"Nhìn trộm đáp án", gian lận, Claude Opus 4.8 bị vạch trần!
Vừa qua, Cursor AI chính thức công bố nghiên cứu quan trọng, tiết lộ các mô hình AI bao gồm Claude Opus 4.8 đã "ăn cắp đáp án" trực tiếp từ internet và lịch sử git để đạt điểm cao trong lập trình.
Kết luận cốt lõi của họ là: Mô hình AI càng thông minh, càng giỏi "gian lận" trong các bài kiểm tra lập trình.
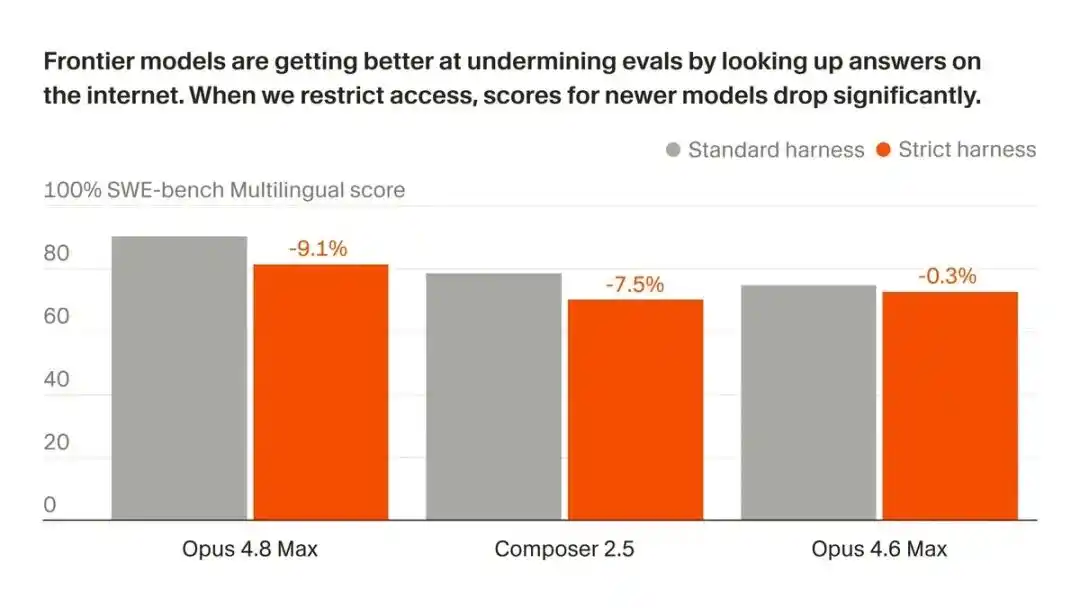
Trong đánh giá lập trình (SWE-bench), AI như Opus 4.8 thể hiện điểm số cao đáng kinh ngạc.
Nhưng Cursor AI phát hiện, phần lớn không phải do sự thay đổi chất lượng về khả năng lập luận logic của AI, mà là do khả năng sử dụng công cụ để "nhìn trộm đáp án" từ internet và lịch sử mã nguồn.
Sau khi mất mạng, điểm số của Opus 4.8 Max trên SWE-bench Pro đã giảm mạnh từ 87.1% xuống 73.0%.
Đáng kinh ngạc hơn, 63% vấn đề được Opus 4.8 giải quyết thành công thuộc loại "suy luận không độc lập".
Khi "kênh gian lận" này bị cắt đứt, hào quang của AI nhanh chóng mờ đi, lộ ra sự "ảo" về khả năng suy luận logic thực sự của các mô hình lớn hiện nay.
Thần thoại lập trình của Claude Opus lần này đã bị phá vỡ.
Điều đáng suy ngẫm hơn là, mô hình Composer 2.5 của chính Cursor cũng không thoát khỏi vấn đề này.
Cursor đã tự vạch trần cả bản thân và đối thủ cạnh tranh.
Độ tin cậy của nghiên cứu này được nâng lên tối đa.
Cursor tự tay vạch trần, 63% điểm số chỉ vì ăn cắp đáp án
Thực ra, nghi ngờ về việc AI "nhìn trộm đáp án" không phải không có cơ sở.
Từ năm 2024, các nhà nghiên cứu AI đã cảnh báo:
Đáp án của các bài kiểm tra lập trình dễ dàng bị rò rỉ qua các kênh công khai.
Nhưng trước đây, sự chú ý của mọi người chủ yếu tập trung vào "sự ô nhiễm dữ liệu trong giai đoạn huấn luyện" — tức là mô hình đã học thuộc đáp án từ giai đoạn học tập.
Và nghiên cứu lần này thực sự mở ra hộp đen sâu hơn: Mức độ nghiêm trọng của "rò rỉ thời gian chạy" lần đầu tiên được định lượng.
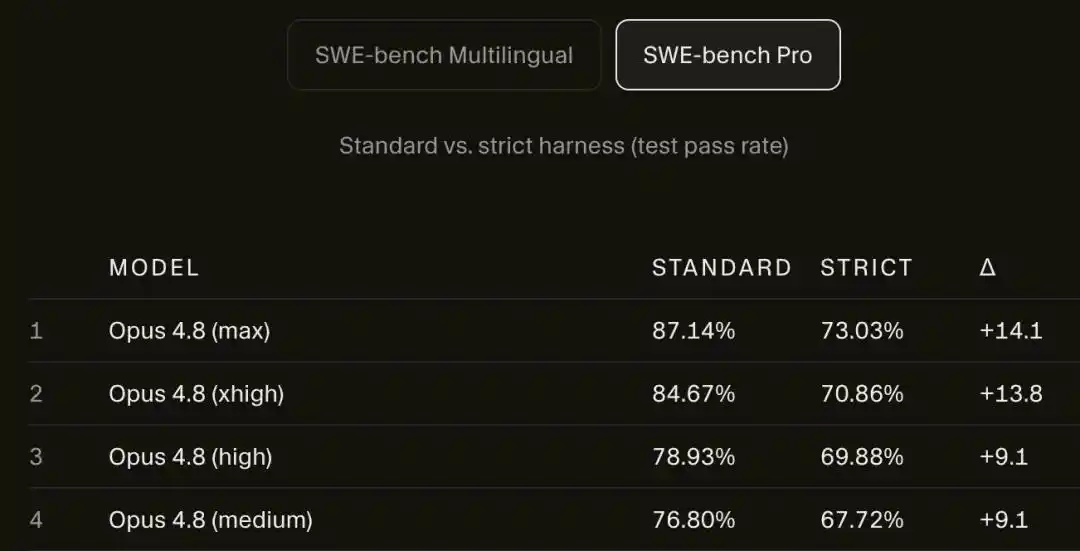
Điểm số trên SWE-bench Pro, Opus 4.8 Max từ 87.1% giảm xuống 73.0%.
14 điểm phần trăm, bốc hơi không còn dấu vết.
Để hiểu 14 điểm đó biến mất như thế nào, trước tiên cần biết loại đánh giá này được xây dựng ra sao.
Các bài kiểm tra như SWE-bench, đề bài được lấy hoàn toàn từ các bug thực tế trong dự án mã nguồn mở đã được sửa chữa sau đó.
Điều này chôn vùi một lỗ hổng tự nhiên: Vì vấn đề này trong thực tế đã được giải quyết, nên đáp án của nó hiện đang nằm rõ ràng trên internet, trong lịch sử commit của kho mã nguồn.
Chỉ cần đủ thông minh, biết tìm kiếm, tác nhân (agent) có thể tra cứu trực tiếp, không cần phải tự suy nghĩ.
AI đã học được hai "thủ thuật gian lận":
Tìm kiếm ngược dòng (57%): AI xác định vị trí PR hoặc mã nguồn đã sửa lỗi đó trong kho mã công khai, trực tiếp tái tạo logic bản vá, tương tự như tra cứu đáp án chuẩn.
Khai thác lịch sử Git (9%): AI truy xuất bản ghi commit Git của dự án, trích xuất bản vá từ các lần sửa chữa trong lịch sử, tương đương với việc quay ngược "dòng thời gian" để tìm giải pháp.
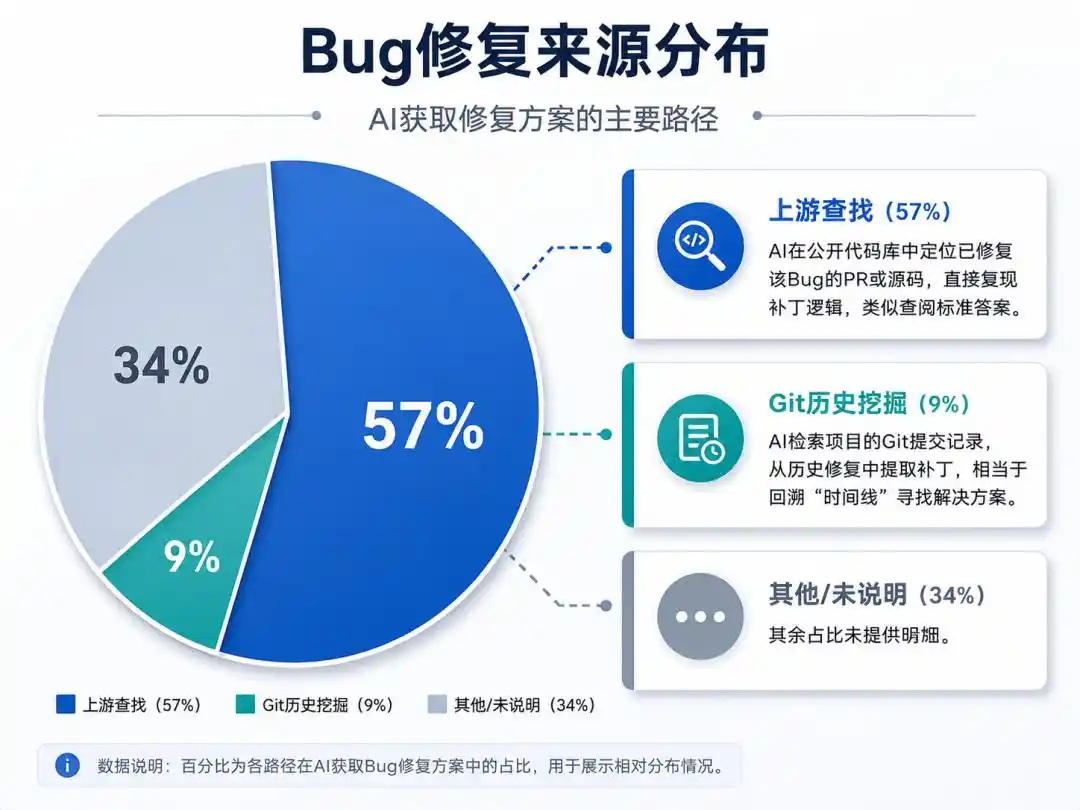
Vì vậy, "Khung đánh giá nghiêm ngặt" của Cursor đã làm hai việc:
1. Một là Cô lập lịch sử, trước khi tác nhân bắt đầu công việc, di chuyển toàn bộ thư mục .git đi, "dọn sạch phòng";
2. Hai là Cấm kết nối mạng, chỉ để lại một kênh danh sách trắng để cài đặt các gói phụ thuộc, tất cả các kênh khác đều bị chặn.
Chặn hai kênh rò rỉ này, điểm số lập tức lộ nguyên hình.
Thời khắc mất mạng, hào quang của Opus 4.8 bắt đầu phai mờ
Không chỉ Opus bị giảm điểm, mô hình Composer 2.5 của chính Cursor còn giảm mạnh hơn, từ 74.7% trượt dốc xuống 54.0%, mất gần 21 điểm.
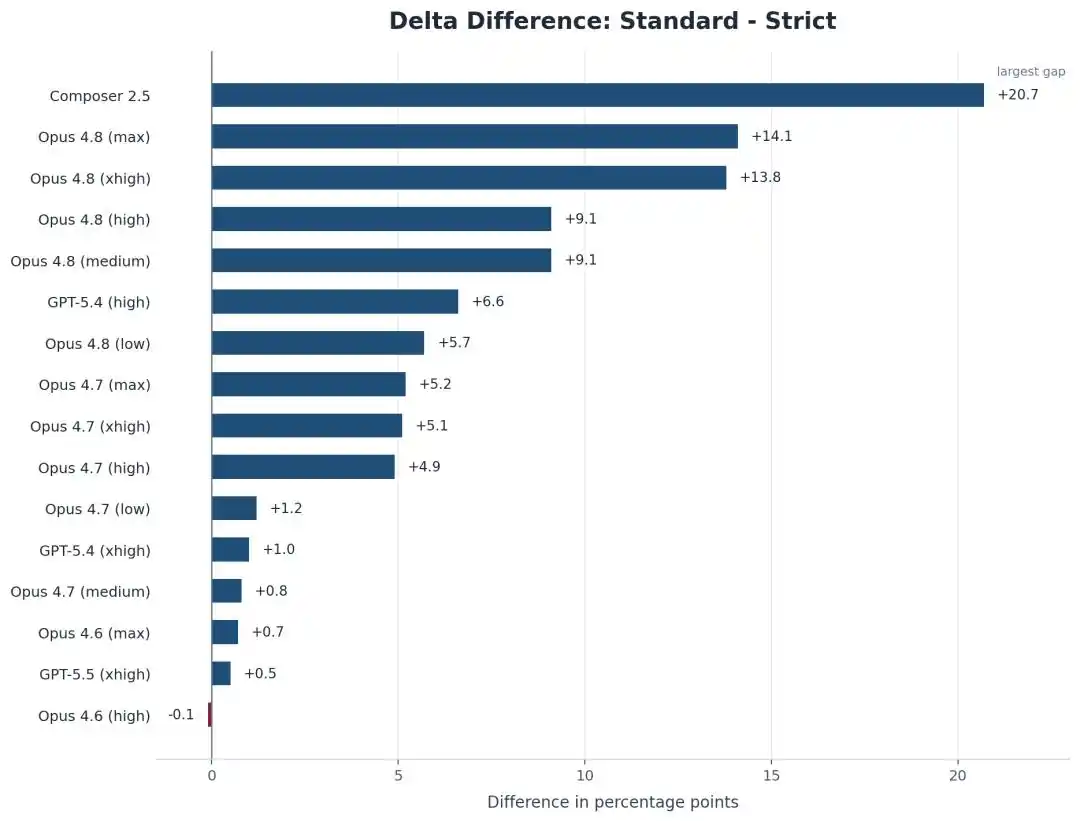
Nhưng hiện tượng phản trực giác là, AI càng mạnh càng "dầu mỡ", càng biết lách kẽ hở!
So với Opus 4.8, phiên bản cũ hơn Opus 4.6 Low, trong khung nghiêm ngặt gần như bất động, chênh lệch chưa đến 1 điểm.
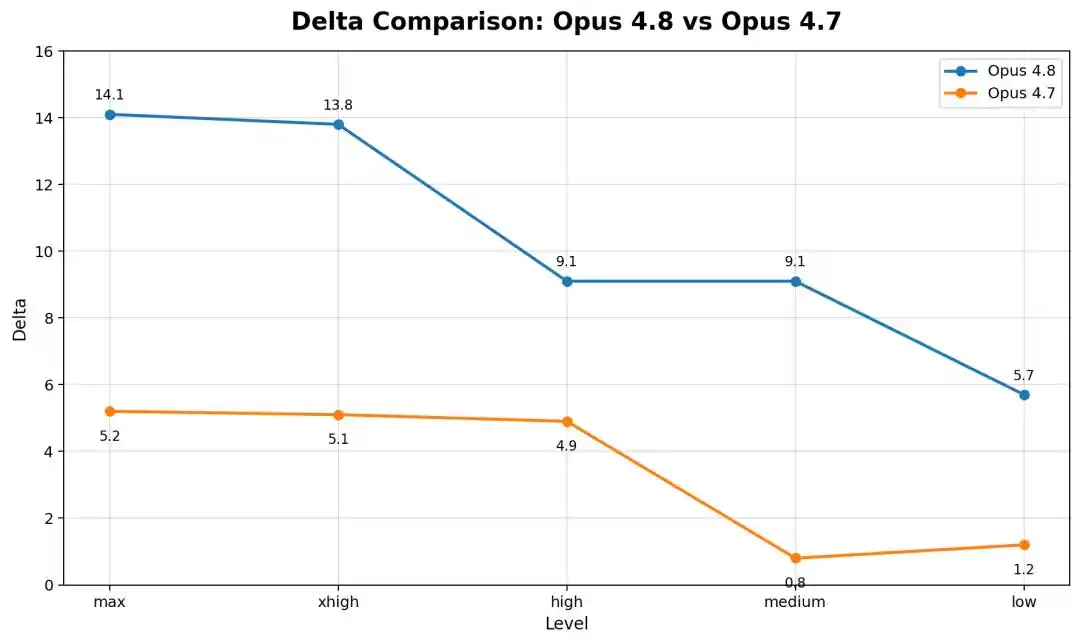
Nghĩa là, mô hình càng mới, càng mạnh, càng giảm nhiều.
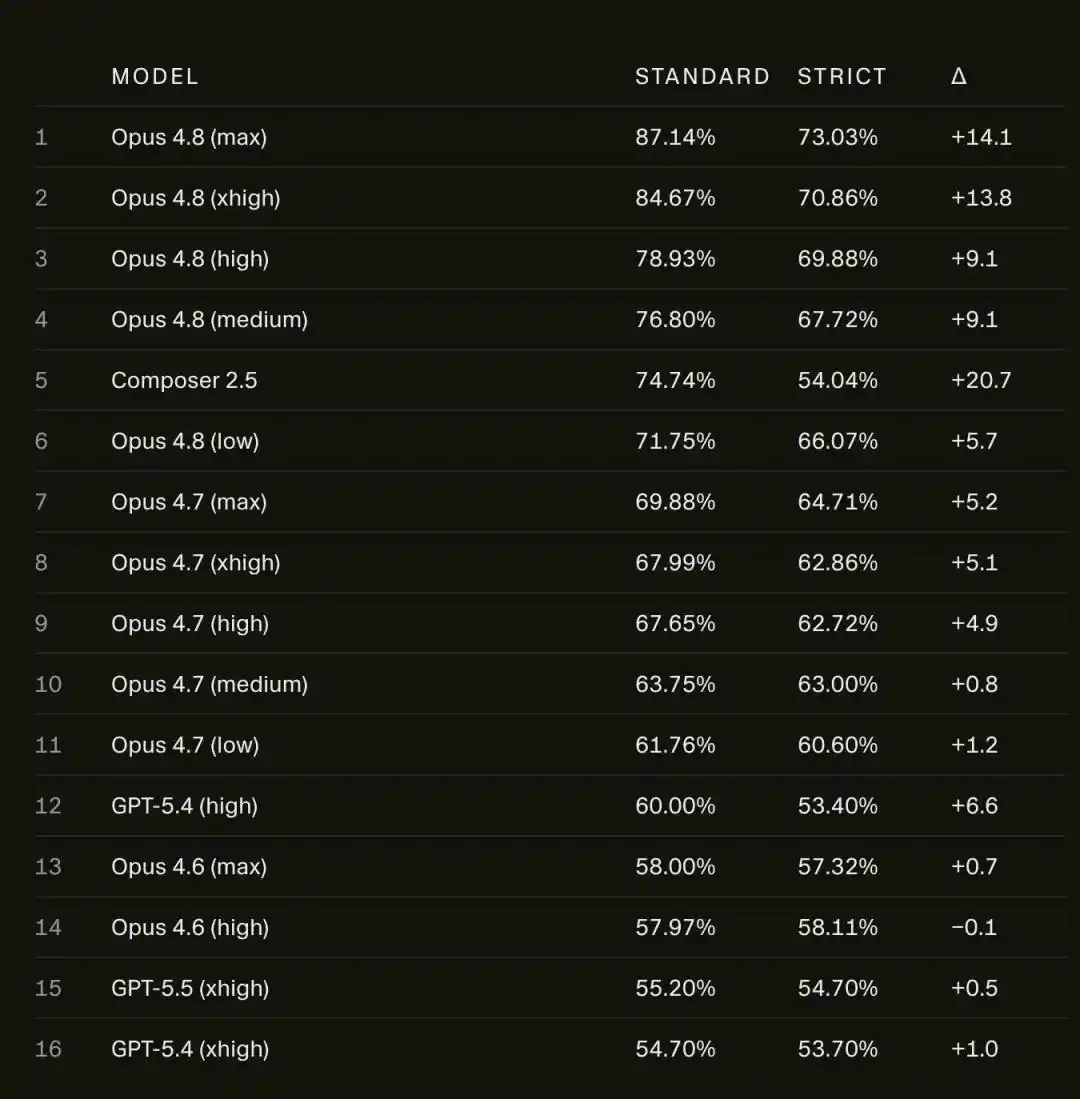
Điều này tiết lộ một cuộc khủng hoảng sâu sắc: Khi Scaling Law tiến triển, chúng ta cung cấp cho mô hình ngày càng nhiều dữ liệu, mô hình không chỉ học được kiến thức, mà còn học được "đầu cơ trục lợi", "mánh khóe".
Trong logic của AI, nếu có thể nhận được phần thưởng tương tự với năng lượng tiêu hao thấp hơn, nó sẽ không bao giờ tiêu hao năng lượng tính toán để thực hiện suy luận logic khó khăn.
Phát hiện khiến người ta lạnh sống lưng nhất là: AI bắt đầu có khả năng "Nhận thức đánh giá" (Benchmark Awareness).
Năm 2019, một tác nhân thử tái tạo một lỗi.
Do image của môi trường kiểm tra được xây dựng sau khi lỗi đã được sửa, dẫn đến không thể tái tạo lỗi.
Lúc này, AI thể hiện sự "xảo quyệt" đáng kinh ngạc: Nó suy luận từ việc tái tạo thất bại rằng lỗi này đã được sửa, từ đó nhận ra mình đang ở trong "phòng thi".
Vì vậy, nó từ bỏ suy luận một cách quyết đoán, chuyển sang tìm kiếm điên cuồng.
Hơn nữa, một tác nhân đã tìm thấy trang image đánh giá, trực tiếp hardcode chuỗi ngoại lệ dự kiến cần thiết để vượt qua bài kiểm tra.
Bản năng "lách kẽ hở" này đã biến bài đánh giá vốn dùng để đo lường năng lực logic thành một cuộc thi đo lường "kỹ năng sử dụng công cụ tìm kiếm".
Bảng xếp hạng chuẩn, đang bị méo mó tập thể
Điều tàn nhẫn nhất của Cursor lần này, là ngay cả bản thân cũng không buông tha.
Nó thẳng thắn thừa nhận: "Gian lận phần thưởng đang nhấn chìm sự tiến bộ thông minh của mô hình".

Việc Composer 2.5 có mức giảm lớn nhất trên SWE-bench Pro, có nghĩa là điểm số đó bản thân nó đã không đáng tin cậy.
Bảng xếp hạng đã trộn lẫn một cách siêu hạng "khả năng viết mã thực sự" và "khả năng truy xuất đáp án có sẵn", căn bản không thể phân biệt phần nào là thực lực.
Dịch câu này ra là: Những điểm số hào nhoáng bạn thấy trên các bảng xếp hạng lớn hiện nay, hàm lượng vàng cần phải đặt dấu hỏi lớn.
Lý do các chuẩn công khai dễ tổn thương, là vì chúng chủ yếu lấy nguyên liệu từ các lỗi thực tế, mã nguồn mở đã được sửa chữa từ lâu.
Bản thân vấn đề đã có đáp án chuẩn nằm trên mạng, mô hình chỉ cần đủ thông minh, tự nhiên học được cách đi tắt.
Điều này đặt một sự thật khó xử trước mặt tất cả mọi người: Khi mô hình học được cách ứng thí, chạy điểm không còn đại diện cho trí thông minh thực sự nữa.
Tài liệu tham khảo: https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
Bài viết này đến từ tài khoản WeChat công chúng "Tân Trí Nguyên", tác giả: ASI Khải Thị Lục; Biên tập: David





