projects like Numbers Protocol, Starling Lab use blockchain as a public, tamper-proof registry for these credentials.
But even with a robust provenance system anchored on-chain, it cannot guarantee whether content was originally human or AI-generated.
A user could perfectly display an AI-generated image on a high-definition screen and photograph it with a C2PA-compliant camera, resulting in a validly signed file labeled "authentically captured." The same applies to text: manually retyping AI-generated text into a compliant editor yields "human-authored" provenance.
Furthermore, once content is altered beyond recognition against the on-chain record, provenance breaks. A universal registry covering all content is nearly impossible in the foreseeable future, leaving provenance systems with significant gaps.
Key Point: In a narrow sense, blockchain can provide robust integrity guarantees for provenance metadata, but it is far from a complete solution to the AI-generated content detection problem.
A truly effective solution requires a universal ecosystem where every piece of content is captured by trusted devices and instantly put on-chain. In reality, most content is created and shared using tools without cryptographic anchoring, leaving unlabeled content in a grey area.
Misconception 2: Blockchain or Decentralization Can Solve AI Bias and Fairness Issues
"Putting model inference and training on-chain will solve AI's unfairness and bias." To evaluate this broad claim, one must first distinguish between different types of bias.
Algorithmic bias is the most common fairness concept in AI. Models learn and can amplify imbalances in datasets, causing discriminative models to perform poorly on disadvantaged groups, or generative models to perpetuate harmful language or stereotypes from training data.
The academic field has proposed numerous technical solutions for training-time and inference-time (guardrails). But these protections are far from perfect; fairness is not a solved problem and may never be fully solved, as even "defining fairness" involves significant trade-offs.
Decentralization cannot solve algorithmic bias because it originates from the training process itself, typically mitigated by improving training or inference techniques—areas decentralization doesn't touch.
However, bias has a second source: high-level decisions influencing model performance—what data to use, what architecture, how to compensate contributors. This layer is orthogonal to the typical AI fairness understanding but can affect algorithmic bias. Some aspects here can be improved using two properties of decentralization.
The first property is transparency. Developers can use blockchain to publicly commit to training data, training algorithms, model checkpoints, and inference guardrails, allowing operators to provably trace the output of a specific training run or inference.
But this is difficult to scale to large models and checkpoints (storage and computation costs are too high). In existing systems, such data mostly resides off-chain and isn't directly accessible to users anyway. In the short term, the benefits of transparency might be limited to the inference stage.
More crucially, unless the industry clarifies what use cases this transparency serves and what interfaces are needed (e.g., allowing users to report misuse of their data, which requires establishing true data ownership and supporting technologies like machine unlearning), transparency alone may not change how people develop and use AI.
The second property is decentralized governance, which needs distinction. The first type includes community governance mechanisms explored and adopted in blockchain (token-weighted voting, liquid democracy). The second type is the decentralized autonomous governance represented by DAOs, where governance decisions are enforced by smart contracts.
The common key point for both is that community governance mechanisms like these don't require blockchain to implement. Therefore, labeling them as "AI problems solved by blockchain" is inaccurate. Technically sensitive, performance-critical AI decisions aren't suitable for broad voting, but value-laden decisions (like model alignment) are more suitable. Mainstream AI developers have explored this but haven't truly adopted it.
True on-chain governance enforced by smart contracts (direct execution or slashing) can enhance robustness but faces the same technical barriers as on-chain transparency. Current infrastructure cannot support AI's storage and computation needs. Realization awaits significant progress in verifiable training—a coherent but premature long-term vision.
Key Point: Blockchain itself cannot reduce algorithmic bias, but it can promote transparency across AI lifecycle stages and broaden participation in AI governance.
Misconception 3: Giving an AI Agent a Wallet Makes It "Autonomous"
Projects working on "agent wallets" and payment protocols often claim that giving an AI agent a wallet, allowing it to earn, spend, and "survive" on its own, makes it autonomous. This statement conflates several different concepts.
The ambiguity first stems from different meanings of "autonomy" across fields. In AI, an autonomous agent can act based on its own perception, learning, and experience, not rigidly following preset rules. Smart contracts are also often called autonomous, but emphasize tamper-resistance, censorship-resistance, and unstoppability.
The former can be called "intelligent autonomy," the latter "execution autonomy." Modern AI agents already possess considerable intelligent autonomy but may lack execution autonomy—administrators can still shut down the servers running them.
What an agent wallet brings is neither type of autonomy. Having a wallet doesn't make AI smarter, nor does it make it more resistant to manipulation or shutdown. What it actually brings is automation: the agent can trade, transfer, and call on-chain facilities programmatically, bypassing manual approval steps.
This automation isn't unique to blockchain either; centralized financial infrastructure can also be called programmatically by agents. A more defensible interpretation is: blockchain payment systems themselves offer stronger autonomy (though not specifically for agents) compared to centralized solutions, e.g., guaranteeing an agent's transactions aren't discriminated against—neutrality and censorship-resistance.
Key Point: Agent wallets enable AI agents to conveniently access financial interfaces, automate economic interactions, and remove manual approvals. But automation is not autonomy. A wallet alone cannot free an agent from human control (operators can still shut down the models or infrastructure it relies on). Automated payments don't require blockchain; centralized systems can achieve them too.
The real value proposition of blockchain payments lies in neutrality and censorship-resistance, suitable for scenarios where payment suppression or intervention is a concern.
Misconception 4: Transparent AI Equals Trustworthy AI
Putting a model's data provenance and inference records on-chain seems like an ideal tool to ensure AI trustworthiness. This argument originated from a widely cited IBM blog and has been extended to AI agents. It needs unpacking at two levels.
Regarding model-layer transparency, recording training data sources seems to provide transparency about model creation, but a huge gap exists between "data provenance records" and "model behavior guarantees."
First, on-chain records are just records, not proof of provenance (proving training set composition requires specialized techniques).
Second, even with complete knowledge of training data, it's insufficient to determine how a model will behave, as training procedures and computational environments also determine model behavior.
Third, even with the full workflow from data to model enabling model reproduction, the inherent non-determinism of stochastic training makes it infeasible in principle to "verify model weights using the training procedure."
Moreover, even with the weights, there's no universally effective method to detect backdoors or adversarial manipulation implanted during training. Recording model data and training info on-chain doesn't directly guarantee its behavioral characteristics or absence of adversarial manipulation.
Regarding inference-layer transparency, recording model inputs and corresponding inferences on-chain seems to provide transparency about model usage. But blockchain makes transactions transparent, not inferences transparent. An on-chain record stating "model X produced inference Z on input Y" offers almost no proof that Z is trustworthy.
It cannot prove "correct execution" (proving this triple was indeed produced by model X according to spec requires TEEs or expensive cryptographic means), nor can it prove "model trustworthiness."
Even if execution correctness is proven, a more fundamental issue is: the complete provenance record of model X cannot, at a semantic level, prove it meets user expectations or industry norms. Using a weight hash to specify a model is even weaker, as model identity does not equal model trustworthiness.
Blockchain is indeed useful for certain trust goals. For example, institutions can publish the hash of an open-source weight model on-chain as an immutable reference, allowing users to confirm they are using the genuine, unaltered model. Similar tamper-evident logging ideas are used for firmware update records and certificate transparency (maintaining publicly auditable logs of certificate issuance using blockchain-like append-only ledgers).
Key Point: A significant gap remains between putting model data provenance and inference records on-chain and providing meaningful guarantees of "model and inference trustworthiness."
Misconception 5: Decentralization Naturally Makes AI Tasks Cheaper
Some projects present decentralized networks as more efficient, cost-saving AI solutions, typified by Decentralized Physical Infrastructure Networks (DePINs), where users rent out their own hardware (e.g., GPUs). The main selling point is lower cost—renting a GPU on a DePIN can be much cheaper than renting a comparable one from a major cloud provider.
But cheaper machines don't necessarily lead to lower total task cost. Decentralized nodes communicate over the public internet; the throughput and latency requirements of AI tasks significantly impact total cost, and very large tasks (like training frontier models) are often bottlenecked by throughput.
Direct cost comparisons are currently difficult because the industry lacks systematic benchmarking to compare the performance and cost of AI tasks on DePINs with traditional clouds on an apples-to-apples basis.
Key Point: Decentralized networks are an attractive alternative to high-cost centralized clouds, but existing data is insufficient to predict when a given task will be cheaper on a DePIN or decentralized AI platform versus a centralized cloud.
Small tasks (inference, small-scale training) are likely cheaper. Very large tasks (training foundation models) might suffer from unstable, low-bandwidth communication between nodes. More research is needed to clarify these trade-offs.
The common thread among these five misconceptions is that what blockchain can provide is more about "integrity" and "verifiability," not "truthfulness" or "trustworthiness" itself. Crypto x AI is still in its early stages, requiring evidence over narrative.