Blog bị trì hoãn ba năm, cuối cùng Lilian Weng cũng đã đăng.
Ngay lúc này, một bài viết dài bị trì hoãn hơn ba năm của cựu phó chủ tịch OpenAI Lilian Weng đang gây bão mạng.
Trong bài blog có tựa đề "Scaling Laws, Carefully", cô ấy đã phân tích Scaling Laws từ đầu đến cuối—
Định luật mà ngành AI đã đổ hàng trăm tỷ đô la để đặt cược này, yếu ớt hơn bất kỳ ai tưởng tượng.
Tổng quan trong một phút: Bài viết dài vạn chữ này nói về điều gì
Một công thức điều hành cả ngành công nghiệp trong năm năm. Scaling Laws nói rằng "làm mô hình lớn hơn, cho nhiều dữ liệu hơn, cung cấp đủ sức mạnh tính toán, hiệu suất sẽ tăng lên theo một tỷ lệ cố định". Nó biến AI từ một thứ huyền bí thành một việc kinh doanh có thể tính toán, gián tiếp chỉ đạo dòng chảy của hàng nghìn tỷ đô la.
OpenAI và DeepMind đưa ra câu trả lời trái ngược. Cùng một câu hỏi "làm thế nào để phân bổ ngân sách sức mạnh tính toán", vào năm 2020 OpenAI nói mô hình nên tăng nhanh hơn dữ liệu, đến năm 2022 DeepMind nói cả hai bên phải tăng cùng nhau. Sau này phát hiện, nguồn gốc của sự bất đồng là do sự khác biệt trong cách thống kê một tham số, cộng với quy mô thí nghiệm không đủ lớn.
Công thức của người chiến thắng cũng ẩn chứa bug. Tỷ lệ tối ưu mà DeepMind đưa ra và được cả ngành sao chép trong hai năm, vào năm 2024 khi được kiểm chứng lại từng dòng, người ta phát hiện: hàm mất mát lấy giá trị trung bình thay vì tổng, khiến bộ tối ưu hóa dừng sớm, các tham số đầu ra hoàn toàn không phải là nghiệm tối ưu.
Phải rất cẩn thận khi dùng quy luật từ mô hình nhỏ để dự đoán mô hình lớn. Đường cong này được khớp trên các mô hình tương đối nhỏ, khi ngoại suy lên cấp độ nghìn tỷ tham số, một sự khác biệt do làm tròn có thể khiến kết luận sai lệch một khoảng lớn. Bài blog có kèm một trình mô phỏng tương tác, chỉ cần kéo thanh trượt là có thể thấy tận mắt.
Còn một vấn đề căn bản hơn: dữ liệu sắp cạn. Công thức mặc định dữ liệu có thể cung cấp vô hạn, nhưng văn bản chất lượng cao là có hạn. Đây cũng là lý do tại sao toàn bộ ngành công nghiệp chuyển hướng tập thể sang học tăng cường, tính toán tại thời điểm kiểm tra và dữ liệu tổng hợp.
Một đường thẳng, nghìn tỷ đô la
Như đã biết, cốt lõi của Scaling Laws có thể được tóm gọn trong một câu—
Mô hình càng lớn, dữ liệu càng nhiều, sức mạnh tính toán càng mạnh, thì biểu hiện càng tốt. Và cái "càng tốt" này không phải ngẫu nhiên, nó có quy luật toán học chính xác.
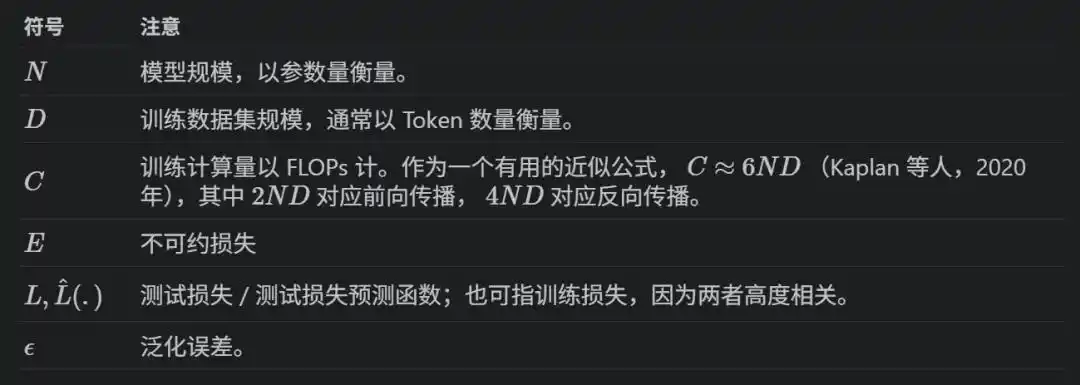
Vẽ hàm mất mát khi huấn luyện mô hình trên tọa độ logarit, nó sẽ giảm xuống theo một đường thẳng khi số lượng tham số mô hình N, lượng dữ liệu D, sức mạnh tính toán C tăng lên.
Viết thành công thức là L(x) = E + A/x^α, trong đó x có thể là N, D hoặc C, E là mất mát tối ưu lý thuyết (entropy của chính dữ liệu), A và α là các hằng số được khớp.
Huấn luyện một mô hình N tham số với D token, tổng sức mạnh tính toán C ≈ 6ND—lan truyền thuận 2ND, lan truyền ngược 4ND.
Đường thẳng này có nghĩa là sự cải thiện hiệu suất là có thể dự đoán được.
Chạy trước vài mô hình nhỏ, khớp đường thẳng đó, ngoại suy sang phải, có thể ước tính biểu hiện của mô hình lớn sau khi huấn luyện. Không cần thực sự tiêu vài tỷ đô la để huấn luyện xong mô hình lớn mới biết nó có được hay không.
Trước đó, học sâu luôn bị chế giễu là "thuật giả kim", biết cái gì hiệu quả nhưng không biết tại sao nó hiệu quả.
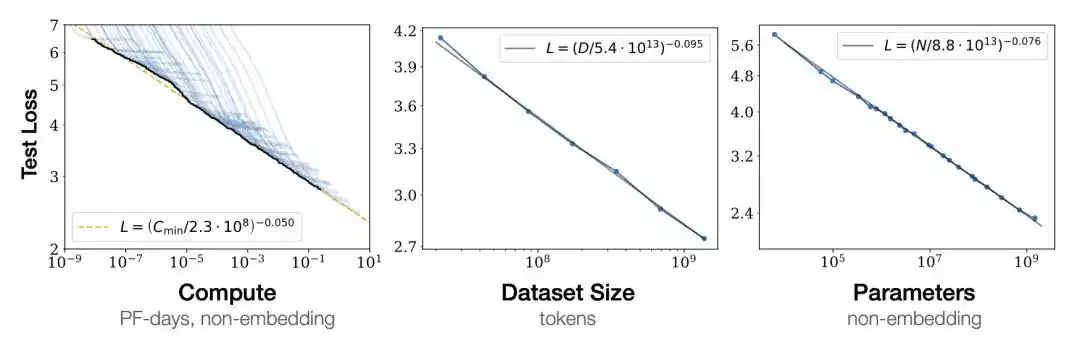
Năm 2020, nhóm Kaplan của OpenAI công bố quy luật lũy thừa này, lần đầu tiên kéo thứ huyền bí vào vùng đất "có thể dự đoán".
Đây chính là niềm tin để tất cả các công ty mô hình lớn dám đổ tiền.
Nhưng lời khuyên quan trọng nhất mà công thức đưa ra, với ngân sách sức mạnh tính toán cho trước, phân bổ mô hình và dữ liệu như thế nào, OpenAI và DeepMind lại đưa ra câu trả lời trái ngược.
Cùng một bài toán
OpenAI và DeepMind đưa ra đáp án trái ngược
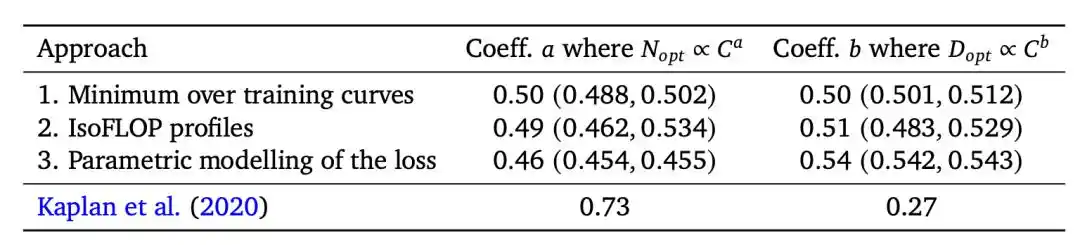
Năm 2020, nhóm Kaplan của OpenAI đưa ra kết luận: Kích thước mô hình tối ưu N_opt ∝ C^0.73.
Dịch ra là: Sức mạnh tính toán tăng gấp 10 lần, 5.5 lần cho mô hình, 1.8 lần cho dữ liệu—mô hình phải tăng nhanh hơn nhiều so với dữ liệu.
Điều này trực tiếp hướng dẫn phương án huấn luyện GPT-3.
Mô hình 175 tỷ tham số, chỉ được cho ăn 300 tỷ token (token là đơn vị nhỏ nhất mà mô hình xử lý văn bản, khoảng 1-2 token tương ứng với một từ).
Theo tiêu chuẩn sau này, đây thuộc loại huấn luyện thiếu nghiêm trọng.
Năm 2022, nhóm Chinchilla của DeepMind đưa ra kết luận ngược lại: N_opt ∝ C^0.50, mô hình và dữ liệu nên tăng trưởng theo tỷ lệ.

Các kỹ sư sau đó đúc kết nó thành một con số có thể nói ra ngay: Tỷ lệ token và tham số tối ưu khoảng 20:1.
Sau đó DeepMind thực hiện một cuộc đối đầu trực tiếp.
Gopher của họ, 280 tỷ tham số với 300 tỷ token. Chinchilla, 70 tỷ tham số với 1.4 nghìn tỷ token. Hai mô hình sử dụng cùng một sức mạnh tính toán.
Chinchilla áp đảo toàn diện.
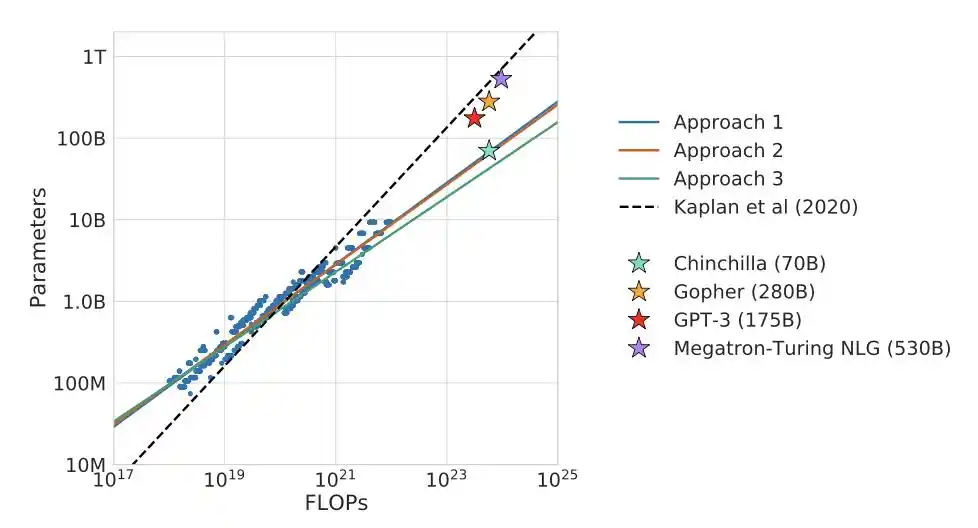
Một mô hình vừa nhỏ vừa "ăn nhiều", đã đánh bại đối thủ vừa to lớn vừa "đói".
Sự đồng thuận của toàn ngành vì thế đảo ngược: từ "làm mô hình lớn" thành "hầu hết mô hình đều được huấn luyện chưa đủ".
0.73 vs 0.50, cùng một vấn đề, đáp án trái ngược, sẽ khiến bạn phân bổ ngân sách sức mạnh tính toán theo hai hướng hoàn toàn khác nhau.
Nguyên nhân hóa ra là một "vấn đề kế toán"
Năm 2024, hai nhà nghiên cứu đã xuất bản một bài báo hòa giải trên tạp chí hàng đầu về máy học TMLR, truy tìm tận gốc sự bất đồng này.
Kết luận khiến người ta vừa buồn cười vừa bực mình.
Nguyên nhân đầu tiên: Hai bên đếm tham số theo cách khác nhau.
Trong mô hình có một lớp tham số gọi là embedding, chịu trách nhiệm chuyển đổi chữ viết thành vectơ số mà mô hình có thể hiểu. Trong mô hình nhỏ, lớp này chiếm tỷ lệ rất lớn trong tổng số tham số, mô hình vài chục triệu tham số có thể chiếm đến một phần ba.
Kaplan khi thống kê số lượng tham số đã loại trừ embedding, trong khi Chinchilla tính nó vào.
Chỉ một sự khác biệt trong cách thống kê tham số như vậy, đủ để làm biến dạng chỉ số lũy thừa được khớp cuối cùng.
Họ đưa ra một công thức hiệu chỉnh ngắn gọn: N = N_\E + ω·N_\E^(1/3), trong đó N_\E là số lượng tham số đã loại bỏ embedding, ω là hằng số. Với mô hình nhỏ, số hạng thứ hai chiếm tỷ trọng lớn, ảnh hưởng của embedding đáng kể; mô hình càng lớn, số hạng thứ hai tiến về 0, hai cách đếm cuối cùng cũng giống nhau.
Nguyên nhân thứ hai: Quy mô thí nghiệm của Kaplan quá nhỏ.
Mô hình lớn nhất mà Kaplan thử nghiệm chỉ đến 1.5 tỷ tham số, trong khi thí nghiệm của Chinchilla quét lên đến trên 16 tỷ. Trong tọa độ logarit, sai lệch khớp nhỏ sẽ bị khuếch đại mạnh khi ngoại suy.
Họ dùng cách thống kê tham số thống nhất để suy ra lại công thức của Chinchilla, phát hiện một quy luật then chốt—
Chỉ số lũy thừa sẽ thay đổi theo quy mô sức mạnh tính toán tăng lên. Trong phạm vi thí nghiệm nhỏ của Kaplan, chỉ số thực sự gần 0.73; nhưng khi quy mô tăng lên, chỉ số hội tụ về 0.50.
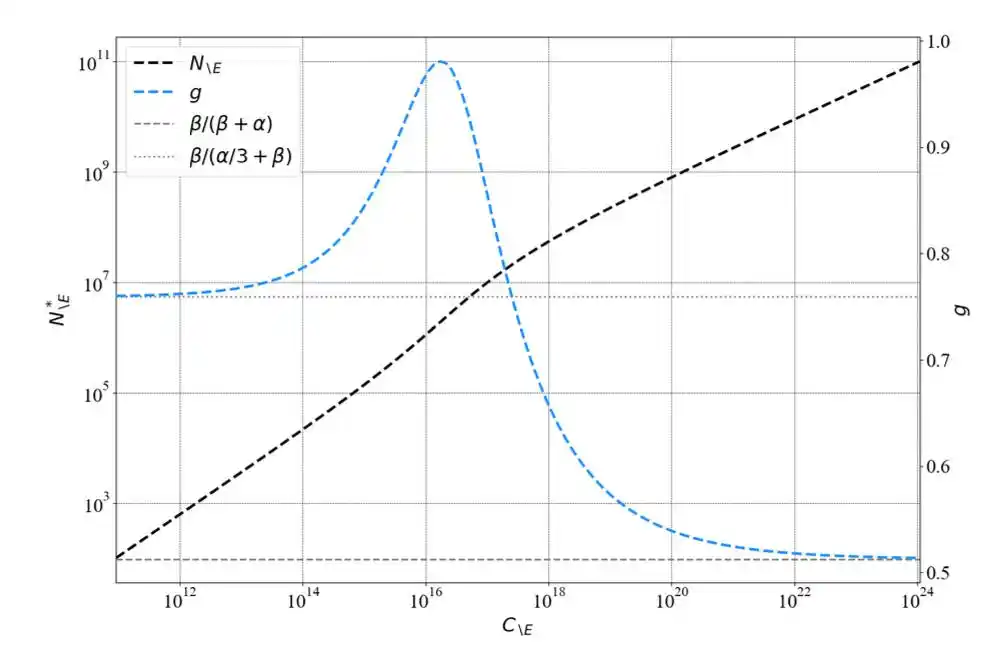
Kaplan không "sai", ông ấy đúng trong phạm vi thí nghiệm của mình.
Nhưng ông ấy đã ngoại suy một quy luật cục bộ thành kết luận toàn cục.
Một vấn đề kế toán về cách đếm tham số, cộng với quy mô thí nghiệm không đủ lớn, đã khiến hai nhóm hàng đầu đưa ra lời khuyên phân bổ tài nguyên trái ngược.
Cả ngành đã điều chỉnh công thức huấn luyện theo kết luận này trong hai năm.
Ngay cả người chiến thắng cũng có bug
Kaplan bị Chinchilla sửa chữa, đó là câu chuyện tiêu chuẩn mà ai cũng biết.
Nhưng Weng đã tiến thêm một bước—Phương pháp luận của chính Chinchilla, cũng có vấn đề.
Bài báo Chinchilla sử dụng ba phương pháp độc lập để kiểm chứng chéo kết luận của mình:
Phương pháp 1: Cố định kích thước mô hình, thay đổi lượng dữ liệu
Phương pháp 2: Vẽ đường cong đẳng sức tính toán (IsoFLOP profiles)
Phương pháp 3: Trực tiếp khớp tham số cho công thức mất mát L(N,D) = E + A/N^α + B/D^β
Ba con đường chỉ đến cùng một kết luận, trông rất vững chắc.
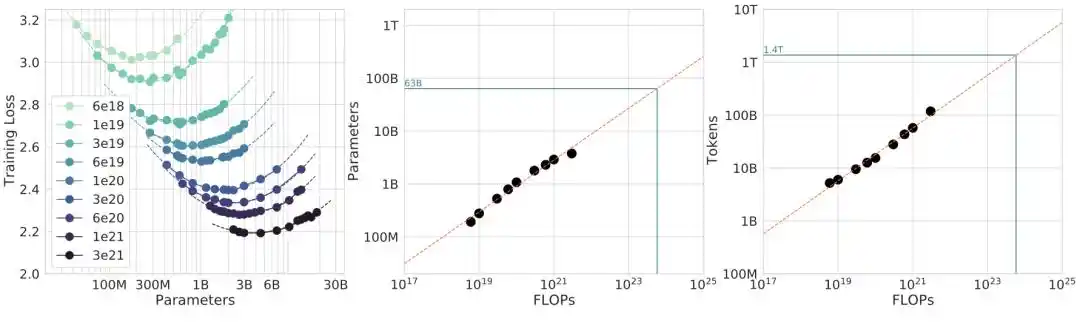
Suy luận toán học của Phương pháp 3 đặc biệt tao nhã: Tối ưu hóa L(N,D) dưới ràng buộc C ≈ 6ND, có thể thu được nghiệm đóng N_opt ∝ (C/6)^(β/(α+β)). Khi α ≈ β, số mũ xấp xỉ 0.5, tức là mô hình và dữ liệu tăng trưởng theo tỷ lệ. Đây là nguồn gốc toán học của 0.50.
Năm 2024, nhóm của tổ chức nghiên cứu AI Epoch AI đã trích xuất thủ công các điểm dữ liệu gốc từ biểu đồ trong bài báo Chinchilla, chạy lại việc khớp của Phương pháp 3.
Hai bug, một cái càng lúc càng khó tin.
Bug 1: Hàm mất mát lấy giá trị trung bình thay vì tổng.
Khi khớp năm tham số này, Chinchilla cần cực tiểu hóa khoảng cách giữa mất mát dự đoán và mất mát thực tế.
Mục tiêu tối ưu hóa đầy đủ như sau: min Σ Huber_δ(log L̂(Nᵢ,Dᵢ) − log Lᵢ), trong đó Huber Loss là một hàm mất mát không nhạy cảm với giá trị ngoại lai (δ = 10⁻³), kết hợp với bộ tối ưu hóa L-BFGS-B để tìm kiếm nghiệm tối ưu.
Vấn đề nằm ở một chi tiết: Họ lấy trung bình (mean) chứ không phải tổng (sum) Huber Loss cho từng mẫu. Hàng trăm mẫu lấy trung bình, giá trị mất mát bị nén xuống mức cực nhỏ.
Bộ tối ưu hóa L-BFGS-B có một tiêu chí hội tụ tích hợp sẵn. Nó tự động dừng khi giá trị mất mát đủ nhỏ. Nó thấy giá trị số nhỏ như vậy, tưởng nhầm đã hội tụ, lập tức dừng lại.
Bộ tối ưu hóa hoàn toàn chưa chạy xong. Các tham số đầu ra không phải là giá trị tối ưu thực sự.
Bug 2: Các tham số then chốt chỉ được giữ lại hai chữ số thập phân.
Trong bài báo Chinchilla có hai chỉ số cốt lõi điều khiển hình dạng quy luật lũy thừa, chỉ được giữ lại đến hai chữ số sau dấu thập phân.
Trông có vẻ là làm tròn vô hại.
Nhưng khi suy ngược lại các hằng số khác từ hai con số thô này, sai số bị khuếch đại theo cấp số nhân. Khoảng tin cậy cuối cùng hẹp một cách phi lý, hẹp đến mức cần độ chính xác đạt được sau hơn 600,000 lần thí nghiệm, trong khi thực tế họ chỉ chạy chưa đến 500 lần.
Một công thức được cả ngành tôn sùng như kim chỉ nam, đằng sau lại ẩn giấu một bug hàm loss chưa chạy xong, và bug này đã ẩn náu suốt hai năm trời.
Weng trong blog còn đính kèm một trình mô phỏng tương tác, ba thanh trượt lần lượt điều khiển độ chính xác mất mát, nhiễu mất mát và khoảng khớp.
Mỗi lần di chuyển, Scaling Law được khớp ra lại biến thành một dạng khác.
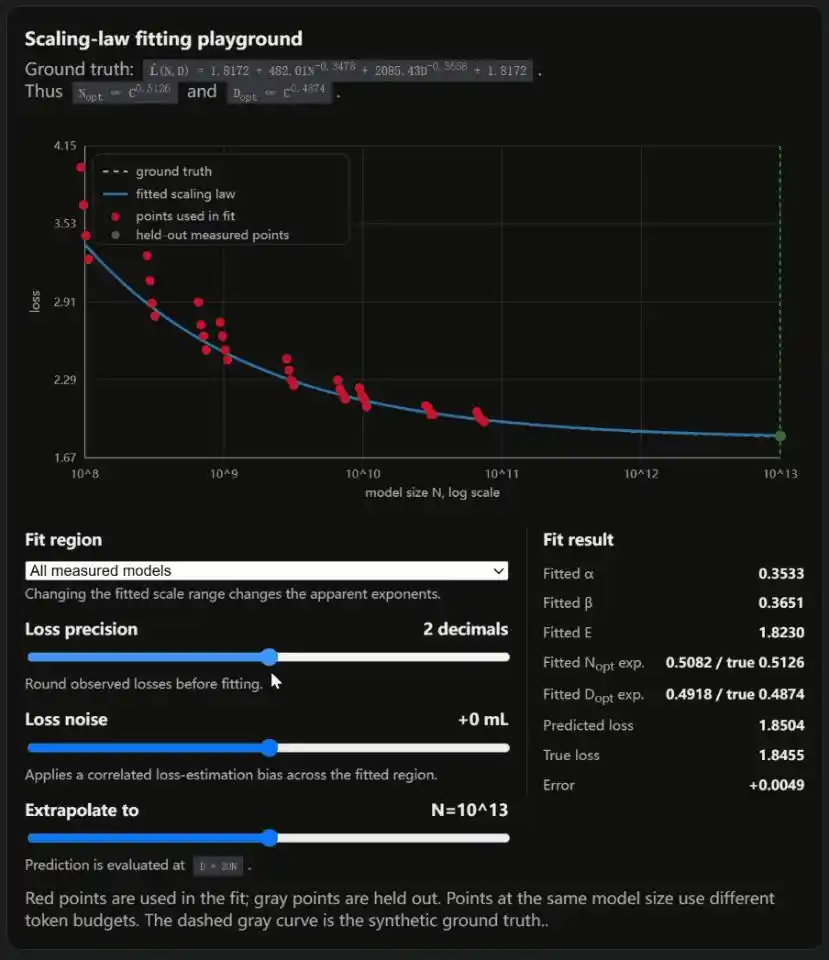
Kết luận của OpenAI có độ lệch cục bộ, kết luận của DeepMind có khiếm khuyết phương pháp luận. Cuộc tranh luận học thuật quan trọng nhất ngành AI, cả hai bên đều có vết nứt.
Dữ liệu sắp cạn kiệt
Ba phần trước nói về các vấn đề phương pháp khớp, tham số đếm thế nào, mất mát tính ra sao, độ chính xác lấy mấy chữ số.
Nhưng ngay cả khi tất cả những vấn đề này đều được sửa chữa, Scaling Laws cổ điển vẫn còn một mối nguy cơ căn bản hơn—
Nó giả định mỗi dữ liệu huấn luyện là duy nhất, không lặp lại, không huấn luyện nhiều lượt, mặc định bạn có dữ liệu vô hạn.
Thực tế là, dữ liệu văn bản chất lượng cao dự kiến sẽ bị các phòng thí nghiệm lớn quét sạch trong khoảng từ 2026 đến 2028.
Việc lặp lại huấn luyện trên dữ liệu là không thể tránh khỏi, tiền đề của công thức cổ điển đang sụp đổ.
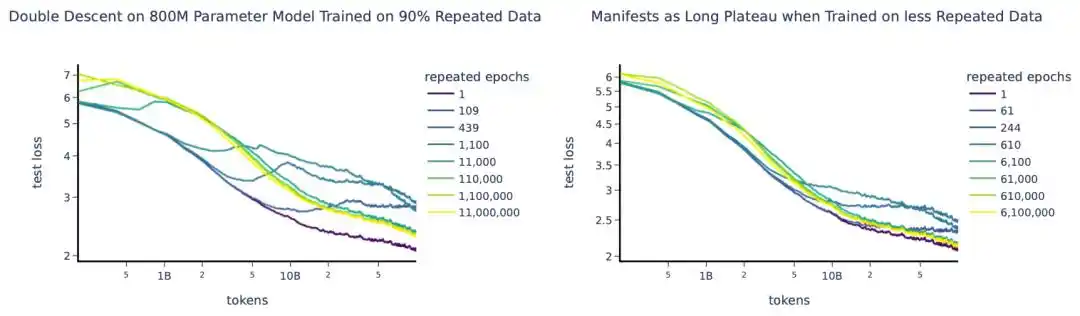
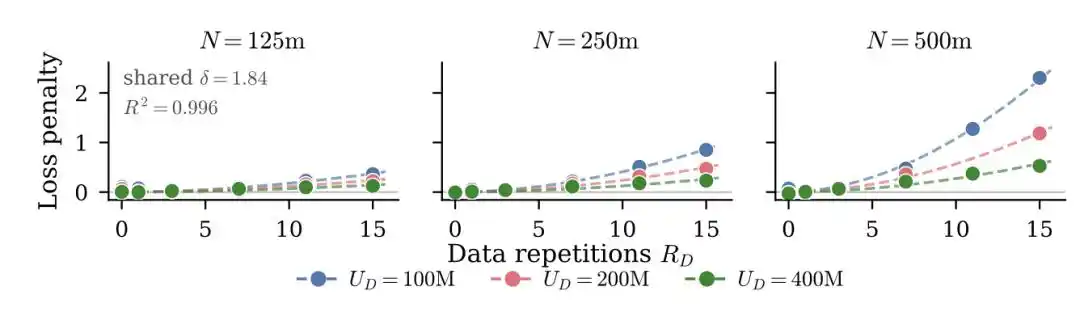
Một thí nghiệm quy mô lớn năm 2023 huấn luyện khoảng 400 mô hình, từ vài chục triệu đến 9 tỷ tham số, tối đa lặp lại huấn luyện 1500 lượt.
Tư tưởng cốt lõi là đưa vào khái niệm "lượng dữ liệu hiệu dụng" để thay thế lượng dữ liệu thực tế—
Nếu bạn có U mẫu dữ liệu duy nhất được lặp lại R lượt, lượng dữ liệu hiệu dụng không phải là U×R, mà được quy đổi theo đường cong suy giảm hàm mũ D_eff = U·(1 - e^(-R)). Lặp lại lượt đầu tiên vẫn có thể học được nhiều thứ mới, đến lượt thứ năm, thứ mười, lợi ích học tập biên tiệm cận về không.
Họ còn phát hiện một kết luận trái với trực giác: Tham số thừa "mất giá" nhanh hơn dữ liệu lặp lại. Tức là, khi ngân sách hạn chế, thay vì tăng mô hình, chi bằng chạy thêm vài lượt huấn luyện sẽ hiệu quả hơn.
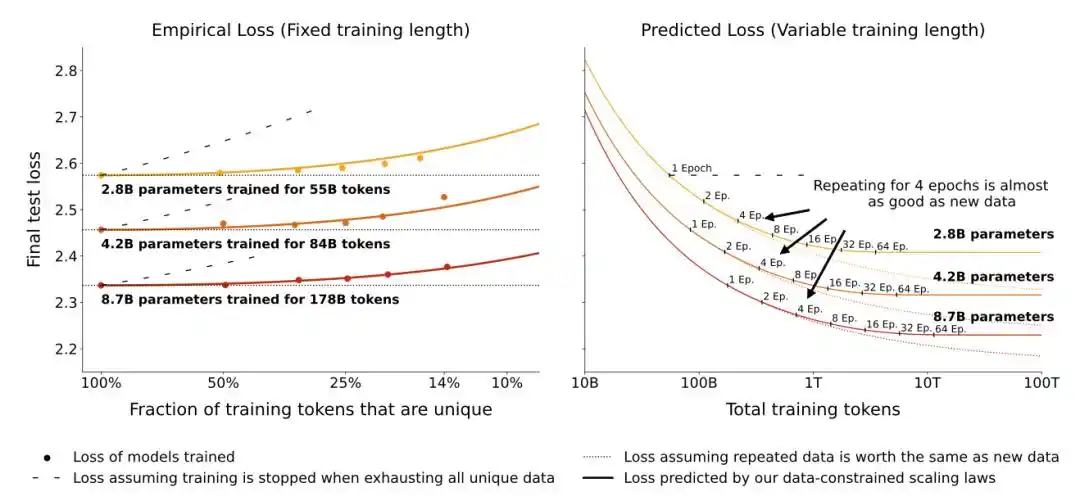
Một bài báo mới vào tháng 5/2026 đổi hướng tiếp cận.
Họ không quy đổi lượng dữ liệu hiệu dụng, mà trực tiếp thêm vào sau công thức mất mát cổ điển một số hạng phạt quá khớp rõ ràng—mô hình xem cùng một lô dữ liệu càng nhiều lần, hình phạt càng lớn, và hình phạt này liên quan đến kích thước mô hình.
Công thức đầy đủ của họ như thế này:
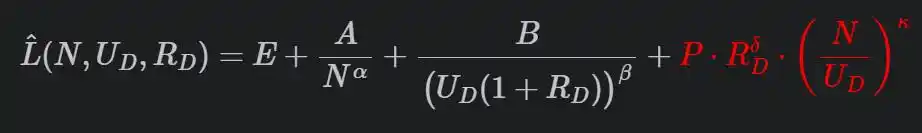
Số hạng phạt màu đỏ cuối cùng là then chốt.
R là số lần lặp lại, N/U là tỷ số giữa số lượng tham số mô hình và lượng dữ liệu duy nhất (mô hình "thừa" bao nhiêu so với dữ liệu), P, δ, κ là các tham số được khớp từ thí nghiệm. Lặp lại càng nhiều, mô hình càng lớn, hình phạt càng nặng.
Phát hiện cốt lõi của bài báo này là: Mô hình lớn nhạy cảm hơn với việc lặp lại dữ liệu. Cũng lặp lại huấn luyện dữ liệu 10 lượt, một mô hình 500 triệu tham số có thể vẫn chịu được, nhưng một mô hình 5 tỷ tham số sẽ bị suy giảm hiệu suất nghiêm trọng hơn nhiều.
Một phát hiện trực tiếp hữu ích trong kỹ thuật là: Tăng cường suy giảm trọng số (weight decay) có thể giảm nhẹ đáng kể hiện tượng quá khớp do huấn luyện lặp lại mang lại.
Đây cũng là lý do tại sao từ 2025 đến 2026, sự chú ý của toàn ngành chuyển hướng tập trung sang ba con đường vượt qua bức tường dữ liệu—
Học tăng cường, DeepSeek R1, OpenAI o-series, để mô hình tự đấu với chính nó trong các nhiệm vụ có thể kiểm chứng như toán học và lập trình, tạo ra tín hiệu huấn luyện.
Tính toán tại thời điểm kiểm tra, không tăng chi phí huấn luyện, để mô hình "suy nghĩ" thêm vài bước khi trả lời câu hỏi để đổi lấy biểu hiện tốt hơn.
Dữ liệu tổng hợp, dùng mô hình mạnh hiện có để tạo ra dữ liệu mới huấn luyện thế hệ mô hình kế tiếp.
Ẩn ý của ba con đường giống nhau: Quy luật lũy thừa thuần túy dựa vào "chồng chất quy mô", đã không còn đủ dùng.
Từ Bắc Đại đến OpenAI đến công ty riêng
Lilian Weng, cử nhân Bắc Đại, tiến sĩ Đại học Indiana Bloomington.
Thú vị là, hướng tiến sĩ của cô không phải học sâu, mà là Khoa học Mạng và Hệ thống Phức tạp, nghiên cứu thông tin lan truyền trong mạng xã hội như thế nào.
Sau khi tốt nghiệp, cô đầu tiên đến Dropbox làm khoa học dữ liệu, lại đến công ty fintech Affirm, năm 2018 mới gia nhập OpenAI.
Đến OpenAI, dự án đầu tiên Weng tham gia là robot. Cánh tay cơ khí Dactyl mất hai năm để học giải khối Rubik, cô là một trong những người đóng góp cốt lõi.
Sau đó chuyển sang xây dựng nhóm nghiên cứu ứng dụng, sau khi GPT-4 ra mắt được giao nhiệm vụ thành lập nhóm Safety Systems, đến khi cô rời đi, nhóm này đã có hơn 80 nhà khoa học, kỹ sư và chuyên gia chính sách.
Tháng 8/2024 được thăng chức lên Phó chủ tịch Nghiên cứu và An toàn, ba tháng sau tuyên bố rời đi.

Năm 2017, Weng mới tiếp xúc học sâu không lâu, đã mở một blog cá nhân tên Lil'Log, ban đầu chỉ để tổng hợp ghi chú học tập của mình.
Cô từng nói, "Giải thích rõ ràng một khái niệm, là cách tốt nhất để kiểm tra xem bản thân có thực sự hiểu nó hay không".
Kết quả viết liền chín năm, học tăng cường, mô hình khuếch tán, đại tác tử mô hình lớn, mỗi bài đều viết từ nguyên lý cơ bản, bài dài hàng chục trang kèm sơ đồ tự vẽ.
Blog này sau đó trở thành một trong những blog kỹ thuật cá nhân được trích dẫn nhiều nhất trong lĩnh vực AI, nhiều trường đại học trực tiếp lấy làm giáo trình.
Tháng 2/2025, cô và cựu CTO OpenAI Mira Murati thành lập Thinking Machines Lab, đồng sáng lập còn có đồng sáng lập OpenAI John Schulman, cựu phó chủ tịch nghiên cứu Barret Zoph và Luke Metz. a16z dẫn đầu vòng hạt giống 20 tỷ đô la, định giá 120 tỷ.
Và trong khi công ty phát triển tốc độ cao, cô dành thời gian viết xong bài viết dài về Scaling Laws bị trì hoãn ba năm này.
ChatGPT, Claude, Gemini mà bạn dùng hàng ngày, đằng sau đều là những công thức này quyết định thế hệ tiếp theo sẽ được huấn luyện như thế nào.
Thế hệ AI tiếp theo có dễ dùng hay không, không phụ thuộc vào ai có nhiều GPU hơn, mà phụ thuộc vào ai xử lý những chi tiết này chính xác hơn.
Tài liệu tham khảo:
https://x.com/lilianweng/status/2070237256070389897?s=20
https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
Bài viết từ tài khoản công chúng WeChat "Tân Trí Nguyên", tác giả: ASI Khải Thị Lục, biên tập: Môi-tây
![Đánh giá mức giảm giá 12% của Sonic [S] và lý do có thể còn nhiều đợt bán tháo tiếp theo](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)







