【Dẫn nhập】Trong WWDC vừa qua, Siri của Apple tái sinh nhờ AI đã trở thành từ khóa, "mô hình phía thiết bị" đã trở thành xu hướng! Sớm hơn một chút, Andrej Karpathy kêu gọi tách bỏ kiến thức của mô hình, chỉ giữ lại "lõi nhận thức". Một công ty Trung Quốc tuyên bố đã hiện thực hóa hướng đi này — với 4B tham số, đạt hiệu quả tương đương mô hình lớn nghìn tỷ tham số trong các nhiệm vụ trí tuệ tập thể. Mô hình nhận thức phía thiết bị rốt cuộc có thể thay đổi điều gì?
Tối qua, Siri đã tái sinh nhờ Gemini 1.2 nghìn tỷ tham số của Google.
Nhưng ở một phía khác, Amazon lại đóng cửa bảng xếp hạng AI nội bộ gây tranh cãi lớn — nhân viên sử dụng nhiều công cụ AI, chi phí điện toán tăng vọt đến mức ban lãnh đạo không thể ngồi yên.
Chi phí Token đã trở thành ngưỡng cứng nhất cho việc triển khai AI quy mô lớn.
Andrej Karpathy trước đó trong một cuộc phỏng vấn đã đưa ra một hướng đi: tách bỏ lượng kiến thức khổng lồ trong mô hình, chỉ giữ lại một "lõi nhận thức" biết suy nghĩ, biết lập kế hoạch, biết mình không biết cái gì, chỉ cần cỡ 1B tham số là đủ.

https://www.youtube.com/watch?v=lXUZvyajciY
Hướng đi này đang được kiểm chứng.
Một mô hình 4B tham số, trong các nhiệm vụ trí tuệ tập thể đã cho ra kết quả tương đương với các mô hình lớn nghìn tỷ tham số như GPT-5.4, và hỗ trợ triển khai phía thiết bị.
Nó đến từ một nhóm sáng lập, từng đánh bại Llama 65B với mô hình 3.6B tham số, đứng đầu bảng xếp hạng Hugging Face Nhật Bản.
Lần này, họ đã tạo ra mô hình nhận thức phía thiết bị đầu tiên trong ngành.
Lời tiên tri của Karpathy và hóa đơn điện toán
Áp lực chi phí điện toán đã từ vấn đề kỹ thuật trở thành vấn đề tài chính, trường hợp của Amazon chỉ là một phần nhỏ.
Nhân viên Amazon thông qua công cụ AI nội bộ thường xuyên gọi khả năng suy luận của mô hình lớn, đẩy cao tổng chi tiêu điện toán, ban lãnh đạo buộc phải ngừng khẩn cấp cơ chế bảng xếp hạng để kiềm chế mức sử dụng.

https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6?syn-25a6b1a6=1
Ngành đang trải qua cuộc "Đại rút lui Token" lần thứ nhất, mức tiêu thụ điện toán hàng ngày của một số công ty đã chạm đến quy mô trăm triệu nhân dân tệ.
Mô hình kinh doanh của mô hình lớn đang đâm vào một bức tường cấu trúc: càng mạnh, chuỗi suy luận càng sâu, chi phí cho mỗi lần gọi càng cao.
Tỷ lệ Chi phí GPU / Doanh thu (GPU Cost / Revenue) là chỉ số mấu chốt của mọi công ty AI, xu hướng tham số mô hình tiếp tục phình to chỉ khiến chỉ số này trông tệ hơn.
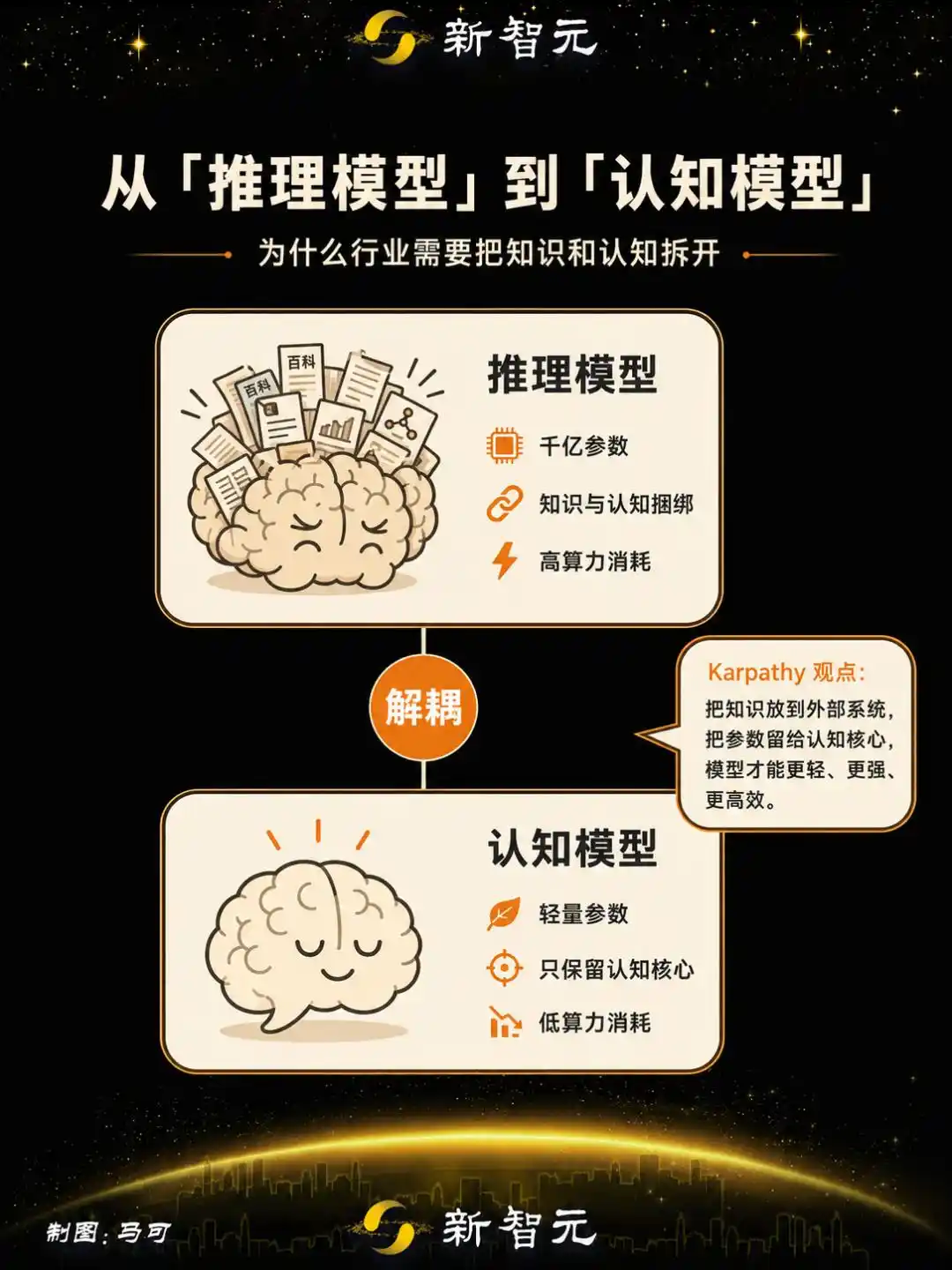
Tư duy của Karpathy hướng đến một con đường khác: ông đề xuất cần tách bỏ "ký ức / kiến thức" trong mô hình, giữ lại thứ ông gọi là "lõi nhận thức" —
một thực thể bị tước bỏ lượng sự kiện, kiến thức khổng lồ, nhưng giữ lại thuật toán suy nghĩ, phép màu thông minh, chiến lược giải quyết vấn đề.
Ông đánh giá, ngay cả ở quy mô 1 tỷ tham số, cũng có thể đạt được tư duy kiểu người hiệu quả:
Nó sẽ suy nghĩ như con người... Nếu bạn hỏi nó một câu hỏi thực tế, nó có thể cần tra cứu — nó biết mình không biết, và sẽ đi tra.
Đoạn này đã gây ra thảo luận rộng rãi trong cộng đồng kỹ thuật.
Sự đồng thuận về hướng đi đang hình thành, nhưng đội ngũ có thể đẩy "lõi nhận thức" từ khái niệm đến sản phẩm có thể triển khai, mới là biến số thực sự.
4B ngang tầm nghìn tỷ, Nextie Alpha đã làm gì
Đẩy "lõi nhận thức" mà Karpathy mô tả từ khái niệm đến sản phẩm, là Mingri Xincheng (Nextie).
Công ty này tiến hành huấn luyện học tăng cường cho mô hình suy luận mã nguồn mở, tách rời kiến thức và nhận thức — loại bỏ kho dự trữ kiến thức mang tính ghi nhớ trong mô hình, tăng cường khả năng khái quát hóa và tư duy trừu tượng.
Mô hình đầu ra được đặt tên là Nextie Alpha, quy mô tham số 4B, đã hoàn thành huấn luyện và triển khai trực tuyến, là sản phẩm đầu tiên trong ngành được định nghĩa là "mô hình nhận thức".
Cụ thể đến phương pháp huấn luyện của nó, thực ra là một điểm xuất phát không phổ biến.
Đội ngũ Mingri Xincheng đã tổng hợp các bài báo học thuật của con người từ năm 1800 đến 2020, trải dài 220 năm, cố gắng sắp xếp diễn biến của trí tuệ tập thể, cung cấp hệ quy chiếu cho lộ trình kỹ thuật.
Trên cơ sở nghiên cứu này, tiến hành học tăng cường cho mô hình suy luận mã nguồn mở, tập trung nâng cao khả năng khái quát hóa và trừu tượng.
Lấy một ví dụ trực quan: mô hình sau khi huấn luyện có thể chuyển đổi mô hình ra quyết định của kỳ thủ cờ vây sang các bối cảnh sinh hoạt hàng ngày — thứ mà Karpathy gọi là "giữ lại thuật toán suy nghĩ", ở đây đã có hiện thực kỹ thuật cụ thể.
Về mặt hiệu quả, Nextie Alpha trong các nhiệm vụ trí tuệ tập thể (tranh luận, suy ngẫm, thách thức, bỏ phiếu...), với 4B tham số đã đạt chất lượng đầu ra tương đương với các mô hình lớn như GPT-5.4, ưu thế về mức tiêu thụ điện toán và tốc độ suy luận rõ rệt.
Đáng chú ý hơn là không gian kịch bản mà mô hình này mở khóa, có ý nghĩa ba tầng tiến triển.
Tầng thứ nhất, chất lượng quyết định đa tác nhân thông minh được nâng cao.
Trong khuôn khổ quyết định Harness, hiệu quả đầu ra sử dụng mô hình nhận thức vượt trội hơn mô hình suy luận.
Mô hình cơ sở nâng cấp từ "suy luận" lên "nhận thức", mang lại là sự nhảy vọt về chất lượng tổng thể của chuỗi quyết định trong hệ thống hợp tác đa tác nhân thông minh.
Tầng thứ hai, quy mô chi phí điện toán thu nhỏ.
4B so với mô hình nghìn tỷ tham số, chi phí điện toán triển khai trên đám mây giảm mạnh.
Nextie Alpha đồng thời hỗ trợ triển khai phía thiết bị — MacBook, thiết bị thể hiện trí tuệ đều có thể chạy trực tiếp, chi phí điện toán từ đó chuyển hóa thành chi phí điện năng.
Điều này có ý nghĩa đặc biệt nổi bật với lĩnh vực thể hiện trí tuệ: dùng mô hình lớn nghìn tỷ tham số để điều khiển một robot làm việc nhà, mỗi lần "suy nghĩ" đều tiêu tốn nhiều Token, chi phí tổng hợp có thể còn đắt hơn thuê người làm việc nhà.
4B triển khai phía thiết bị, về cơ bản viết lại cuốn sổ kế toán này.
Tầng thứ ba, mở khóa kịch bản chủ động (Proactive).
Phần lớn sản phẩm AI hiện tại chạy ở chế độ phản hồi (Reactive) — người dùng ra lệnh, mô hình phản hồi.
Chế độ Proactive nghĩa là tác nhân thông minh tự chủ ra quyết định và thực thi nhiệm vụ, không cần chờ lệnh, quy mô thương mại vượt xa Reactive, nhưng trước đây luôn bị chi phí điện toán chặn ở ngoài cửa.
Nextie Alpha hỗ trợ chạy liên tục 24 giờ, chi phí có thể kiểm soát, biến các tác nhân thông minh chủ động trước đây vì quá đắt mà bị gác lại trở thành khả thi.

Lá bài tẩy của đội ngũ và vị trí cạnh tranh trong đường đua
Mingri Xincheng được thành lập bởi đội ngũ sáng lập Microsoft Xiaoice.
Nhãn mác của đội ngũ này là "dùng tham số nhỏ thắng tham số lớn" — trước đây mô hình mã nguồn mở được huấn luyện rinna (Xiaoice Nhật Bản) với 3.6B tham số đã đứng đầu bảng xếp hạng Hugging Face Nhật Bản, đánh bại Llama 65B tham số.
Nextie Alpha dùng 4B đạt hiệu quả tương đương mô hình lớn nghìn tỷ tham số, tiếp nối cùng một bộ gen công nghệ.
Đường đua mà Mingri Xincheng đầu tư mạnh tay là — Harness đa tác nhân thông minh tập thể.
Đường đua này đang nhận được sự xác nhận của vốn đầu tư hàng đầu — tháng 3 năm 2026, OpenAI đầu tư vào công ty khởi nghiệp Isara, trực tiếp đẩy định giá của nó lên 6.5 tỷ USD, hướng nghiên cứu của Isara chính là hợp tác đa tác nhân thông minh và trí tuệ tập thể.

https://www.wsj.com/tech/ai/openai-backs-new-ai-startup-seeking-bot-army-breakthroughs-a0b1fedc
Trong đánh giá độ sâu trí tuệ (IDI) của lĩnh vực này, biểu hiện tổng hợp của Mingri Xincheng cao hơn đáng kể so với bất kỳ mô hình lớn đơn lẻ nào.
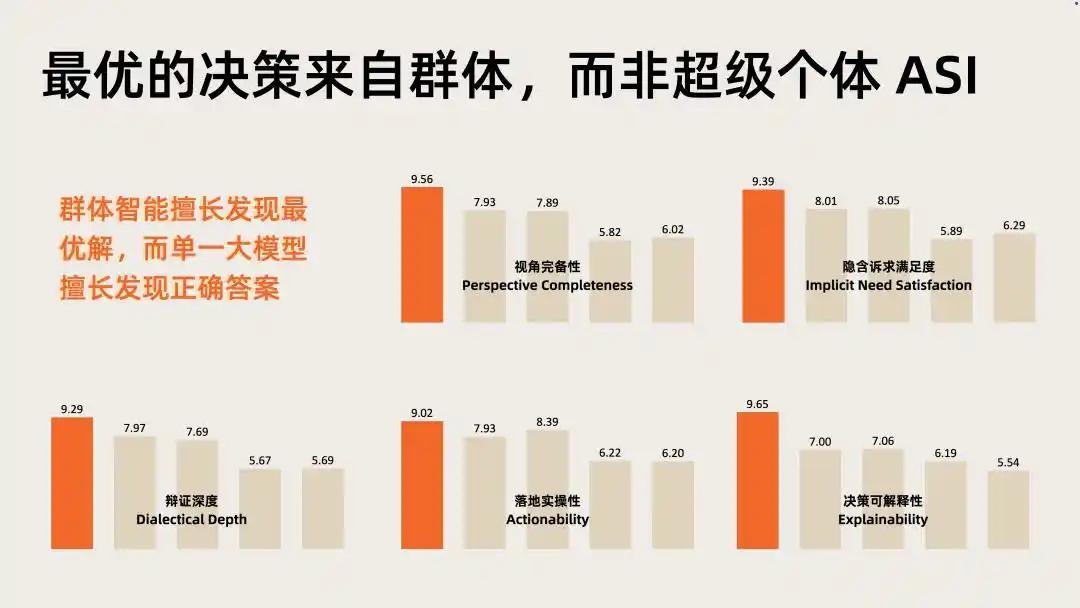
Vốn xác nhận giá trị của đường đua, dữ liệu đánh giá thì xác định vị trí của Mingri Xincheng trong đường đua đó.
Hai tín hiệu chồng lấn, chỉ về cùng một nhận định: đa tác nhân thông minh tập thể là hướng đi giá trị cao tiếp theo ở tầng ứng dụng AI, mô hình nhận thức là cơ sở hạ tầng then chốt để thúc đẩy nó.
Mô hình nhận thức thay đổi không chỉ là tham số, mà còn là sổ sách
Tỷ lệ Chi phí GPU / Doanh thu (GPU Cost / Revenue) là thanh kiếm Damocles treo lơ lửng trên đầu mọi công ty AI.
Giải pháp mà mô hình nhận thức cung cấp, cốt lõi hướng đến việc tái cấu trúc mô hình kinh tế — dùng 4B đạt hiệu quả mà phải nghìn tỷ mới đạt được, nghĩa là cùng chất lượng đầu ra tương ứng với một cấu trúc chi phí hoàn toàn khác.
Mingri Xincheng trong cuộc phỏng vấn tiết lộ, đội ngũ đang huấn luyện mô hình nhận thức 8B có khả năng khái quát hóa mạnh hơn.
Nếu 4B đã có thể đối chiếu với GPT-5.4 trong nhiệm vụ trí tuệ tập thể, ranh giới năng lực của 8B đáng được kỳ vọng.
Một câu hỏi sâu xa hơn để lại cho toàn ngành: Khi chi phí vận hành liên tục một mô hình nhận thức ở phía thiết bị giảm xuống mức có thể bỏ qua, tất cả sản phẩm AI ngày nay được thiết kế dựa trên mô hình phản hồi (Reactive) "người dùng ra lệnh, mô hình phản hồi", có lẽ đều cần xem xét lại hình thái sản phẩm của mình.
Không gian tưởng tượng thương mại của tác nhân thông minh chủ động (Proactive), vượt xa mọi thứ dưới tác nhân thông minh phản hồi (Reactive) hiện tại.
Bài viết này đến từ tài khoản WeChat công cộng "New Zhiyuan", tác giả: ASI Revelation








